Principle of network applications
Network application architectures
Application architecture: (different from the network architecture) Designed by the application developer, dictates how the application is structured over the various end system.
Two predominant architectural paradigms: a) the client-server architecture b) the peer-to-peer (P2P) architecture.
Client-server architecture: There is an always-on host (server), which services requested from many other sometimes-on or always-on hosts (clients).
Clients do not directly communicate with each other;
The server has a fixed-well known address (IP address).
e.g. the Web, FTP, Telnet, email.
server farm: a cluster of hosts used to create a powerful virtual server in client-server architectures.
Infrastructure intensive: Application services that are based on the client-server architecture.
P2P architecture: The application exploits direct communication between pairs of peers.
Peers communicate without passing through a dedicated server.
Peers: Intermittently connected hosts, not owned by the service provider, but are devices controlled by users.
e.g. BitTorrent, eMule, Skype, PPLive.
P2P architectures have Self-scalability.
Some application have hybrid architectures, combining both client-serer and P2P elements.
e.g. Instant messaging applications.
Processes Communicating
Process: a program that is running within an end system.
When processes are running on the same end system, they communicate with each other with interprocess communication;
When processes are running on different end systems, they communicate with each other by exchanging messages across the computer network.
How does a process indicate which process it wants to communicate with?
To identify the receiving process, 2 pieces of information need to be specified:
a. The name or address of the host. [IP address]
b. An identifier that specifies the receiving process in the destination host. [A destination port number]
Client and Server processes
A network application consists of pairs of processes that send messages to each other over a network, we label one of the two processes as the client and the other process as the server.
(Even if in some applications like P2P file sharing, a process can be both a client and a server, we can still label one process as the client and the other process as the server.)
In the context of a communication session between a pair of processes:
The process that initiates the communication is labeled as the client;
The process that waits to be contacted to begin the session is the server.
Socket
Socket: The interface between the application layer and the transport layer within a host, also referred to as the Application Programming Interface (API) between the application and the network.
A process sends messages into and receive message from, the network through a socket.
Analogy: a door
The application developer has control of everything on the application-layer side of the socket;
The application developer has little control of the transport-layer side of the socket, only includes:
a) The choice of transport protocol; b) The ability to fix a few transport-layer parameters.
Transport-layered protocols for applications
Transport services classification
The services that a transport-layer protocol can offer to applications invoking it can be broadly classify along 4 dimensions: reliable data transfer, throughput, timing, and security.
Reliable data transfer
If a protocol provides a guaranteed data delivery service – guarantee that the data sent by one end of the application is delivered correctly and completely to the other end of the application, it is said to provide reliable data transfer.
A transport-layer protocol that doesn’t provide reliable data transfer may be acceptable for loss-tolerant applications. (e.g. multimedia applications like real-time audio/video)
Throughput
A transport-layer protocol can provide a guaranteed available throughput at some specified rate, with such a service, the application could request a guaranteed throughput of r bits/sec, and the transport protocol would then ensure that the available throughput is always at least r bits/sec.
Bandwidth-sensitive applications: Applications that have throughput requirements.
Elastic applications: Applications that can make use of as much, or as little, throughput as happens to be available.
Timing
Timing guarantees can come in many shapes and forms.
e.g. guarantees that every bit that the sender pump into the socket arrives at the receiver’s socket no more than 100 msec later.
(Appealing to interactive real-time applications.)
Security
A transport protocol can provide an application with one or more security services, providing confidentiality, data integrity or end-point authentication between the 2 processes.
Transport services provided by the internet
The Internet makes 2 transport protocols available to applications, UDP and TCP.

Services provided by TCP protocol
When an application invokes TCP as its transport protocol, the application receives both a connection-oriented service and a reliable data transfer service from TCP.
1) Connection-oriented service: TCP has the client and server exchange transport layer control information with each other (i.e. handshaking procedure) before the application-level message begin to flow. After the handshaking phase, a TCP connection exists between the sockets of the two processes.
The connection is a full-duplex connection. (i.e. The two processes can send message to each other over the connection at the same time.)
When the application finishes sending message, it must tear down the connection.
2) Reliable data transfer service: The communicating processes can rely on TCP to deliver all data sent without error and in the proper order.
TCP also includes a congestion-control mechanism service that throttles a sending process when the network is congested between sender and receiver, and attempts to limit each TCP connection to its fair share of network bandwidth.
Services provided by UDP protocol
UDP is a no-frill, lightweight transport protocol, providing minimal services.
UDP is connectionless (no handshaking), provides an unreliable data transfer service, does not include a congestion-control mechanism.
Services not provided by Internet transport protocols
Today’s Internet can often provide satisfactory service to time-sensitive applications, but it cannot provide any timing or bandwidth (throughput) guarantees.
Application-layer protocols
An application-layer protocol defines:
1) The types of messages exchanged;
2) The syntax of the various message types;
3) The semantics of the fields in the message;
4) Rules for determining when and how a process sends messages and responds to messages.
Some application-layer protocols are available in the public domain (specified in RFCs), e.g. HTTP;
Many other application-layer protocols are proprietary and intentionally not available in the public domain.
An application-layer protocols (e.g. HTTP, SMTP) is only one piece of the network application that using it (e.g. Web, e-mail).
1. The Web & HTTP
Network application: Web
Application-layered protocol: HTTP
HyperText Transfer Protocol (HTTP): The Web’s application-layer protocol, defines the structure of HTTP messages and how the client and server exchange the messages.
When a user requests a Web page, the browser sends HTTP request messages fro the object in the page to the server. The server receives the requests and responds with HTTP response messages that contain the objects.
HTTP is implemented in a client program and a server program executing on different end systems that talk to each other by exchanging HTTP messages.
Web browsers implement the client side of HTTP;
Web servers implement the server side of HTTP, house Web objects, each addressable by a URL.
Object: An object is simply a file tat is addressable by a single URL. (e.g. HTML file, JPEG image, Java applet, video clip.)
Web page: A Web page consists of objects.
Most Web pages consists of a base HTML file and several referenced objects. The base HTML file reference the other objects in the page with the objects’ URLs.
URL: consists of the hostname of the server that houses the object and the object’s path name.
HTTP uses TCP as its underlying transport protocol.
The HTTP client first initiates a TCP connection with the server. Once the connection is established, the browser and the server processes access TCP through their socket interfaces.
The client sends HTTP request messages into its socket interface and receives HTTP response messages from its socket interface;
The server receives HTTP request messages from its socket interfaces and sends HTTP response messages into its socket interface.
HTTP is a stateless protocol, an HTTP server maintains no information about the clients.
HTTP can use both non-persistent connections and persistent connections (default).
Non-persistent connections: If each request/response pair is sent over a separate TCP connection, the application uses non-persistent connections. Each TCP connection transports exactly one request messages and one response messages, and is closed after the server sends the object.
Persistent connections: Else, all of the requests and their corresponding responses are sent over the same TCP connection, the application uses persistent connections. The server leaves the TCP connection open after sending a response, subsequent requests and responses between the same client and server can be sent over that connection.
Round-trip time (RTT): The time for a small packet to travel from client to server and then back to the client.
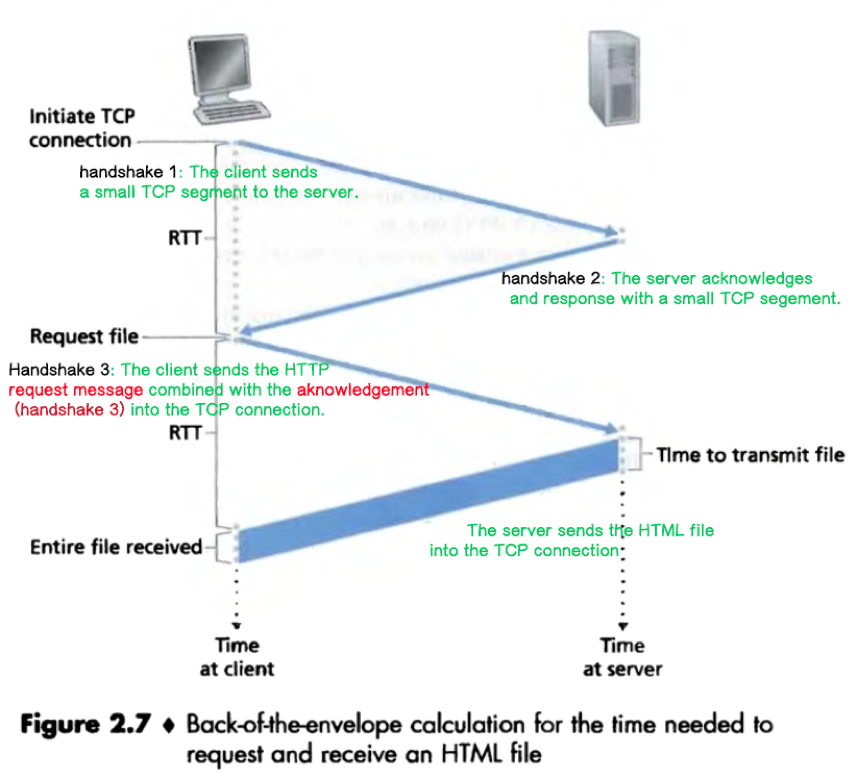
Time needed to request and receive an object = 2*RTT + the transmission time at the server (non-persistent)
There are 2 types of HTTP messages, request messages and response messages.
HTTP request message:

e.g.
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/4.0
Accept-language: fr
Request line: The first line of an HTTP request messages, consists of the method field, the URL filed and the HTTP request field.
Header lines: The subsequent lines after the request line.
The method field can take on values including GET, POST, HEAD, PUT and DELETE.
The GET method is used when the browser requests an object with the requested object identified in the URL field;
The POST method is used when the users fills out a form, use POST and the entity body contains what the user entered into the form field (empty if using GET);
(The GET method can also be used to generate a request with a form by including the inputted data in the requested URL.)
The HEAD method is often used by application developers for debugging. When a server receives a request with the HEAD method, it responds with an HTTP message but leaves out the requested object;
The PUT method allows a user or an application to upload an object on a Web server;
The DELETE method allows a user or an application to delete an object on a Web server.
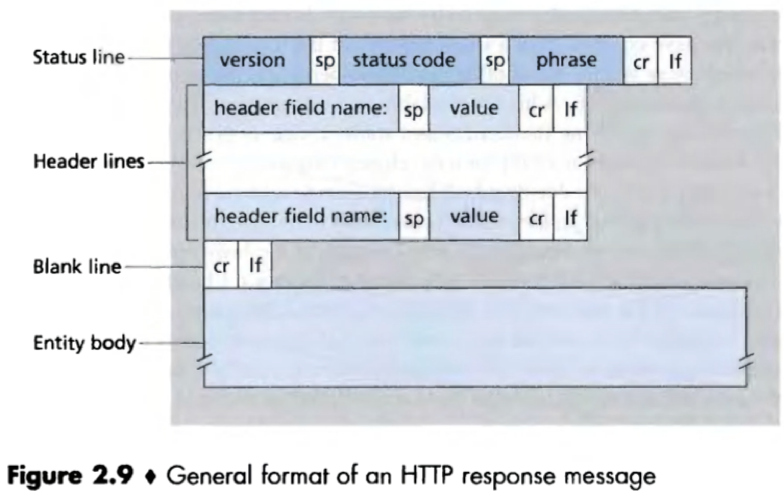
HTTP response message
e.g.
HTTP/1.1 200 OK
Connection: close
Date: Thu, 07 Jul 2007 12:00:15 GMT
Server: Apache/1.3.0 (Unix)
Last-Modified: Sun, 6 May 2007 09:23:24 GMT
Content_Length: 6821
Content_Type: text/html
(data data data data data …)
Status line consists of the protocol version field, a status code and a corresponding status message.
Some common status codes and associated phrases includes:
200 OK; 301 Moved Permanently; 400 Bad Request; 404 Not Found; 505 HTTP Version Not Supported.
Cookies allow server to keep track of users, help to create a user session layer on top of stateless HTTP.
Cookies technology have 4 components:
1) A cookie header line in the HTTP response message; (e.g. Set-cookie: 1678)
2) A cookie header line in the HTTP request message; (e.g. Cookie: 1678)
3) A cookie file kept on the user’s end system and managed by the user’s browser;
4) A back-end database at the Web site.

Each time the client requests a Web page from the server, the browser consults cookie file, extract the identification number for this site, and puts a cookie header line that includes the identification number in the HTTP request.
In this manner, the server is able to track the user’s activity at that site.
Web cache / proxy server: A network entity that satisfies HTTP requests on the behalf of an origin Web serer.
A web cache has its own disk storage and keeps copies of recently requested objects in this storage. Once a browser is configured, each browser request for an object is first directed to the Web cache.
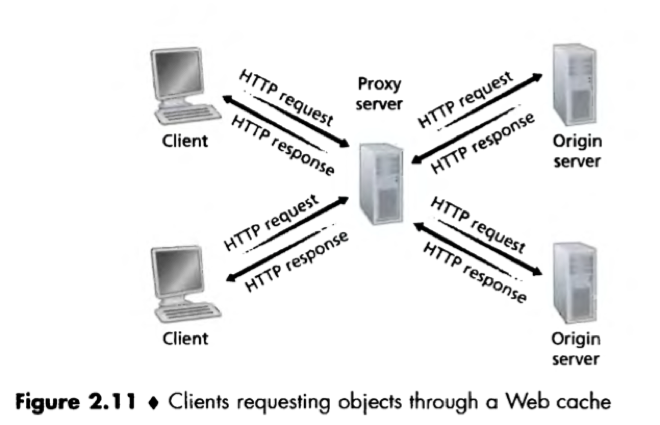
Process:
1) The browser establishes a TCP connection to the Web cache and sends an HTTP request for the object to the Web cache;
2) The Web cache checks if it has a copy of the object stored locally. If it does, the Web cache returns the object within an HTTP response message to the client browser;
3) If the Web cache does not have the object, the Web cache opens a TCP connection to the origin server, sends an HTTP request for the object into the cache-to-server TCP connection.
After receiving this request, the origin server sends the object within an HTTP response to the Web cache;
4) When the Web cache receives the object, it stores a copy in its local storage, and sends a copy within an HTTP response message to the client browser (over the existing TCP connection between the client browser and the Web cache).
Typically a Web cache is purchased and installed by an ISP. Benefits:
a. A Web cache can substantially reduce the response time for a client request, particularly if the bottleneck bandwidth between the client and the origin server is much less than the bottleneck bandwidth between the client and the cache;
b. Web caches substantially reduce traffic on an institution’s access link to the Internet. (Thus the institution does not have to upgrade bandwidth as quickly, thereby reducing costs.)
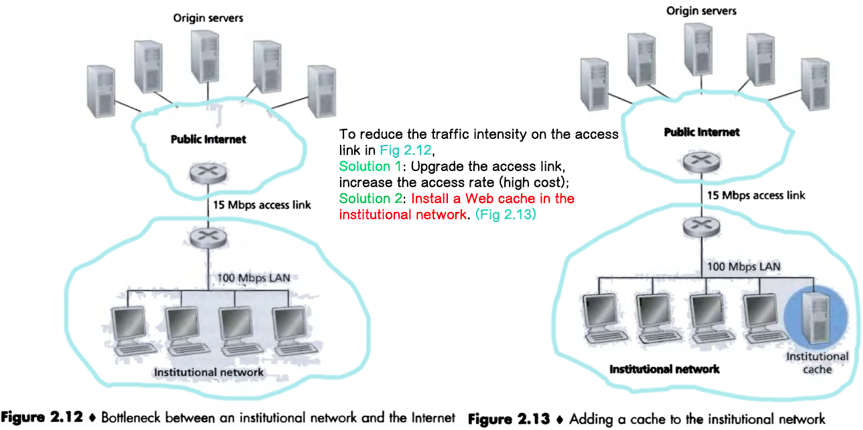
For Web caching, because the object housed in the Web server may have been modified since the copy was cached, the copy residing in the cache may be stale.
The conditional GET: A mechanism that allows a cache to verify that its objects are up to date.
Conditional GET message: An HTTP request message that 1) uses the GET method and 2) includes an If-Modified-Since: header line, telling the server to send the object only if the object has been modified since the specified date.
Process:
1. On behalf of a requesting browser, a proxy cache sends a request message to a Web server:
Cache [requests]→ Web server
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
2. The Web server sends a response message with the requested object to the cache:
Web server [response]→ Web server
HTTP/1.1 200 OK
Date: Thu, 7 Jul 2007 15:39:29
Server: Apache/1.3.0 (Unix)
Last-Modified: Mon, 4 Jul 2007 09:23:24
Content-Type: image/gif
(data data data data data …)
3. The cache forwards the object to the requesting browser. Also, caches the object locally and stores the last-modified date along with the object.
4. (Later, another browser requests the same object via the cache.) The cache performs an up-to-date check by issuing a conditional GET:
Cache [requests with conditional GET]→ Web server
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 4 Jul 2007 09:23:24
5. The server sends a response message to the cache. If not modified since that date, the response message does not include the requested object:
Web server [response (not include requested object)]→ cache
HTTP/1.1 304 Not Modified
Date: Thu, 14 Jul 2007 15:39:29
Server: Apache/1.3.0 (Unix)
6. If the response message that cache receives has 304 NOT Modified in the status line, the cache can go ahead and forward its cached copy of the object to the requesting browser.
2. File transfer & FTP
Network application: File transfer
Application-layered protocol: FTP
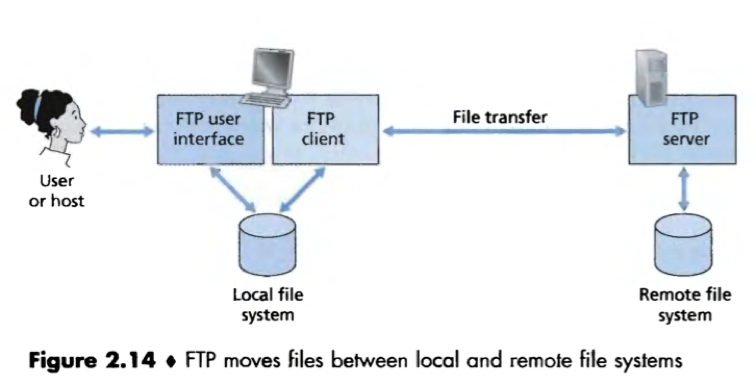
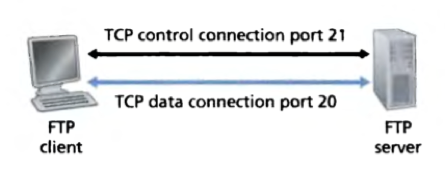
The differences between HTTP and FTP:
1) FTP sends its control information out-of-band, while HTTP sends its control information in-band.
FTP uses 2 parallel TCP connection, a control connection for sending control information (e.g. user identification, password, commands to change remote directory, commands to ‘put’ and ‘get’ files.) between the two hosts, and a data connection for sending a file;
HTTP sends request and response header line into the same TCP connection that carries the transferred file itself.
2) Throughout a session, the FTP server must maintain state about the user, while HTTP is stateless.
The FTP server must associate the control connection with a specific user account, and keep track of the user’ current directory;
HTTP does not have to keep track of any user state.
Process:
1. By providing the hostname of the server (a remote host), The client (a user) causes the FTP client process in the local host to establish an FTP session with the server, initialing a control TCP connection with the server on server port number 21;
2. The client sends the user identification, password over the control connection; (access the remote account)
3. The client wanders about the remote directory tree, sending commands to change remote directory over the control connection;
4. The client sends a command for a file transfer (either to or from the server) over the control connection;
5. The server receives the command and initiates a TCP data connection to the client;
(If, during the same session, the client wants to transfer another file, FTP opens another data connection.)
The data connections of FTP are non-persistent. The FTP control connection remains open throughout the duration of the user session, but a new data connection is created for each file transferred within a session.
The FTP commands and replies are sent across the control connection in 7-bit ASCII format. Each command is followed by a reply.
FTP command: From client to server, consists of 4 uppercase ASCII characters, some with optional arguments. A carriage return and line feed end each command.
e.g.
·USER username: to send the user identification to the server;
·PASS password: to send the user password to the server;
·LIST: to ask the server to send back a list of all the files in the current remote directory. (The server will send the list over a new data connection.)
·RETR filename: to retrieve a file from the current directory of the server. (The server will send the requested file over a new data connection.)
·STOR filename: to store a file into the current directory of the server.
FTP reply: From server to client, three-digit numbers with an optional message following the number.
e.g.
·331 Username OK, password required
·125 Data connection already open; transfer starting
·425 Can’t open data connection
·452 Error writing file
3. Electronic mail
Network application: Electronic mail
Application-layered protocol: SMTP(principle).

Each recipient has a mailbox located in a mail server, managing and maintaining the messages that have been sent to the recipient.

Process:
1. The sender’s user agent pushes the message to his/her mail server, placing the message in the its outgoing message queue; [The sender’s user agent → the sender’s mail server, SMTP]
2. The sender’s mail server relays the message to the recipient’s server, where it is deposited in the recipient’s mailbox. [The sender’s mail server → The recipient ‘s mail server, SMTP]
If the sender’s server cannot deliver mail to the recipient’s server, the sender’s server holds the message in a message queue and attempts to transfer the message later. If there is no success after several days, the server removes the message and notifies the sender with an e-mail message.
3. When the recipient wants to access the message in his/her mailbox, the mail server containing his/her mailbox authenticates the recipient. The recipient’s user agent retrieves the message from his/her mailbox in his/her mail server. [The recipient’s mail server → The recipient’s user agent, mail access protocols including POP3, IMAP, HTTP]
Simple Mail Transfer Protocol (SMTP)
SMTP has a client side that executes on the sender’s mail server, and a server side that executes on the recipient’s mail server. Both the client and server side of SMTP run on every mail server.
How SMTP transfers a message:
1. The client side of SMTP has TCP establish a connection to port 25 at the server side of SMTP.
(If the server is down, the client tries again later.)
2. The server and client perform some initial SMTP handshaking, introducing themselves to each other.
3. The client sends the message into the TCP connection, and the server receives the message.
(The client repeats this process if it has other message to send to the server, else instructs TCP to close the connection.) – SMTP uses persistent connection.
The differences between SMTP and HTTP
1) SMTP is a push protocol, HTTP is a pull protocol.
In SMTP, the TCP connection is initiated by the machine that wants to send the file;
In HTTP, the TCP connection is initiated by the machine that wants to receive the file.
2) SMTP requires each message to be in 7-bit ASCII format.
In SMTP, if the message contains characters that are not 7-bit ASCII or contains binary data, the message has to be encoded into 7-bit ASCII.
HTTP data does not impose this restriction.
3) How a document consisting of text, images or other media types is handled.
HTTP encapsulates each object in its HTTP response message.
SMTP places all of the message’s object into one message.
An email message consists of a header and a message body (in ASCII), separated by a blank line (by CRLF).
Header: a series of header lines, containing peripheral information. Each header line contains readable text, consisting of a keyword followed by a colon followed by a value.
Every header must have a From: header line and a To: header line; Some header lines are optional.
“From:” or “to:”header lines are different from the SMTP commands “FROM” “TO”. the header lines are part of the mail message, the commands are part of the SMTP handshaking protocol.
The multipurpose Internet Mail Extensions (MIME) defines extra headers that allow a user agent to send content other than ASCII text.
The Content—Transfer-Encoding: header alerts the receiving user agent that the message body has been ASCII-encoded and indicates the type of encoding used. (When a user agent receives a message, it uses this header to convert the message body back to its original non-ASCII form.)
The Content-Type: header allows the receiving user agent to take an appropriate action on the message. (After converting the message body back to original form, uses this header to determine what action to take on the message body.)
Upon receiving a message, the SMTP receiving server appends a Received: header line to the message, specifying the name of the SMTP server that sent the message (from), the name of the SMTP server that received the message (by), and the time at which the receiving server received the message.
Sometimes a single message may has multiple Received: header line and a more complex Return-Path: header line, because a message may be forwarded to more than one SMTP server in the path between sender and recipient.
e.g.
Received: from crepes.fr by hamburger.edu; 12 Oct 98
15:27:39 GMT
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Picture of yummy crepe.
MIME-Version: 1.0
Content-Transfer-Encoding: base64
Content-Type: image/jpeg
(base 64 encoded data …… base 64 encoded data)
Why the recipient’s user agent can’t use SMTP to obtain the message?
Because obtaining the message is a pull operation, whereas SMTP is a push protocol.
Mail access protocols transfers messages from recipient’s mail server to his/her local PC.
e.g. Post Office Protocol – Version 3 (POP3), Internet Mail Access Protocol (IMAP), HTTP.
POP3 protocol
POP3 begins when the client (user agent) establishes a TCP connection to the server (mail server) on port 110.
1) Authorization phases: The client sends a username and a password to authenticate the user
2) Transaction phase: The client can retrieve messages, mark messages for deletion, remove deletion marks, and obtain mail statistics.
The client can be configured to “download and delete” or to “download and keep”.
3) Update phase: Occurs after the client has issued the quit command, ending the POP3 session, and the server deletes the messages marked for deletion.
During a POP3 session, the server maintains state information (to keep track of which user message have been marked deleted), but does not carry state information across sessions.
IMAP protocol
IMAP is more complex than POP3.
An IMAP server associates each message with a folder. The IMAP protocol provides commands to allow users to create folders, move messages from one folder to another, search remote folders for messages matching specific criteria.
IMAP provides commands to allow users to obtain components of messages.
Web-based E-mail
With Web-based e-mail service, the user agent is an Web browser, the user communicate with its remote mailbox via HTTP.
The sender’s browser – (HTTP) → The sender’s mail server – (SMTP) → The recipient’s mail server – (HTTP) → The recipient’s browser.
DNS
The Internet’s domain name system (DNS) is 1) a distributed database implemented in a hierarchy of DNS servers and 2) an application-layer protocol (runs over UDP, uses port 53) that allows hosts to query the distributed database.
DNS services:
1.Translating hostnames to IP address;
DNS is commonly employed by other application-layer protocols (HTTP, SMTP, FTP ..) to translate hostnames to IP address.
2. Host aliasing;
An application can invoke DNS to obtain the canonical hostname for a supplied alias hostname (typically more mnemonic) as well as the IP address of the host.
3. Mail server aliasing
A mail application can invoke DNS to obtain the canonical hostname for a supplied alias hostname as well as the IP address of the host.
4. Load distribution
For replicate Web servers, a set of IP address is associated with one canonical host name.
When client makes a DNS query for a name mapped to a set of addresses, the server responds with the entire set of IP addresses, but rotates the ordering of the addresses within each reply, distributing the traffic among the replicated servers.
DNS rotation is also used for e-mail.
How DNS Works in hostname-to-IP-address translation
1) An application invokes the client side of DNS application running on the user’s host;
2) The DNS client sends a DNS query message containing the hostname to a DNS server in the network;
3) The DNS client receives a DNS reply message including the desired mapping.
4) The invoking application receives the mapping from the DNS client, so it can initiate a TCP connection to its server process.
(All DNS query and reply messages are sent within UDP datagrams to port 53.)
The DNS uses a large number of servers, organized in a hierarchical fashion and distributed around the world.
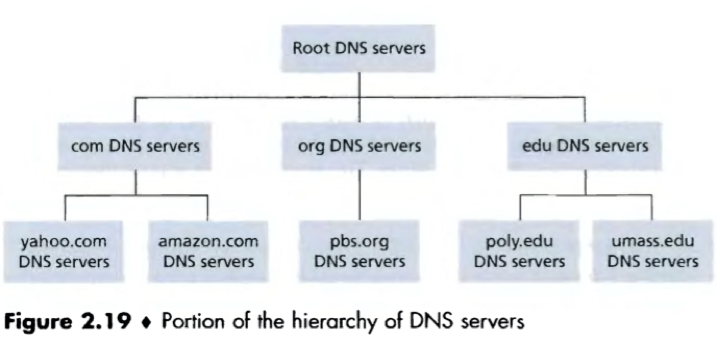
3 classes of DNS servers in the hierarchy:
1) Root DNS servers
2) Top-level domain (TLD) servers: are responsible for top-level domains (e.g. com, org, net, edu, gov) and all of the country top-level domains (e.g. uk, fr, ca, jp).
3) Authoritative DNS servers: Every organization with publicly accessible hosts on the Internet must provide publicly accessible DNS records that map the name of those hosts to IP addresses. An organization’s authoritative DNS server houses these DNS records.
Local DNS serer / default name server: (not strictly belong to the hierarchy) Each ISP has a local DNS server. When a host connecting to to an ISP makes a DNS query, the query is sent to the local DNS server, which acts a proxy, forwarding the query into the DNS server hierarchy.
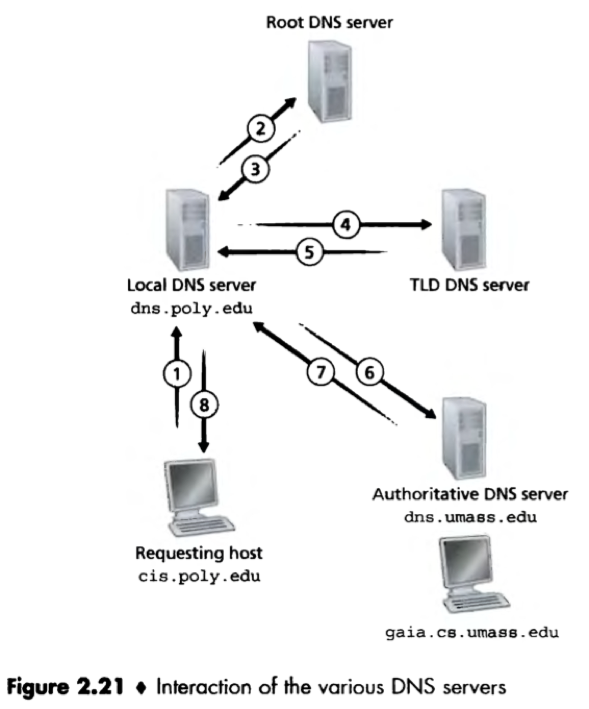
A typical DNS query chain:
1) The requesting host sends a DNS query message (containing the hostname to be translated, ‘gaia.cs.umass.edu’) to its local DNS server; [Recursive query]
2) The local DNS server forwards the query message to a root DNS server; [Iterative query]
3) The root DNS server takes note of the suffix (edu) and returns to the local DNS server a list of IP addresses for TLD servers responsible for that suffix;
4) The local DNS server resends the query message to one of these TLD servers; [Iterative query]
5) The TLD servers takes note of the suffix (umass.edu) and responds with the IP address of the authoritative DNS server for that suffix;
(In general, the TLD server may know only of an intermediate DNS server, which in turn knows the authoritative DNS server for the hostname.)
6) The local DNS server resends the query message to the authoritative DNS server; [Iterative query]
7) The authoritative DNS server responds with the IP address of the hostname to be translated.
Any DNS query can be iterative or recursive.
e.g. A DNS query chain for which all queries are recursive:
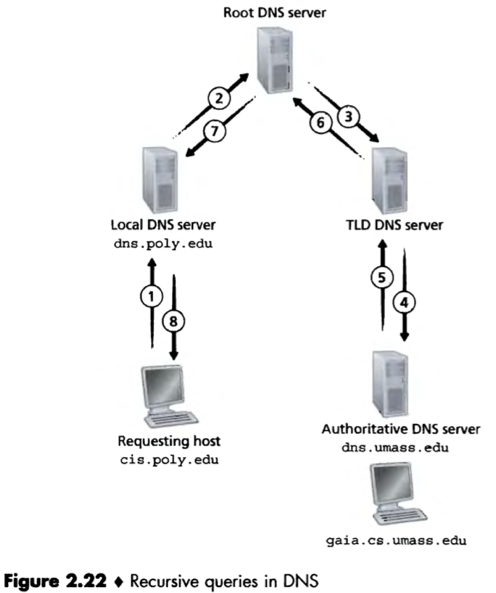
DNS caching: In a query chain, when a DNS server receives a DNS reply, it can cache the information contained in the reply in its local memory. In a period of time, if another query arrives to the DNS server for the same hostname, the DNS can provide the desired IP address (or the IP addresses of TLD servers) without having to query any other DNS servers.
(Can improve the delay performance, reduce the number of DNS messages ricocheting around the Internet.)
DNS Records
The DNS servers that together implements the DNS distributed database store resources records (RRs). Each DNS reply message carries one or more RRs.
A resource record is a four-tuple that contains: (Name, Value, Type, TTL).
TTL: The time to live of the resource record, determines when a resource should be removed from a cache.
The meaning of Name and Value depends on Type:
1) Type: A
Name: A hostname;
Value: IP address for the host-name.
A Type A record provides the standard hostname-to-IP address mapping.
e.g. (relay1.bar.foo.com, 145.37.93.126, A, TTL)
2) Type: NS
Name: A domain;
Value: The hostname of an authoritative DNS server that knows how to obtain the IP addresses for hosts in the domain.
A Type NS record is used to route DNS queries further along in the query chain.
e.g. (foo.com, dns.foo.com, NS, TTL)
3) Type: CNAME
Name: An alias hostname;
Value: The canonical hostname for the alias hostname.
e.g. (foo.com, relay1.bar.foo.com, CNAME, TTL)
4) Type: MX
Name: An alias hostname of a mail server
Value: The canonical name of the mail server
By using the MX record, a company can have the same aliased name for its mail server and for one of its other servers.
e.g. (foo.com, mail.bar.foo.com, MX, TTL)
DNS Messages
DNS messages includes DNS query message and DNS reply message, both of them have the same format.
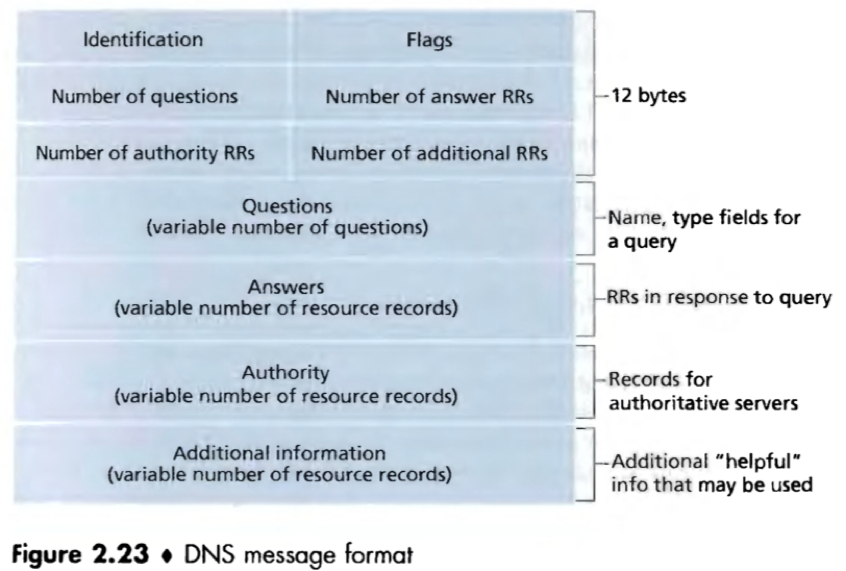
Header section(12 bytes), includes:
Identification field: 16-bit number that identifies the query. The identifier is also copied into the reply message, allowing the client to match received replies with sent queries.
Flags field: has a number of flags. (1) A 1-bit query/reply flag; (2) A 1-bit authoritative flag; (3) A 1-bit recursion-desired flag; (4) A 1-bit recursion-available flag.
The four number-of field indicate the number of occurrences of the four types of data sections that follow the header.
Question section: contains information about the query that is being made, includes (1) a name field that contains the name that is being queried; (2) A type field that indicates the type of question being asked about the name.
Answer section: In a reply from a DNS serer, the answer section contains the RRs for the name that was originally queried. A reply can return multiple RRs in the answer.
Authority section: contains the records of other authoritative servers.
Additional information section: contains other helpful records.
Peer-to-peer applications
P2P file distribution
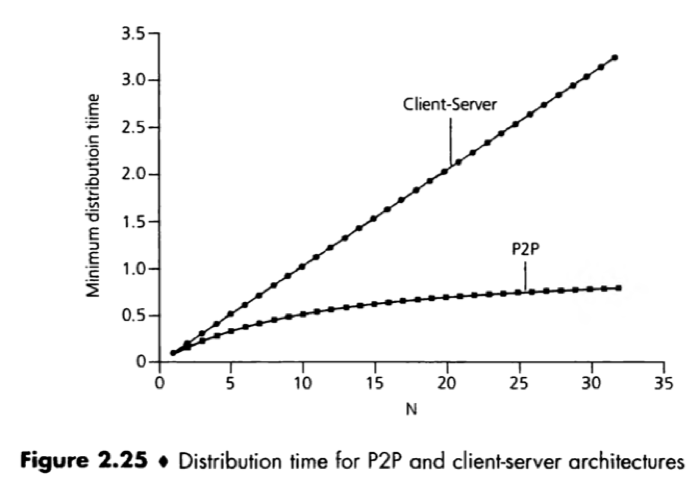
P2P file distribution: An application that distributes a file from a single source to a large number of peers. Each peer can redistribute any portion of the file it has received to any other peers, thereby assisting the server in the distribution process.
Application with the P2P architecture can be self-scaling. E.g.
BitTorrent: A popular P2P file distribution protocol for file distribution. Peers in a torrent download equal-size chunks of the file from one another, with a typical chunk size of 256 Kbytes.
Torrent: (In BitTorrent lingo) A torrent is the collection of all peers participating in the distribution of a particular file.
Tracker: An infrastructure node that each torrent has. When a peer joins a torrent, it registers itself with the tracker and periodically informs the tracker that it is still in the torrent. The tracker keeps track of the peers that are participating in the torrent.
When a new peer first joins a torrent, it has no chunks;
The tracker randomly selects a subset of peers from the set of participating peers, sends their IP addresses to the new peer.
The new peer attempts to establish concurrent TCP connections with all the peers on the list.
(Neighboring peers: Peers with which the new peer succeeds in establishing a TCP connection. A peer’s neighboring peers will fluctuate over time.)
Over time the peer accumulates more and more chunk, while it downloads it also upload chunks to other peers.
Once a peer has acquired the entire file, it may selfishly leave the torrent, or altruistically remain in the torrent and continue to upload chunks to other peers. (Any peer may leave the torrent at any time with only a subset of chunks, and later rejoin the torrent.)
At any given instant of time, the peer will have a subset of chunks and will know which chunks its neighbors have.
1) How to decide which chunks should it request first from its neighbors?
Use the rarest first technique – to determine, from among the chunks the peer does not have, the chunks that are the rarest (have the fewest repeated copies) among its neighbors, and then request the rarest chunks first.
[Aiming to equalize the numbers of copies of each chunk in the torrent.]
2) How to decide to which of its neighbors should it send requested chunks?
BitTorrent uses a clever trading algorithm – to gives priority to the neighbors that are currently supplying data to the node at the highest rate. Random neighbor selection allows new peers to get chunks, peers capable of uploading at compatible rates tend to find each other.
Searching for information in a P2P community
Information index: A mapping of information to host location, is a critical component of many P2P applications. In such application, the peers dynamically update and search the index.
(The BitTorrent protocol does not provide any functionality for indexing and searching for files.)
Three approaches for organizing and searching an index in a community of peers:
Centralized Index
The index service is provided by a large server (or a serer farm).
When a user launches the P2P application, the application informs the index server of its IP address and of the names of the files that it is making available for sharing. The index server collects this information from each peer that becomes active, creating a centralized, dynamic index that maps each file copy to a set of IP address.
A P2P file-sharing system with a centralized index is a hybrid of P2P [the file distribution] and client-server [the search] architectures.
Query flooding
The index is fully distributed over the community of peers.
Overlay network: An abstract, logical network formed by peers in query flooding. The graph consisting of all active peers and the connecting edges (ongoing TCP connections) defines the overlay network.
A given peer will typically be connected to a small number of other nodes, and send messages to neighboring peers in the overlay network over the pre-existing TCP connection.
When a peer receives a query, it checks to see whether the keyword matches any of the file it is making available for sharing. If there is a match, the peer sends a query-hit message to the requesting peer (using the pre-existing TCP connection on the reverse path of the query message).
Problem: non-scalable, significant amount of traffic.
Solution: Limited-scope query flooding – In a q query message, a peer-count field is set to a specific limit. When a peer receives a query with the peer-count field decreased to 0 (as forwarding), it stops forwarding the query.
Hierarchical overlay
Hierarchical overlay design combines features of centralized index and decentralized query flooding.
Super peers: Peers with high-bandwidth connections into the Internet and high availabilities. Ordinary peers is assigned as a child to a super peer.
Each super peer maintains an index that includes the identity of all files its children are sharing, meta-data about these files, and the corresponding IP addresses of children holding these files.
Super peers interconnect themselves with TCP connections, can forward queries to their neighboring super peers.
Distributed hash table (DHT): Another important design approach of searching in P2P community. DHT (1) creates a fully decentralized index that maps file identifiers to file locations and (2) allows a user to determine all the locations of file without generating an excessive amount of search traffic.
Socket programming with TCP
There are 2 sorts of network application:
1) An implementation of a public-domain protocol standard (e.g. defined in RFC). The client and server programs created by independent developers conform to rules dictated by the RFC so they can interoperate. (Use the port number associated with the protocol.)
2) A proprietary network application. The application-layer protocol does not necessarily conform to RFC, the developer creates both the client and server program. (be careful not to use one of the well-known port number defined in the RFC.)


Client socket: The client process can initiate a TCP connection to the server by creating a client socket. It specifies the IP address of the server host and the port number of the server process.
Three-way handshake: Once the client socket has been created, the TCP in the client initiates a three-way handshake and establishes a TCP connection with the server. (At the transport layer.)
During the three-way handshake, the client process contacts the server’s welcoming socket.
Connection socket: When the welcoming socket’s accept() method is invoked by the client process’s contact, the server creates a new, dedicated connection socket.
At the end of the handshaking phase, a TCP connection exists between the client socket and the the server’s connection socket.
Stream: A stream is a sequence of characters that flow into or out of a process. Each stream is either an input stream for the process or an output stream for the process.
TCP provides a reliable byte-stream service between the client and server processes.
import java.io.*;
import java.net.*;
class TCPClient {
public static void main(String argv[]) throws Exception {
String sentence;
String modifiedSentence;
//Input stream that read text from keyboard.
BufferedReader inFromUser = new BufferedReader(
new InputStreamReader(System.in));
/*create a client socket, initiates the TCP connection between client
and server, 'hostname' should be replace d with the host name of
the server.*/
Socket clientSocket = new Socket("hostname", 6789);
//Output stream that provides the process output to the socket
DataOutputStream outToServer = new DataOutputStream(
clientSocket.getOutputStream());
//Input stream that provides the process input from the socket
BufferedReader inFromServer =
new BufferedReader(new InputStreamReader(
clientSocket.getInputStream()));
//Place a line typed by the user into the string 'sentence'
sentence = inFromUser.readLine();
//Send the sentence into the output stream 'outToServer'
outToServer.writeBytes(sentence+'
');
/*place the characters from the server through the input stream
'inFromServer' into the string 'modifiedSentence'.*/
modifiedSentence = inFromServer.readLine();
System.out.println("FROM SERVER: " +
modifiedSentence);
clientSocket.close();
}
}
import java.io.*;
import java.net.*;
public class TCPServer {
public static void main(String argv[]) throws Exception {
String clientSentence;
String capitalizedSentence;
//create a welcome socket listening on port 6789
ServerSocket welcomeSocket = new ServerSocket(6789);
while (true) {
/*create a connection socket, also has port 6789.
TCP then establishes a direct virtual pipe between
clientSocket (at client) and the connectionSocket (at server).*/
Socket connectionSocket = welcomeSocket.accept();
BufferedReader inFromClient =
new BufferedReader(new InputStreamReader(
connectionSocket.getInputStream()));
DataOutputStream outToClient =
new DataOutputStream(
connectionSocket.getOutputStream());
clientSentence = inFromClient.readLine();
//take the line sent by the client and caplitalize it
capitalizedSentence =
clientSentence.toUpperCase()+'
';
outToClient.writeBytes(capitalizedSentence);
}
}
}


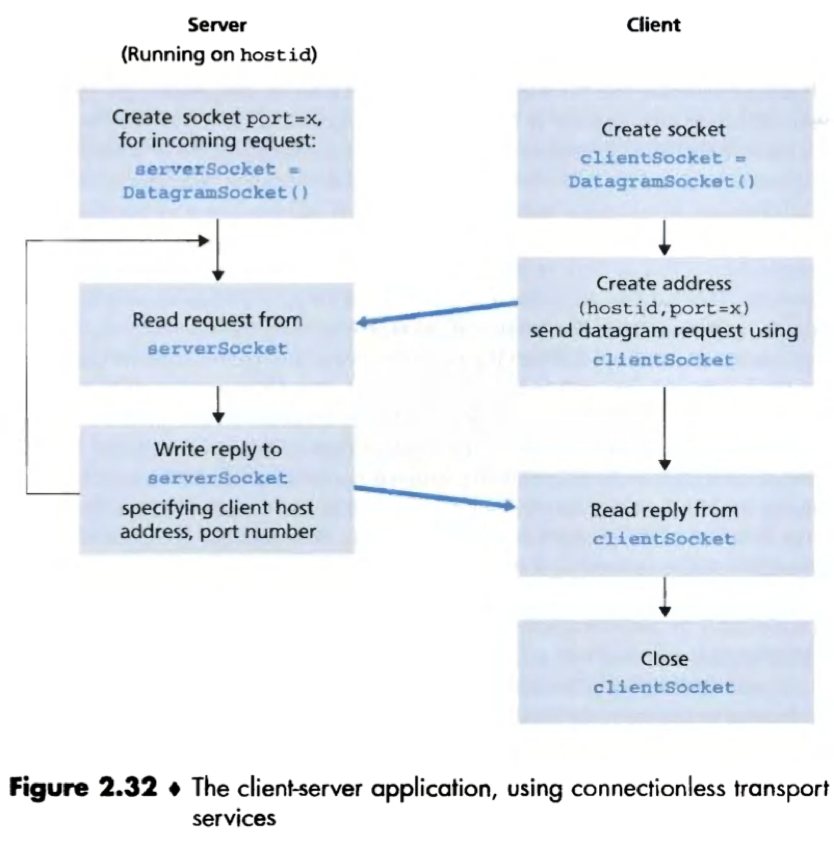
Socket programming with UDP
Socket programming with UDP is different from TCP.
1) No initial handshaking (so no welcoming socket).
2) No streams are attached to the sockets;
3) The sending hosts create packets by attaching the IP destination address and port number to each batch of bytes it sends;
4) The receiving process must unravel each received packet to obtain the packet’s information bytes.
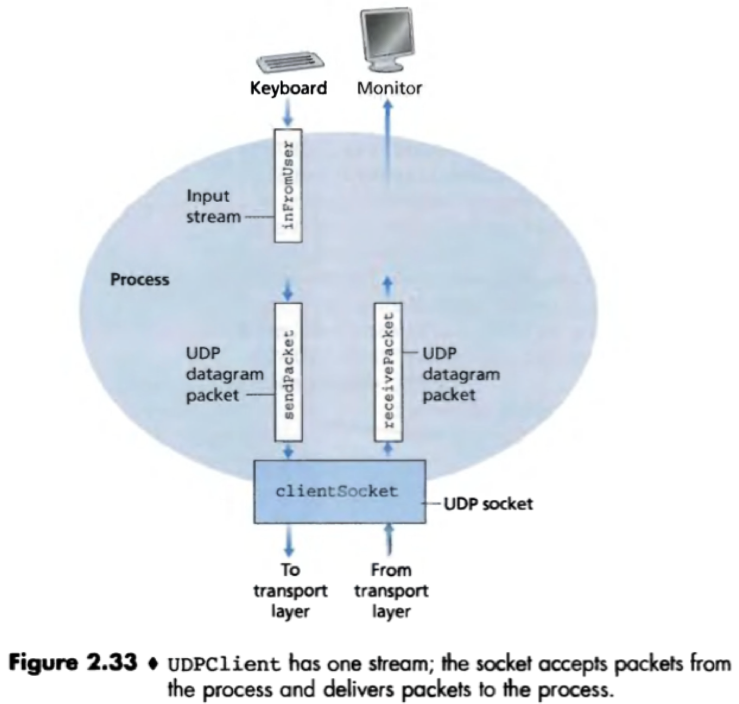
import java.io.*;
import java.net.*;
public class UDPClient {
public static void main(String args[]) throws Exception {
//input stream that read text from keyboard
BufferedReader inFromUser =
new BufferedReader(new InputStreamReader(System.in));
/*create a client socket but no TCP connection (connectionless)
thus no hostname or port number arguments.*/
DatagramSocket clientSocket = new DatagramSocket();
//invoke a DNS lookup, translate hostname to an IP address
InetAddress IPAddress = InetAddress.getByName("hostname");
byte[] sendData = new byte[1024];
byte[] receiveData = new byte[1024];
String sentence = inFromUser.readLine();
sendData = sentence.getBytes();
//construct the packet to send
DatagramPacket sendPacket =
new DatagramPacket(sendData, sendData.length, IPAddress, 9876);
//pop the packet into the network through the client socket
clientSocket.send(sendPacket);
//create a placeholder for the packet from the server
DatagramPacket receivePacket =
new DatagramPacket(receiveData, receiveData.length);
//idle until receives a packet, puts the packet in receivePacket.
clientSocket.receive(receivePacket);
//extract data from the packet, convert into string
String modifiedSentence = new String(receivePacket.getData());
System.out.println("From SERVER:"+modifiedSentence);
clientSocket.close();
}
}
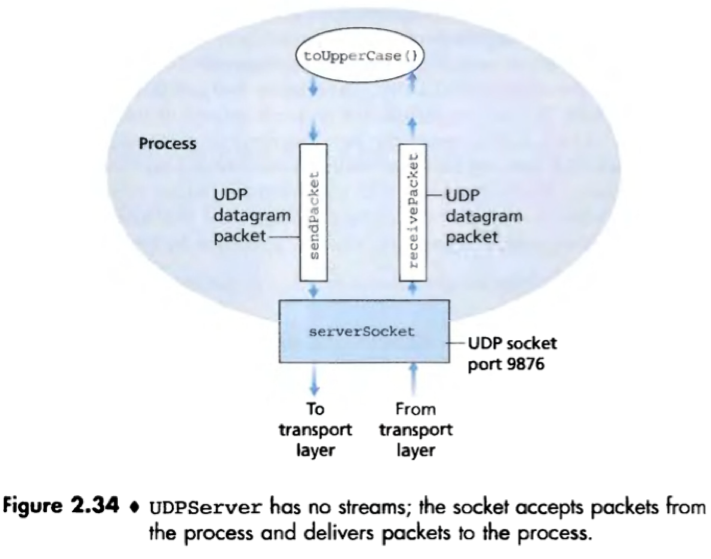
import java.io.*;
import java.net.*;
public class UDPServer {
public static void main(String args[]) throws Exception {
//all data sent and received pass through the serverSocket
DatagramSocket serverSocket = new DatagramSocket(9876);
byte[] receiveData = new byte[1024];
byte[] sendData = new byte[1024];
while (true) {
DatagramPacket receivePacket =
new DatagramPacket(receiveData, receiveData.length);
serverSocket.receive(receivePacket);
/*unravel the packet sent from the client
extract data, IP address and the client port number.
*/
String sentence = new String(receivePacket.getData());
InetAddress IPAddress = receivePacket.getAddress();
/*The port number is chosen by the client, and is different
from the sever port number(9876).*/
int port = receivePacket.getPort();
String capitalizedSentence = sentence.toUpperCase();
sendData = capitalizedSentence.getBytes();
DatagramPacket sendPacket =
new DatagramPacket(sendData, sendData.length, IPAddress, port);
serverSocket.send(sendPacket);
}
}
}