一、
数组
数据集合、元素、下表
文字处理程序处理字符数据
字符编码
ASCII-英文
字符类型
字符数组
+数组定义
数据类型 数组变量名[表达式....];
+size
sizeof(数据类型名)//计算结果是指定数据类型占用的字节数
或
sizeof(表达式)//计算结果是指定表达式结果类型占用的字节数 表达式可以是单个变量、常量或数组变量,这时sizeof的计算结果就是该变量、常量或数组变量占用的字节数
sizeof(int) sizeof(double)
sizeof(2.0) sizeof(2+3.5)
+访问数组元素
数组变量名[下标1][下标2]....
+数组的整体输入与输出
+数组初始化
int x[3]={2,4,6};
//求数组元素最大值、最小值
#include <isostream>
using namespace std;
int main()
{
int x[6]={1,4,6,2,5,3};
int max,min;//定义变量max保存最大值 min保存最小值
max=x[0];min=x[0];//先假设第0个元素就是最大值,也是最小值
for(int n=1;n<6;n++)
{
if(x[n]>max)max=x[n];//如果x[n]比max大,则这个值是最大值,修改max
if(x[n]<min)min=x[n];//如果x[n]比min小,则这个值是最小值,修改min
}
cout<<"最大值="<<max<<"最小值="<<min<<endl;//
return 0;
}
+数据排序
二、指针与数组
+通过指针变量间接访问数组元素
int x[6]={1,4,6,2,5,3};//定义一维数组变量x,并初始化
int p;
p=&x[0];//将指针变量配指向第0个元素,第0个元素的地址是数组的首地址
cout<<p;//通过指针变量p间接访问第0个元素,显示结果 1
p=&x[1];
cout<<*p;
+首地址
p=&x[0];//将指针变量p指向数组的首地址
p=x;
+指针变量的算数运算
数组变量在内存中连续存放

int型数组 指针变量p指向下一个数组元素 p+=4;
double型数组: p+=8
+指针变量与整数进行加减运算
表达式p±n 的结果仍为T类型的指针,其地址值等于p的地制指: ±n*sizeof(T)
+同类型指针变量之间相减
表达式p1-p2 的结果为int型,数值等于: (p1-p2)/sizeof(T) //下标的差值
+void型指针
不能参与上述运算
sizeof(void)没有确切的定义
#include <isostream>
using namespace std;
int main()
{
int x[6]={1,4,6,2,5,3};
int *p,*p1m*p2;
p=&x[0];//将指针变量p指向第0个元素
for(int n=0;n<6;n++)
cout<<*(p+n)<<",";//通过指针变量与整数的算术运算符依次访问各数组元素
int d;
p1=p+1;//将指针变量p1指向第1个元素
p2=p+4;//将指针变量p2指向第4个元素
d=p2-p1;//指针变量之间的差值等于其所指向数组元素下标之间的差值,即4-1
cout<<d<<endl;//显示结果为3
return 0;
}
+指针的关系运算
+指针的取内容运算
int x[6]={1,4,6,2,5,3},p=x;
通过指针运算符访问数组元素
p,(p+1),(p+2)
通过下标运算符[]访问数组元素
p[0],p[1],p[2]
此时指针相当于数组名
通过数组名访问数组元素
x[0],x[1],x[2]
x,(x+1),(x+2)
数组名相当于指针
+动态内存分配
针对不确定情况
new delete 运算符
静态分配 int x;x=10;
++单个变量的动态分配与释放 :
指针变量名=new 数据类型(初始值);
delete指针变量名;
初始值可省略
计算机执行new运算符时将按照数据类型指定的字节数分配内存空间并初始化,然后返回所分配内存单元的首地址。应当通过赋值语句将该首地址保存到一个预先定义好的同类型指针变量中
执行delete运算符时将按照指针变量中的地址释放指定的内存单元
int *p;
p=new int;
*p=10;
delete p;
int *p=new int(10);//简化
++一维数组的动态分配与释放
指针变量名=new 数据类型[整数表达式];
delete []指针变量名
int *p=new int[5];//动态分配一个int型一维数组变量,包含5个数组元素
*(p+1)=10;//通过指针运算符访问第1个元素,向其中写入数据10
//或过下标运算符访问第一个元素: p[1]=10;
cout<<*(p+1);//通过指针运算符访问第1个元素,读出数据10并显示出来
//或通过下标运算符访问第一个元素: cout<<p[1];
delete []p;//内存使用完后,用delete运算符释放该数组变量所分配的内存空间
#include <ostream>
using namespace std;
int main()
{
int N;
cin>>N;
int *p=new int[N];//动态创建包含N个元素的数组,用于保存数列的前N项
p[0]=0;p[1]=1;//指定数列的前2项
int n;
for(n=2;n<N;n++)//使用循环结构计算出剩余的数列项
p[n]=p[n-1]+p[n-2];//每一项等于其前来2项之和
for(n=0;n<N;n++)
{
cout<<p[n]<<",";
if((n+1)%5==0) cout<<endl;
}
delete[]p;//数组使用结束,动态释放其内存空间
return 0;
}
三、字符类型
+文字处理
字符编码
字符集
编码值
ASCII编码 0-9从小到大;英文字母案字母顺序连续编码;大小写分别编码,小写比大写大32;0表示一种特殊字符,称为空字符
+字符类型
字符类型与单字节整数类型合二为一:char ,一个字节
char ch=77;
+字符常量 'a' 'A' '?' '@' ch='M';等价于ch=77
不可见字符 Esc键(27)
使用转义字符形式 'x1B' '33'
可字符也可以使用转义的形式来书写 例如'M'(77) 转义形式 'x4D' '115'

+字符型运算
可以对字符型数据进行算数运算,运算时,将字符的ASCII码值作为整数参与运算
四、字符数组与文字处理
+字符数组
char str[10]={'h','e','l',l'','o'};
+字符串
""
+字符串常量
"hello" "A"
末尾自动加结束标识� 长度等于字符个数+1
char *p;
p="hello"; 字符串常量赋值给字符型指针变量:字符串在内存中的首地址赋给指针/指针指向字符串的首地址
cout<<"yse
No"; 可插入转义字符
cout<<""yse",'no'"; //"yse",'no'
初始化
char str[10]={'h','e','l',l'','o'};//不初始化默认0
char str[]={'h','e','l',l'','o'};
char str[10]="hello";
char str[]="hello";
char str[3][10]={};
+字符数组的整体输入输出
可以整体输入输出
char str[10];
cin>>str;
cout<<str;
+指针变量的输出
int x,*p=&x;
cout<<p<<endl;
char str[10]="hello";
char *p=str;
cout<<p<<endl;//显示 hello
cout<<p+2<<endl;//显示 llo
cout<<(int *)p<<endl;//显示p中的地址 强制转为其他类型
+常用文字处理算法
//检测有多少非0字符
#include <iostream>
using namespace std;
int main()
{
char str[10]="hello";
int n=0;//定义int型变量n来保存元素下标,初始化为0
while(str[n]!='�')
n++;
cout<<n<<endl;
return 0;
}
//字符串插入
#include <iostream>
using namespace std;
int main()
{
char str[10]="helo";
char ch='l';//插入的字符
char oldch;
int n=2;//在哪个位置插入
do
{
oldch=str[n];//插入前要吧当前位置原来的字符先暂存起来,以便后移
str[n]=ch;//ch保存在当前位置
ch=oldch;//oldch转存到ch中,算法含义:将当前字符作为下一次循环时
//将插入在下一元素位置的字符,这样后移操作被转为在下一位置的插入操作
n++;//转入下一元素位置,循环做插入操作
}while(ch!='�');//如果ch是结束符,则停止循环
str[n]='�';//为插入操作后的字符串添加结束符'�'
cout<<str<<endl;
return 0;
}
//字符串拷贝
#include <iostream>
using namespace std;
int main()
{
char str1[10]="hello";
char str2[20];//将str1种的字符串拷贝到str2
//注意 定义str2时的数组长度应大于字符串长度,否则会越界
int n=0;//保存元素下标
while(str1[n]!='�')//通过循环结构从第0个元素开始拷贝
{
str2[n]=str1[n];//拷贝第n个元素
n++;//下标加1 继续拷贝下一个元素
}
str2[n]='�';
cout<<str2<<endl;
return 0;
}
五、中文处理
+汉子字符编码标准 例如GB2312
+中文操作系统 例如中文windows
+处理中文的应用软件 例如中文word
char str[]="你好,hello";
cout<<str<<endl;
+字符编码标准
ASCII 单字节字符集
汉子编码 双字节字符集
ANSI : 英文+中文、英文+日文 缺陷:前面不能中文+日文
Unicode编码: 英文+中文+日文+......
+基于ANSI编码的中文处理
是否具有适合中国用户使用的中文界面
是否需要处理中文,例如对中文字符串的插入、删除等操作
GB2312,6763个汉字,某些嵌入式系统还在用
GBK,GB2312的拓展,21000多个汉字;
基于ANSI的中文操作系统
两套字符集,
一套ASCII 单字节存储 码值范围0~127 7位 最高位都为0,
一套GBK 双字节存储 第1位称为前导字节 =1
可根据第一位区分字符集
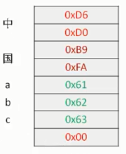
"中国abc"字符串在内存中占 4+3+1 8个字节(结束字符)
在C++语言中,中文字符串和英文字符串在以下几个方面是完全一样的:
都使用字符数组来存储
都使用空字符'�'作为字符串结束标记
都可以使用cin指令直接从键盘输入,并保存到某个字符数组中
都可以使用cout指令将保存在某个字符数组中的字符串输出到显示器上
c++中 中文可以用"中文",不能用'中文'
#include <iostream>
using namespace std;
int main()
{
char str[20];//字符数组 保存键盘输入字符串
cin>>str;
char cstr[20];//字符数组 保存str中筛选出的中文
int n,cn;//n str下标,cn cstr下标
n=0;cn=0;
while(str[n]!='�')
{
if((str[n] & 0x80)!=0)//通过位运算检查最高位是否为0
{
cstr[cn]=str[n];cstr[cn+1]=str[n+1];//最高位为1,双字节GBK字符;复制
cn+=2;n+=2;//中文字符:下标加2,转到下1字符
}
else
n++;//英文字符:下标加1,转到下一字符
}
cstr[cn]='�';
cout<<cstr<<endl;
return 0;
}
+基于Unicode编码的中文处理
通用字符集(全放一块统一编码 超十万字符)
“中”的GBK编码:0xD6D0
unicode编码:0x4E2D
占几个字节:不同的操作系统和编程语言都不一样,32位windows和VC6.0 一个Unicode字符占2个字节,linux和Java用4个字节,因为对Unicode的实现方式不同
Unicode编码的3种实现方式
UTF8、UTF16、UTF32
UTF表示转换格式,8、16、32表示存储位数,
UTF32 4个字节
UTF16 定长编码,都是2字节,
UTF8 变长编码,存储1个英文字符需1个字节,存储汉字可能需要3-4个字节,增加了算法的复杂度
宽字符类型 wchar_t
c++将unicode编码称为宽字符
VC6.0中宽字符占2个字节,并按无符号格式存储Unicode编码
c++用L来执行宽字符常量 和 宽字符串常量
'a' 字符常量
L'a' 宽字符常量
L"中国abc"

wchar_t wch=L'中';
wchar_t wstr[6]=L"中国abc";
+宽字节字符的输入输出
wcin
wcout
wcout
输出宽字符串需改用wcout指令。wcout指令在显示中文时,首先将Unicode编码转换成GBK编码,然后再显示GBK编码的中文字符。使用wcout指令之前需将语言设置为简体中文,即GBK编码
wcin
输入宽字符串需改用wcin指令。wcin指令在输入中文时,先转换成GBK编码,然后再将GBK编码转换成Unicode编码。使用wcin指令之前需将语言设置为简体中文,即GBK编码