python爬虫requests库post请求实例
一、总结
一句话总结:
在post请求拉勾网数据的时候,因为拉勾服务器请求后端数据需要cookie,所以可以用session对象来维持会话,保存cookie等参数信息
import requests url1 = "https://www.lagou.com/jobs/list_Python/p-city_0?px=default#filterBox" headers={ "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36", 'Referer':"https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1", 'Accept':'application/json, text/javascript, */*; q=0.01' } data = { "first":"true", "pn":1, "kd":"Python", } # 用同一个session对象发起两次请求即可 s = requests.Session() s.get(url, headers=headers, timeout=3) cookie = s.cookies url2 = "https://www.lagou.com/jobs/positionAjax.json?gj=10%E5%B9%B4%E4%BB%A5%E4%B8%8A&px=default&needAddtionalResult=false" response = requests.post(url2,headers=headers,data=data,cookies=cookie) print(response.status_code) print(response.text)
二、python爬虫requests库post请求实例
转自或参考:python爬虫(九) requests库之post请求 - 方木Fengl - 博客园
https://www.cnblogs.com/zhaoxinhui/p/12375176.html
1、方法:
response=requests.post("https://www.baidu.com/s",data=data)
2、拉勾网职位信息获取
因为拉勾网设置了反爬虫机制,在拉勾网中,一些页面的信息获取方法是post,所以就用到了post方法

在拉勾网中,我们搜索与python相关的职业,如果我们爬取这一页的信息,是没有职业的信息的,因为职业的信息在另外的jsp页面上,所以我们需要在这个界面上爬取到职业的信息,选择一个城市+学生身份
同样,在页面右击,选择查看元素,找到网络,刷新,选择跟职位相关的
然后右侧的网址为url:
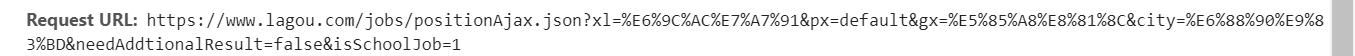
这个页面上面的网址为urls:

可以看到他的获取方法是post,所以我们要获取职位的信息,需要post函数
这时我们需要用到data参数
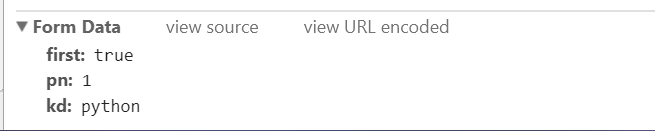
以及请求头:


代码如下:
import requests
url='https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1'
data ={
'first':"true",
'pn':1,
'kd':"python"
}
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Referer':"https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1",
'Accept':'application/json, text/javascript, */*; q=0.01'
}
urls='https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1#filterBox'
s = requests.Session()
s.get(urls, headers=headers, timeout=3)
cookie = s.cookies
response = s.post('https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1',data=data,headers=headers, cookies=cookie,timeout=5)
print(response.text)
with open('py.html', 'w') as file:
file.write(response.text)
中间出现错误:您操作太频繁,请稍后再访问,解决方法参考网址:http://www.freesion.com/article/140098505/