自数十年前首次引入以来,我们了解到分布式系统可以实现我们甚至在他们之前都无法想到的用例,但是它们也引入了各种新问题
当这些系统稀少而简单时,工程师通过减少远程交互的数量来应对增加的复杂性。处理分发的最安全方法是尽可能避免分发,即使这意味着跨各种系统复制逻辑和数据也是如此。
但是,作为一个行业,我们的需求使我们进一步发展,从几台大型中央计算机到成千上万的小型服务。在这个新世界中,我们必须开始勇往直前,应对新的挑战和悬而未决的问题,首先要以个案的方式完成临时解决方案,然后再采用更复杂的解决方案。当我们发现有关问题领域的更多信息并设计更好的解决方案时,我们开始将一些最常见的需求明确化为模式,库,最后是平台。
当我们第一次开始联网计算机时发生了什么
由于人们首先想到让两台或更多台计算机相互通信,因此他们设想了以下内容:
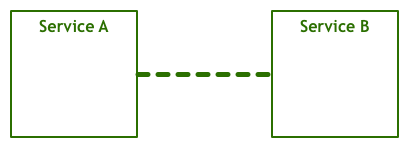
一种服务与另一种服务进行对话以实现最终用户的某些目标。这显然是过于简化的视图,因为缺少了在代码操作的字节与通过电线发送和接收的电信号之间转换的许多层。但是,对于我们的讨论而言,抽象就足够了。让我们通过将网络堆栈显示为不同的组件来添加更多细节:
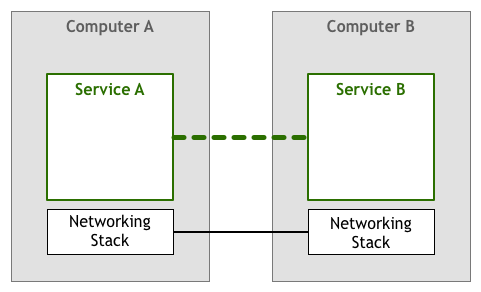
自1950年代以来,一直在使用上述模型的变体。最初,计算机是稀有且昂贵的,因此两个节点之间的每个链接都是经过精心设计和维护的。随着计算机变得越来越便宜,越来越流行,连接的数量和通过它们的数据量急剧增加。随着人们越来越依赖网络系统,工程师需要确保他们构建的软件能够满足其用户所需的服务质量。
而且,要想达到所需的质量水平,还需要回答许多问题。人们需要找到机器相互查找的方式,通过同一根导线处理多个同时连接,允许机器在未直接连接时彼此对话,在网络上路由数据包,对流量进行加密等。
其中,有一个称为流控制的东西,我们将使用它作为示例。流控制是一种机制,可以防止一台服务器发送比下游服务器可以处理的数据包更多的数据包。这是必要的,因为在网络系统中,您至少有两台彼此不了解的独立计算机。计算机A以给定的速率向计算机B发送字节,但是不能保证B将以一致且足够快的速度处理接收到的字节。例如,B可能正在忙于并行运行其他任务,或者数据包可能无序到达,并且B被阻塞,等待应首先到达的数据包。这意味着不仅A不会达到B的预期性能,而且还可能使情况变得更糟,因为它可能会使B超载,现在B必须将所有这些传入数据包排队进行处理。
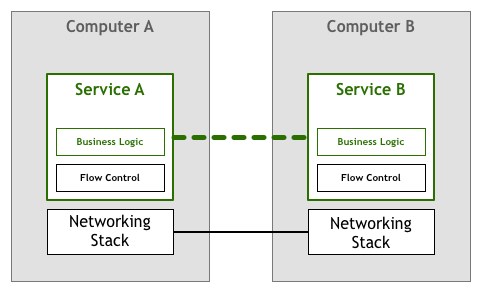
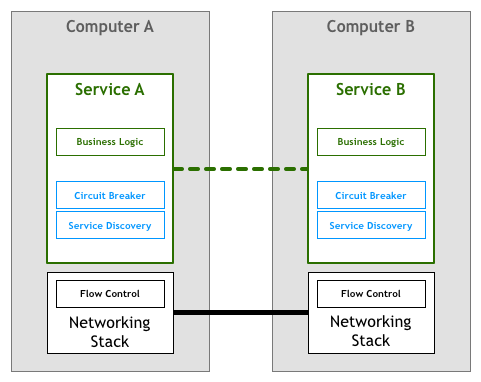
一段时间以来,人们期望构建网络服务和应用程序的人们能够应对上面编写的代码中提出的挑战。在我们的流控制示例中,这意味着应用程序本身必须包含逻辑,以确保我们不会因数据包而使服务过载。繁重的网络逻辑与您的业务逻辑并存。在我们的抽象图中,将是这样的:
幸运的是,技术迅速发展,并且很快有足够的标准(如TCP / IP)将解决方案集成到网络堆栈本身中,以实现流控制和许多其他问题。这意味着该代码段仍然存在,但已从您的应用程序中提取到了操作系统提供的基础网络层:
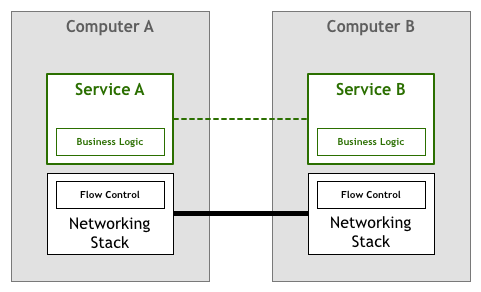
这种模式取得了巨大的成功。很少有组织不能仅使用商品操作系统随附的TCP / IP堆栈来推动业务发展,即使需要高性能和可靠性也是如此。
当我们第一次开始使用微服务时发生了什么
多年来,计算机变得更便宜,越来越普及,并且上述网络堆栈已被证明是可靠连接系统的实际工具集。有了更多的节点和稳定的连接,该行业就玩起了各种各样的网络系统,从细粒度的分布式代理和对象到由较大但仍然分布很广的组件组成的面向服务的体系结构。
这种极端的分布带来了许多有趣的高级用例和收益,但同时也带来了一些挑战。其中一些挑战是全新的,但其他挑战只是我们在谈论原始网络时所讨论的挑战的更高版本。
在90年代,Peter Deutsch和他在Sun Microsystems的工程师合编了“分布式计算的8个谬误”,其中列出了人们在使用分布式系统时倾向于做出的一些假设。Peter的观点是,这些可能在更原始的网络体系结构或理论模型中是正确的,但在现代世界中却不成立:
- 网络可靠
- 延迟为零
- 带宽无限大
- 网络安全
- 拓扑不变
- 只有一名管理员
- 运输成本为零
- 网络是同质的
将上面的列表宣布为“谬误”意味着工程师不能仅仅忽略这些问题,而必须对其进行明确处理。
为了使问题进一步复杂化,迁移到甚至在我们通常称为微服务体系结构的分布式系统中,在可操作性方面提出了新的需求。之前,我们已经详细讨论了其中一些问题,但是以下是其中必须处理的内容的快速列表:
- 快速配置计算资源
- 基本监控
- 快速部署
- 易于调配存储
- 轻松进入边缘
- 认证/授权
- 标准化RPC
因此,尽管数十年前开发的TCP / IP堆栈和通用网络模型仍然是使计算机相互通信的强大工具,但更复杂的体系结构又引入了另一层要求,这是必须由从事此工作的工程师来满足的。这样的架构。
例如,考虑服务发现和断路器,这是用于解决上面列出的一些弹性和分配挑战的两种技术。
随着历史趋向于重演,基于微服务构建系统的第一批组织遵循的策略与前几代联网计算机的策略非常相似。这意味着处理上面列出的需求的责任留给了编写服务的工程师。
服务发现是自动查找哪些服务实例满足给定查询的过程,例如,称为的服务Teams需要查找Players属性environment设置为的称为服务的实例。production。您将调用一些服务发现过程,该过程将返回合适的服务器列表。对于更整体的体系结构,这是一个简单的任务,通常使用DNS,负载均衡器和一些有关端口号的约定来实现(例如,所有服务将其HTTP服务器绑定到端口8080)。在更加分散的环境中,任务开始变得更加复杂,以前可以盲目地依靠其DNS查找来找到依赖关系的服务现在必须处理诸如客户端负载平衡,多个不同环境(例如,登台与生产)的问题。 ),地理位置分散的服务器等。如果您之前只需要一行代码来解析主机名,那么现在您的服务就需要很多样板代码来处理更高版本所带来的各种情况。
断路器是Michael Nygard在他的书Release It中分类的一种模式。我喜欢Martin Fowler对该模式的总结:
断路器的基本原理非常简单。将受保护的函数调用包装在断路器对象中,该对象将监视故障。一旦故障达到某个阈值,断路器将跳闸,并且所有对该断路器的进一步呼叫都会返回错误,而根本不会进行受保护的呼叫。通常,如果断路器跳闸,您还需要某种监视器警报。
这些都是出色的简单设备,可为您的服务之间的交互增加更多的可靠性。但是,就像其他所有内容一样,随着分布水平的提高,它们往往会变得更加复杂。系统中出现问题的可能性随着分布的增加而呈指数级增长,因此,即使诸如“如果断路器跳闸时出现某种监视器警报”之类的简单事情也不一定变得直截了当。一个组件中的一个故障会在许多客户端和客户端的客户端之间造成一连串的影响,从而触发成千上万的电路同时跳闸。过去仅需几行代码,现在又需要大量样板来处理仅在这个新世界中存在的情况。
实际上,上面列出的两个示例很难正确实现,以至于大型,复杂的库(例如Twitter的Finagle和Facebook的Proxygen)作为避免在每个服务中重写相同逻辑的手段而变得非常流行。
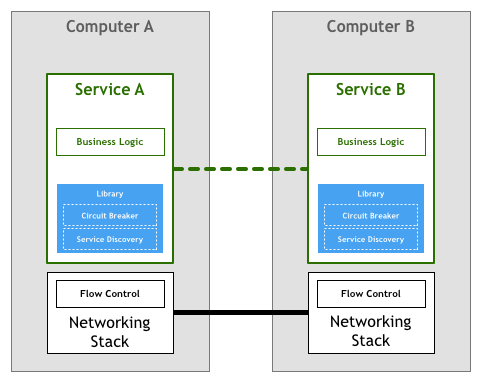
上面描述的模型被大多数开创了微服务架构的组织所采用,例如Netflix,Twitter和SoundCloud。随着系统中服务数量的增加,他们还偶然发现了此方法的各种缺点。
即使使用像Finagle这样的库,最昂贵的挑战可能是组织仍需要花费其工程团队的时间来建立将库与其他生态系统联系起来的粘合剂。根据我在SoundCloud和DigitalOcean的经验,我估计在100-250个工程师组织中采用这种策略后,需要将1/10的员工专用于构建工具。有时,这笔费用是明确的,因为工程师被分配到了专门负责构建工具的团队中,但是价格标签通常是不可见的,因为随着您花费时间在产品上工作,价格标签本身就体现出来了。
第二个问题是,以上设置限制了可用于微服务的工具,运行时和语言。微服务库通常是为特定平台编写的,无论是编程语言还是JVM之类的运行时。如果组织使用库支持的平台以外的平台,则通常需要将代码移植到新平台本身。这浪费了宝贵的工程时间。工程师不必再致力于核心业务和产品,而必须再次构建工具和基础架构。这就是为什么诸如SoundCloud和DigitalOcean之类的中型组织决定仅支持其内部服务的一个平台的原因,分别是Scala和Go。
这个模型值得讨论的最后一个问题是治理。库模型可以抽象化解决微服务体系结构需求所需功能的实现,但是它本身仍然是需要维护的组件。确保成千上万的服务实例使用相同或至少兼容的库版本并非易事,并且每次更新都意味着集成,测试和重新部署所有服务,即使该服务本身未遭受任何损害也是如此。改变。
下一步是合乎逻辑的
与我们在网络堆栈中看到的类似,非常需要将大规模分布式服务所需的功能提取到基础平台中。
人们使用HTTP等高级协议编写非常复杂的应用程序和服务,而无需考虑TCP如何控制其网络上的数据包。这种情况正是我们对微服务所需要的,在微服务中,从事服务的工程师可以专注于他们的业务逻辑,避免浪费时间编写自己的服务基础结构代码或管理整个团队中的库和框架。
将这个想法整合到我们的图表中,我们可能会得到如下所示的结果:
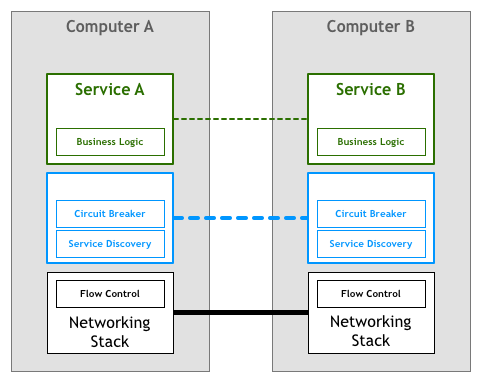
不幸的是,更改网络堆栈以添加此层不是可行的任务。许多从业人员发现的解决方案是将其作为一组代理来实现。这里的想法是,服务不会直接连接到其下游依赖项,而是所有流量都将通过一小段软件透明地添加所需的功能。
在这个空间里首次有记载的发展所用的概念,侧柜。边车是一个辅助过程,可在您的应用程序旁边运行,并为它提供额外的功能。2013年,Airbnb撰写了有关Synapse和Nerve的开源文件,其中包括Sidecar的开源实现。一年后,Netflix推出了Prana,这是一种辅助工具,致力于使非JVM应用程序能够从其NetflixOSS生态系统中受益。在SoundCloud,我们制造了辅助工具,使我们的Ruby传统可以使用为JVM微服务构建的基础结构。
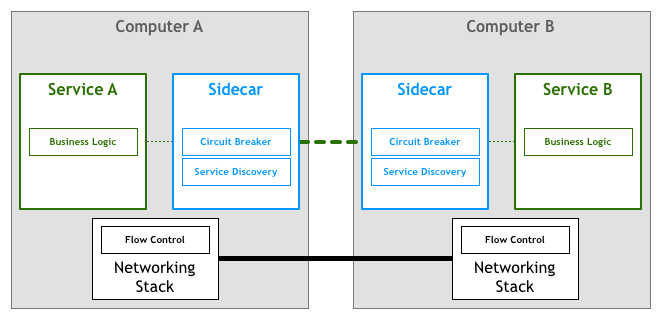
尽管有许多此类开放源代码代理实现,但它们往往旨在与特定的基础结构组件一起使用。例如,在服务发现方面,Airbnb的Nerve&Synapse假定服务已在Zookeeper中注册,而对于Prana,则应使用Netflix自己的Eureka服务注册表。
随着微服务架构的日益普及,我们最近看到了新一轮的代理浪潮,这些代理足够灵活以适应不同的基础架构组件和偏好。这个领域的第一个广为人知的系统是Linkerd,它是由Buoyant基于工程师在Twitter微服务平台上的先前工作而创建的。很快,Lyft的工程团队宣布了Envoy,它遵循类似的原则。
服务网格
在这种模型中,您的每项服务都将有一个伴随代理服务。鉴于服务仅通过sidecar代理相互通信,因此我们最终得到了类似于下图的部署:
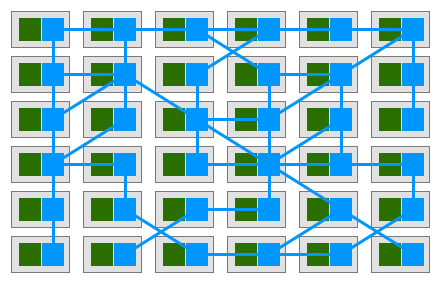
Buoyant的首席执行官William Morgan观察到代理之间的互连形成了一个网状网络。2017年初,William为该平台编写了一个定义,并将其称为Service Mesh:
服务网格是用于处理服务到服务通信的专用基础结构层。它负责通过构成现代云原生应用程序的复杂服务拓扑可靠地传递请求。实际上,服务网格通常被实现为轻量级网络代理的阵列,这些轻量级网络代理与应用程序代码一起部署,而无需了解应用程序。
他的定义中最有力的方面可能是,它摆脱了将代理视为独立组件的想法,并认识到它们形成的网络本身就是有价值的东西。
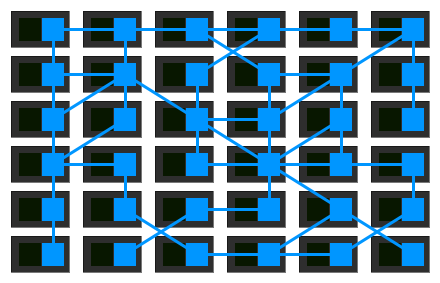
随着组织将其微服务部署移至更复杂的运行时(如Kubernetes和Mesos),人员和组织已开始使用那些平台提供的工具来正确实现此网状网络的思想。他们正从一组独立工作的独立代理转移到一个适当的,有点集中的控制平面。
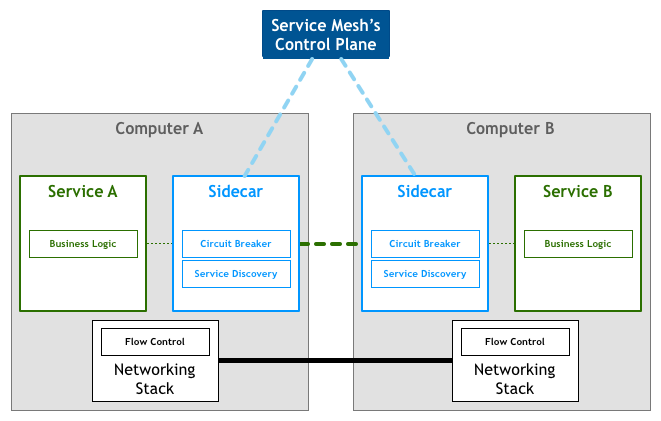
查看鸟瞰图,我们看到实际的服务流量仍然直接从代理流向代理,但是控制平面知道每个代理实例。控制平面使代理可以实现诸如访问控制和指标收集之类的事情,这需要合作:
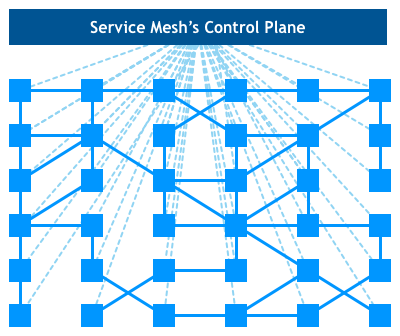
最近宣布的Istio项目是此类系统的最突出示例。
全面了解服务网格在大规模系统中的影响还为时过早。这种方法的两个好处对我来说已经很明显了。首先,不必编写定制软件来处理微服务体系结构的最终商品代码,这将使许多较小的组织可以享受以前仅大型企业才能使用的功能,从而创建各种有趣的用例。第二个问题是,这种体系结构可能使我们最终实现使用最佳工具/语言完成工作的梦想,而不必担心每个平台的库和模式的可用性。
参考链接
https://philcalcado.com/2017/08/03/pattern_service_mesh.html