定义:
是一种工具,就像是容器,能存储任意数量的具有共同属性的对象。
与数组比较优点:
(1)数组定义后长度不可变,集合长度可变;
(2)数组只能通过下标访问,且下标类型只能是数字型,而有的集合(map)可以通过任意类型查找所映射的具体对象。
集合框架体系结构:
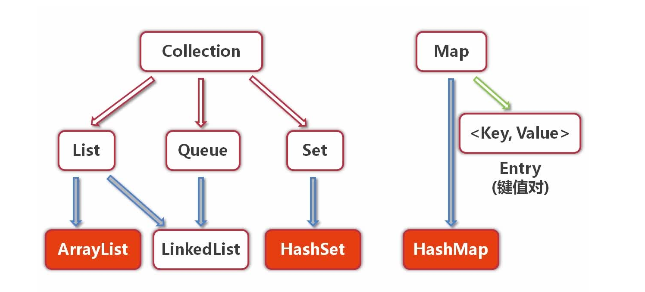
List的重要实现:ArrayList,LinkedList
ArrayList:
优点:ArrayList以类似数组的形式进行存储,故随机访问速度极快;
缺点:不适用进行频繁的插入或删除操作,因为每次插入或删除操作都会移动数组中的元素。
ArrayList就是基于数组的一个线性表,只不过长度可以动态改变。
关于ArrayList的几点注意:
(1)初始化ArrayList的时候如果没有指定初始化长度,默认长度为10;
(2)ArrayList在增加新元素的时候如果超过了原始容量,会进行扩容,为 原始容量*3/2 +1;
(3)ArrayList是线程不安全的,在多线程的情况下不要使用。
但可以使用Vector,因为Vector和ArrayList基本一致,区别在于Vector中的绝大部分方法都使用了同步关键字修饰,这样在多线程的情况下不会出现并发的错误。
Vector的扩容为原始容量*2;
Vector是ArrayList多线程的替代品。
(4)ArrayList实现遍历的几种方法:
public class Test7 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("hello");
list.add("world");
list.add("!!!");
//1、for循环遍历
for(String str:list){
System.out.println(str);
}
for(int i=0;i<list.size();i++){
System.out.println(list.get(i));
}
//2、把链表变成数组相关的内容进行遍历
String[] stringArr = new String[list.size()];
list.toArray(stringArr);
for(int j=0;j<stringArr.length;j++){
System.out.println(stringArr[j]);
}
//3、迭代器遍历
Iterator<String> it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
LinkedList:
优点:适合于在链表中间进行频繁的进行插入和删除操作;
缺点:随机访问速度较慢,查找元素需要从头开始一个一个的找。
LinkedList就是一种双向循环链表的链式线性表,只不过存储的结构使用的是链式表而已。
LinkedList的内部实现:【推荐看jdk源码】
LinkedList的内部是基于双向循环链表的结构来实现的。在LinkedList中有一个类似于C语言中结构体的Entry内部类。
在Entry的内部类中包含了前一个元素的地址引用和后一个元素的地址引用,类似于C语言中的指针。
LinkedList是线程不安全的,如果在多线程下面访问可以自己重写LinkedList,然后在需要同步的方法上面加上同步关键字synchronized。
LinkedList的遍历方法:
package javaEE;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
/**
* @author 047493
* @version 2018年8月30日
* LinkedList遍历
*/
public class Test8 {
public static void main(String[] args) {
List<String> list = new LinkedList<String>();
list.add("hello");
list.add("world");
list.add("我是一颗铜豌豆!");
for(String str:list){
System.out.println(str);
}
/*for(int i=0;i<list.size();i++){
System.out.println(list);
}*/
String[] strArr = new String[list.size()];
list.toArray(strArr);
for(int j=0;j<strArr.length;j++){
System.out.println(strArr[j]);
}
Iterator<String> it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
由于LinkedList实现了接口Dueue,所以LinkedList可以被当做堆栈来使用。
Set接口:
Set接口与List接口的区别在于,Set中的元素实现了不重复,有点像集合的概念,无序,不允许有重复的元素,最多允许有一个null元素对象。
需要注意的是:虽然Set中的元素没有顺序,但是元素在Set中的位置是由该元素的hashCode决定的,其具体位置其实是很固定的。
举个例子:
对象A和对象B本来是两个不同的对象,正常情况下它们是可以同时放到Set集合中去的,但是,如果对象A和对象B都重写了hashcode和equals方法,并且重写后的hashcode和equals值相同的话,
那么A和B就不能同时放到Set集合中去了,也就是说Set集合中的去重和hashcode与equals方法相关。
package javaEE;
import java.util.HashSet;
import java.util.Set;
/**
* @author 047493
* @version 2018年8月30日
* 类说明
*/
public class Test9 {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("hello");
set.add("world");
set.add("hello");
set.add(null);
set.add(null);
System.out.println("set的大小为"+set.size());
System.out.println("set中的元素有"+set.toString());
}
}
运行结果如下:
set的大小为3
set中的元素有[null, hello, world]
由于String类重写了hashcode和equals方法,所以第二个hello和null是加不进去的。
遍历HashSet的几种方法:
package javaEE;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* @author 047493
* @version 2018年8月30日
* 类说明
*/
public class Test9 {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("hello");
set.add("world");
set.add("hello");
set.add("我是一颗铜豌豆");
set.add(null);
for(String str:set){
System.out.println(str);
}
String[] arrSet = new String[set.size()];
set.toArray(arrSet);
for(int i=0;i<arrSet.length;i++){
System.out.println(arrSet[i]);
}
Iterator<String> it = set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
LinkedHashSet:
LinkedHashSet不仅是Set的子接口,还是HashSet的子接口。
LinkedHashSet与HashSet的主要区别在于,LinkedHashSet中存储的元素是在哈希算法的基础上增加了链式表的结构。
TreeSet:
TreeSet是一种排序二叉树。存入Set集合中的值,会按照值的大小进行相关的排序操作。底层算法是基于红黑树实现的;
TreeSet和HashSet的主要区别在于TreeSet中的元素会按照相关的值进行排序;
关于HashSet和TreeSet的区别和联系:
- HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的是Map中的key;
- Map的key和Set都有一个共同的特性就是集合的唯一性,TreeMap更是多了一个排序的功能;
- hashCde和equals()是hashMap用的,因为无需排序,所以只需关注定位和唯一性即可;
hashCode是用来计算hash值的,hash值是用来确定hash表索引的;
hash表中的一个索引处存放的是一张链表,所以还要通过equals()循环比较链上的每一个对象才可以真正定位到键值对应的Entry;
put时如果hash表中没有定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧的value。
4. 由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较,当然也是用Comparator进行定位的;
Comparator可以在创建TreeMap时指定;
如果创建时没有指定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口;
TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了。
package javaEE;
import java.util.Iterator;
import java.util.TreeSet;
/**
* @author 047493
* @version 2018年8月30日
* 类说明
*/
public class Test10 {
public static void main(String[] args) {
TreeSet<String> treeSet = new TreeSet<String>();
treeSet.add("a");
treeSet.add("c");
treeSet.add("d");
treeSet.add("b");
Iterator<String> it = treeSet.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
运行结果:
a
b
c
d
Map:
- Map提供了一种映射关系,其中元素是以键值对(key-value)的形式存储的,能够实现根据key快速查找value;
- Map中的键值对以Entry类型的对象实例形式存在;
- key不可重复,value值可重复,每个键最多只能映射到一个值;
- Map支持泛型,形如:Map<K,V>;
- Map中使用put<key,value>方法添加。
HashMap:
- HashMap是Map的一个重要实现类,基于哈希表实现;
- HashMap中的Entry对象是无序排列的;
- key值和value值都可以为null,但一个hashMap只能有一个key值为null的映射
https://www.cnblogs.com/jpwz/p/5680494.html
Hash算法:http://www.cnblogs.com/xiohao/p/4389672.html
map的几种遍历方法:
package javaEE;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
/**
* @author 047493
* @version 2018年8月30日
* Map的遍历
*/
public class Test11 {
public static void main(String[] args) {
String[] str = {"i love xiaomei","xiaomei love me","zhaoxin love xiaoli","xiaoli love zhaoxin"};
Map<Integer,String> map = new HashMap<>();
for(int i=0;i<str.length;i++){
map.put(i, str[i]);
}
//迭代 通过Map.entrySet使用迭代器遍历key和value
Iterator<Entry<Integer, String>> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Integer, String> entry = (Entry<Integer, String>) it.next();
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println("key:"+key+",value:"+value);
}
//推荐使用,尤其容量大时 通过map.entrySet遍历key和value
for(Map.Entry<Integer, String> entry:map.entrySet()){
int key = entry.getKey();
String value = entry.getValue();
System.out.println("key:"+key+",value:"+value);
}
//只能遍历出value的值,无法遍历key的值
for(String strVal:map.values()){
System.out.println("value:"+strVal);
}
//普遍使用,二次取值 通过Map.KeySet遍历key和value
for(int keys:map.keySet()){
System.out.println("key:"+keys+",value"+map.get(keys));
}
}
}