目录:
一:查找的概念与术语
二:折半查找
三:二叉排序树
四:平衡二叉树
五:B-树
六:B+树
七:散列表
八:实践题:QQ帐户的申请与登陆
九:自我总结
一、查找的概念与术语
(一)查找表
查找表是由同一类型的数据元素(或记录)构成的集合。
(二)关键字
关键字是数据元素(或记录)中某个数据项的值,用它可以标识一个数据元素(或记录)。
(三)查找
查找是指根据给定的某个值,在查找表中确定一个其关键字等于给定值得记录或数据元素。
(四)动态查找表和静态查找表
若在查找的同时对表作修改操作(如插入和删除),则相应的表称之为动态查找表,否则称之为静态查找表。
(五)平均查找长度(ASL)
为确定记录在查找表中的位置,需和给定值进行比较的关键字个数的期望值,成为查找算法在查找成功时的平均查找长度。
对于含有n个记录的表,查找成功时的平均查找长度为P1*C1+P2*C2+....+Pi*Ci+.....+Pn*Cn
其中,Pi为查找表中第i个记录的概率,Ci为找到表中其关键字与给定值相等的第i个记录时,和给定值已进行过比较的关键字个数。
二、折半查找
折半查找也称二分查找,它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
折半查找的查找过程为:从表的中间记录开始,如果给定值和中间记录的关键字相等,则查找成功;如果给定值大于或者小于中间记录的关键字,则在表中大于或小于中间记录的那一半
中查找,这样重复操作,直到查找成功,或者在某一步中查找区间为空,则代表查找失败。
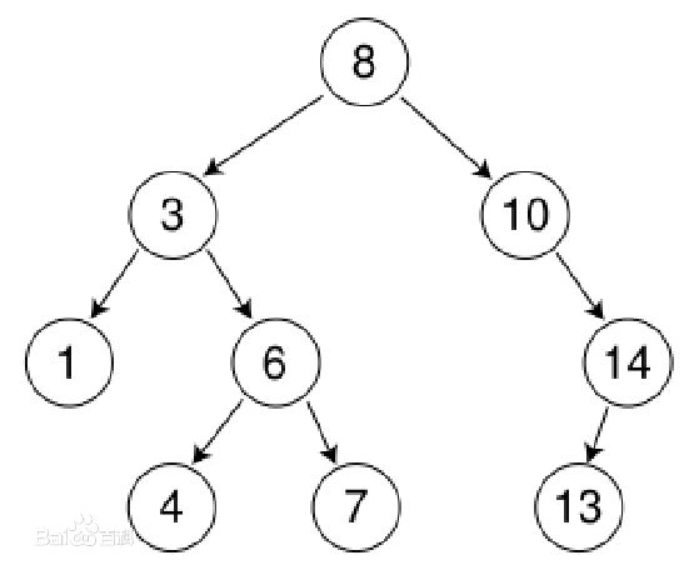
三:二叉排序树
二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
(一)若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
(二)若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
(三)它的左、右子树也分别为二叉排序树。
如下图就为一棵二叉排序树
四、平衡二叉树
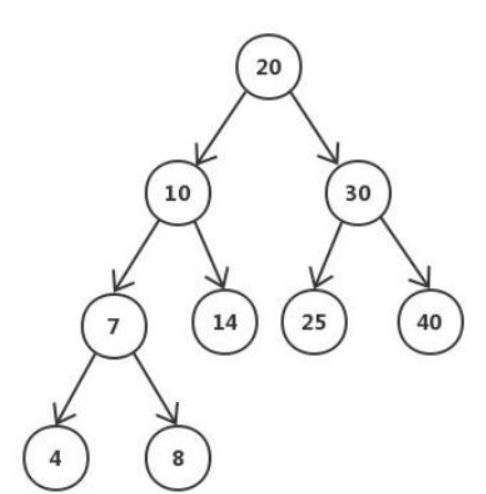
平衡二叉搜索树(Self-balancing binary search tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。 最小二叉平衡树的节点总数的公式如下 F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,可以参考Fibonacci(斐波那契)数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量。
如下图就为一棵平衡二叉树
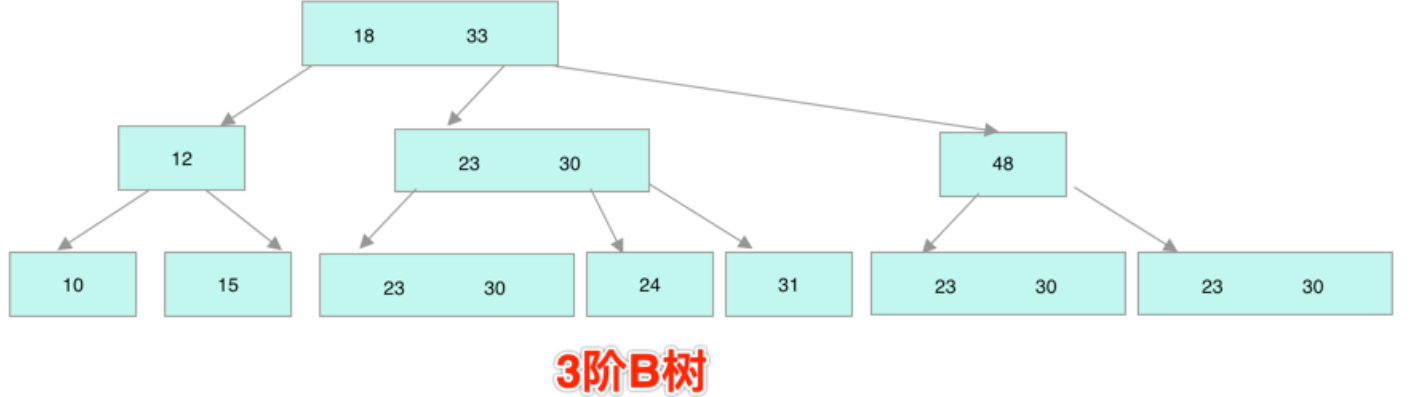
五、B-树
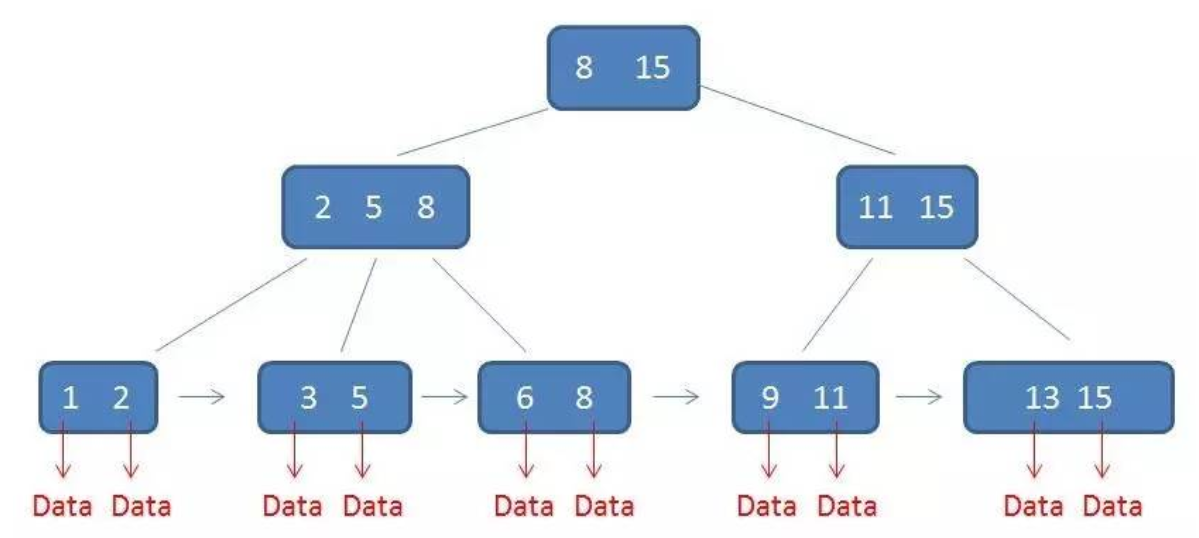
六、B+树
一棵m阶的B+树和m阶的B-树的差异在于:
(一)有n棵子树的节点中含有n个关键字;
(二)所有的叶子结点中包含了全部关键字的信息,以及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序连接;
(三)所有的非终端节点可以看成是索引部分,节点中仅含有其子树中的最大(或最小)关键字
如图
七、散列表
(一)散列法中常用的几个术语:(二)散列函数的构造方法:
1.数字分析法
2.平方取中法
3.折叠法
4.除留余数法 (假设散列表表长为m,选择一个不大于m的数p,用p去除关键字,除后所得余数为散列地址)
(三)处理冲突的办法
1.开放地址法
(1)线性探测法
(2)二次探测法
(3)伪随机探测法
2.链地址法(下面做实践题目用到)
实现QQ新帐户申请和老帐户登陆的简化版功能。最大挑战是:据说现在的QQ号码已经有10位数了。
输入格式:
输入首先给出一个正整数N(≤),随后给出N行指令。每行指令的格式为:“命令符(空格)QQ号码(空格)密码”。其中命令符为“N”(代表New)时表示要新申请一个QQ号,后面是新帐户的号码和密码;命令符为“L”(代表Login)时表示是老帐户登陆,后面是登陆信息。QQ号码为一个不超过10位、但大于1000(据说QQ老总的号码是1001)的整数。密码为不小于6位、不超过16位、且不包含空格的字符串。
输出格式:
针对每条指令,给出相应的信息:
1)若新申请帐户成功,则输出“New: OK”;
2)若新申请的号码已经存在,则输出“ERROR: Exist”;
3)若老帐户登陆成功,则输出“Login: OK”;
4)若老帐户QQ号码不存在,则输出“ERROR: Not Exist”;
5)若老帐户密码错误,则输出“ERROR: Wrong PW”。
输入样例:
5
L 1234567890 myQQ@qq.com
N 1234567890 myQQ@qq.com
N 1234567890 myQQ@qq.com
L 1234567890 myQQ@qq
L 1234567890 myQQ@qq.com输出样例:
ERROR: Not Exist New: OK ERROR: Exist ERROR: Wrong PW Login: OK
先附上使用map的代码


#include <iostream>
#include <map>
using namespace std;
map<string,string> m;
int main()
{
int N;
cin>>N;
for(int i=1;i<=N;++i){
string QQ,mi;
char ca[2];
cin>>ca>>QQ>>mi;
if(ca[0]=='L'){
if(m[QQ].length()<=0) {
cout<<"ERROR: Not Exist
";
continue;
}
if(m[QQ]==mi) cout<<"Login: OK
";
else cout<<"ERROR: Wrong PW
";
}
else{
if(m[QQ].length()<=0) {
m[QQ]=mi;cout<<"New: OK
";
}
else cout<<"ERROR: Exist
";
}
}
return 0;
}
下面来分享一下我的想法
QQ号最大9位数,数组开不了这么大,但是题目表示最多只会创建1e5个号码,为了实现快速查询,我们对QQ号进行哈希
先定义存储QQ号的结构体(QQ是QQ号码,mi是密码,r是指向右边的指针,下面会用到)
struct node{
ll QQ;
string mi;
node* r;
};
散列函数我选择除留余数法 ,1到1e5中最大的质数为99991,令mod=99991
那么hash函数就写好了
int gethash(long long int num)
{
return num%mod;
}
接下来就要处理冲突问题了,我选择链地址法
假如多个QQ号的hash值都为key,那就把他们都放在head【key】的链表中
举个栗子
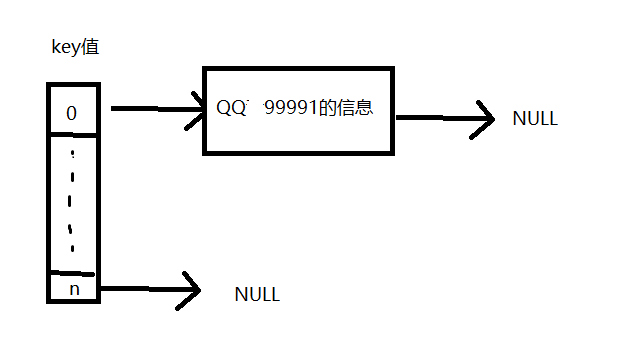
假如我创了2个QQ号,一个是99991,一个是99991*2=199982,这两个QQ号hash出来的key都是0
先开一个辅助指针数组head[100010],head[i]表示key为i的第一个节点地址(间接获得QQ号信息)
当创建QQ号是99991的时候
发现head[0]为NULL,直接new一个节点p,赋值好相关信息,令head[0]=p;
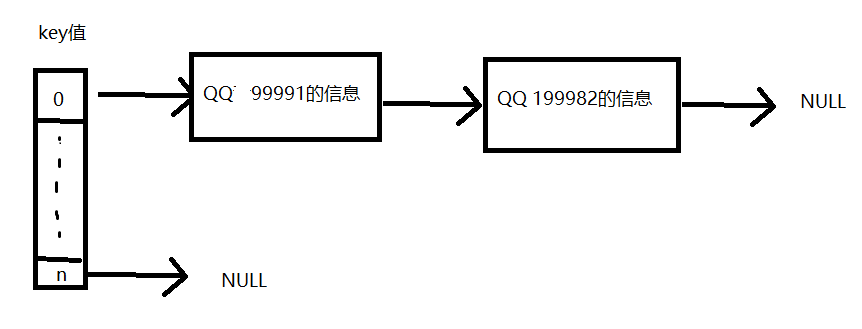
当创建QQ号是199982的时候
发现head[0]有值了,那么创立一个临时指针q=head[0]
一直令q=q->r,往右边找,如果途中找到了一个QQ号和准备创建的QQ号一样,说明QQ号存在,进行一些操作
如果到q->r为NULL的时候还没找到一个QQ号和准备创建的QQ号一样时,说明这个QQ号可以用
new一个节点p,赋值,令q->r=p(链表后插),输出创建成功
登陆的话就很简单了,只需要在对应的链表中跑,每一条链表的元素个数都不会很多,所以不会超时
图示:

AC代码:
#include <iostream>
#include <string.h>
#define ll long long int
using namespace std;
const int mod = 99991;
struct node{
ll QQ;//QQ号
string mi;//QQ密码
node* r;//该节点右边的节点地址
};
node *head[100010];//链表头
int gethash(ll num)//hash函数
{
return num%mod;
}
void login(ll QQ,string mi)
{//登陆函数
int key = gethash(QQ),flag_qq=0;//获取散列地址key
if(head[key]==NULL) {//key的链表是空的,里面没有元素,QQ号不存在
cout<<"ERROR: Not Exist
";
return ;
}
node* now=head[key];
while(now!=NULL)
{//遍历key的链表
if(now->QQ==QQ) {
flag_qq=1;
if(now->mi == mi) cout<<"Login: OK
";//string类可以进行==比较
else cout<<"ERROR: Wrong PW
";
break;
}
now=now->r;
}
if(flag_qq==0) cout<<"ERROR: Not Exist
";//while循环正常退出,说明找不到这个QQ号
}
void create(ll QQ,string mi)
{//创建QQ号
int key = gethash(QQ),flag=0;
node *p = new node;
p->QQ=QQ;p->mi=mi;p->r=NULL;//创建空间存QQ信息
if(head[key]==NULL){//key的链表是空,那这个节点就是链表头了
head[key]=p;
cout<<"New: OK
";
}
else{
node *q=head[key];
if(q->QQ==QQ) flag=1;//打补丁 特判
while(q->r!=NULL){//一直走到key链表的尽头,进行尾插
if(q->QQ==QQ) {
flag=1;
break;
}
q=q->r;
}
if(q->QQ==QQ) flag=1;//打补丁 特判
if(!flag) {
q->r=p;
cout<<"New: OK
";
}
else cout<<"ERROR: Exist
";
}
}
int main()
{
int N;
cin>>N;
for(int i=1;i<=N;++i){
char str[2];
ll QQ;
string mi;
cin>>str>>QQ>>mi;
if(str[0]=='L'){
login(QQ,mi);
}
else {
create(QQ,mi);
}
}
return 0;
}
九、自我总结
上次的目标算是达到了吧,理解状压DP,感觉自己能理解它说啥,但是做题的时候不能熟练运用。
下次的目标:好好复习期末考试,恶补电子电路和高数
暑假集训加油!