一、计算核心增加
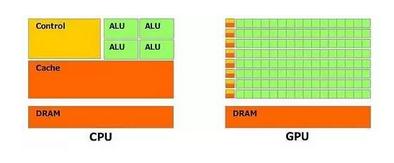
二者都由寄存器、控制器、逻辑单元构成,但比例很大不同,决定了CPU擅长指令处理,函数调用上;GPU在数据处理(算数运算/逻辑运算)强力很多。
NIVIDA基于Maxwell构架的GPU代号GM200的显示核心主要由4个图形处理集群(GPC ),16个流处理集群(SMM)和4个64bit显存控制器组成。每个流处理集群中包含了4个调度器(Warp),每个调度器又控制着32个逻辑计算核心(Core),Core是实现逻辑计算的基本单元。
GPU处理数据过程:
- 从CPU得到数据处理指令。
- 把大规模、无结构化的数据分解成很多独立的部分然后分配给各个流处理器集群。
- 每个流处理器集群再次把数据分解,分配给调度器所控制的多个计算核心同时执行数据的计算和处理。
如果一个核心的计算算作一个线程,那么在这颗GPU中就有32×4×16, 2048个线程同时进行数据的处理。尽管每个线程/Core的计算性能、效率与CPU中的Core相比低了不少,但是当所有线程都并行计算,那么累加之后它的计算能力又远远高于CPU。
二、内存结构不同
GPU另一个比较重要的优势就是他的内存结构。
- 首先是共享内存。在NVIDIA披露的性能参数中,每个流处理器集群末端设有共享内存。相比于CPU每次操作数据都要返回内存再进行调用,GPU线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来最大的好处就是线程间通讯速度的提高(速度:共享内存》全局内存)。
- 再就是高速的全局内存(显存):目前GPU上普遍采用GDDR5的显存颗粒不仅具有更高的工作频率从而带来更快的数据读取/写入速度,而且具有更大的显存带宽。我们认为在数据处理中,速度往往最终取决于处理器从内存中提取数据以及流入和通过处理器要花多少时间。
而在传统的CPU构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在CPU中运算最后返回内存中。由于构架的原因,二者之间的通信带宽通常在60GB/s左右徘徊。与之相比,大显存带宽的GPU具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
数据推断:FPGA VS ASIC
CPU与GPU都是利用现有的成熟技术去提供了一种通用级的解决方法来满足深度学习的要求,是大公司对于深度学习的一种妥协,而并不是一种针对性的专业解决方案。
FPGA可编程逻辑阵列:它有一下几个的特点: 硬件层面上,其内部集成大量的数字电路基本门电路和存储器,用户可以通过烧入配置文件来定义这些它们之间的连线,从而达到定制电路的目的;逻辑层面上,它不依赖于冯诺依曼结构,一个计算得到的结果可以被直接馈送到下一个无需在主存储器临时保存。
ASIC特定应用集成电路:应特定应用要求和特定电子系统的需要而设计制造的集成电路,比FPGA快。
与GPU/CPU相比,FPGA与ASIC运行能效比更好(运算量/功耗),虽然前者有很多核心但是受限于冯诺依曼结构无法发挥并行计算特点,后者除了可以做到并行计算还能实现流水处理,大大减小了输入输出延时比。
在设计环节对比,FPGA只需用描述语言定义好内部逻辑结构即可实现硬件功能,ASIC设计制造要经过很多验证和物理设计,开发周期是是FPGA的两倍;但FPGA虽然灵活低成本,但是执行效率远比不上ASIC,FPGA的通用性必然导致亢余,其运算电路基于查找表,比如说FPGA内部有1000万个自定义逻辑部件,一个4输入的查找表单元要96个晶体管来支持,而在ASIC大概10个,这些亢余会体现在面积和功耗上。
GPU/CPU竞争一边倒,FPGA/ASIC相对缓和,FPGA被大量应用在大企业线上数据处理中心和军工单位,ASIC偏向消费电子
GPU适合搭建平台,FPGA/ASIC适合数据推段(95%工作量),摩尔定律的枯竭和数据的爆发增长产生矛盾,一种解决方法是通过硬件加速,采用专用协处理器提升性能
以深度学习为例,从芯片架构、计算性能、功耗、开发难度几个方面对芯片分析对比。深度学习又叫深层神经网络,是从人工神经网络发展而来
CPU
CPU作为通用处理器,兼顾计算和控制,70%晶体管用来构建Cache和流程控制器,用来处理复杂逻辑和提高指令效率,致使可以处理计算复杂度高,但性能一般
提高CPU性能三个方向:加核、提高频率、修改架构(增加计算单元个数)
GPU
GPU提供大量计算单元和高速内存,可同时并行处理很多像素,GPU把晶体管更多用于计算单元,而不像CPU,这样的设计是因为并行计算时每个数据单元执行相同程序,不需要繁琐流程控制及大Cache容量,而更需高计算能力。GPU中一个逻辑控制单元对应多个计算单元,要计算单元充分并行逻辑控制单元必然不能太复杂,例如太多if...else...分支无法提高并行度
FPGA
FPGA的硬件语言描述的逻辑可以直接被编译为晶体管电路的组合,直接用晶体管实现算法,没有通过指令系统翻译。FPGA的计算单元可以是DSP
ASIC
相比通用芯片,体积小、能耗低、计算效能高、效率高、出货量越大成本越低;相比FPGA,缺点算法固定,AI算法却处于爆发期;开发周期长在高可靠性场合如军工和工业ASIC需要更多时间,而FPGA直接买军工级FPGA就可以了。ASIC性能高于FPGA(5~10倍)量产后成本低于FPGA。