文章目录
一、MySQL体系结构
1.管理工具和服务(Management Serveices & Utilities)
2.连接池(Connection Pool)
3.SQL接口(SQL Interface)
4.解析器(Parser)
5.查询优化器(Optimizer)
6.缓存器(Caches & Buffers)
二、MySQL内存结构
2.1 innodb_buffer_bool
2.2 innodb_log_buffer
2.3 key_buffer_size
2.4 innodb_additional_mem_pool_size
2.5 query cache
2.6 sort_buffer_size
2.7 join_buffer_size
2.8 read_buffer_size
2.9 read_rnd_buffer_size
2.10 binlog_cache
2.11 tmp_table_size
三、MySQL物理结构
3.1 数据文件
3.2 日志文件
四、MySQL逻辑结构
4.1 表空间
4.2 段
4.3 区
4.4 页
4.5 行
一、MySQL体系结构
MySQL体系结构经典图
1.管理工具和服务(Management Serveices & Utilities)
系统管理和控制工具,例如备份恢复、MySQL复制、集群等
2.连接池(Connection Pool)
数据库连接是一种关键的、有限的、昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。对数据库连接的管理能显著影响到整个应用程序的伸缩性和健壮性,影响到程序的性能指标。数据库连接池正是针对这个问题提出来的。
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等。也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
3.SQL接口(SQL Interface)
接受用户的SQL命令,并且返回用户需要查询的结果。
4.解析器(Parser)
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
主要功能:
a.将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
b.如果在分解构成中遇到错误,那么就说明这个SQL语句是不合理的
5.查询优化器(Optimizer)
SQL语句在查询之前会使用查询优化器对查询进行优化。使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解:select uid,name from user where gender = 1;
这个select查询先根据where语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果
6.缓存器(Caches & Buffers)
MySQL 8.0已经去掉此功能。
查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
通过LRU算法将数据的冷端溢出,未来得及时刷新到磁盘的数据页,叫脏页。
这个缓存机制是由一系列小缓存组成的。比如表缓存、记录缓存、Key缓存、权限缓存等
二、MySQL内存结构
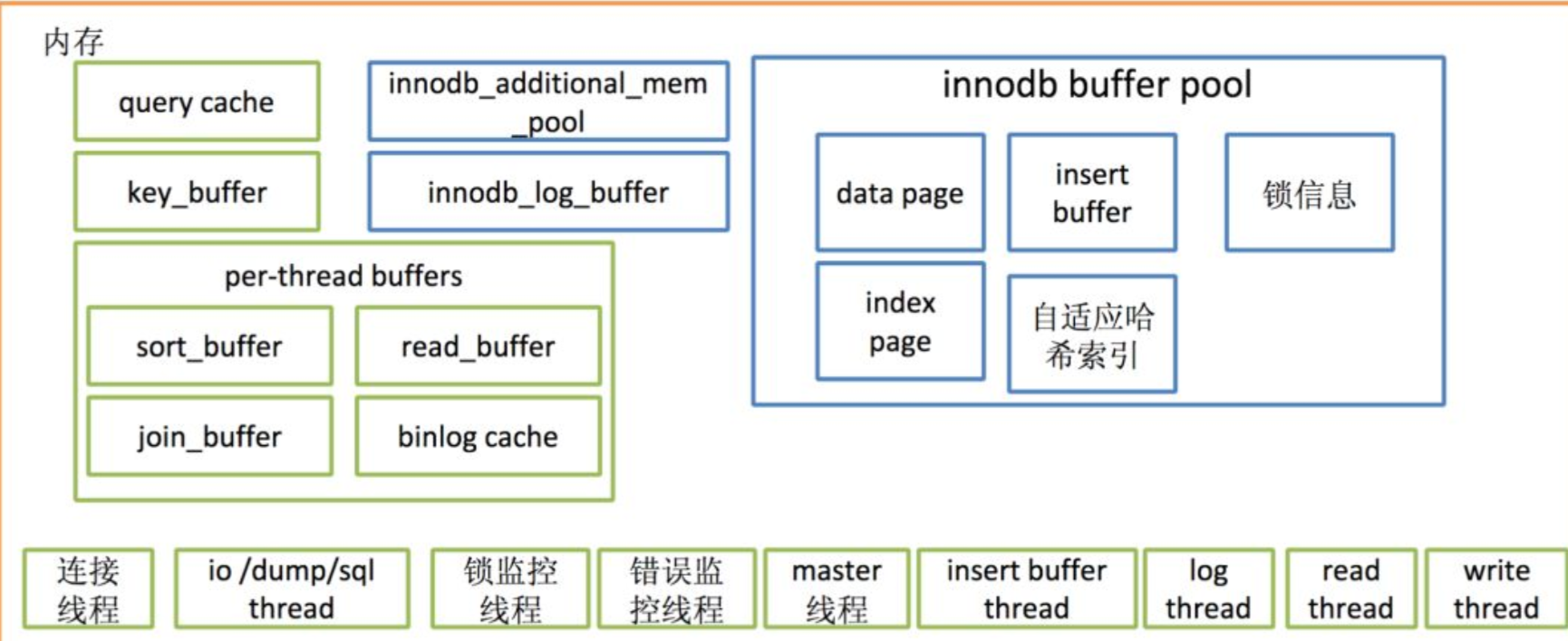
查看内存大小
show variables like "%buffer%";
2.1 innodb_buffer_bool
用来缓存Innodb表的数据、索引、插入缓冲、数据字典等信息。
2.2 innodb_log_buffer
事务在内存中的缓冲,即read log buffer的大小
2.3 key_buffer_size
用于MyISAM存储引擎,缓存MyISAM存储。
引擎表的索引文件(区别于innodb_buffer_poll数据和索引缓存)
2.4 innodb_additional_mem_pool_size
用来缓存数据字典信息和其它内部数据结构的内存池的大小。MySQL 5.7.4中该参数取消。
2.5 query cache
高速查询缓存,MySQL 8.0已经去掉query cache。
2.6 sort_buffer_size
主要用于SQL语句在内存中的临时排序
2.7 join_buffer_size
表连接使用,用于BKA,MySQL 5.6之后开始支持。
2.8 read_buffer_size
表顺序扫描的缓存,只能应用于MyISAM表存储引擎。
2.9 read_rnd_buffer_size
MySQL随机读缓冲区大小,用于做mrr,mrr是MySQL 5.6之后才有的特性。
2.10 binlog_cache
缓存binlog文件
2.11 tmp_table_size
SQL语句在排序或分组时没有用到索引,就会使用临时表空间。
三、MySQL物理结构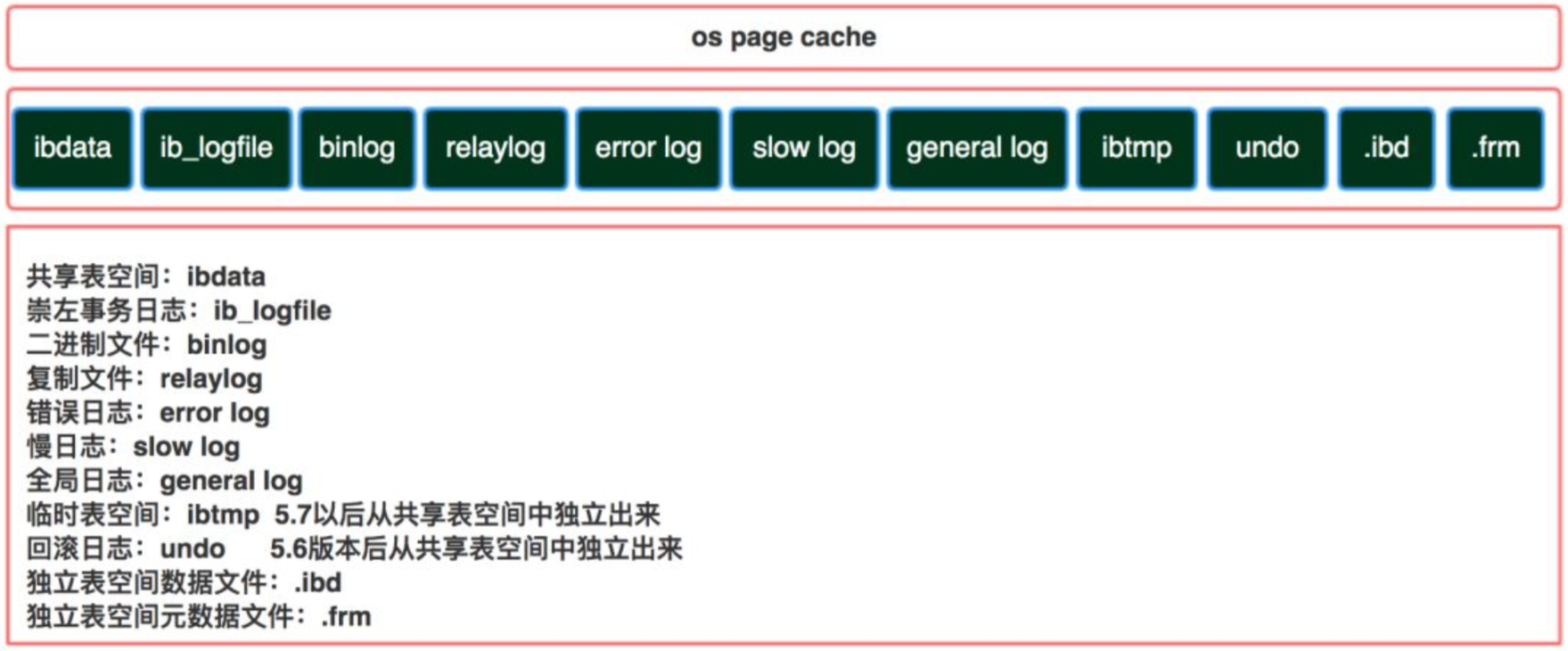
MySQL是通过文件系统对数据和索引进行存储的。
MySQL从物理结构上可分为日志文件和数据索引文件。
日志文件采用顺序IO方式存储,数据文件采用随机IO方式存储。
查看MySQL数据文件在Linux系统中存储目录:
show variables like '%datadir%';
3.1 数据文件
MySQL 8.0开始表结构定义放在系统表里,没有frm文件
InnoDB数据文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息
.ibd文件:使用独享表空间存储表数据和索引信息,一张表对应一个ibd文件。
.ibdata文件:使用共享表空间存储表数据和索引信息,所有表共同使用一个或多个ibdata文件。
MyISAM数据文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息
.myd文件:主要用来存储表数据信息。
.myi文件:主要用来存储表数据文件中任何索引的数据树。
3.2 日志文件
日志文件包含:错误日志(errorlog)、二进制日志(bin log)、通用查询日志(general query log)、慢查询日志(slow query log)、中继日志(relay log)、重做日志(redo log)、回滚日志(undo log)。
错误日志 : 默认是开启的,而且从MySQL 5.5.7以后无法关闭错误日志,错误日志记录了运行过程中遇到的所有严重的错误信息,以及MySQL每次启动和关闭的详细信息。
二进制日志:binlog记录了数据库所有的ddl语句和dml语句,但不包括select语句内容,语句以事件的形式保存,描述了数据的变更顺序,binlog还包括了每个更新语句的执行时间信息。如果是DDL语句,则直接记录到binlog日志,而DML语句,必须通过事务提交才能记录到binlog日志中。生产中开启用于数据备份、恢复及主从复制。
通用查询日志:记录所有的内容,耗性能生产中不开启。
慢查询日志:SQL调优,定位select比较慢的语句,默认是关闭的。
开启方法:
开启慢查询日志
slow_query_log=ON
慢查询的阈值
long_query_time=3
日志记录文件如果没有给出file_name值,默认为主机名,后缀为-slow.log。
如果给出了文件名,但不是绝对路径名,文件则写入数据目录。
slow_query_log_file=file_name
记录执行时间超过long_query_time秒的所有查询,便于收集查询时间比较长的SQL语句。
四、MySQL逻辑结构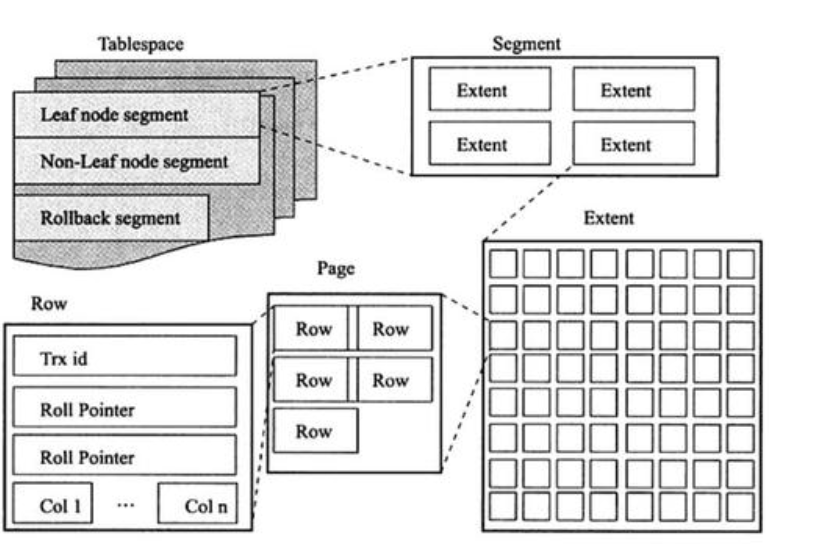
4.1 表空间
表空间可看做是InnoDB存储引擎逻辑结构的最高层
推荐使用独立表空间:
如果使用软链接将大表分配到不同的分区上,易于管理数据文件;
易于监控解决IO资源使用的问题;
易于修复和恢复损坏的数据;
相互独立的,不会影响其它InnoDB表;
导出导入只针对单个表,而不是整个共享表空间;
解决单个文件大小的限制;
对于大量的Delete操作,更易于回收磁盘空间;
碎片较少,易于整理Optimize table;
易于安全审计;
易于备份。
如果InnoDB表已创建后设置innodb_file_per_table,那么数据将不会迁移到单独的表空间上,而是续集使用之前的共享表空间。只有新创建的表才会分离到自己的表空间文件。
4.2 段
表空间由各个段组成,常见的段有数据段、索引段、回滚段等;一个表可以理解为一个独立的段;如果是分区表,每个分区都是一个独立的段。
4.3 区
由64个连续的页组成,每个页大小为16K,即每个区大小为1M;
InnoDB给表或索引分配空间,一次性最少分配一个区1M;
如果是一次性分配1个页16k,这样会拖慢写入的性能。
4.4 页
每页16K,且不能更改。常见的页有:数据页、Undo页、系统页、事务数据页、插入缓冲位图页、插入缓冲空闲列表页、未压缩的二进制大对象页、压缩的二进制大对象页。
4.5 行
行: Innodb存储引擎是面向行的,每页最多允许存放7992行数据。