本篇序言
作为一个并不严谨的C++开发者,接触了C++这么多年后,将C++看作是“C with Class”还是我的主观看法(夸张了,但八九不离十),许多优秀特性都是一知半解或者完全不知道,更何况有些特性还是ISO C++ 03(甚至更老版本)里面的。所以又拿起了曾经在Udemy买的只看了几节课的C++课程以及那本落了很厚灰的《C++ primer plus》,算是做查漏补缺用,特此整理为C/C++戏法系列,记录一些很旮旯拐角但又很有用的C与C++优秀特性。当然,我会在特性后面标记这个特性的所属,方便只想了解C特性的同学们。补充说明一下:如果想要借本系列学习C++,那么我假定你已经了解了一些基础C++概念(比如RTTI、RAII、初始化列表等)。
哦,还有,从本系列开始,本人的博客文章头图采用一个系列使用唯一头图(这仅限我的GitHub博客),即比如以后本系列的头图都将使用上面那个。毕竟想要选一张好看并且不影响标题显示的头图实在太麻烦,并且前一段时间我一个同学就因为博客里使用了一张P站的大触板绘被警告了,即使最后说明了非商业用途从而解开误会,但那还是很麻烦。这就像是有着全世界最可爱的女朋友却还要搞外遇的那种麻烦一样(真是很有黑白熊风格的奇妙比喻呢,唔噗噗噗~)。所以想要用爬虫爬取二次元美图的同学们可能要失望了(笑)。
废话了这么多,开始正文。
1. explicit(C++)
中文翻译过来意为“显性的”,字面意思,即防止隐性转换。不过不着急,我们先看一下所谓的隐性转换。
首先我们定义一个类,粗暴一点,名字就叫Test:
class Test
{
public:
Test(int _a, int _b) : a(_a){/*按照参数_b的值来初始化数组c的长度*/}
Test(int _a) : a(_a){/*初始化数组c的长度为1*/}
bool addArrayMember(int _am)
{
// 增加数组c的成员,与本文无关,暂不叙述
}
int & operator[] (int _index)
{
// 返回_index检索到的数组引用
}
int arrLength()
{
// 返回c的节点数量(即数组长度)
}
private:
int a;
// 假设arr是一个结构体类型(链表节点),里面存储了数据(int)以及指向下一个节点的指针(pNext)
arr* c;
};
看起来不错,接下来我们把它放进EntryPoint.cpp文件里,按如下方式调用:
int main(int argc, char** argv)
{
Test test(1, 6);
test = 5;
std::cout << test.arrLength() << std::endl;
system("pause");
return 0;
}
似乎并没有什么问题,让我们运行一下看看:
1
啊嘞?有点问题了:我们传入的数组长度不应该是6吗?怎么是1?不要心急,我们一行行慢慢来看:
- 首先我们声明了一个Test类的对象test,数组长度设为6,成员变量a的值为1,并没有什么问题,去下一步。
- 我们为test对象中第0个元素赋值为5……哦?忘了加重载运算符了,那么加上,改为
test[0] = 5,好了,继续下一步。 - 输出数组长度,这里假设类成员方法没有问题,甚至比相对论还要权威。好的,没有问题。
这时我们再运行一下:
6
这下就没有什么问题了。不过为什么?
问题就出在我刚刚粗心没加重载运算符的那里。这就是开头所讲的隐式转换,不过并不是我们所熟知的将integer与float之间的那种隐式转换,而是单参数构造函数的隐式转换。我们刚刚 test = 5; 的写法其实就等价于 test(5); ,也就是说在我们的这个例子里integer被隐式转换为了Test类的单参数构造函数。而在Test单参数构造函数中,我们创建了一个默认长度(节点数量)为1的链表,这便是问题根源。“不过,我不粗心不就行了,写完代码多检查上那么几遍不就行了?” 嘛,话虽然可以这么去说,但在面对拥有极为庞大的代码量的项目又或者是并未提供完善文档的第三方库时,这么做可不简单。毕竟这不是Intelligence Sense可以检测出的语法问题,因为C++的单参数构造函数隐式转换特性允许这么做。当然,Bjarne这么做是有原因的。不过目前,为了解决我们这个问题,我们可以使用explicit关键字来限定Test类的单参数构造函数,防止它进行隐式转换。用法如下:
explicit Test(int _a) : a(_a){/*初始化数组c的长度为1*/}
我们可以试着去掉源代码EntryPoint.cpp中的运算符重载,这时,IDE会报错。不错,这是我们想要的结果:即防止单参数构造函数进行隐式转换。
2. constant + function / function + constant ? (C++)
与其用上面这个标题,我倒更喜欢“const 秘传”,不过这东西也并不是什么C++里的“免许皆传”级别,只好作罢。话说回来,一说到const关键字,大多数人的第一印象就是const常量,这并不是什么好事,用我特别喜欢的一个比喻来说就好像只知道火药能拿来做摔炮一样。实际上正如标题所说const在函数(或者说方法)中有前缀和后缀两种用法,让我一一道来:
2.1 constant + function
先来举一个例子,毕竟事例驱动才是王道:
class A
{
public:
selfStruct & aGet()
{
return a;
}
bool aSet(selfStruct & _a)
{
if(/*a需要符合的某个条件*/)
{
this->a = _a;
return true;
}
else{ return false; }
}
private:
selfStruct a;
};
其中selfStruct是一个自定义的数据结构体,为何返回一个引用?只是我不想再多浪费内存而去存储一个临时结构体对象(这么说不严谨,但由于struct在C++的实现与class无异,所以不用管),尤其是在对性能需求更高的应用中,比如Vulkan或者OpenCL为架构的高性能应用。出发点是好的,但是有一个极其严重的问题:假设我对私有成员a的赋值有着极其严格的规定,如上方法aSet所述,只有符合条件时才可进行赋值,否则拒绝。但实际上在上面这个类A中,我们可以绕开我刚刚设置的这个限制来进行非法赋值(这里的非法并不是指syntax,而是我规定的赋值规则)。如下:
int main(int argc, char** argv)
{
selfStruct a = {···};
A b;
b.aGet() = a;
system("pause");
return 0;
}
代码第五行里我使用了类A里面的aGet方法进行了非法赋值操作,还记得原因么?因为我用了引用作为aGet方法的返回值。这种以引用作为返回值的方式更多的被用在运算符重载中,比如上面的类Test的 “[ ]” 运算符重载就是这么做的,但在那里我允许相关方法这么去做。在类A这里有一个很重要的前提:成员a有赋值限制。那么,为了防止这种非法赋值问题该如何处理,我们可以在相应方法声明前加上const关键字,表明其返回值不可修改。就是这么简单。
2.2 function + const
假如说我现在又为类A写入了一个方法,如下所示:
selfStruct & A :: add(selfStruct & _para)
{
// 这里不用担心非法赋值,因为返回的值并不是类的成员变量
return this->a + _para;
}
我在这个方法里并没有对私有成员a做任何修改操作,看起来并没有什么问题,如果我将这段代码的声明公开出来,为了向使用它的人表明这个方法并不会修改类的私有成员该怎么去做,很简单,方法声明后加上const即可。
目前看起来这种做法除了提高代码可读性外并没什么别的用处,但实际上我们可以将它作为对这个方法的功能限制,在以后扩充这个方法职能时可以让编译器或者IDE时刻提醒你这里不可更改类中任何成员变量,也包括方法(自身递归调用除外)。关于这里为什么连方法也一概包括,我的猜想是防止套娃式的更改类成员变量,即方法一声明后有const限制,而方法二并没有const限制并且方法二定义里有对成员变量的修改语句,那么若没有对方法的限制,那方法一便可以通过方法二隐式修改成员变量,const限制也便失去了自己的职能。
这里有个问题,假设类A是这么定义的:
class A
{
public:
/*这里写一大堆方法声明,巴拉巴拉巴拉巴拉……*/
private:
int a;
selfStruct b;
bool c;
float d;
};
这时我重载了add方法,定义如下:
selfStruct & A::add(selfStruct & _para, int _a) const
{
this->a = _a;
return this->a + _para;
}
我们知道这个定义是无法通过编译的,但假如现在有某种情况导致我们必须要在这个方法里用参数_a来对a成员赋值,其他成员变量不做操作。这时我们该怎么办?
2.3 mutable
既然我能在这里(刻意地)提出这个问题,那么就说明一定有相关的解决方案:使用mutable关键字(啊?又来?)即可解决。但并不是在方法前加,而是这么去用:
class A
{
public:
/*这里写一大堆方法声明,巴拉巴拉巴拉巴拉……*/
private:
mutable int a; // 添加mutable关键字
selfStruct b;
bool c;
float d;
};
这样就可在重载的add方法中尽情地使用成员a了。
3. 前向声明(C++)
话说各位在上C语言课的时候可能都会遇到这种情况:
#include <stdio.h>
void func();
int main()
{
func();
return 0;
}
void func()
{
/*blablablablabla......*/
}
为了让编译器知道有func这个函数的存在,这就是前向声明。不过,既然我专门拿出来讲,就说明事情远没有这么简单。
我们知道,无论是在编写C还是C++,都有一个不成文的规定:尽量避免在header中包含header。 因为如果这么做无疑会造成以下两点问题:
- 链接速度变慢,尤其是将声明与定义写在两个文件中(.h 和 .cpp),因为我们都知道include在预编译阶段会将header里面的所有代码加载进包含它的代码文件中。这样的话会导致我们真正包含的库文件被转移了两次,因为真正生成.obj(或.o)文件的是同名cpp文件。
- 使用VS进行日常开发的同学应该都知道著名的LNK2019错误,就是因为在header中随意包含别的header,一旦包含关系复杂后,就极有可能产生LNK2019(标准库例外,因为其中有着一套防止这方面错误的机制)。虽然听说C++20可能支持module,但在VS以及GCC支持C++20标准的新版本出来之前,还是老老实实遵循这个不成文的规定吧(笑)。
但是这样会产生一个问题,举个例子来说明一下:
以下是类Test的声明与定义,分别写在header以及cpp文件中。
Test.h
#pragma once
#ifndef TEST
#define TEST
class Test
{
public:
void func(std::string a);
private:
std::string alfa;
};
#endif
Test.cpp
#include "Test.h"
#include <string>
void Test::func(std::string a)
{
/*blablablablabla......*/
}
看出问题了么?这段代码并不会被编译通过,这是因为虽然我们遵循了上述不成文的规定,但编译器未在Test.h内寻找到std::string的定义,因为我包含的是标准库文件,所以即使在header中包含也不会有太大问题,但是,请试想一下,如果是我们自定义的某个类呢?总不可能气势汹汹地跑到ISO组织去指着标准组成员的鼻子说:“快把老子写的类塞到标准库里去!”这显然不现实,那么,该怎么办?
这时候我们就可以使用前向声明来解决这个问题,在这个例子中的体现就是:我们在Test.h中声明一个string类。当然,仅仅是声明。更改后的Test.h文件如下:
#pragma once
#ifndef TEST
#define TEST
namespace std
{
class string;
}
class Test
{
public:
void func(std::string a);
private:
std::string * alfa;
};
#endif
不过要注意的是,我们的私有成员alfa的写法变了,这是因为Test.h并未包含string的具体成员声明,也就是说它是一个抽象的存在,在Test.h的文件范围内编译器不知道它是标准库里的string类,所以并不支持RAII式写法,这也就意味着你必须在类的析构函数里使用delete关键字来释放成员占据的内存空间了。
4. 再次探索继承“御三家”(C++)
友情提示:本小节篇幅较长,建议阅读之前先冲一杯咖啡,并且打开你用的最顺手的IDE,以及适当的休息后,再开始阅读。
有过C++面向对象基础的各位应该都知道C++的继承方式有三种:public,private,protected。它们也被称为继承方式“御三家”,但实际上在日常开发中(以我的经验)用的最多的也就是public方式,因为更加贴近OOP嘛。以至于我当初在学习完这三种方式的时候认为除public外,其余两种就是用来凑数的。
本小节并不会像学校老师以及课本那样讲述这三种继承方式特性方面的东西,更多的是偏向于用法,如果准备好的话,那就让我们开始吧!(掏出蹦蹦炸弹)
4.1 public
如果有C#或Java基础的同学返回过来学C++的话,public继承方式会让你倍感亲切。public是典型的is-a结构(关于has-a以及is-a稍后会讲,目前只要记住C#和Java都是这种就行了),基类的私有成员仅限在派生类中访问,基类的公有成员可以在派生类外经过派生类对象调用。
目前看来一切都没有什么问题,在探讨接下来的内容前,让我们来看一下is-a和has-a:
-
is-a:直接翻译过来为“是一个”,即两个类之间的关系为一个类是另一个类,再转过来想,那不就是一个类从另一个类派生过来?举个例子:
class A { ...... }; class B : public A { ...... };在这个例子里面“B is an A”,即B类由A类派生过来。为何要说“B is an A”?这其实是一种比较RTTI的说法,毕竟我们可以用基类的指针或引用来索引派生类。
-
has-a:直接翻译过来为“有一个”,即两个类之间的关系为一个类被包含在另一个类中,还是举个例子吧:
class A { ...... }; class B { ...... }; class C { public: ...... private: A a; B b; };在这个例子里面,类C与类A,B之间的关系即为has-a关系。
简单了解了这两种关系后,让我们往深聊一些:现在有一个职员类,产品经理要求我们需要在这个职员类里面包含两个属性:姓名以及工号。你第一个会想到的实现方式便是has-a,如下:
class employee
{
public:
......
private:
std::string str_eName;
uint64_t i_eNum;
};
由于为了保证数据安全性,我们不得不将这两个属性设置为私有属性,这一点相信大家都明白。接下来请想像这样一个场景:在我们将这个类的定义包装到.dll或.so中提供给前端开发人员后,过了不久,开发人员提供了一些反馈,他们希望我们使用更加直观的方式完成对职员类的赋值以及别的数据操作,好的,API的2.0版本开发工作提上日程,这里以员工姓名赋值为例,我们可以这样去写两个重载运算符方法:
std::string & employee :: operator = (std::string & _str) noexcept
{
this->str_eName = _str;
}
std::string & employee :: operator = (const char * _str) noexcept
{
this->str_eName = _str;
}
这样的确是很好的完成了前端开发人员的需求,但是,不觉得很别扭么?我们写了两个运算符重载方法,但实际上还是调用了string类里面的运算符重载,在函数栈里相当于入栈了两次,到这里,你可能会说,我们可以将它们设置为内联函数,不错的提议。其实还有和内联差不多的方法,就是继承(派生)。到了这里,可能会有人理解不了了,没关系,让我们回想一下继承的特性:我们可以在派生类以及派生里的对象里调用基类的公有成员以及方法。对啊,既然string类自身就包含着这么好的赋值方法,为什么我们还要再费劲去套个娃?
API 2.0 版本如下:
class employee : public std::string
{
public:
employee() : std::string("nully"){}
......
private:
uint64_t i_eNum;
};
嘛,貌似不错,这样我们可以直接去用operator = 进行赋值操作了,但是构造函数(如上所示)还是避不开套娃的,不过前提是想要实现使用构造函数来对employee进行赋值的操作。
总结一下,我们通过继承的方式简化了代码编写,甚至还可以用一大堆由string提供的方法直接操作employee类里面的数据。但是问题也出在这里:还记得我在上面讲的数据安全性么?由于某些业务需要,我们必须要对数据的赋值以及一系列操作进行限制,那如果按照我们2.0版本的构想,这便不存在数据安全性了,可以随意赋值以及其他一系列操作所带来的结果有可能是灾难性的,这也正是测试小组向我们提出的反馈。那么,如何解决?不着急,往下看。
4.2 private
各位应该都知道私有继承的特性:基类的公有方法与成员对派生类开放,但不得在派生类外利用派生类对象来调用。在接到了测试小组的反馈之后,API 3.0开发迫在眉睫,我们可以这么去做:
首先我们联系了一下前端开发人员,确定了一下他们的需求:
- 可以用 = 这种直观的方法赋值,并无赋值限制要求。
- 在必要时刻需要转换成C风格字符串。
- 不允许向已录入的员工姓名中添加其他字符。
那么,我们可以这么去写API 3.0 preview版本了:
class employee : private std::string
{
public:
employee() : std::string("nully"){}
......
private:
uint64_t i_eNum;
};
看起来不错,在保证了安全性的同时也继承了string的优秀特性,但就在送往测试小组测试后过了几天,测试小组送来的反馈里写道:无法进行任何与前端开发小组要求相符的操作。这是个问题,刚刚讲到:私有继承中,不得在派生类外利用派生类对象来调用基类的任何方法与成员。矛盾出来了:我们既想要保证数据安全性,也想要更方便的调用方式(小孩子才做选择,大人我全都要)。 该怎么办?
不必担心,我们可以这么去做:
class employee : private std::string
{
public:
employee() : std::string("nully"){}
using std::string::operator =;
using std::string::c_str;
......
private:
uint64_t i_eNum;
};
嗯?using关键字,是不是很熟悉?在名称空间引用中用的频率很多,但是为什么这里也可以这样用?《C++ Primer Plus》给出的解释是这样的:可以将它看作是using关键字的重载,毕竟引入新的关键字是会让几乎所有C++程序员不满的(相信各位在看到上文所讲的explicit以及mutable时就是这么想的吧)。这里using和名称空间关系不大,主要是为了方便使用一部分继承而来的基类方法。
这种方法在保证了数据安全性的同时又可以在外部使用我想用的方法,真好。当我们将这个API 3.0版本送到了前端开发人员那里,的确受到了不错的反馈。在高兴之余,让我们来反思以下几个问题:
-
我们知道,C++继承方式与我们所理解的继承是有所不同的,一般理解上的继承是将基类的代码复用到派生类上去,有点像是包含头文件那样粗暴的复制粘贴。但实际上,底层实现是会在派生类对象里隐式创建一个指向新创建基类对象的引用。也就是在你创建派生类对象时,编译器也同步创建了一个基类对象并存储在你的派生类对象中,这也是创建新对象时使用new关键字而不是malloc方法的一个原因所在。所以,当我们为员工类存储两个及以上的string成员时,这种方法可就没用了,因为这种方法最多只允许操作一个基类对象。
-
若是前端开发人员再次提出需求:希望可以使用输入输出流来将员工姓名打印直接出来。嗯,怎么实现?相信各位都已经想到了:
using std::string::operator <<;这样的确不错,但前提是string拥有符号“<<”的重载。但当我们翻遍string头文件,我们也并没找到相关重载方法,怎么办?有一部分小伙伴可能已经想到了:
using std::ostream::operator <<;看起来很棒,但编译器不会通过,因为这里的using关键字只允许“搬运”基类中存在的方法,然后,又有同学提出了这么一种办法:由于C++支持MI,那么我们可以再继承ostream类。但让我们都没想到的是,ostream类不包含默认构造函数,也就是说,派生类employee必须在每个构造函数后的初始化列表里加上ostream的初始化,但是翻看了一下相关的构造函数,我们会发现极其麻烦。这样浪费了大量时间不说,还增加了代码复杂程度。难道就没有解决方案了么?看这里:
friend std::ostream & employee :: operator << (std::ostream & _os, Employee & _ee) noexcept { _os << (std::string)_ee; return _os; }没错,的确是可以编译通过了,但是我们不得不加上强制类型转换以及友元标识,更可笑的是,我们还是没能逃离“套娃”——即我们在函数内部又使用了标准库的同名方法。看吧,转了一圈又转回来了。
当然,并不是说这种方式不好,而是想通过这两个问题告诉各位,is-a以及has-a的方法需要参考具体情况慎重选用。不过,比起has-a,is-a还是有一定优势的:对于继承的基类中的保护成员,如果出于业务要求而要求调用,如果使用has-a方式,那么是不可被使用的,但is-a可以。
4.3 protected
这里相对简单点,很明显,当基类想要把自己的公有方法传承下去时,选用protected继承方式,这样既保证了数据安全性,也能让派生类完全获得祖先类的“优良传统”。
还有一点补充,在上面提到的using用法中,公开后的方法接口在派生类的派生类中依旧是来自于基类的私有成员,无论使用何种继承方法,都不会改变这个特性,所以必须要再手动调用using声明。但很麻烦,不是么?这就轮到了保护继承出场的时刻,由于前端开发人员并不用去关心API的内部实现,所以,我们可以将Employee类的继承方式选择为protected,在以后继承Employee的派生类中,只要把using写一次即可。
4.4 MI
这便是大名鼎鼎的多重继承(Multiple Inherited),这也算是C++里的一大优点,不过呢,也是被许多人喷的一项特性。以至于Linux之父Linus借此讥笑“C++就是来捣乱的”。嘛,不否认Linus大神指出的某些C++特性的确不太灵活,但多重继承既然被提出并且在C++ 11、14、17、乃至即将发布的的20标准中被一直保留,那就说明还是有存在的必要性。我总结了一下,批评某项编程语言特性的群体无疑有两种人构成:一种是像Linus这样的真大佬(就连Bjarne自己也经常会对C++作出反思),另一种大家也知道是谁。关于前一种人的见解我们可以多参考,多反思;但对于第二种人,对他们做出“国际友好手势”就行了。
好的,闲扯这么多,让我们开始:
接下来我们会探讨三个问题:
- MI的空间成本
- MI的二义问题
- MI成员优先级问题
4.4.1 MI的空间成本
项目成功后,我们的开发小组在业内获得了不错的声望,委托开发的请求络绎不绝。这不,在短暂的摸鱼时光后不久,项目经理带来了新的需求:这次是接到了一个游戏项目,我们需要完成一个实体类关系,具体要求如下:
这是一个类似于《合金装备》的战术潜入类游戏,我们需要完成的是持枪的敌人的逻辑,开发商已经将引擎的世界实体类EngineObject以及一系列规范文档提供给我们,为了方便引擎资产的管理,我们需要分别完成枪械(GunObject)的一系列逻辑以及敌人(Enemy)的一系列逻辑,并且还要为持枪的敌人创建一个实体类(Soldier),游戏中真正被调用的是这个持枪的敌人类,但在调试时还是需要一些枪械与敌人类的方法。
在接到需求后的三个小时之后,我们完成了这一系列的关系,以下是各个类的声明:
EngineObject:
class ENGINE_API EngineObject
{
public:
EngineObject(){}
virtual bool Draw() = 0;
virtual bool loadModel(Model & _model) = 0;
......
private:
double i_locX;
double i_locY;
double i_locZ;
......
};
GunObject:
class GunObject : public EngineObject
{
public:
GunObject(){}
bool Draw() const;
bool loadModel(Model & _model);
void Fire() noexcept;
......
private:
uint32_t i_ammoNum;
......
};
Enemy:
class Enemy : public EngineObject
{
public:
GunObject(){}
bool Draw() const;
bool loadModel(Model & _model);
virtual Run() noexcept;
......
private:
uint32_t i_ammoNum;
......
};
Soldier:
class Soldier : public GunObject, public Enemy
{
public:
Soldier(){}
bool Draw() const;
bool loadModel(Model & _model);
void Attack() noexcept;
void Idle() noexcept;
void Gurd() noexcept;
......
private:
float f_healthVal;
......
};
上面这些类的关系可以用下图表示:
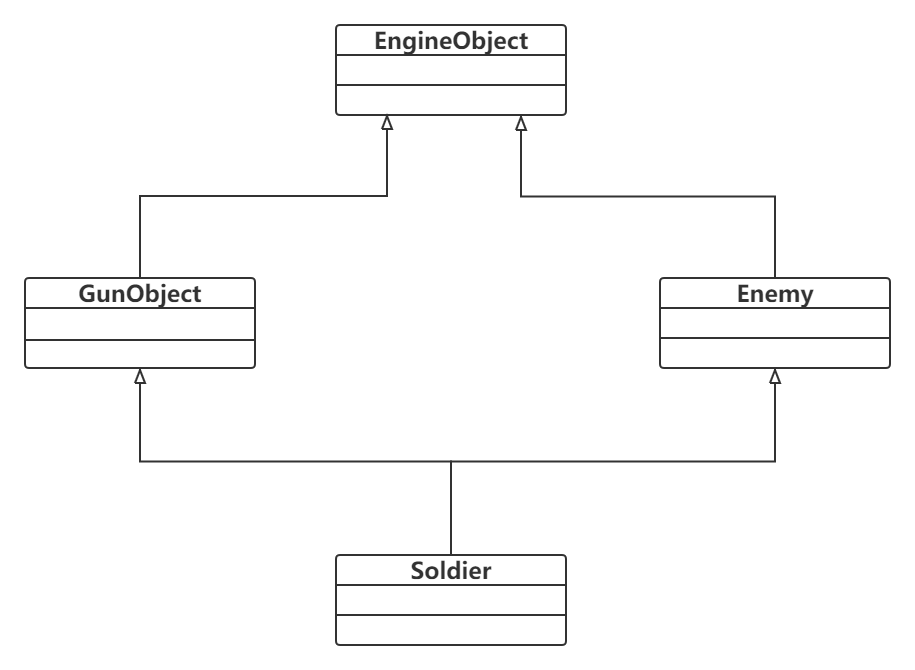
由图我们可以知道这是一个典型的菱形结构,由于C++支持MI,这种继承关系便是家常便饭。解释一下:Draw方法用于在引擎中调用,绘制这个实体类所对应的模型以及动画,LoadModel方法用于为实体类载入由美工制作好的模型资产,其他的方法看一看应该也就知道想要表达的意思了。好的,当我们将这个做好的对应关系与类的声明以及实现交付给开发商后没过几天,开发商反馈的信息中写道:我们无法使用引擎基类的引用来动态的调用Soldier类的对象。这是怎么回事?在收到反馈后,我们连夜召开了会议,最后得出了结果,你猜是什么?不要着急,还记得我前面说过的继承实际实现么?对,就是在你创建派生类对象时,编译器也同步创建了一个基类对象并存储在你的派生类对象中。
但是二者之间有什么联系呢?我们会发现,Soldier继承的基类有两个,分别为GunObject以及Enemy,而这两个类同时都继承自EngineObject类,根据上面的继承实现,我们可以轻易地推导出Soldier的对象中存在两个EngineObject对象,这便是C++ MI的空间成本,它占据了更多的空间却保存着相同的祖先基类对象,这种并未换取到效率的浪费是不可取的。并且,如开发商反馈所说,无法利用基类的引用去动态调用Soldier的对象,因为上述原因产生了二义性,编译器不知道动态调用哪一个基类对象,毕竟除了地址外其它都一样。
在确定了问题所在后,我们开始对解决方案进行讨论,首先,有同学肯定想到了强制类型转换,如下:
(GunObject *) & soldier;
(Enemy *) & soldier;
看起来不错,看来我们只要向开发商说明使用这种方式即可避免上述问题。但就在大家达成一致意见时候,产品经理一脚踹开会议室的门:“你们这是严重的甩锅行为,这样做会使我们的声誉严重受损!”而且放在性能层面上看,这样的确无意义的浪费了一部分资源。所以我们开始商讨第二种方案是否存在以及它的的可行性。
这里就要引入一个新的概念:虚基类。
在《C++ Primer Plus》中给虚基类的描述中是这么说的:虚基类可使得从多个基类(它们从一个共同的祖先类派生而来)派生的派生类只继承一个祖先类对象。
声明方式如下:
class ClassName : virtual (public/private/protected) BaseClassName{};
class ClassName : (public/private/protected) virtual BaseClassName{};
在这里,我们可以把virtual关键字看作一种关键字重载。其实虚函数与虚基类之间并无任何联系。为何要用“虚”?其实也就是为了防止新关键字的引入罢了。
在了解了虚基类的定义后,我们便可以将我们要交付的产品做如下修改:
GunObject:
class GunObject : virtual public EngineObject
{
public:
GunObject(){}
bool Draw() const;
bool loadModel(Model & _model);
void Fire() noexcept;
......
private:
uint32_t i_ammoNum;
......
};
Enemy:
class Enemy : virtual public EngineObject
{
public:
GunObject(){}
bool Draw() const;
bool loadModel(Model & _model);
virtual Run() noexcept;
......
private:
uint32_t i_ammoNum;
......
};
由于引擎基类是一个实现代码被封装在动态链接库里的接口,所以我们无法对引擎基类进修改,所以我们可以将Enemy以及GunObject的继承方式加个virtual,一切问题便迎刃而解。结果也的确是如此,我们收到了来自开发商不错的反馈。
这时候有同学会提出疑问,说为什么不将虚基类作为MI的准则?既然可以这么想,那么当然值得鼓励,不过实际上还是有一些情况是需要多个同一祖先类对象存在的,鉴于这种情况,bjarne以及ISO也就没取消掉虚基类的定义。不过具体使用情景这里就不过多介绍了。
4.4.2 MI的二义性以及优先级
用我们刚刚成功的项目举个例子,开发商提供的调试入口点定义如下:
class Entry
{
public:
static void FrameInit()
{
// 各个对象成员初始化
Soldier guard();
}
static void FrameLoopCallback()
{
// 以回调函数的形式作用在引擎的渲染循环中
// 就不要较图形API的真了,我当然知道Vulkan的渲染操作是写在队列里的(笑)。
guard.Draw();
}
static void Terminate() noexcept
{
// 程序结束,释放资源
}
};
在继续之前,我们先做一个假设:EngineObject类并不是Enemy以及GunObject的虚基类,也就正如我们所提交的第一个版本那样,忽略动态引用问题。在运行上面这段代码时,会出现问题,即编译器不知道该调用哪里的Draw方法(二义性),即使我们的Soldier类的Draw方法是将Enemy以及GunObject的Draw方法打包后的套娃方法。所以这时,如果我们将EngineObject类作为Enemy以及GunObject的虚基类,那么编译器便会遵循虚基类的优先级原则:派生类同名对象优先级大于虚基类,所以如果使用了虚基类的话,编译器会优先调用Soldier类的Draw方法。问题便迎刃而解。
5. 本篇结语
码了这么多字,太费劲了(笑),看来想要深入学一门技术还是要下很多功夫的啊,这些可能在许多C++大佬那里看来算是很naive的东西,不过呢,学习使我快乐,这点倒不算什么。看在我这么努力码字的基础上,如果感觉不错,还请不要吝啬点一点推荐吧,非常感谢,这个系列也会持续更下去的,保证不咕,这点还请大家放心。那么,下次见!
6. Reference
《C++ Primer Plus 6th》(2012): Stephen Prata
备注

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行过许可