实现预测的功能
# 导入包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
# %matplotlib inline
# 要显示中文 需要导入该模块
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 导入数据各个海滨城市数据
ferrara1 = pd.read_csv('./ferrara_150715.csv')
ferrara2 = pd.read_csv('./ferrara_250715.csv')
ferrara3 = pd.read_csv('./ferrara_270615.csv')
ferrara=pd.concat([ferrara1,ferrara2,ferrara3],ignore_index=True)
# concat做级联 用列与列级联 ignore_index=True 忽略显式的行索引
torino1 = pd.read_csv('./torino_150715.csv')
torino2 = pd.read_csv('./torino_250715.csv')
torino3 = pd.read_csv('./torino_270615.csv')
torino = pd.concat([torino1,torino2,torino3],ignore_index=True)
mantova1 = pd.read_csv('./mantova_150715.csv')
mantova2 = pd.read_csv('./mantova_250715.csv')
mantova3 = pd.read_csv('./mantova_270615.csv')
mantova = pd.concat([mantova1,mantova2,mantova3],ignore_index=True)
milano1 = pd.read_csv('./milano_150715.csv')
milano2 = pd.read_csv('./milano_250715.csv')
milano3 = pd.read_csv('./milano_270615.csv')
milano = pd.concat([milano1,milano2,milano3],ignore_index=True)
ravenna1 = pd.read_csv('./ravenna_150715.csv')
ravenna2 = pd.read_csv('./ravenna_250715.csv')
ravenna3 = pd.read_csv('./ravenna_270615.csv')
ravenna = pd.concat([ravenna1,ravenna2,ravenna3],ignore_index=True)
asti1 = pd.read_csv('./asti_150715.csv')
asti2 = pd.read_csv('./asti_250715.csv')
asti3 = pd.read_csv('./asti_270615.csv')
asti = pd.concat([asti1,asti2,asti3],ignore_index=True)
bologna1 = pd.read_csv('./bologna_150715.csv')
bologna2 = pd.read_csv('./bologna_250715.csv')
bologna3 = pd.read_csv('./bologna_270615.csv')
bologna = pd.concat([bologna1,bologna2,bologna3],ignore_index=True)
piacenza1 = pd.read_csv('./piacenza_150715.csv')
piacenza2 = pd.read_csv('./piacenza_250715.csv')
piacenza3 = pd.read_csv('./piacenza_270615.csv')
piacenza = pd.concat([piacenza1,piacenza2,piacenza3],ignore_index=True)
cesena1 = pd.read_csv('./cesena_150715.csv')
cesena2 = pd.read_csv('./cesena_250715.csv')
cesena3 = pd.read_csv('./cesena_270615.csv')
cesena = pd.concat([cesena1,cesena2,cesena3],ignore_index=True)
faenza1 = pd.read_csv('./faenza_150715.csv')
faenza2 = pd.read_csv('./faenza_250715.csv')
faenza3 = pd.read_csv('./faenza_270615.csv')
faenza = pd.concat([faenza1,faenza2,faenza3],ignore_index=True)
cesena.head()
# 查看一下表格
# 去除没用的列 'Unnamed: 0'
city_list = [ferrara,torino,mantova,milano,ravenna,asti,bologna,piacenza,cesena,faenza]
for city in city_list:
city.drop(labels='Unnamed: 0',axis=1,inplace=True)
cesena.head(1)
# 在查看一下表格里的'Unnamed: 0'有没去掉
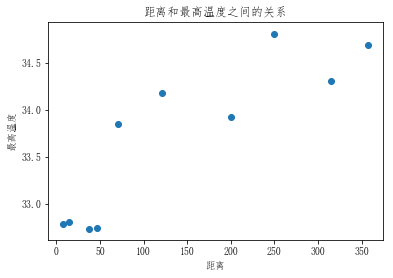
# 显示最高温度于离海远近的关系(观察多个城市)
city_max_temp = []
city_dist = []
city_list = [ferrara,torino,mantova,milano,ravenna,asti,bologna,piacenza,cesena,faenza]
for city in city_list:
temp = city['temp'].max()
dist = city['dist'].max()
city_max_temp.append(temp)
city_dist.append(dist)
# 查看数据
city_max_temp
city_dist
# [47, 357, 121, 250, 8, 315, 71, 200, 14, 37]
plt.scatter(city_dist,city_max_temp)
plt.xlabel('距离')
plt.ylabel('最高温度')
plt.title('距离和最高温度之间的关系')
机器学习
# 有一个未知最高温度的海滨城市,该城市的距离是已知的,我们需要建立一个模型,通过该城市的距离预测该城市的最高温度。
# 引出 机器学习
### 机器学习
- 机器学习和AI(人工智能)之间的关联是什么?
- 机器学习是实现人工智能的一种技术手段
- 算法模型:
- 特殊的对象。对象内部封装了一个还没有求出解的方程(算法)。
- 作用:
- 预测:预测出一个未知的值
- 分类:将一个未知的事物归到已知的分类中
- 预测或者分类的结果就是模型对象方程的解
- 样本数据:
- 组成部分:
- 特征数据:自变量
- 目标数据:因变量
- 样本数据和算法模型对象之间的关联?
- 可以将样本数据带入到算法模型中,对其内部的方程进行求解操作。一旦模型对象有解了,那么就可以实现分类或者预测的功能。
- 训练模型:将样本数据带入到算法模型,让其模型对象有解。
- 算法模型的分类:
- 有监督学习:如果算法模型需要的样本数据必须要包含特征数据和目标数据
- 无监督学习:如果算法模型需要的样本数据只包含特征数据即可
- sklearn模块展开学习
- 封装好了多种不同的算法模型
面积 楼层 采光率 售价
100 3 34% 80w
80 6 89% 100w
需求
有一个未知最高温度的海滨城市,该城市的距离是已知的,我们需要建立一个模型,通过该城市的距离预测该城市的最高温度。
# 有一个未知最高温度的海滨城市,该城市的距离是已知的,我们需要建立一个模型,通过该城市的距离预测该城市的最高温度。
样本集:用于对机器学习算法模型对象进行训练。样本集通常为一个DataFrame。
- 特征数据:特征数据的变化会影响目标数据的变化。通常为多列。
- 目标数据:结果。通常为一列。
#提取样本
feature = city_dist # 列表形式的特征数据
target = city_max_temp # 列表形式的目标数据
# 因为特征数据必须是二维的,所以变为np的二维数据
# np 很容易去变形
feature = np.array(feature) # np形式的特征数据
target = np.array(target) # np形式的目标数据
# 导入sklearn,建立线性回归算法模型对象
from sklearn.linear_model import LinearRegression
# 实例化算法模型对象
linner = LinearRegression() # y = wx + b
# 训练模型 ,训练模型需要样本数据
# X:二维的特征数据
# y:目标数据
linner.fit(feature.reshape((-1,1)),target)
# -1 是自动计算行数,1是 1 列 ,,当前是10行 就是表示为10行1列
# 返回一个LinearRegression 对象,模型训练完毕
# LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
# 预测
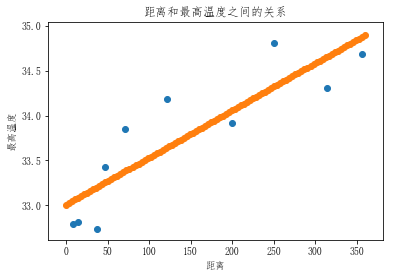
linner.predict([[175],[201]])
# array([33.9261553 , 34.06258068])
将远海城市的数据带入到散点图中进行展示,并且进行线性回归
x = np.linspace(0,360,num=100)# 随机获取100个数值 等差的数列
y = linner.predict(x.reshape(-1,1))# 调用方程
plt.scatter(city_dist,city_max_temp)# 会把10个散点绘制出来
plt.scatter(x,y) # 将100个点绘制出
plt.xlabel('距离')
plt.ylabel('最高温度')
plt.title('距离和最高温度之间的关系')