本文详细说明,如何使用 tensorrt C++ API搭建MPL网络,实现推理,帮助与我类似的小白更快上手C++ 版本的方法,我将介绍内容为: 简单介绍、visual studio如何配置、MLP网络搭建步骤及详细说明、原始代码与改编代码。
同篇关联python API文章为:https://www.cnblogs.com/tangjunjun/p/16154788.html
一.简单介绍
TensorRT是英伟达针对自家平台做的一个加速包,可以认为 TensorRT 是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,TensorFlow 的网络模型解析,然后与 TensorRT 中对应的层进行一一映射,把其他框架的模型统一全部转换到 TensorRT 中,然后在 TensorRT 中可以针对 NVIDIA 自家 GPU 实施优化策略,并进行部署加速。根据官方文档,使用TensorRT,在CPU或者GPU模式下其可提供10X乃至100X的加速。本人的实际经验中,TensorRT提供了20X的加速
TensorRT主要做了这么两件事情,来提升模型的运行速度:
- TensorRT支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的
- TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化
二.visual studio的环境配置
简单介绍visual studio的环境配置,前提条件你已经将tensorrt库相应放在cuda文件夹下了:
①选择项目——>xxxx(你的项目名称)属性——>VC++目录——>包含目录,添加库文件路径;
如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\include
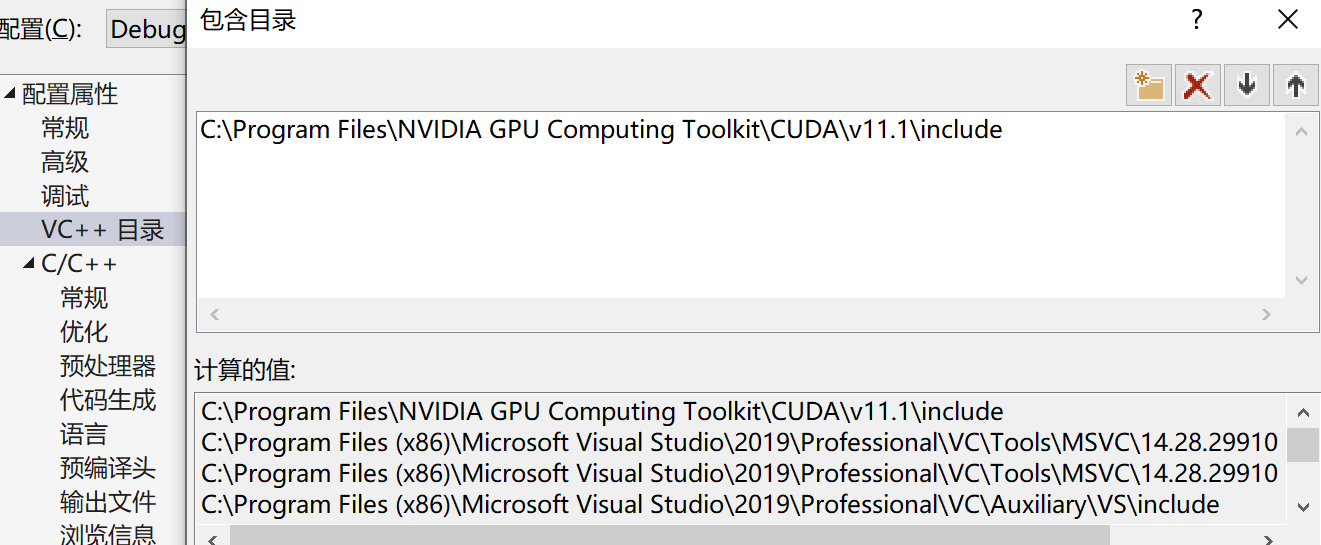
②选择项目——>xxxx(你的项目名称)属性——>VC++目录——>库目录,添加库文件路径;
如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib\x64
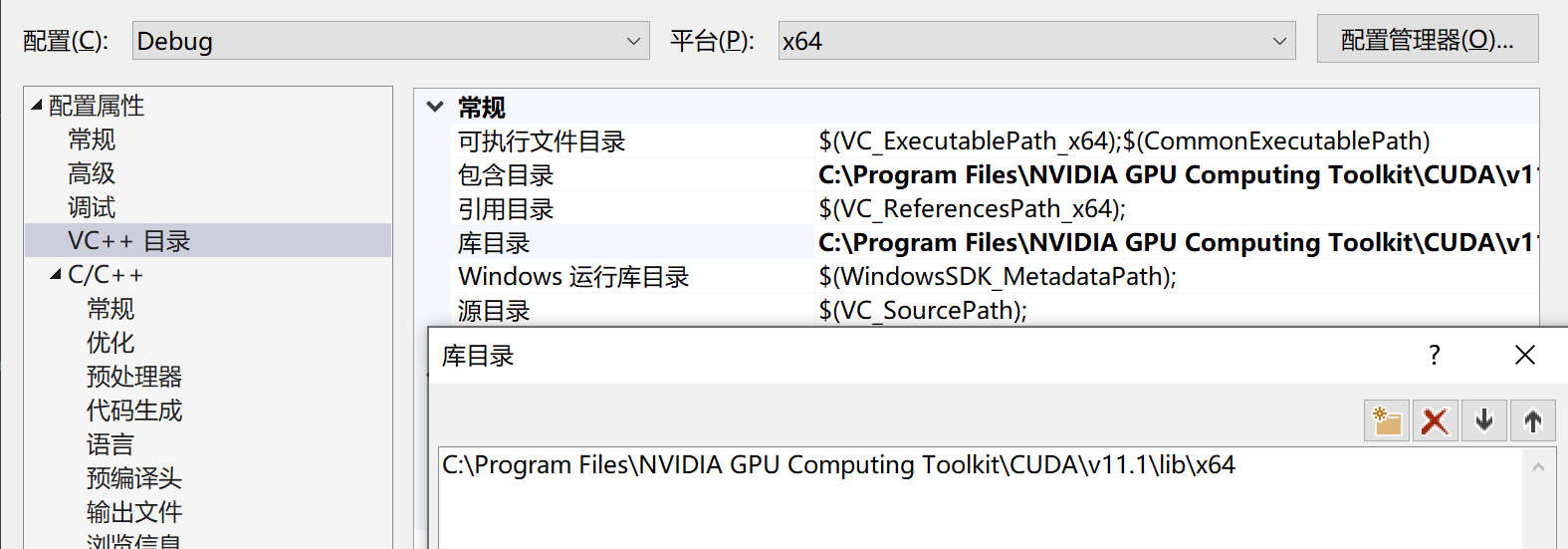
③选择项目——>xxxx(你的项目名称)属性——>链接器——>输入——>附加依赖项,添加以下文件;
nvinfer.lib
nvinfer_plugin.lib
cudart.lib

三.tensorrt C++ API 以搭建MLP网络结构,详细说明步骤:
需引用头文件如下:
#include "NvInferRuntimeCommon.h" #include <cassert> #include "NvInfer.h" // TensorRT library #include "iostream" // Standard input/output library #include <map> // for weight maps #include <fstream> // for file-handling #include <chrono> // for timing the execution
构建引擎engine,并将其保存为文件形式
①构建glogging,为创建builder做准备,简单创建代码如下:
class Logger : public nvinfer1::ILogger
{
void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity != Severity::kINFO)
std::cout << msg << std::endl;
}
} gLogger;
②创建builder,使用gLogger
IBuilder* builder = createInferBuilder(gLogger); // Create builder with the help of logger 构建builder
③构建网络
INetworkDefinition* network = builder->createNetworkV2(0U); //创造网络
网络构建完毕后,需为网络添加结构,可以使用onnx/caffe/uft解析添加网络,但本篇博客使用C++ API 构建网络,如下:
ITensor* data = network->addInput("data", DataType::kFLOAT, Dims3{ 1, 1, 1 });// Create an input with proper *name 创建输入,参数:名称 类型 维度
IFullyConnectedLayer* fc1 = network->addFullyConnected(*data, 1, weightMap["linear.weight"], weightMap["linear.bias"]); // Add layer for MLP 参数:输入 输出 w权重 b权重
fc1->getOutput(0)->setName("out"); // set output with *name 设置fc1层的输出,(对特殊的网络层通过ITensor->setName()方法设定名称,方便后面的操作);指定网络的output节点,tensorrt必须指定输出节点,否则有可能会在优化过程中将该节点优化掉
network->markOutput(*fc1->getOutput(0)); //设为网络的输出,防止被优化掉
其中weightMap为权重保存变量,类似一个字典
④设置网络参数
调用TensorRT的builder来创建优化的runtime。 builder的其中一个功能是搜索其CUDA内核目录以获得最快的实现,因此用来构建优化的engine的GPU设备和实际跑的GPU设备一定要是相同的才行,这也是为什么无法适应其它环境原因。
builder具有许多属性,可以通过设置这些属性来控制网络运行的精度,以及自动调整参数。还可以查询builder以找出硬件本身支持的降低的精度类型。
有个特别重要的属性,最大batch size :大batch size指定TensorRT将要优化的batch大小。在运行时,只能选择比这个值小的batch。
config有个workspace size:各种layer算法通常需要临时工作空间。这个参数限制了网络中所有的层可以使用的最大的workspace空间大小。 如果分配的空间不足,TensorRT可能无法找到给定层的实现。
IBuilderConfig* config = builder->createBuilderConfig(); // Create hardware configs为builder分配内存,默认全部分配
builder->setMaxBatchSize(1); // Set configurations config->setMaxWorkspaceSize(1 << 20); // Set workspace size
⑤创建引擎engine
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);// Build CUDA Engine using network and configurations
network->destroy();//顺带销毁网络,释放内存
⑥引擎engine序列化
IHostMemory** modelStream;//引擎变量声明,并保存序列化结果 (*modelStream) = engine->serialize(); //调用序列化方法
⑦释放内存
engine->destroy(); //释放engine结构 builder->destroy();//释放builder结构
⑧保存序列化引擎
// Open the file and write the contents there in binary format
std::ofstream p(file_engine, std::ios::binary);
if (!p) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
p.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size());
其中modelStream为序列化的变量,file_engine为保存engine的地址,如:"C:\\Users\\Administrator\\Desktop\\code\\tensorrt-code\\mlp\\mlp.wts"
⑨释放序列化内存
modelStream->destroy();
以上为tensorrt C++ API 将网络编译成engine,并保存的全部流程,若后续更改不同网络,主要更改步骤③构建网络模块。
重载引擎文件,并实现推理:
①读取引擎engine
char* trtModelStream{ nullptr }; //指针函数,创建保存engine序列化文件结果
size_t size{ 0 };
// read model from the engine file
std::ifstream file(file_engine, std::ios::binary);
if (file.good()) {
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
}
其中file_engine为:file_engine = "C:\\Users\\Administrator\\Desktop\\code\\tensorrt-code\\mlp\\mlp.engine"
②反序列化
// create a runtime (required for deserialization of model) with NVIDIA's logger
IRuntime* runtime = createInferRuntime(gLogger); //反序列化方法
assert(runtime != nullptr);
// deserialize engine for using the char-stream
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr);
assert(engine != nullptr);
/*
一个engine可以有多个execution context,并允许将同一套weights用于多个推理任务。可以在并行的CUDA streams流中按每个stream流一个engine和一个context来处理图像。每个context在engine相同的GPU上创建。
*/
runtime->destroy(); //顺道销毁runtime,释放内存
其中gLogger来源创建引擎构建的glogging
以上为初始化过程,从以下为实施推理过程
③构建可执行方法
IExecutionContext* context = engine->createExecutionContext(); // create execution context -- required for inference executions
④设置输入输出
float out[1]; // array for output
float data[1]; // array for input
for (float& i : data)
i = 12.0; // put any value for input
⑤调用推理
// do inference using the parameters
doInference(*context, data, out, 1);
void doInference(IExecutionContext& context, float* input, float* output, int batchSize) {
const ICudaEngine& engine = context.getEngine(); // Get engine from the context
// Pointers to input and output device buffers to pass to engine.
void* buffers[2]; // Engine requires exactly IEngine::getNbBindings() number of buffers.
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine.getBindingIndex("data");
const int outputIndex = engine.getBindingIndex("out");
// Create GPU buffers on device -- allocate memory for input and output
cudaMalloc(&buffers[inputIndex], batchSize * INPUT_SIZE * sizeof(float));
cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float));
// create CUDA stream for simultaneous CUDA operations
cudaStream_t stream;
cudaStreamCreate(&stream);
// copy input from host (CPU) to device (GPU) in stream
cudaMemcpyAsync(buffers[inputIndex], input, batchSize * INPUT_SIZE * sizeof(float), cudaMemcpyHostToDevice, stream);
// execute inference using context provided by engine
context.enqueue(batchSize, buffers, stream, nullptr);//*******************************************************************************************************************重点推理****************
// copy output back from device (GPU) to host (CPU)
cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost,
stream);
// synchronize the stream to prevent issues (block CUDA and wait for CUDA operations to be completed)
cudaStreamSynchronize(stream);
// Release stream and buffers (memory)
cudaStreamDestroy(stream);
cudaFree(buffers[inputIndex]);
cudaFree(buffers[outputIndex]);
}
以上为tensorrt实现推理过程
四.代码部分
Ⅰ.权重加载代码说明及wts文件说名:
Tensorrt对权重的使用-->如何保存tensorrt的权重文件wts,如何使用C++加载权重wts文件
①保存权重.wts文件说明:
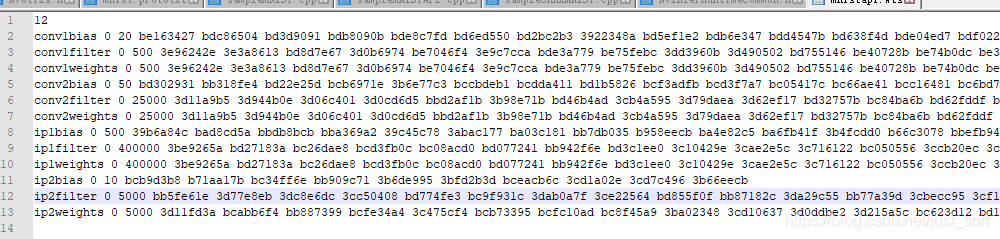
12 表示保存12个层
conv1bias就是第一个卷积层的偏置系数,后面的0指的是 kFLOAT 类型,也就是float 32;后面的20是系数的个数,因为输出是20,所以偏置是20个;
convlfiter是卷积核的系数,因为是20个5 x 5的卷积核,所以有20 x 5 x 5=500个参数。
你用相应工具解析解析模型将层名和权值参数键值对存到这个文件中就可以了。
②C++如何调用权重wts
/*
Weights是类别类型
class Weights
{
public:
DataType type; //!< The type of the weights.
const void* values; //!< The weight values, in a contiguous array.
int64_t count; //!< The number of weights in the array.
};
*/
//file为文件路径
std::map<std::string, Weights> loadWeights(const std::string file) {
/**
* Parse the .wts file and store weights in dict format.
*
* @param file path to .wts file
* @return weight_map: dictionary containing weights and their values
*/
std::cout << "[INFO]: Loading weights..." << file << std::endl;
std::map<std::string, Weights> weightMap; //定义声明
// Open Weight file
std::ifstream input(file);
assert(input.is_open() && "[ERROR]: Unable to load weight file...");
// Read number of weights
int32_t count;
input >> count;
assert(count > 0 && "Invalid weight map file.");
// Loop through number of line, actually the number of weights & biases
while (count--) {
// TensorRT weights
Weights wt{DataType::kFLOAT, nullptr, 0};
uint32_t size;
// Read name and type of weights
std::string w_name;
input >> w_name >> std::dec >> size;
wt.type = DataType::kFLOAT;
uint32_t *val = reinterpret_cast<uint32_t *>(malloc(sizeof(val) * size));
for (uint32_t x = 0, y = size; x < y; ++x) {
// Change hex values to uint32 (for higher values)
input >> std::hex >> val[x]; //hex为16进制
}
wt.values = val;
wt.count = size;
// Add weight values against its name (key)
weightMap[w_name] = wt; //将权重结果保存此处
}
return weightMap;
}
Ⅱ.原始代码如下:
使用tensorrt C++ API 编写mlp推理,需要三个文件,头文件logging.h,源文件mlp.cpp,权重文件wts。
以下将给出这三个文件:
头文件 logging.h


/* * Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ #ifndef TENSORRT_LOGGING_H #define TENSORRT_LOGGING_H #include "NvInferRuntimeCommon.h" #include <cassert> #include <ctime> #include <iomanip> #include <iostream> #include <ostream> #include <sstream> #include <string> //using namespace nvinfer1; using Severity = nvinfer1::ILogger::Severity; class LogStreamConsumerBuffer : public std::stringbuf { public: LogStreamConsumerBuffer(std::ostream& stream, const std::string& prefix, bool shouldLog) : mOutput(stream) , mPrefix(prefix) , mShouldLog(shouldLog) { } LogStreamConsumerBuffer(LogStreamConsumerBuffer&& other) : mOutput(other.mOutput) { } ~LogStreamConsumerBuffer() { // std::streambuf::pbase() gives a pointer to the beginning of the buffered part of the output sequence // std::streambuf::pptr() gives a pointer to the current position of the output sequence // if the pointer to the beginning is not equal to the pointer to the current position, // call putOutput() to log the output to the stream if (pbase() != pptr()) { putOutput(); } } // synchronizes the stream buffer and returns 0 on success // synchronizing the stream buffer consists of inserting the buffer contents into the stream, // resetting the buffer and flushing the stream virtual int sync() { putOutput(); return 0; } void putOutput() { if (mShouldLog) { // prepend timestamp std::time_t timestamp = std::time(nullptr); tm* tm_local = std::localtime(×tamp); std::cout << "["; std::cout << std::setw(2) << std::setfill('0') << 1 + tm_local->tm_mon << "/"; std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_mday << "/"; std::cout << std::setw(4) << std::setfill('0') << 1900 + tm_local->tm_year << "-"; std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_hour << ":"; std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_min << ":"; std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_sec << "] "; // std::stringbuf::str() gets the string contents of the buffer // insert the buffer contents pre-appended by the appropriate prefix into the stream mOutput << mPrefix << str(); // set the buffer to empty str(""); // flush the stream mOutput.flush(); } } void setShouldLog(bool shouldLog) { mShouldLog = shouldLog; } private: std::ostream& mOutput; std::string mPrefix; bool mShouldLog; }; //! //! \class LogStreamConsumerBase //! \brief Convenience object used to initialize LogStreamConsumerBuffer before std::ostream in LogStreamConsumer //! class LogStreamConsumerBase { public: LogStreamConsumerBase(std::ostream& stream, const std::string& prefix, bool shouldLog) : mBuffer(stream, prefix, shouldLog) { } protected: LogStreamConsumerBuffer mBuffer; }; //! //! \class LogStreamConsumer //! \brief Convenience object used to facilitate use of C++ stream syntax when logging messages. //! Order of base classes is LogStreamConsumerBase and then std::ostream. //! This is because the LogStreamConsumerBase class is used to initialize the LogStreamConsumerBuffer member field //! in LogStreamConsumer and then the address of the buffer is passed to std::ostream. //! This is necessary to prevent the address of an uninitialized buffer from being passed to std::ostream. //! Please do not change the order of the parent classes. //! class LogStreamConsumer : protected LogStreamConsumerBase, public std::ostream { public: //! \brief Creates a LogStreamConsumer which logs messages with level severity. //! Reportable severity determines if the messages are severe enough to be logged. LogStreamConsumer(Severity reportableSeverity, Severity severity) : LogStreamConsumerBase(severityOstream(severity), severityPrefix(severity), severity <= reportableSeverity) , std::ostream(&mBuffer) // links the stream buffer with the stream , mShouldLog(severity <= reportableSeverity) , mSeverity(severity) { } LogStreamConsumer(LogStreamConsumer&& other) : LogStreamConsumerBase(severityOstream(other.mSeverity), severityPrefix(other.mSeverity), other.mShouldLog) , std::ostream(&mBuffer) // links the stream buffer with the stream , mShouldLog(other.mShouldLog) , mSeverity(other.mSeverity) { } void setReportableSeverity(Severity reportableSeverity) { mShouldLog = mSeverity <= reportableSeverity; mBuffer.setShouldLog(mShouldLog); } private: static std::ostream& severityOstream(Severity severity) { return severity >= Severity::kINFO ? std::cout : std::cerr; } static std::string severityPrefix(Severity severity) { switch (severity) { case Severity::kINTERNAL_ERROR: return "[F] "; case Severity::kERROR: return "[E] "; case Severity::kWARNING: return "[W] "; case Severity::kINFO: return "[I] "; case Severity::kVERBOSE: return "[V] "; default: assert(0); return ""; } } bool mShouldLog; Severity mSeverity; }; //! \class Logger //! //! \brief Class which manages logging of TensorRT tools and samples //! //! \details This class provides a common interface for TensorRT tools and samples to log information to the console, //! and supports logging two types of messages: //! //! - Debugging messages with an associated severity (info, warning, error, or internal error/fatal) //! - Test pass/fail messages //! //! The advantage of having all samples use this class for logging as opposed to emitting directly to stdout/stderr is //! that the logic for controlling the verbosity and formatting of sample output is centralized in one location. //! //! In the future, this class could be extended to support dumping test results to a file in some standard format //! (for example, JUnit XML), and providing additional metadata (e.g. timing the duration of a test run). //! //! TODO: For backwards compatibility with existing samples, this class inherits directly from the nvinfer1::ILogger //! interface, which is problematic since there isn't a clean separation between messages coming from the TensorRT //! library and messages coming from the sample. //! //! In the future (once all samples are updated to use Logger::getTRTLogger() to access the ILogger) we can refactor the //! class to eliminate the inheritance and instead make the nvinfer1::ILogger implementation a member of the Logger //! object. class Logger : public nvinfer1::ILogger { public: Logger(Severity severity = Severity::kWARNING) : mReportableSeverity(severity) { } //! //! \enum TestResult //! \brief Represents the state of a given test //! enum class TestResult { kRUNNING, //!< The test is running kPASSED, //!< The test passed kFAILED, //!< The test failed kWAIVED //!< The test was waived }; //! //! \brief Forward-compatible method for retrieving the nvinfer::ILogger associated with this Logger //! \return The nvinfer1::ILogger associated with this Logger //! //! TODO Once all samples are updated to use this method to register the logger with TensorRT, //! we can eliminate the inheritance of Logger from ILogger //! nvinfer1::ILogger& getTRTLogger() { return *this; } //! //! \brief Implementation of the nvinfer1::ILogger::log() virtual method //! //! Note samples should not be calling this function directly; it will eventually go away once we eliminate the //! inheritance from nvinfer1::ILogger //! void log(Severity severity, const char* msg) noexcept override { LogStreamConsumer(mReportableSeverity, severity) << "[TRT] " << std::string(msg) << std::endl; } //! //! \brief Method for controlling the verbosity of logging output //! //! \param severity The logger will only emit messages that have severity of this level or higher. //! void setReportableSeverity(Severity severity) { mReportableSeverity = severity; } //! //! \brief Opaque handle that holds logging information for a particular test //! //! This object is an opaque handle to information used by the Logger to print test results. //! The sample must call Logger::defineTest() in order to obtain a TestAtom that can be used //! with Logger::reportTest{Start,End}(). //! class TestAtom { public: TestAtom(TestAtom&&) = default; private: friend class Logger; TestAtom(bool started, const std::string& name, const std::string& cmdline) : mStarted(started) , mName(name) , mCmdline(cmdline) { } bool mStarted; std::string mName; std::string mCmdline; }; //! //! \brief Define a test for logging //! //! \param[in] name The name of the test. This should be a string starting with //! "TensorRT" and containing dot-separated strings containing //! the characters [A-Za-z0-9_]. //! For example, "TensorRT.sample_googlenet" //! \param[in] cmdline The command line used to reproduce the test // //! \return a TestAtom that can be used in Logger::reportTest{Start,End}(). //! static TestAtom defineTest(const std::string& name, const std::string& cmdline) { return TestAtom(false, name, cmdline); } //! //! \brief A convenience overloaded version of defineTest() that accepts an array of command-line arguments //! as input //! //! \param[in] name The name of the test //! \param[in] argc The number of command-line arguments //! \param[in] argv The array of command-line arguments (given as C strings) //! //! \return a TestAtom that can be used in Logger::reportTest{Start,End}(). static TestAtom defineTest(const std::string& name, int argc, char const* const* argv) { auto cmdline = genCmdlineString(argc, argv); return defineTest(name, cmdline); } //! //! \brief Report that a test has started. //! //! \pre reportTestStart() has not been called yet for the given testAtom //! //! \param[in] testAtom The handle to the test that has started //! static void reportTestStart(TestAtom& testAtom) { reportTestResult(testAtom, TestResult::kRUNNING); assert(!testAtom.mStarted); testAtom.mStarted = true; } //! //! \brief Report that a test has ended. //! //! \pre reportTestStart() has been called for the given testAtom //! //! \param[in] testAtom The handle to the test that has ended //! \param[in] result The result of the test. Should be one of TestResult::kPASSED, //! TestResult::kFAILED, TestResult::kWAIVED //! static void reportTestEnd(const TestAtom& testAtom, TestResult result) { assert(result != TestResult::kRUNNING); assert(testAtom.mStarted); reportTestResult(testAtom, result); } static int reportPass(const TestAtom& testAtom) { reportTestEnd(testAtom, TestResult::kPASSED); return EXIT_SUCCESS; } static int reportFail(const TestAtom& testAtom) { reportTestEnd(testAtom, TestResult::kFAILED); return EXIT_FAILURE; } static int reportWaive(const TestAtom& testAtom) { reportTestEnd(testAtom, TestResult::kWAIVED); return EXIT_SUCCESS; } static int reportTest(const TestAtom& testAtom, bool pass) { return pass ? reportPass(testAtom) : reportFail(testAtom); } Severity getReportableSeverity() const { return mReportableSeverity; } private: //! //! \brief returns an appropriate string for prefixing a log message with the given severity //! static const char* severityPrefix(Severity severity) { switch (severity) { case Severity::kINTERNAL_ERROR: return "[F] "; case Severity::kERROR: return "[E] "; case Severity::kWARNING: return "[W] "; case Severity::kINFO: return "[I] "; case Severity::kVERBOSE: return "[V] "; default: assert(0); return ""; } } //! //! \brief returns an appropriate string for prefixing a test result message with the given result //! static const char* testResultString(TestResult result) { switch (result) { case TestResult::kRUNNING: return "RUNNING"; case TestResult::kPASSED: return "PASSED"; case TestResult::kFAILED: return "FAILED"; case TestResult::kWAIVED: return "WAIVED"; default: assert(0); return ""; } } //! //! \brief returns an appropriate output stream (cout or cerr) to use with the given severity //! static std::ostream& severityOstream(Severity severity) { return severity >= Severity::kINFO ? std::cout : std::cerr; } //! //! \brief method that implements logging test results //! static void reportTestResult(const TestAtom& testAtom, TestResult result) { severityOstream(Severity::kINFO) << "&&&& " << testResultString(result) << " " << testAtom.mName << " # " << testAtom.mCmdline << std::endl; } //! //! \brief generate a command line string from the given (argc, argv) values //! static std::string genCmdlineString(int argc, char const* const* argv) { std::stringstream ss; for (int i = 0; i < argc; i++) { if (i > 0) ss << " "; ss << argv[i]; } return ss.str(); } Severity mReportableSeverity; }; namespace { //! //! \brief produces a LogStreamConsumer object that can be used to log messages of severity kVERBOSE //! //! Example usage: //! //! LOG_VERBOSE(logger) << "hello world" << std::endl; //! inline LogStreamConsumer LOG_VERBOSE(const Logger& logger) { return LogStreamConsumer(logger.getReportableSeverity(), Severity::kVERBOSE); } //! //! \brief produces a LogStreamConsumer object that can be used to log messages of severity kINFO //! //! Example usage: //! //! LOG_INFO(logger) << "hello world" << std::endl; //! inline LogStreamConsumer LOG_INFO(const Logger& logger) { return LogStreamConsumer(logger.getReportableSeverity(), Severity::kINFO); } //! //! \brief produces a LogStreamConsumer object that can be used to log messages of severity kWARNING //! //! Example usage: //! //! LOG_WARN(logger) << "hello world" << std::endl; //! inline LogStreamConsumer LOG_WARN(const Logger& logger) { return LogStreamConsumer(logger.getReportableSeverity(), Severity::kWARNING); } //! //! \brief produces a LogStreamConsumer object that can be used to log messages of severity kERROR //! //! Example usage: //! //! LOG_ERROR(logger) << "hello world" << std::endl; //! inline LogStreamConsumer LOG_ERROR(const Logger& logger) { return LogStreamConsumer(logger.getReportableSeverity(), Severity::kERROR); } //! //! \brief produces a LogStreamConsumer object that can be used to log messages of severity kINTERNAL_ERROR // ("fatal" severity) //! //! Example usage: //! //! LOG_FATAL(logger) << "hello world" << std::endl; //! inline LogStreamConsumer LOG_FATAL(const Logger& logger) { return LogStreamConsumer(logger.getReportableSeverity(), Severity::kINTERNAL_ERROR); } } // anonymous namespace #endif // TENSORRT_LOGGING_H
源文件mlp.cpp
#include "NvInfer.h" // TensorRT library #include "iostream" // Standard input/output library #include "logging.h" // logging file -- by NVIDIA #include <map> // for weight maps #include <fstream> // for file-handling #include <chrono> // for timing the execution // provided by nvidia for using TensorRT APIs using namespace nvinfer1; // Logger from TRT API static Logger gLogger; const int INPUT_SIZE = 1; const int OUTPUT_SIZE = 1; /*******************************************************构建engine将其序列化并保存*******************************************************************************/ /* Weights是类别类型 class Weights { public: DataType type; //!< The type of the weights. const void* values; //!< The weight values, in a contiguous array. int64_t count; //!< The number of weights in the array. }; */ //载入权重函数 std::map<std::string, Weights> loadWeights(const std::string file) { /** * Parse the .wts file and store weights in dict format. * * @param file path to .wts file * @return weight_map: dictionary containing weights and their values */ std::cout << "[INFO]: Loading weights..." << file << std::endl; std::map<std::string, Weights> weightMap; //定义声明 // Open Weight file std::ifstream input(file); assert(input.is_open() && "[ERROR]: Unable to load weight file..."); // Read number of weights int32_t count; input >> count; assert(count > 0 && "Invalid weight map file."); // Loop through number of line, actually the number of weights & biases while (count--) { // TensorRT weights Weights wt{DataType::kFLOAT, nullptr, 0}; uint32_t size; // Read name and type of weights std::string w_name; input >> w_name >> std::dec >> size; wt.type = DataType::kFLOAT; uint32_t *val = reinterpret_cast<uint32_t *>(malloc(sizeof(val) * size)); for (uint32_t x = 0, y = size; x < y; ++x) { // Change hex values to uint32 (for higher values) input >> std::hex >> val[x]; //hex为16进制 } wt.values = val; wt.count = size; // Add weight values against its name (key) weightMap[w_name] = wt; //将权重结果保存此处 } return weightMap; } //构建engine函数 ICudaEngine *createMLPEngine(unsigned int maxBatchSize, IBuilder *builder, IBuilderConfig *config, DataType dt, const std::string file_wts) { /** * Create Multi-Layer Perceptron using the TRT Builder and Configurations * * @param maxBatchSize: batch size for built TRT model * @param builder: to build engine and networks * @param config: configuration related to Hardware * @param dt: datatype for model layers * @return engine: TRT model */ //std::cout << "[INFO]: Creating MLP using TensorRT..." << std::endl; // Load Weights from relevant file std::map<std::string, Weights> weightMap = loadWeights(file_wts); //载入权重中 // Create an empty network INetworkDefinition *network = builder->createNetworkV2(0U); //创造网络 // Create an input with proper *name ITensor *data = network->addInput("data", DataType::kFLOAT, Dims3{1, 1, 1}); assert(data); // Add layer for MLP 输入 输出 w权重 b权重 IFullyConnectedLayer *fc1 = network->addFullyConnected(*data, 1, weightMap["linear.weight"], weightMap["linear.bias"]); assert(fc1); // set output with *name fc1->getOutput(0)->setName("out"); // mark the output network->markOutput(*fc1->getOutput(0)); // Set configurations builder->setMaxBatchSize(1); // Set workspace size config->setMaxWorkspaceSize(1 << 20); // Build CUDA Engine using network and configurations ICudaEngine *engine = builder->buildEngineWithConfig(*network, *config); assert(engine != nullptr); // Don't need the network any more // free captured memory network->destroy();//销毁网络 // Release host memory for (auto &mem: weightMap) { free((void *) (mem.second.values)); } return engine; } //构建模型,主要调用ICudaEngine函数 void APIToModel(unsigned int maxBatchSize, IHostMemory **modelStream, const std::string file_wts) { /** * Create engine using TensorRT APIs * * @param maxBatchSize: for the deployed model configs * @param modelStream: shared memory to store serialized model */ // Create builder with the help of logger IBuilder *builder = createInferBuilder(gLogger); //构建builder // Create hardware configs IBuilderConfig *config = builder->createBuilderConfig(); //为builder分配内存,默认全部分配 // Build an engine ICudaEngine *engine = createMLPEngine(maxBatchSize, builder, config, DataType::kFLOAT,file_wts); //创造引擎 // DataType::kFLOAT指的是数据类型,kFLOAT=0表示32float;kHALF=1表示16float; // kFLOAT = 0 32-bit floating point format. kHALF = 1 16-bit floating-point format.kINT8=2 8-bit integer representing a quantized floating-point value. //kINT32=3 Signed 32-bit integer format.kBOOL=4 8-bit boolean. 0 = false, 1 = true, other values undefined. assert(engine != nullptr); // serialize the engine into binary stream (*modelStream) = engine->serialize(); //调用序列化方法 // free up the memory engine->destroy(); //释放engine结构 builder->destroy();//释放builder结构 } //载入wts权重与构建网络,转为engine,并将其序列化保存 void performSerialization(std::string file_wts= "C:\\Users\\Administrator\\Desktop\\C++code\\trt-try\\mlp.wts", std::string file_engine= "C:\\Users\\Administrator\\Desktop\\C++code\\trt-try\\mlp1.engine") { /** 将网络Serialization保存engine格式保存 file_wts表示载入权重路径 file_engine表示保存engine路径 */ // Shared memory object IHostMemory *modelStream{nullptr}; //创建IHostMemory变量,用于保存engine模型 // Write model into stream APIToModel(1, &modelStream,file_wts); assert(modelStream != nullptr); std::cout << "[INFO]: Writing engine into binary..." << std::endl; // Open the file and write the contents there in binary format std::ofstream p(file_engine, std::ios::binary); if (!p) { std::cerr << "could not open plan output file" << std::endl; return; } p.write(reinterpret_cast<const char *>(modelStream->data()), modelStream->size()); // Release the memory modelStream->destroy(); std::cout << "[INFO]: Successfully created TensorRT engine..." << std::endl; std::cout << "\n\tRun inference using `./mlp -d`" << std::endl; } /******************************************************************加载engine并推理*********************************************/ void doInference(IExecutionContext &context, float *input, float *output, int batchSize) { /** * Perform inference using the CUDA context * * @param context: context created by engine * @param input: input from the host * @param output: output to save on host * @param batchSize: batch size for TRT model */ // Get engine from the context const ICudaEngine &engine = context.getEngine(); // Pointers to input and output device buffers to pass to engine. // Engine requires exactly IEngine::getNbBindings() number of buffers. assert(engine.getNbBindings() == 2); void *buffers[2]; // In order to bind the buffers, we need to know the names of the input and output tensors. // Note that indices are guaranteed to be less than IEngine::getNbBindings() const int inputIndex = engine.getBindingIndex("data"); const int outputIndex = engine.getBindingIndex("out"); // Create GPU buffers on device -- allocate memory for input and output cudaMalloc(&buffers[inputIndex], batchSize * INPUT_SIZE * sizeof(float)); cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)); // create CUDA stream for simultaneous CUDA operations cudaStream_t stream; cudaStreamCreate(&stream); // copy input from host (CPU) to device (GPU) in stream cudaMemcpyAsync(buffers[inputIndex], input, batchSize * INPUT_SIZE * sizeof(float), cudaMemcpyHostToDevice, stream); // execute inference using context provided by engine context.enqueue(batchSize, buffers, stream, nullptr); // copy output back from device (GPU) to host (CPU) cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream); // synchronize the stream to prevent issues // (block CUDA and wait for CUDA operations to be completed) cudaStreamSynchronize(stream); // Release stream and buffers (memory) cudaStreamDestroy(stream); cudaFree(buffers[inputIndex]); cudaFree(buffers[outputIndex]); } ICudaEngine* inite_engine(std::string file_engine = "C:\\Users\\Administrator\\Desktop\\C++code\\trt-try\\mlp.engine"){ /* 读取engine文件,将其反序列化,构造engine结构,相当于网络初始化 */ char* trtModelStream{ nullptr }; //指针函数,创建保存engine序列化文件结果 size_t size{ 0 }; // read model from the engine file std::ifstream file(file_engine, std::ios::binary); if (file.good()) { file.seekg(0, file.end); size = file.tellg(); file.seekg(0, file.beg); trtModelStream = new char[size]; assert(trtModelStream); file.read(trtModelStream, size); file.close(); } // create a runtime (required for deserialization of model) with NVIDIA's logger IRuntime* runtime = createInferRuntime(gLogger); //反序列化方法 assert(runtime != nullptr); // deserialize engine for using the char-stream ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr); assert(engine != nullptr); /* 一个engine可以有多个execution context,并允许将同一套weights用于多个推理任务。可以在并行的CUDA streams流中按每个stream流一个engine和一个context来处理图像。每个context在engine相同的GPU上创建。 */ runtime->destroy(); return engine; }; auto infer(ICudaEngine* engine) { // create execution context -- required for inference executions IExecutionContext* context = engine->createExecutionContext(); assert(context != nullptr); float out[1]; // array for output float data[1]; // array for input for (float& i : data) i = 12.0; // put any value for input // time the execution auto start = std::chrono::system_clock::now(); // do inference using the parameters doInference(*context, data, out, 1); // time the execution auto end = std::chrono::system_clock::now(); std::cout << "\n[INFO]: Time taken by execution: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl; // free the captured space context->destroy(); engine->destroy(); //runtime->destroy(); std::cout << "\nInput:\t" << data[0]; std::cout << "\nOutput:\t"; for (float i : out) { std::cout << i; } std::cout << std::endl; return out; }; int checkArgs(int argc, char **argv) { /** * Parse command line arguments * * @param argc: argument count * @param argv: arguments vector * @return int: a flag to perform operation */ if (argc != 2) { std::cerr << "[ERROR]: Arguments not right!" << std::endl; std::cerr << "./mlp -s // serialize model to plan file" << std::endl; std::cerr << "./mlp -d // deserialize plan file and run inference" << std::endl; return -1; } if (std::string(argv[1]) == "-s") { return 1; } else if (std::string(argv[1]) == "-d") { return 2; } return -1; } int argc = 2; int main() { //int argc = 2; int args = 2; //int args = checkArgs(argc, argv); if (args == 1) { performSerialization(); } else if (args == 2) { ICudaEngine* engine = inite_engine(); auto out=infer(engine); std::cout << out << std::endl; //performInference(); } return 0; }
权重文件mlp.wts
2 linear.weight 1 3fff7e32 linear.bias 1 3c138a5a
结果示意如下:
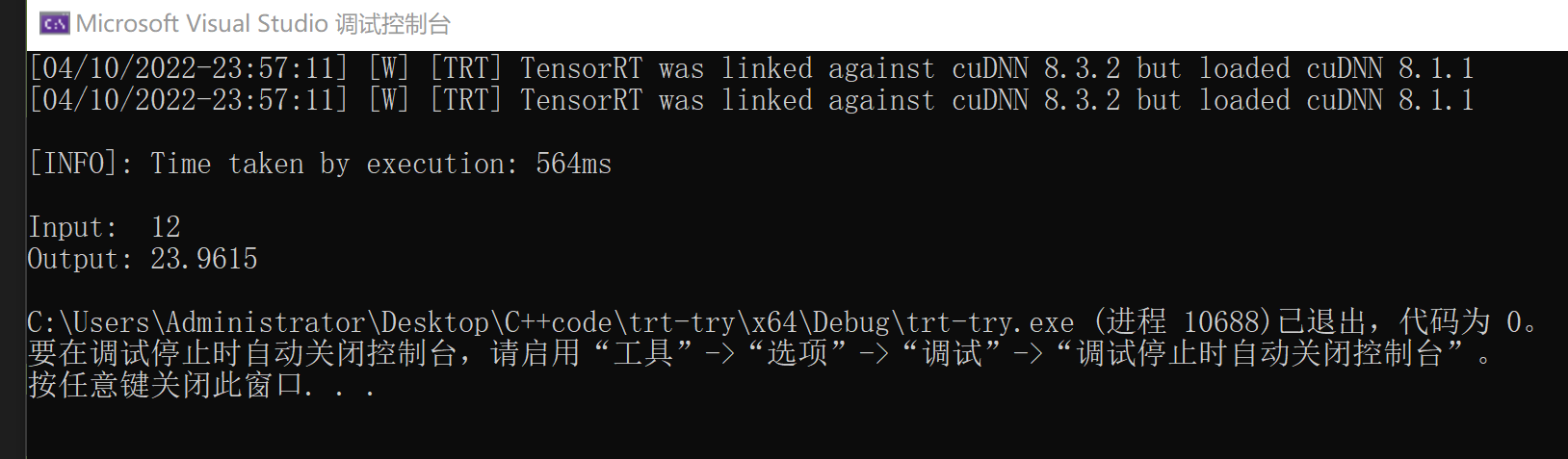
Ⅲ.修改代码使用
通过研究可以使用简单logging的定义,将无需logging.h文件,任可运行,代码如下:
#include "NvInfer.h" // TensorRT library #include "iostream" // Standard input/output library //#include "logging.h" // logging file -- by NVIDIA #include <map> // for weight maps #include <fstream> // for file-handling #include <chrono> // for timing the execution // provided by nvidia for using TensorRT APIs using namespace nvinfer1; /*****************************************源代码调用的logger********************************************/ // Logger from TRT API //static Logger gLogger; //using namespace nvinfer1; /****************************************修改后调用的logger*****************************************/ #include "NvInferRuntimeCommon.h" #include <cassert> class Logger : public nvinfer1::ILogger { void log(Severity severity, const char* msg) noexcept override { // suppress info-level messages if (severity != Severity::kINFO) std::cout << msg << std::endl; } } gLogger; const int INPUT_SIZE = 1; const int OUTPUT_SIZE = 1; /*******************************************************构建engine将其序列化并保存*******************************************************************************/ /* Weights是类别类型 class Weights { public: DataType type; //!< The type of the weights. const void* values; //!< The weight values, in a contiguous array. int64_t count; //!< The number of weights in the array. }; */ //载入权重函数 std::map<std::string, Weights> loadWeights(const std::string file) { /** * Parse the .wts file and store weights in dict format. * * @param file path to .wts file * @return weight_map: dictionary containing weights and their values */ std::cout << "[INFO]: Loading weights..." << file << std::endl; std::map<std::string, Weights> weightMap; //定义声明 // Open Weight file std::ifstream input(file); assert(input.is_open() && "[ERROR]: Unable to load weight file..."); // Read number of weights int32_t count; input >> count; assert(count > 0 && "Invalid weight map file."); // Loop through number of line, actually the number of weights & biases while (count--) { // TensorRT weights Weights wt{ DataType::kFLOAT, nullptr, 0 }; uint32_t size; // Read name and type of weights std::string w_name; input >> w_name >> std::dec >> size; wt.type = DataType::kFLOAT; uint32_t* val = reinterpret_cast<uint32_t*>(malloc(sizeof(val) * size)); for (uint32_t x = 0, y = size; x < y; ++x) { // Change hex values to uint32 (for higher values) input >> std::hex >> val[x]; //hex为16进制 } wt.values = val; wt.count = size; // Add weight values against its name (key) weightMap[w_name] = wt; //将权重结果保存此处 } return weightMap; } //构建engine函数 ICudaEngine* createMLPEngine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, const std::string file_wts) { /** * Create Multi-Layer Perceptron using the TRT Builder and Configurations * * @param maxBatchSize: batch size for built TRT model * @param builder: to build engine and networks * @param config: configuration related to Hardware * @param dt: datatype for model layers * @return engine: TRT model */ //std::cout << "[INFO]: Creating MLP using TensorRT..." << std::endl; // Load Weights from relevant file std::map<std::string, Weights> weightMap = loadWeights(file_wts); //载入权重中 // Create an empty network INetworkDefinition* network = builder->createNetworkV2(0U); //创造网络 // Create an input with proper *name ITensor* data = network->addInput("data", DataType::kFLOAT, Dims3{ 1, 1, 1 }); assert(data); // Add layer for MLP 输入 输出 w权重 b权重 IFullyConnectedLayer* fc1 = network->addFullyConnected(*data, 1, weightMap["linear.weight"], weightMap["linear.bias"]); assert(fc1); // set output with *name fc1->getOutput(0)->setName("out"); /*设置fc1层的输出,(对特殊的网络层通过ITensor->setName()方法设定名称,方便后面的操作); 指定网络的output节点,tensorrt必须指定输出节点,否则有可能会在优化过程中将该节点优化掉 */ // mark the output network->markOutput(*fc1->getOutput(0)); //设为网络的输出,防止被优化掉 // Set configurations builder->setMaxBatchSize(1); // Set workspace size config->setMaxWorkspaceSize(1 << 20); // Build CUDA Engine using network and configurations ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config); assert(engine != nullptr); // Don't need the network any more // free captured memory network->destroy();//销毁网络 // Release host memory for (auto& mem : weightMap) { free((void*)(mem.second.values)); } return engine; } //构建模型,主要调用ICudaEngine函数 void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream, const std::string file_wts) { /** * Create engine using TensorRT APIs * * @param maxBatchSize: for the deployed model configs * @param modelStream: shared memory to store serialized model */ // Create builder with the help of logger IBuilder* builder = createInferBuilder(gLogger); //构建builder // Create hardware configs IBuilderConfig* config = builder->createBuilderConfig(); //为builder分配内存,默认全部分配 // Build an engine ICudaEngine* engine = createMLPEngine(maxBatchSize, builder, config, DataType::kFLOAT, file_wts); //创造引擎 // DataType::kFLOAT指的是数据类型,kFLOAT=0表示32float;kHALF=1表示16float; // kFLOAT = 0 32-bit floating point format. kHALF = 1 16-bit floating-point format.kINT8=2 8-bit integer representing a quantized floating-point value. //kINT32=3 Signed 32-bit integer format.kBOOL=4 8-bit boolean. 0 = false, 1 = true, other values undefined. assert(engine != nullptr); // serialize the engine into binary stream (*modelStream) = engine->serialize(); //调用序列化方法 // free up the memory engine->destroy(); //释放engine结构 builder->destroy();//释放builder结构 } //载入wts权重与构建网络,转为engine,并将其序列化保存 void performSerialization(std::string file_wts = "C:\\Users\\Administrator\\Desktop\\code\\tensorrt-code\\mlp\\mlp.wts", std::string file_engine = "C:\\Users\\Administrator\\Desktop\\code\\tensorrt-code\\mlp\\mlp.engine") { /** 将网络Serialization保存engine格式保存 file_wts表示载入权重路径 file_engine表示保存engine路径 */ // Shared memory object IHostMemory* modelStream{ nullptr }; //创建IHostMemory变量,用于保存engine模型 // Write model into stream APIToModel(1, &modelStream, file_wts); assert(modelStream != nullptr); std::cout << "[INFO]: Writing engine into binary..." << std::endl; // Open the file and write the contents there in binary format std::ofstream p(file_engine, std::ios::binary); if (!p) { std::cerr << "could not open plan output file" << std::endl; return; } p.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size()); // Release the memory modelStream->destroy(); std::cout << "[INFO]: Successfully created TensorRT engine..." << std::endl; std::cout << "\n\tRun inference using `./mlp -d`" << std::endl; } /******************************************************************加载engine并推理*********************************************/ void doInference(IExecutionContext& context, float* input, float* output, int batchSize) { /** * Perform inference using the CUDA context * * @param context: context created by engine * @param input: input from the host * @param output: output to save on host * @param batchSize: batch size for TRT model */ // Get engine from the context const ICudaEngine& engine = context.getEngine(); // Pointers to input and output device buffers to pass to engine. // Engine requires exactly IEngine::getNbBindings() number of buffers. assert(engine.getNbBindings() == 2); void* buffers[2]; // In order to bind the buffers, we need to know the names of the input and output tensors. // Note that indices are guaranteed to be less than IEngine::getNbBindings() const int inputIndex = engine.getBindingIndex("data"); const int outputIndex = engine.getBindingIndex("out"); // Create GPU buffers on device -- allocate memory for input and output cudaMalloc(&buffers[inputIndex], batchSize * INPUT_SIZE * sizeof(float)); cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)); // create CUDA stream for simultaneous CUDA operations cudaStream_t stream; cudaStreamCreate(&stream); // copy input from host (CPU) to device (GPU) in stream cudaMemcpyAsync(buffers[inputIndex], input, batchSize * INPUT_SIZE * sizeof(float), cudaMemcpyHostToDevice, stream); // execute inference using context provided by engine context.enqueue(batchSize, buffers, stream, nullptr);//*******************************************************************************************************************重点推理**************** // copy output back from device (GPU) to host (CPU) cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream); // synchronize the stream to prevent issues (block CUDA and wait for CUDA operations to be completed) cudaStreamSynchronize(stream); // Release stream and buffers (memory) cudaStreamDestroy(stream); cudaFree(buffers[inputIndex]); cudaFree(buffers[outputIndex]); } ICudaEngine* inite_engine(std::string file_engine = "C:\\Users\\Administrator\\Desktop\\code\\tensorrt-code\\mlp\\mlp.engine") { /* 读取engine文件,将其反序列化,构造engine结构,相当于网络初始化 */ char* trtModelStream{ nullptr }; //指针函数,创建保存engine序列化文件结果 size_t size{ 0 }; // read model from the engine file std::ifstream file(file_engine, std::ios::binary); if (file.good()) { file.seekg(0, file.end); size = file.tellg(); file.seekg(0, file.beg); trtModelStream = new char[size]; assert(trtModelStream); file.read(trtModelStream, size); file.close(); } // create a runtime (required for deserialization of model) with NVIDIA's logger IRuntime* runtime = createInferRuntime(gLogger); //反序列化方法 assert(runtime != nullptr); // deserialize engine for using the char-stream ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr); assert(engine != nullptr); /* 一个engine可以有多个execution context,并允许将同一套weights用于多个推理任务。可以在并行的CUDA streams流中按每个stream流一个engine和一个context来处理图像。每个context在engine相同的GPU上创建。 */ runtime->destroy(); return engine; }; auto infer(ICudaEngine* engine) { // create execution context -- required for inference executions IExecutionContext* context = engine->createExecutionContext(); assert(context != nullptr); float out[1]; // array for output float data[1]; // array for input for (float& i : data) i = 12.0; // put any value for input // time the execution auto start = std::chrono::system_clock::now(); // do inference using the parameters doInference(*context, data, out, 1); // time the execution auto end = std::chrono::system_clock::now(); std::cout << "\n[INFO]: Time taken by execution: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl; // free the captured space context->destroy(); engine->destroy(); //runtime->destroy(); std::cout << "\nInput:\t" << data[0]; std::cout << "\nOutput:\t"; for (float i : out) { std::cout << i; } std::cout << std::endl; return out; }; int main() { //int argc = 2; int args = 1; //int args = checkArgs(argc, argv); if (args == 1) { performSerialization(); } else if (args == 2) { ICudaEngine* engine = inite_engine(); auto out = infer(engine); std::cout << out << std::endl; //performInference(); } return 0; }
tensorRT下载路径:https://developer.nvidia.com/nvidia-tensorrt-8x-download
参考原文:
https://blog.csdn.net/just_sort/article/details/104772653