一
- 文章名称:DeepDiag: Detailed NFV Performance Diagnosis
- 发表时间:2019
- 期刊来源:
解决问题:
- 一 NFV性能的具体诊断
论文要点:
- 一 NFV性能根源问题来源于时间资源的竞争,包括每个NF的输入流量队列、cpu、缓存等。
- 二 要做到具体的诊断,需要知道什么资源被竞争,竞争者有哪些,以及资源竞争的来源。诊断的难点在于 1. 每个资源竞争有多个竞争者,它们是混合的,难以区分;2. 仅仅查看当前的NF的情况是不够的,可能要往源头找(类似于找链表的头);3. 一个长延时的包可能不仅仅是由于处理这个包的过程中的资源竞争导致延时,而且可能是由于处理这个包之前的资源竞争导致。
- 三 主要做法是监控每个NF的队列。 利用来自所有NF的排队信息,我们可以了解每个数据包的体验,以及流量模式如何在不同的NF之间变化。 使用资源计数器,我们还可以随时了解每个资源处于什么样的争用状态。 因此,对于每个性能问题,我们可以了解哪些资源争用会导致问题,以及谁是竞争者。 此外,我们还可以了解资源争用如何改变不同NF的流量模式,以及流量模式变化如何影响NF的性能。
所做贡献:
- 一 设计了DeepDiag实现对NFV性能问题的具体诊断.DeepDiag主要是利用包级队列信息(Packet-level Queuing Information)。DeepDiag为每个NF的每个数据包输出对应的队列信息:1)五元组;2)时间戳;3)队列长度;4)数据包id,以区分是每个数据包。当性能问题发生时,DeepDiag可以知道输入队列是如何建立、依据队列信息知道每个NF的流量模式是如何变化以及 流量模式的变化展示了资源竞争的影响(可以找到源头)。
- 二 DeepDiag 算法。
1)本地分数分配;
2)分数反向传播。第一步的目的是为了弄清楚长延时的数据包来源。这一步的关键是考虑“队列的间隔”,而不是队列的内容,这是因为引起竞争的原因可能来源于历史的流量。另一个关键是定义一个可以进行资源对比的分值。DeepDiag将分值定义为由于不同资源竞争导致在队列中缓存的数据包数量。第二步的目的是为了弄清楚问题的根源所在以及是如何导致这个问题的。主要想法就是弄明白是哪些包导致了后面的性能问题。 - 三
不足之处:
- 一 是从出了问题去找问题的根源。还是会有导致性能等的问题。
诊断性能原型图
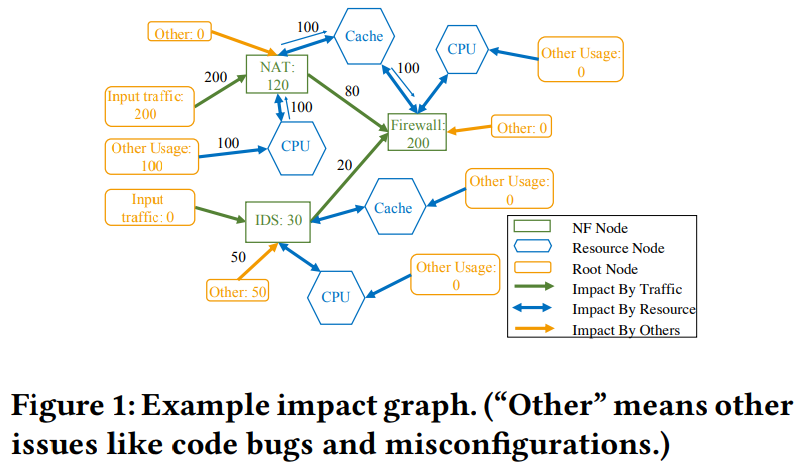
实验对比:
无。
二
- 文章名称:Efficiently Migrating Stateful Middleboxes
- 发表时间:2012
- 期刊来源:
问题描述
为了使此类分布式中间盒具有可伸缩性,我们需要在本地或远程服务器之间无缝移动处理及其关联的流状态的方法。这将允许平台通过添加服务器来应对负载激增,并通过关闭计算机来有效地缩小规模。 处理甚至可以迁移到世界其他地区的不同中间盒,以优化其他方面,例如用户感知的延迟。(无缝迁移流)
实现保持每条流的网络状态的处理,一般用种两方法一起来解决流迁移问题(方法:Pre-copy,Stop-and-copy,Demand migration)
解决方法
基本思想是允许短流死亡,并在发生任何流状态转移之前删除它们的相应状态。 为了实现此目标,我们在较短的时间内并行运行了源处理和目标处理。 迁移开始时,会将一小组页面复制到包含代码和不变全局状态的B中。 此后,该算法包括两个重叠的阶段:空闲阶段和迭代的冻结和复制阶段。
在空闲阶段,所有流量最初都会转发到A。A停止为尚未看到的流量建立新状态。 所有命中A但没有任何匹配状态的数据包都将转发给B,后者将对其进行正常处理。空闲阶段利用了大多数流都是短暂的这一事实。 无需转移这些状态,而是可以将它们保留在原始计算机上,直到它们到期,同时允许在另一台计算机上建立新流的状态。 两台机器都是菊花链式连接(无论方向如何,数据包始终始终先命中A;见图1(a))
冻结和复制阶段是迭代的,仅在状态在A上到期的速率降至某个阈值以下时才开始; 其余国家可能是长期存在的,需要转移。 A冻结其一些剩余状态,并开始将它们传输到B。所有将修改冻结状态的数据包都由A进行缓冲。传输完成后,所有冻结状态都将被删除,并且已缓冲的数据包将转发到B。重复该过程 直到所有状态都复制到B。此阶段仅处理长期流,冻结的目的是减少丢弃的数据包数量。 菊花链持续进行,直到冻结和复制状态结束。 此时,机器A上没有剩余流量状态,并且流量在OF交换机中被重定向到直接命中机器B。
三
- 文章名称:An Approach for Service Function Chain Routing and Virtual Function Network Instance Migration in Network Function Virtualization Architectures
- 发表时间:2017
- 期刊来源:
解决问题:
- 一 在何处实例化VNFI
- 二 为每个VNFI分配多少资源
- 三 如何以正确的顺序将SFC请求路由到适当的VNFI
- 四 何时以及如何迁移VNFI,以响应SFC请求强度和位置的更改。
概述:
我们开发了一种方法,该方法使用了三种算法,这些算法被背对背使用,以响应不断变化的工作负载而导致VNFI放置,SFC路由和VNFI迁移。目的是首先最大程度地减少对SFC带宽的拒绝,其次是在尽可能少的服务器中整合VNFI,以减少能耗。所提出的合并算法基于VNFI的迁移策略,该策略考虑了由于迁移过程中发生的信息丢失而使用户遭受的QoS下降所导致的收入损失。目的是最大程度地减少能耗和由于QoS降低而导致的收入损失所带来的总成本
本文贡献:
本文提供了两个主要的贡献。
贡献1
第一个是提出一种用于SFC路由和VNFI放置的算法,其中,按照核心文献中提出的最多文献[11]所假定的,按核数确定VNFI的尺寸不是先验确定的,但是可以作为问题的输出;提出的算法的目的是在高峰时段间隔内执行SFC路由和VNF放置,以最小化拒绝的SFC带宽。
贡献2
第二个贡献是提出流量发生变化期间SFC路由和VNF布置分配的VNFI的迁移策略。迁移策略的目标是在整体时间范围内将总成本降至最低,同时考虑能耗和重新配置成本。该策略在合并带来的节能优势与VNFI迁移期间发生的QoS降低导致运营商的收入损失的劣势之间提供了适当的权衡。我们给出了最佳问题的整数线性规划(ILP)公式,并且由于其复杂性,我们提出了一种针对循环平稳交通场景的解决方案,并根据给定的最优性先验评估了VNFI到服务器的可能映射标准。我们通过比较其结果与ILP公式的精确解决方案(对于小型网络)的效果,来评估所提出的解决方案启发式方法的有效性。最后,我们将建议的迁移策略的性能与简单的本地策略进行比较,在本地策略中,迁移决策仅考虑瞬时重新配置成本,而不再考虑长期因素。
当运营和重新配置成本分别由能耗和由于VNFI迁移导致的信息损失来表征时,我们提出了优化问题。 所提出的解决方案基于Markov决策过程理论的应用,已经由我们自己解决了其他问题(覆盖网络[24],虚拟网络嵌入[23], [25], [26]
[12] [11]也是关于迁移的论文 【10】【13】-【15】关于VNFI的路由和放置问题
四
- 文章名称: Enhancing VNF performance by exploiting SR-IOV and DPDK packet processing acceleration
- 发表时间: 2015
- 期刊来源:
背景知识介绍
pktGen:
可以使用PktGen生成流量,速度可达到 10Gbps;地址: https:/github.comPktgen Pktgcn-DPDK/ NDPI:一款开源的深度包检测库。
DPDK:
为了更高效利用网络资源和计算资源以及快速实现密集的网络功能而开发的一个工具
解决问题:
- 1.为开发人员提供一系列高速建立数据平面应用;
- 2.通过访问NIC可以实现高效的网络功能
摘要:
网络功能虚拟化(NFV)的主要目标是将物理网络功能迁移到在云计算环境中在虚拟机(VM)上运行的软件版本中。 虚拟化技术的飞速发展已使虚拟化基础架构环境中的高速网络连接和线速数据包处理成为可能。选择了以计算密集型虚拟化网络功能(VNF)形式进行的网络流量的深度数据包检查(DPI),作为代表用例。 使用了DPI用例,以演示将支持SRIOV的设备与DPDK一起使用以支持高性能虚拟网络功能(VNF)部署的好处。已经对使用LibPCAP,SRIOV和DPDK的VNF版本进行了性能评估。结果表明, 与使用本机Linux内核网络堆栈进行数据包处理相比,统一使用SRIOV和DPDK可以显着提高数据包吞吐性能
问题:
路由、过滤、流重建等云架构方案(比如OpenStack)运行在大量的网络组件之上,产生巨大负载,导致性能penalties,这是由于每个数据包经过OS内核并且不是直接访问用户空间。由于OpenStack的网络服务Neutron实质上是建立在一个OVS实例上,OVS包含许多的native虚拟端口,TAP虚拟网络接口和内核bridge对它们进行连接。多个虚拟bridge接口的安装,导致了在数据包转发性能上的延迟。这是由于每个数据包到达最终目的地之前,必须多次通过内核以及由内核进行处理。这种设计方案内核性能很快就成为限制的瓶颈。
描述和设计实现:
设计两组实验,第一组,DPI应用直接使用物理NIC。第二组,DPI应用部署于虚拟机,数据包的拿到方式是通过SR-IOV快速路径方式。在对应的性能评测时,分别使用LibPCAP和DPDK。第一个组实验的目的是为了给DPDK提升的DPI应用提供一个相应的基准线。
第一组:
第二组:
使用DPDK作为数据包加速框架的原因是:1.DPDK提供高级的用户级功能;2.DPDK有两种执行模式(pipline model and run-to-completion model)
pipline model:一个计算机内核能够将从NIC得到的数据传递给第二个内核。
run-to-completion model:数据包分布在所有的内核中进行加速处理。
五
- 文章名称:Reasonably Migrating Virtual Machine in NFV-featured Networks
- 发表时间:2017
- 期刊来源: IEEE International Conference on Computer & Information Technology
问题描述:
之前NFV迁移,集中在VNF内部的状态迁移,需要重新编写VNF软件和定制新协议。由于再次软件开发引入了额外的工作和更多的bugs。
工作总结:
本文提出一种直接迁移VM而不是VNF的方法来简化再次软件开发的工作负载。VM迁移引入的传输负载应该降至最小,本文将试下良好的VM迁移以及最小化其迁移时间,同时满足网络带宽需求。最后给出了仿真结果,对未来的方向进行了探讨。
针对稠密图和稀疏图推荐了两种算法来建立迁移的路径,从而降低迁移的成本(用时间作为衡量标准):算法分别为Preallocation和Backtracking(回溯法调整迁移带宽)