反向传播算法(Back propagation)
目的及思想
我们现在有一堆输入,我们希望能有一个网络,使得通过这个网络的构成的映射关系满足我们的期待。也就是说,我们在解决这个问题之前先假设,这种映射可以用网络的模型来比较好的描述。为什么是网络而不是什么别的形式呢?不懂了。。
这个网络到底是个怎样的形式呢?如下图所示,(i1,i2)是输入,(o1,o2)是输出,其中(w1...w8, b1, b2)是这个网络中的参数。对于一个结点来说,它的所有输出都等于它的每个输入,对于对应(w)的加权求和带入激活函数的结果。
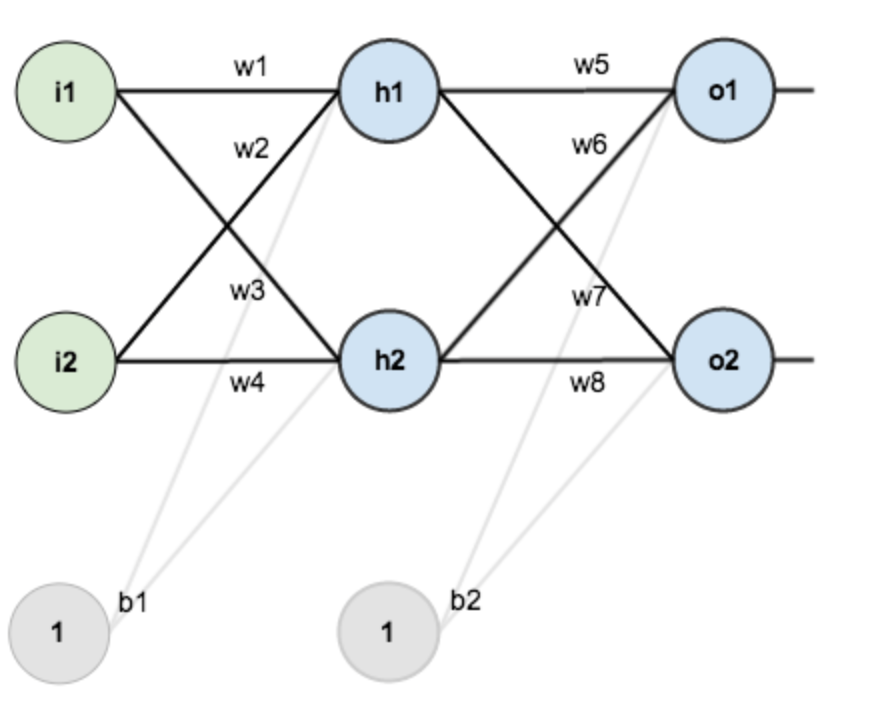
而现在(w1...w8, b1, b2)这些参数都是未知的,我们希望能通过一些方法逼近这些参数的真实结果。
我们将(w1...w8, b1, b2)这些参数,考虑成一个高维空间中的点,与三维还有二维的情况类似的,我们贪心的朝着周围都走一小步,找到那个能获得相对最优解的方向,并接受这次移动,这是经典的梯度下降的思想。于是,我们引入了损失函数,使用它来描述这个点的优秀程度。(w1...w8, b1, b2)是这个函数的输入,通过调整这些输入,我们希望能获得一个使得损失函数获得最值的位置,然而实际上,我们获得的显然是一个极值,并不一定是最值,除非能证明这个损失函数关于这些参数是凸的。但是,作为一个比较优秀的解,这样做还是有价值的。
后半部分的思想过程顺理成章,感觉整套方法最有价值和启发意义的就是这个网络模型。
具体算法
- 设定输入量(i_1,i_2...i_n),以及(w_1...w_{n*n*2}, b_1, b_2),如果可能尽量设定在离真实解较近的位置,最好在一个坑里?
- 激活函数选取经典的sigmoid函数 (f(x) = frac{1}{1+e^{-x}})
- 损失函数取 (L(w_1...w_{n*n*2}, b_1, b_2) = frac{1}{2} sum_{i=1}^n (target_j - o_j)^2), 我们定义(i_j)对应的目标输出为(target_j)
- 对于当前网络带入(i_1,i_2...i_n),求出对应的(o_1,o_2,...,o_n). 这个过程显然就是在一张dag上按照拓扑序递推更它的后继节点即可,每到一个点计算它的激活函数的输出,然后更新它的后继节点
- 更新完之后,我们就获得了(o_1,o_2,...,o_n). 现在需要求解 L 关于这每个参数的在当前输入情况下的偏导。容易利用链式法则解决(懒得写了)这里有超详细推导
一文弄懂神经网络中的反向传播法——BackPropagation - 返回操作 4,直到获得令人满意的精度
代码
c++写了个实现。太丑了不发了。。最麻烦的部分就是链式求导算梯度的几个式子推导,有了式子之后还是挺好写的。非常有意思的是,一开始的写法,没有加入参数 b1,b2,因此迭代 500000 次左右才能使L达到 1e-22 的精度,但是当我们,补上 b1 和 b2 时,只用迭代 200000 次即可达到,一个式子形式的设计或者说网络结构的设计,对于算法的效果影响还是很巨大的。