一、什么是库
1. 概念
库是写好的现有的,成熟的,可以复用的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在意义非同寻常。
本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。库有两种:静态库(.a、.lib)和动态库(.so、.dll),所谓静态、动态是指链接。
2. 将一个程序编译成可执行程序的步骤

3. 静态链接方式和动态链接方式

4. 静态库
4.1 概念
之所以称为静态库,是因为在链接阶段,会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件(.out)中。因此对应的链接方式称为静态链接。试想一下,静态库与汇编生成的目标文件一起链接为可执行文件,那么静态库必定跟.o文件格式相似。其实一个静态库可以简单看成是一组目标文件(.o 文件)的集合,即很多目标文件经过压缩打包后形成的一个文件。
静态库特点总结:
- 静态库对函数库的链接是放在编译时期完成的。
- 程序在运行时与函数库再无瓜葛,移植方便。
- 浪费空间和资源,因为所有相关的目标文件与牵涉到的函数库被链接合成一个可执行文件
下面编写一些简单的四则运算C++类,将其编译成静态库给他人用,头文件如下所示:
1 class StaticMath
2 {
3 public:
4 StaticMath(void);
5 ~StaticMath(void);
6
7 static double add(double a, double b);//加
8 static double sub(double a, double b);//减
9 static double mul(double a, double b);//乘
10 static double div(double a, double b);//除
11
12 };
Linux下使用 ar 工具,将目标文件压缩到一起,并且对其进行编号和索引,以便于查找和检索。一般创建静态库的步骤如图所示:
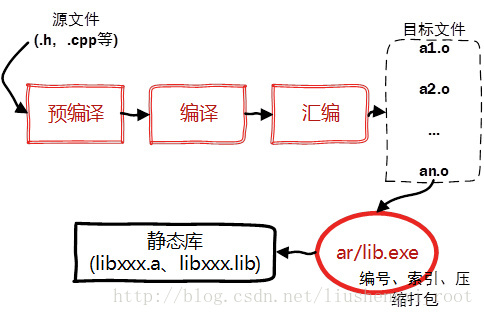
4.2 Linux下创建与使用静态库
4.2.1 Linux静态库命名规则
Linux静态库命名规范,必须*是”lib[your_library_name].a”:lib为前缀,中间是静态库名,扩展名为 .a
创建静态库(.a)
通过上面的流程可以知道,Linux创建静态库过程如下:
- (1)首先,将代码文件编译成目标文件.o(StaticMath.o)
1 //这是StaticMath.cpp 文件 2 #include<iostream> 3 #include"myhead.h" 4 using namespace std; 5 double StaticMath::add(double a,double b) 6 { 7 return a+b; 8 } 9 double StaticMath::sub(double a,double b) 10 { 11 return a-b; 12 } 13 double StaticMath::mul(double a,double b) 14 { 15 return a*b; 16 } 17 double StaticMath::div(double a,double b) 18 { 19 return a/b ; 20 }1 g++ -c StaticMath.cpp注意带参数-c,将其编译为.o 文件,否则直接编译为可执行文件
- (2)然后,通过 ar 工具将目标文件打包成 .a 静态库文件,最好编写makefile文件(CMake等等工程管理工具)来生成静态库,输入多个命令太麻烦了。格式为:ar rcs + 静态库的名字(libMytest.a) + 生成的所有的.o
1 ar -jcv -f libstaticmath.a StaticMath.o - (3) 使用静态库
编写使用上面创建的静态库的测试代码:
1 #include "StaticMath.h"
2 #include <iostream>
3 using namespace std;
4
5 int main(int argc, char* argv[])
6 {
7 double a = 10;
8 double b = 2;
9
10 cout << "a + b = " << StaticMath::add(a, b) << endl;
11 cout << "a - b = " << StaticMath::sub(a, b) << endl;
12 cout << "a * b = " << StaticMath::mul(a, b) << endl;
13 cout << "a / b = " << StaticMath::div(a, b) << endl;
14
15 return 0;
16 }
Linux下使用静态库,只需要在编译的时候,指定静态库的搜索路径(-L选项)、指定静态库名(不需要lib前缀和.a后缀,-l选项)。
1 g++ TestStaticLibrary.cpp -L../StaticLibrary -lstaticmath
-L:表示要连接的库所在目录
-l (小写L):指定链接时需要的动态库,编译器查找动态连接库时有隐含的命名规则,即在给出的名字前面加上lib,后面加上.a或.so来确定库的名称。
4.3 gcc 参数简介
这里只写了几个关键的,其它的可以在这里GCC 参数详解查找。
-E:只执行到预处理阶段,不生成任何文件
-S:将C代码转换为汇编代码(.s 汇编文件)
-c:仅执行编译操作,不进行连接操作(.o 机器码)
-o:指定生成的输出文件(.out 可执行文件)
-L:告诉gcc去哪里找库文件。 gcc默认会在程序当前目录、/lib、/usr/lib和/usr/local/lib下找对应的库
-l:用来指定具体的静态库、动态库是哪个
-I: 告诉gcc去哪里找头文件
5. 动态库
5.1 为什么还需要动态库?
为什么需要动态库,其实也是静态库的特点导致。
- 空间浪费是静态库的一个问题。
- 另一个问题是静态库对程序的更新、部署和发布页会带来麻烦。如果静态库liba.lib更新了,所以使用它的应用程序都需要重新编译、发布给用户(对于玩家来说,可能是一个很小的改动,却导致整个程序重新下载,全量更新)
动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。动态库在程序运行是才被载入,也解决了静态库对程序的更新、部署和发布页会带来麻烦。用户只需要更新动态库即可。
5.2 动态库特点
- 动态库把对一些库函数的链接载入推迟到程序运行的时期。
- 可以实现进程之间的资源共享。(因此动态库也称为共享库)
- 将一些程序升级变得简单。甚至可以真正做到链接载入完全由程序员在程序代码中控制(显式调用)。
5.3 Linux下创建与使用动态库
5.3.1 Linux动态库的命名规则
动态链接库的名字形式为 libxxx.so,前缀是lib,后缀名为“.so”,ib + 名字 + .so
5.3.2 创建动态库(.so)
编写四则运算动态库代码
1 // myhead.h 文件
2 class DP
3 {
4 public:
5 static void print_111();
6 static void print_222();
7 static void print_333();
8 };
9
10 //print_333 文件(print_111和print_222 文件与print_333 文件类似)
11 #include<iostream>
12 #include"myhead.h"
13 using namespace std;
14 void DP::print_333()
15 {
16 cout << "333333333333333" << endl ;
17 }
首先,生成目标文件,此时要加编译器选项-fpic
1 g++ -fPIC -c print_*.cpp
-fPIC 创建与地址无关的编译程序(pic,position independent code),是为了能够在多个应用程序间共享。
然后,生成动态库,此时要加链接器选项 -share
1 g++ -shared -o libtest.so print_*.o
-shared 指定生成动态链接库。
其实上面两个步骤可以合并为一个命令:
1 g++ -fPIC -shared -o libtest.so print_*.cpp
生成libtest.so 动态库
5.3.3 使用动态库
lld命令:用于查看可执行程序依赖的so动态链接库文件
1 [root@localhost ld.so.conf.d]# ldd /usr/local/tengine/sbin/nginx
2 linux-vdso.so.1 => (0x00007ffc9fd66000)
3 libpthread.so.0 => /lib64/libpthread.so.0 (0x00007ff1c5f56000)
4 libdl.so.2 => /lib64/libdl.so.2 (0x00007ff1c5d52000)
5 libcrypt.so.1 => /lib64/libcrypt.so.1 (0x00007ff1c5b1a000)
6 libjemalloc.so.2 => /usr/jemalloc/lib/libjemalloc.so.2 (0x00007ff1c58cb000)
7 libc.so.6 => /lib64/libc.so.6 (0x00007ff1c550a000)
8 /lib64/ld-linux-x86-64.so.2 (0x00007ff1c6187000)
9 libfreebl3.so => /lib64/libfreebl3.so (0x00007ff1c5306000)
显示not found的提示说明没有找到该库文件,则程序运行会报错,手动添加就可以了
编写使用动态库的测试代码:
1 // testDP.cpp 文件
2 #include "myhead.h"
3 #include <iostream>
4 using namespace std;
5
6 int main(void)
7 {
8 DP::print_111();
9 DP::print_222();
10 DP::print_333();
11 return 0;
12 }
引用动态库编译成可执行文件(跟静态库方式一样):
1 g++ testDP.cpp -L./ -ltest
然后运行:./a.out,报错如下:

这是由于程序运行时没有找到动态链接库造成的。程序编译时链接动态链接库和运行时使用动态链接库的概念是不同的,在运行时,系统能够知道其所依赖的库的名字,但是还需要知道绝对路径。有几种办法可以解决此种问题:
(1) 因为系统会按照 LD_LIBRARY_PATH 环境变量来查找除了默认路径之外( /lib, /usr/lib, /usr/local/lib)的共享库(动态链接库)的其他路径,就像PATH变量一样!所以我们可以修改该环境变量来解决这个问题。
1 export LD_LIBRARY_PATH=/home/hp/LinuxC:$LD_LIBRARY_PATH
也就是将我们发布的共动态库所在的路径加入系统的查找选项中。动态库的加载顺序为LD_PRELOAD>LD_LIBRARY_PATH>/etc/ld.so.cache>/lib>/usr/lib。
(2)使用LD_PRELOAD,如果使用了这个变量,系统会优先去这个路径下寻找,如果找到了就返回,不在往下找了
1 LD_PRELOAD=./libtest.so ./a.out
(3)将动态链接库赋值一份到默认路径
1 sudo cp libtest.so /usr/lib
(4)因为系统中的配置文件/etc/ld.so.conf是动态链接库的搜索路径配置文件,在程序运行时会去读取该文件,那么我们就将我们自己编写的库的路径写到该配置文件中去即可。

在最后一行加入 /home/liushengxi/C-/自建库/test,运行ldconfig ,该命令会重建/etc/ld.so.cache文件
二、可执行程序的链接、装载
《程序员的自我修养-链接装载与库》是一本值得推荐的书,主要介绍系统软件的运行机制和原理,涉及在Windows和Linux两个系统平台上,一个应用程序在编译、链接和运行时刻所发生的各种事项,包括:代码指令是如何保存的,库文件如何与应用程序代码静态链接,应用程序如何被装载到内存中并开始运行,动态链接如何实现,C/C++运行库的工作原理,以及操作系统提供的系统服务是如何被调用的。
2.1 基础知识
许多IDE和编译器将编译和链接的过程合并在一起,称为构建(Build),使用起来非常方便。但只有深入理解其中的机制,才能看清许多问题的本质,正确解决问题。
一般的编译过程可以分解为4个步骤,预处理,编译,汇编和链接:
- 预编译:处理源代码中的以”#”开始的预编译指令,如”#include”、”#define”等。
- 编译:把预处理完的文件进行一系列的词法分析、语法分析、语义分析及优化后产生相应的汇编代码文件,是程序构建的核心部分,也是最复杂的部分之一。
- 汇编:将汇编代码根据指令对照表转变成机器可以执行的指令,一个汇编语句一般对应一条机器指令。
- 链接:将多个目标文件综合起来形成一个可执行文件。
而对于第2步,编译由编译器完成器,编译器是将高级语言翻译成机器语言的一个工具,其具体步骤包括:
- 词法分析:将源代码程序输入扫描器,将源代码字符序列分割成一系列记号(Token)。
- 语法分析:对产生的记号使用上下文无关语法进行语法分析,产生语法树。
- 语义分析:进行静态语义分析,通常包括声明和类型的匹配,类型的转换。
- 中间语言生成:使用源代码优化器将语法树转换成中间代码并进行源码级的优化。
- 目标代码生成:使用代码生成器将中间代码转成依赖于具体机器的目标机器代码。
- 目标代码优化:使用目标代码优化器对目标代码进行优化,比如选择合适的寻址方式、使用位移替代乘法、删除多余指令等。
如果一个源代码文件中有变量或函数等符号定义在其他模块,那么编译后得到的目标代码中,该符号的地址并没有确定下来,因为编译器不知道到哪里去找这些符号,事实上这些变量和函数的最终地址要在链接的时候才能确定。现代的编译器只是将一个源代码编译成一个未链接的目标文件,最终由链接器将这些目标文件链接起来形成可执行文件。
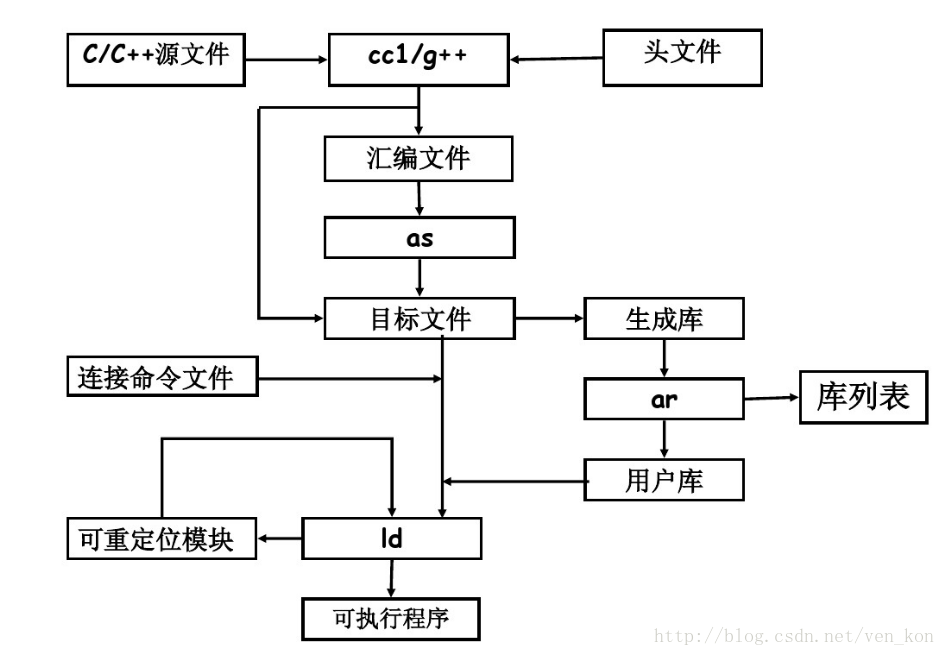
先以 helloworld.c 程序为例,搞清楚可执行文件是如何生成的:
1 #include <stdio.h>
2 int main(void)
3 {
4 printf("hello, world!
");
5 return 0;
6 }
(1)预处理,处理代码中的宏定义和 include 文件,并做语法检查
1 gcc -E helloworld.c -o helloworld.cpp
(2)编译,生成汇编代码
1 gcc -S helloworld.cpp -o helloworld.s
(3)汇编,生成汇编代码
1 gcc -c helloworld.s -o helloworld.o
(4)链接,生成可执行文件
1 gcc helloworld.o -o helloworld
具体过程可以用下面的图片表示,各种文件格式之间的关系如下:
2.2 ELF 文件格式
编译器编译源代码后生成的文件称为目标文件,事实上,目标文件是按照可执行文件的格式存储的,二者结构只是稍有不同。Linux下的目标文件和可执行文件可以看成一种类型的文件,统称为ELF文件,一般有以下几类:
- 可重定位文件,如:.o 文件,包含代码和数据,可以被链接成可执行文件或共享目标文件,静态链接库属于这类。
- 可执行文件,如:/bin/bash 文件,包含可直接执行的程序,没有扩展名。
- 共享目标文件,如:.so 文件,包含代码和数据,可以跟其他可重定位文件和共享目标文件链接产生新的目标文件,也可以跟可执行文件结合作为进程映像的一部分。
ELF 文件由 ELF header 和文件数据组成,文件数据包括:
- Program header table, 程序头:描述段信息
- .text, 代码段:保存编译后得到的指令数据
- .data, 数据段:保存已经初始化的全局静态变量和局部静态变量
- Section header table, 节头表:链接与重定位需要的数据
除了这几个常用的段之外,ELF可能包含其他的段,保存与程序相关的信息,如:
1 .comment 编译器版本信息
2 .debug 调试信息
3 .dynamic 动态链接信息
4 .hash 符号哈希表
5 .line 调试时的行号表,源代码行号与编译后指令的对应表
6 .note 额外的比编译器信息
7 .strtab String Table,字符串表,存储用到的各种字符串
8 .symtab Symbol Table,符号表
9 .shstrtab Section String Table,段名表
10 .plt 动态链接跳转表
11 .got 动态链接全局入口表
12 .init 程序初始化代码段
13 .fini 程序终结代码段
1 Section Headers:
2 [Nr] Name Type Addr Off Size ES Flg Lk Inf Al
3 [ 0] NULL 00000000 000000 000000 00 0 0 0
4 [ 1] .group GROUP 00000000 000034 000008 04 12 16 4
5 [ 2] .text PROGBITS 00000000 00003c 000078 00 AX 0 0 1
6 [ 3] .rel.text REL 00000000 000338 000048 08 I 12 2 4
7 [ 4] .data PROGBITS 00000000 0000b4 000008 00 WA 0 0 4
8 [ 5] .bss NOBITS 00000000 0000bc 000004 00 WA 0 0 4
9 [ 6] .rodata PROGBITS 00000000 0000bc 000004 00 A 0 0 1
10 [ 7] .text.__x86.get_p PROGBITS 00000000 0000c0 000004 00 AXG 0 0 1
11 [ 8] .comment PROGBITS 00000000 0000c4 000012 01 MS 0 0 1
12 [ 9] .note.GNU-stack PROGBITS 00000000 0000d6 000000 00 0 0 1
13 [10] .eh_frame PROGBITS 00000000 0000d8 00007c 00 A 0 0 4
14 [11] .rel.eh_frame REL 00000000 000380 000018 08 I 12 10 4
15 [12] .symtab SYMTAB 00000000 000154 000140 10 13 13 4
16 [13] .strtab STRTAB 00000000 000294 0000a2 00 0 0 1
17 [14] .shstrtab STRTAB 00000000 000398 000082 00 0 0 1
18 Key to Flags:
19 W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
20 L (link order), O (extra OS processing required), G (group), T (TLS),
21 C (compressed), x (unknown), o (OS specific), E (exclude),
22 p (processor specific)

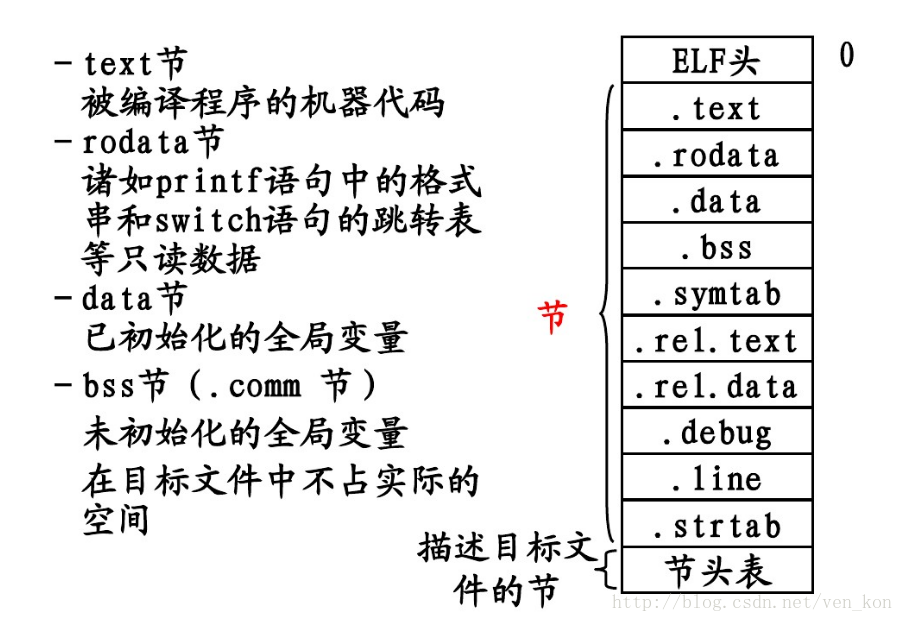
ELF文件组成字段分析:
ELF文件头(ELF Header):保存描述整个文件的基本属性,如ELF魔数、文件机器字节长度、数据存储格式等。
段表(Section Header Table):保存各个段的基本属性,是除了文件头之最重要的结构。节选样例内容如下:
| [Nr] | Name | Type | Addr | Off | Size | ES | Flg | Lk | Inf | Al |
| [1] | .text | PROGBITS | 00000000 | 000034 | 00005b | 00 | AX | 0 | 0 | 4 |
其表示的意义为,下标为1的段是.text段,类型是程序段(PROGBITS包括代码段和数据段),加载地址为0,在文件中的偏移量是0×34,长度为0x5b,项的长度为0(表示该段不包含固定大小的项),标志AX表示该段要分配空间及可以被执行,链接信息的两个0没有意义(不是与链接相关的段),最后的4表示段地址对齐为2^4=16字节。
重定位表:链接器在处理目标文件的时候,需要对目标文件中某些部位进行重定位,即代码段和数据段中那些绝对地址的引用位置,这些重定位信息记录在重定位表里。每个需要重定位的代码段或数据段都会有一个相应的重定位表,如.rel.text是针对”.text”段的重定位表,”.rel.data”是针对”.data”段的重定位表。
字符串表:ELF文件中用到很多字符串,如段名、变量名,因为字符串的长度不固定,用固定的结构来表示它比较困难,一般把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串。一般字符串表在ELF中以段的形式保存,常见的有.strtab(字符串表,String Table)和.shstrtab(段表字符串表,Section Header String Table),前者保存如符号名字等普通字符串,后者保存如段名等段表中用到的字符串。
符号表:函数和变量统称为符号,其名称称为符号名。链接过程中关键的部分就是符号的管理,每一个目标文件都会有一个相应的符号表,记录了目标文件用到的所有符号,每个符号有一个对应的符号值,一般为符号的地址。一个样例如下:
| Num | Value | Size | Type | Bind | Vis | Ndx | Name |
| 13 | 0000001b | 64 | FUNC | GLOBAL | DEFAULT | 1 | main |
其意义如下:下标为13的符号的符号值为0x1b,大小为64字节,类型为函数,绑定信息为全局符号,VIS可以忽略,Ndx表示其所在段的下标为1(通过上一个样例可知,该段为.text段),符号名称为main。如果Ndx下标一项为UND(undefine),则表示该符号在其他模块定义,以后需要重定位。
调试信息:目标文件里可能保存有调试信息,如在GCC编译时加上”-g”参数,会生成许多以”.debug”开头的段。
2.3 链接
链接,是收集和组织程序所需的不同代码和数据的过程,以便程序能被装入内存并被执行。一般分为两步:1.空间与地址分配,2.符号解析与重定位。一般有两种类型,一是静态链接,二是动态链接。
- 空间与地址分配
扫描所有的输入目标文件,获得它们的各个段的长度、属性和位置,并且将输入目标文件中的符号定义和符号引用收集起来,统一放到一个全局符号表。这一步中,连接器将能获得所有输入如目标文件的 段长度,并且将它们合并,计算出输出文件中各个段合并后的长度和位置,并建立映射关系。
- 符号解析与重定位
使用上面一步中收集的所有信息,读取输入文件中的段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等。事实上,这一步是链接过程的核心,特别是重定位过程。
使用静态链接的好处是,依赖的动态链接库较少(这句话有点绕),对动态链接库的版本更新不会很敏感,具有较好的兼容性;不好地方主要是生成的程序比较大,占用资源多。使用动态链接的好处是生成的程序小,占用资源少。动态链接分为可执行程序装载时动态链接和运行时动态链接。
当用户启动一个应用程序时,它们就会调用一个可执行和链接格式映像。Linux 中 ELF 支持两种类型的库:静态库包含在编译时静态绑定到一个程序的函数。动态库则是在加载应用程序时被加载的,而且它与应用程序是在运行时绑定的。
2.4 代码分析
sys_execve内部会解析可执行文件格式。代码在内核中/linux-4.15.0/fs/exec.c中。sys_execve调用顺序:do_execve -> do_execve_common -> exec_binprm
do_execve 函数
1 int do_execve(struct filename *filename,
2 const char __user *const __user *__argv,
3 const char __user *const __user *__envp)
4 {
5 struct user_arg_ptr argv = { .ptr.native = __argv };
6 struct user_arg_ptr envp = { .ptr.native = __envp };
7 return do_execve_common(filename, argv, envp);
8 }
do_execve_common 函数


1 /*
2 * sys_execve() executes a new program.
3 */
4 static int do_execveat_common(int fd, struct filename *filename,
5 struct user_arg_ptr argv,
6 struct user_arg_ptr envp,
7 int flags)
8 {
9 char *pathbuf = NULL;
10 struct linux_binprm *bprm;
11 struct file *file;
12 struct files_struct *displaced;
13 int retval;
14
15 if (IS_ERR(filename))
16 return PTR_ERR(filename);
17
18 /*
19 * We move the actual failure in case of RLIMIT_NPROC excess from
20 * set*uid() to execve() because too many poorly written programs
21 * don't check setuid() return code. Here we additionally recheck
22 * whether NPROC limit is still exceeded.
23 */
24 if ((current->flags & PF_NPROC_EXCEEDED) &&
25 atomic_read(¤t_user()->processes) > rlimit(RLIMIT_NPROC)) {
26 retval = -EAGAIN;
27 goto out_ret;
28 }
29
30 /* We're below the limit (still or again), so we don't want to make
31 * further execve() calls fail. */
32 current->flags &= ~PF_NPROC_EXCEEDED;
33
34 retval = unshare_files(&displaced);
35 if (retval)
36 goto out_ret;
37
38 retval = -ENOMEM;
39 bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
40 if (!bprm)
41 goto out_files;
42
43 retval = prepare_bprm_creds(bprm);
44 if (retval)
45 goto out_free;
46
47 check_unsafe_exec(bprm);
48 current->in_execve = 1;
49
50 file = do_open_execat(fd, filename, flags);
51 retval = PTR_ERR(file);
52 if (IS_ERR(file))
53 goto out_unmark;
54
55 sched_exec();
56
57 bprm->file = file;
58 if (fd == AT_FDCWD || filename->name[0] == '/') {
59 bprm->filename = filename->name;
60 } else {
61 if (filename->name[0] == '�')
62 pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d", fd);
63 else
64 pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d/%s",
65 fd, filename->name);
66 if (!pathbuf) {
67 retval = -ENOMEM;
68 goto out_unmark;
69 }
70 /*
71 * Record that a name derived from an O_CLOEXEC fd will be
72 * inaccessible after exec. Relies on having exclusive access to
73 * current->files (due to unshare_files above).
74 */
75 if (close_on_exec(fd, rcu_dereference_raw(current->files->fdt)))
76 bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE;
77 bprm->filename = pathbuf;
78 }
79 bprm->interp = bprm->filename;
80
81 retval = bprm_mm_init(bprm);
82 if (retval)
83 goto out_unmark;
84
85 bprm->argc = count(argv, MAX_ARG_STRINGS);
86 if ((retval = bprm->argc) < 0)
87 goto out;
88
89 bprm->envc = count(envp, MAX_ARG_STRINGS);
90 if ((retval = bprm->envc) < 0)
91 goto out;
92
93 retval = prepare_binprm(bprm);
94 if (retval < 0)
95 goto out;
96
97 retval = copy_strings_kernel(1, &bprm->filename, bprm);
98 if (retval < 0)
99 goto out;
100
101 bprm->exec = bprm->p;
102 retval = copy_strings(bprm->envc, envp, bprm);
103 if (retval < 0)
104 goto out;
105
106 retval = copy_strings(bprm->argc, argv, bprm);
107 if (retval < 0)
108 goto out;
109
110 retval = exec_binprm(bprm);
111 if (retval < 0)
112 goto out;
113
114 /* execve succeeded */
115 current->fs->in_exec = 0;
116 current->in_execve = 0;
117 membarrier_execve(current);
118 acct_update_integrals(current);
119 task_numa_free(current, false);
120 free_bprm(bprm);
121 kfree(pathbuf);
122 putname(filename);
123 if (displaced)
124 put_files_struct(displaced);
125 return retval;
126
127 out:
128 if (bprm->mm) {
129 acct_arg_size(bprm, 0);
130 mmput(bprm->mm);
131 }
132
133 out_unmark:
134 current->fs->in_exec = 0;
135 current->in_execve = 0;
136
137 out_free:
138 free_bprm(bprm);
139 kfree(pathbuf);
140
141 out_files:
142 if (displaced)
143 reset_files_struct(displaced);
144 out_ret:
145 putname(filename);
146 return retval;
147 }
exec_binprm函数
1 static int exec_binprm(struct linux_binprm *bprm)
2 {
3 pid_t old_pid, old_vpid;
4 int ret;
5
6 /* Need to fetch pid before load_binary changes it */
7 old_pid = current->pid;
8 rcu_read_lock();
9 old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
10 rcu_read_unlock();
11
12 ret = search_binary_handler(bprm);
13 if (ret >= 0) {
14 audit_bprm(bprm);
15 trace_sched_process_exec(current, old_pid, bprm);
16 ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
17 proc_exec_connector(current);
18 }
19
20 return ret;
21 }
search_binary_handler寻找符合文件格式对应的解析模板,如下:(对于给定的文件名,根据文件头部信息寻找对应的文件格式处理模块)
1 /*
2 * cycle the list of binary formats handler, until one recognizes the image
3 */
4 int search_binary_handler(struct linux_binprm *bprm)
5 {
6 bool need_retry = IS_ENABLED(CONFIG_MODULES);
7 struct linux_binfmt *fmt;
8 int retval;
9
10 /* This allows 4 levels of binfmt rewrites before failing hard. */
11 if (bprm->recursion_depth > 5)
12 return -ELOOP;
13
14 retval = security_bprm_check(bprm);
15 if (retval)
16 return retval;
17
18 retval = -ENOENT;
19 retry:
20 read_lock(&binfmt_lock);
21 list_for_each_entry(fmt, &formats, lh) {
22 if (!try_module_get(fmt->module))
23 continue;
24 read_unlock(&binfmt_lock);
25 bprm->recursion_depth++;
26 retval = fmt->load_binary(bprm);
27 read_lock(&binfmt_lock);
28 put_binfmt(fmt);
29 bprm->recursion_depth--;
30 if (retval < 0 && !bprm->mm) {
31 /* we got to flush_old_exec() and failed after it */
32 read_unlock(&binfmt_lock);
33 force_sigsegv(SIGSEGV, current);
34 return retval;
35 }
36 if (retval != -ENOEXEC || !bprm->file) {
37 read_unlock(&binfmt_lock);
38 return retval;
39 }
40 }
41 read_unlock(&binfmt_lock);
42
43 if (need_retry) {
44 if (printable(bprm->buf[0]) && printable(bprm->buf[1]) &&
45 printable(bprm->buf[2]) && printable(bprm->buf[3]))
46 return retval;
47 if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0)
48 return retval;
49 need_retry = false;
50 goto retry;
51 }
52
53 return retval;
54 }
55 EXPORT_SYMBOL(search_binary_handler);
对于ELF格式的可执行文件fmt->load_binary(bprm); 执行的应该是load_elf_binary其内部是和ELF文件格式解析的部分需要和ELF文件格式标准结合起来阅读。load_elf_binary在/linux-4.15.0/fs/binfmt_elf.c文件中,代码太长,在此不贴出,这个函数主要作用就是在函数的最后根据链接种类启动一个起点为新的可执行程序的入口的进程。其中的关键代码如下:
1 static int load_elf_binary(struct linux_binprm *bprm) 2 { 3 struct file *interpreter = NULL; /* to shut gcc up */ 4 unsigned long load_addr = 0, load_bias = 0; 5 int load_addr_set = 0; 6 char * elf_interpreter = NULL; 7 unsigned long error; 8 struct elf_phdr *elf_ppnt, *elf_phdata, *interp_elf_phdata = NULL; 9 unsigned long elf_bss, elf_brk; 10 int bss_prot = 0; 11 int retval, i; 12 unsigned long elf_entry; 13 unsigned long interp_load_addr = 0; 14 unsigned long start_code, end_code, start_data, end_data; 15 unsigned long reloc_func_desc __maybe_unused = 0; 16 int executable_stack = EXSTACK_DEFAULT; 17 struct pt_regs *regs = current_pt_regs(); 18 struct { 19 struct elfhdr elf_ex; 20 struct elfhdr interp_elf_ex; 21 } *loc; 22 struct arch_elf_state arch_state = INIT_ARCH_ELF_STATE; 23 loff_t pos; 24 25 loc = kmalloc(sizeof(*loc), GFP_KERNEL); 26 if (!loc) { 27 retval = -ENOMEM; 28 goto out_ret; 29 } 30 31 /* Get the exec-header */ 32 loc->elf_ex = *((struct elfhdr *)bprm->buf); 33 34 retval = -ENOEXEC; 35 /* First of all, some simple consistency checks */ 36 if (memcmp(loc->elf_ex.e_ident, ELFMAG, SELFMAG) != 0) 37 goto out; 38 39 if (loc->elf_ex.e_type != ET_EXEC && loc->elf_ex.e_type != ET_DYN) 40 goto out; 41 if (!elf_check_arch(&loc->elf_ex)) 42 goto out; 43 if (elf_check_fdpic(&loc->elf_ex)) 44 goto out; 45 if (!bprm->file->f_op->mmap) 46 goto out; 47 48 elf_phdata = load_elf_phdrs(&loc->elf_ex, bprm->file); 49 if (!elf_phdata) 50 goto out; 51 52 elf_ppnt = elf_phdata; 53 elf_bss = 0; 54 elf_brk = 0; 55 56 start_code = ~0UL; 57 end_code = 0; 58 start_data = 0; 59 end_data = 0; 60 61 for (i = 0; i < loc->elf_ex.e_phnum; i++) { 62 if (elf_ppnt->p_type == PT_INTERP) { 63 /* This is the program interpreter used for 64 * shared libraries - for now assume that this 65 * is an a.out format binary 66 */ 67 retval = -ENOEXEC; 68 if (elf_ppnt->p_filesz > PATH_MAX || 69 elf_ppnt->p_filesz < 2) 70 goto out_free_ph; 71 72 retval = -ENOMEM; 73 elf_interpreter = kmalloc(elf_ppnt->p_filesz, 74 GFP_KERNEL); 75 if (!elf_interpreter) 76 goto out_free_ph; 77 78 pos = elf_ppnt->p_offset; 79 retval = kernel_read(bprm->file, elf_interpreter, 80 elf_ppnt->p_filesz, &pos); 81 if (retval != elf_ppnt->p_filesz) { 82 if (retval >= 0) 83 retval = -EIO; 84 goto out_free_interp; 85 } 86 /* make sure path is NULL terminated */ 87 retval = -ENOEXEC; 88 if (elf_interpreter[elf_ppnt->p_filesz - 1] != '�') 89 goto out_free_interp; 90 91 interpreter = open_exec(elf_interpreter); 92 retval = PTR_ERR(interpreter); 93 if (IS_ERR(interpreter)) 94 goto out_free_interp; 95 96 /* 97 * If the binary is not readable then enforce 98 * mm->dumpable = 0 regardless of the interpreter's 99 * permissions. 100 */ 101 would_dump(bprm, interpreter); 102 103 /* Get the exec headers */ 104 pos = 0; 105 retval = kernel_read(interpreter, &loc->interp_elf_ex, 106 sizeof(loc->interp_elf_ex), &pos); 107 if (retval != sizeof(loc->interp_elf_ex)) { 108 if (retval >= 0) 109 retval = -EIO; 110 goto out_free_dentry; 111 } 112 113 break; 114 } 115 elf_ppnt++; 116 } 117 118 elf_ppnt = elf_phdata; 119 for (i = 0; i < loc->elf_ex.e_phnum; i++, elf_ppnt++) 120 switch (elf_ppnt->p_type) { 121 case PT_GNU_STACK: 122 if (elf_ppnt->p_flags & PF_X) 123 executable_stack = EXSTACK_ENABLE_X; 124 else 125 executable_stack = EXSTACK_DISABLE_X; 126 break; 127 128 case PT_LOPROC ... PT_HIPROC: 129 retval = arch_elf_pt_proc(&loc->elf_ex, elf_ppnt, 130 bprm->file, false, 131 &arch_state); 132 if (retval) 133 goto out_free_dentry; 134 break; 135 } 136 137 /* Some simple consistency checks for the interpreter */ 138 if (elf_interpreter) {//动态链接 139 retval = -ELIBBAD; 140 /* Not an ELF interpreter */ 141 if (memcmp(loc->interp_elf_ex.e_ident, ELFMAG, SELFMAG) != 0) 142 goto out_free_dentry; 143 /* Verify the interpreter has a valid arch */ 144 if (!elf_check_arch(&loc->interp_elf_ex) || 145 elf_check_fdpic(&loc->interp_elf_ex)) 146 goto out_free_dentry; 147 148 /* Load the interpreter program headers */ 149 interp_elf_phdata = load_elf_phdrs(&loc->interp_elf_ex, 150 interpreter); 151 if (!interp_elf_phdata) 152 goto out_free_dentry; 153 154 /* Pass PT_LOPROC..PT_HIPROC headers to arch code */ 155 elf_ppnt = interp_elf_phdata; 156 for (i = 0; i < loc->interp_elf_ex.e_phnum; i++, elf_ppnt++) 157 switch (elf_ppnt->p_type) { 158 case PT_LOPROC ... PT_HIPROC: 159 retval = arch_elf_pt_proc(&loc->interp_elf_ex, 160 elf_ppnt, interpreter, 161 true, &arch_state); 162 if (retval) 163 goto out_free_dentry; 164 break; 165 } 166 } 167 168 /* 169 * Allow arch code to reject the ELF at this point, whilst it's 170 * still possible to return an error to the code that invoked 171 * the exec syscall. 172 */ 173 retval = arch_check_elf(&loc->elf_ex, 174 !!interpreter, &loc->interp_elf_ex, 175 &arch_state); 176 if (retval) 177 goto out_free_dentry; 178 179 /* Flush all traces of the currently running executable */ 180 retval = flush_old_exec(bprm); 181 if (retval) 182 goto out_free_dentry; 183 184 /* Do this immediately, since STACK_TOP as used in setup_arg_pages 185 may depend on the personality. */ 186 SET_PERSONALITY2(loc->elf_ex, &arch_state); 187 if (elf_read_implies_exec(loc->elf_ex, executable_stack)) 188 current->personality |= READ_IMPLIES_EXEC; 189 190 if (!(current->personality & ADDR_NO_RANDOMIZE) && randomize_va_space) 191 current->flags |= PF_RANDOMIZE; 192 193 setup_new_exec(bprm); 194 install_exec_creds(bprm); 195 196 /* Do this so that we can load the interpreter, if need be. We will 197 change some of these later */ 198 retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP), 199 executable_stack); 200 if (retval < 0) 201 goto out_free_dentry; 202 203 current->mm->start_stack = bprm->p; 204 205 /* Now we do a little grungy work by mmapping the ELF image into 206 the correct location in memory. */ 207 for(i = 0, elf_ppnt = elf_phdata; 208 i < loc->elf_ex.e_phnum; i++, elf_ppnt++) { 209 int elf_prot = 0, elf_flags; 210 unsigned long k, vaddr; 211 unsigned long total_size = 0; 212 213 if (elf_ppnt->p_type != PT_LOAD) 214 continue; 215 216 if (unlikely (elf_brk > elf_bss)) { 217 unsigned long nbyte; 218 219 /* There was a PT_LOAD segment with p_memsz > p_filesz 220 before this one. Map anonymous pages, if needed, 221 and clear the area. */ 222 retval = set_brk(elf_bss + load_bias, 223 elf_brk + load_bias, 224 bss_prot); 225 if (retval) 226 goto out_free_dentry; 227 nbyte = ELF_PAGEOFFSET(elf_bss); 228 if (nbyte) { 229 nbyte = ELF_MIN_ALIGN - nbyte; 230 if (nbyte > elf_brk - elf_bss) 231 nbyte = elf_brk - elf_bss; 232 if (clear_user((void __user *)elf_bss + 233 load_bias, nbyte)) { 234 /* 235 * This bss-zeroing can fail if the ELF 236 * file specifies odd protections. So 237 * we don't check the return value 238 */ 239 } 240 } 241 } 242 243 if (elf_ppnt->p_flags & PF_R) 244 elf_prot |= PROT_READ; 245 if (elf_ppnt->p_flags & PF_W) 246 elf_prot |= PROT_WRITE; 247 if (elf_ppnt->p_flags & PF_X) 248 elf_prot |= PROT_EXEC; 249 250 elf_flags = MAP_PRIVATE | MAP_DENYWRITE | MAP_EXECUTABLE; 251 252 vaddr = elf_ppnt->p_vaddr; 253 /* 254 * If we are loading ET_EXEC or we have already performed 255 * the ET_DYN load_addr calculations, proceed normally. 256 */ 257 if (loc->elf_ex.e_type == ET_EXEC || load_addr_set) { 258 elf_flags |= MAP_FIXED; 259 } else if (loc->elf_ex.e_type == ET_DYN) { 260 /* 261 * This logic is run once for the first LOAD Program 262 * Header for ET_DYN binaries to calculate the 263 * randomization (load_bias) for all the LOAD 264 * Program Headers, and to calculate the entire 265 * size of the ELF mapping (total_size). (Note that 266 * load_addr_set is set to true later once the 267 * initial mapping is performed.) 268 * 269 * There are effectively two types of ET_DYN 270 * binaries: programs (i.e. PIE: ET_DYN with INTERP) 271 * and loaders (ET_DYN without INTERP, since they 272 * _are_ the ELF interpreter). The loaders must 273 * be loaded away from programs since the program 274 * may otherwise collide with the loader (especially 275 * for ET_EXEC which does not have a randomized 276 * position). For example to handle invocations of 277 * "./ld.so someprog" to test out a new version of 278 * the loader, the subsequent program that the 279 * loader loads must avoid the loader itself, so 280 * they cannot share the same load range. Sufficient 281 * room for the brk must be allocated with the 282 * loader as well, since brk must be available with 283 * the loader. 284 * 285 * Therefore, programs are loaded offset from 286 * ELF_ET_DYN_BASE and loaders are loaded into the 287 * independently randomized mmap region (0 load_bias 288 * without MAP_FIXED). 289 */ 290 if (elf_interpreter) { 291 load_bias = ELF_ET_DYN_BASE; 292 if (current->flags & PF_RANDOMIZE) 293 load_bias += arch_mmap_rnd(); 294 elf_flags |= MAP_FIXED; 295 } else 296 load_bias = 0; 297 298 /* 299 * Since load_bias is used for all subsequent loading 300 * calculations, we must lower it by the first vaddr 301 * so that the remaining calculations based on the 302 * ELF vaddrs will be correctly offset. The result 303 * is then page aligned. 304 */ 305 load_bias = ELF_PAGESTART(load_bias - vaddr); 306 307 total_size = total_mapping_size(elf_phdata, 308 loc->elf_ex.e_phnum); 309 if (!total_size) { 310 retval = -EINVAL; 311 goto out_free_dentry; 312 } 313 } 314 315 error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt, 316 elf_prot, elf_flags, total_size); 317 if (BAD_ADDR(error)) { 318 retval = IS_ERR((void *)error) ? 319 PTR_ERR((void*)error) : -EINVAL; 320 goto out_free_dentry; 321 } 322 323 if (!load_addr_set) { 324 load_addr_set = 1; 325 load_addr = (elf_ppnt->p_vaddr - elf_ppnt->p_offset); 326 if (loc->elf_ex.e_type == ET_DYN) { 327 load_bias += error - 328 ELF_PAGESTART(load_bias + vaddr); 329 load_addr += load_bias; 330 reloc_func_desc = load_bias; 331 } 332 } 333 k = elf_ppnt->p_vaddr; 334 if (k < start_code) 335 start_code = k; 336 if (start_data < k) 337 start_data = k; 338 339 /* 340 * Check to see if the section's size will overflow the 341 * allowed task size. Note that p_filesz must always be 342 * <= p_memsz so it is only necessary to check p_memsz. 343 */ 344 if (BAD_ADDR(k) || elf_ppnt->p_filesz > elf_ppnt->p_memsz || 345 elf_ppnt->p_memsz > TASK_SIZE || 346 TASK_SIZE - elf_ppnt->p_memsz < k) { 347 /* set_brk can never work. Avoid overflows. */ 348 retval = -EINVAL; 349 goto out_free_dentry; 350 } 351 352 k = elf_ppnt->p_vaddr + elf_ppnt->p_filesz; 353 354 if (k > elf_bss) 355 elf_bss = k; 356 if ((elf_ppnt->p_flags & PF_X) && end_code < k) 357 end_code = k; 358 if (end_data < k) 359 end_data = k; 360 k = elf_ppnt->p_vaddr + elf_ppnt->p_memsz; 361 if (k > elf_brk) { 362 bss_prot = elf_prot; 363 elf_brk = k; 364 } 365 } 366 367 loc->elf_ex.e_entry += load_bias; 368 elf_bss += load_bias; 369 elf_brk += load_bias; 370 start_code += load_bias; 371 end_code += load_bias; 372 start_data += load_bias; 373 end_data += load_bias; 374 375 /* Calling set_brk effectively mmaps the pages that we need 376 * for the bss and break sections. We must do this before 377 * mapping in the interpreter, to make sure it doesn't wind 378 * up getting placed where the bss needs to go. 379 */ 380 retval = set_brk(elf_bss, elf_brk, bss_prot); 381 if (retval) 382 goto out_free_dentry; 383 if (likely(elf_bss != elf_brk) && unlikely(padzero(elf_bss))) { 384 retval = -EFAULT; /* Nobody gets to see this, but.. */ 385 goto out_free_dentry; 386 } 387 388 if (elf_interpreter) { 389 unsigned long interp_map_addr = 0; 390 391 elf_entry = load_elf_interp(&loc->interp_elf_ex, 392 interpreter, 393 &interp_map_addr, 394 load_bias, interp_elf_phdata); 395 if (!IS_ERR((void *)elf_entry)) { 396 /* 397 * load_elf_interp() returns relocation 398 * adjustment 399 */ 400 interp_load_addr = elf_entry; 401 elf_entry += loc->interp_elf_ex.e_entry; 402 } 403 if (BAD_ADDR(elf_entry)) { 404 retval = IS_ERR((void *)elf_entry) ? 405 (int)elf_entry : -EINVAL; 406 goto out_free_dentry; 407 } 408 reloc_func_desc = interp_load_addr; 409 410 allow_write_access(interpreter); 411 fput(interpreter); 412 kfree(elf_interpreter); 413 } else { 414 elf_entry = loc->elf_ex.e_entry; 415 if (BAD_ADDR(elf_entry)) { 416 retval = -EINVAL; 417 goto out_free_dentry; 418 } 419 } 420 421 kfree(interp_elf_phdata); 422 kfree(elf_phdata); 423 424 set_binfmt(&elf_format); 425 426 #ifdef ARCH_HAS_SETUP_ADDITIONAL_PAGES 427 retval = arch_setup_additional_pages(bprm, !!elf_interpreter); 428 if (retval < 0) 429 goto out; 430 #endif /* ARCH_HAS_SETUP_ADDITIONAL_PAGES */ 431 432 retval = create_elf_tables(bprm, &loc->elf_ex, 433 load_addr, interp_load_addr); 434 if (retval < 0) 435 goto out; 436 /* N.B. passed_fileno might not be initialized? */ 437 current->mm->end_code = end_code; 438 current->mm->start_code = start_code; 439 current->mm->start_data = start_data; 440 current->mm->end_data = end_data; 441 current->mm->start_stack = bprm->p; 442 443 if ((current->flags & PF_RANDOMIZE) && (randomize_va_space > 1)) { 444 /* 445 * For architectures with ELF randomization, when executing 446 * a loader directly (i.e. no interpreter listed in ELF 447 * headers), move the brk area out of the mmap region 448 * (since it grows up, and may collide early with the stack 449 * growing down), and into the unused ELF_ET_DYN_BASE region. 450 */ 451 if (IS_ENABLED(CONFIG_ARCH_HAS_ELF_RANDOMIZE) && 452 loc->elf_ex.e_type == ET_DYN && !interpreter) 453 current->mm->brk = current->mm->start_brk = 454 ELF_ET_DYN_BASE; 455 456 current->mm->brk = current->mm->start_brk = 457 arch_randomize_brk(current->mm); 458 #ifdef compat_brk_randomized 459 current->brk_randomized = 1; 460 #endif 461 } 462 463 if (current->personality & MMAP_PAGE_ZERO) { 464 /* Why this, you ask??? Well SVr4 maps page 0 as read-only, 465 and some applications "depend" upon this behavior. 466 Since we do not have the power to recompile these, we 467 emulate the SVr4 behavior. Sigh. */ 468 error = vm_mmap(NULL, 0, PAGE_SIZE, PROT_READ | PROT_EXEC, 469 MAP_FIXED | MAP_PRIVATE, 0); 470 } 471 472 #ifdef ELF_PLAT_INIT 473 /* 474 * The ABI may specify that certain registers be set up in special 475 * ways (on i386 %edx is the address of a DT_FINI function, for 476 * example. In addition, it may also specify (eg, PowerPC64 ELF) 477 * that the e_entry field is the address of the function descriptor 478 * for the startup routine, rather than the address of the startup 479 * routine itself. This macro performs whatever initialization to 480 * the regs structure is required as well as any relocations to the 481 * function descriptor entries when executing dynamically links apps. 482 */ 483 ELF_PLAT_INIT(regs, reloc_func_desc); 484 #endif 485 486 start_thread(regs, elf_entry, bprm->p); 487 retval = 0; 488 out: 489 kfree(loc); 490 out_ret: 491 return retval; 492 493 /* error cleanup */ 494 out_free_dentry: 495 kfree(interp_elf_phdata); 496 allow_write_access(interpreter); 497 if (interpreter) 498 fput(interpreter); 499 out_free_interp: 500 kfree(elf_interpreter); 501 out_free_ph: 502 kfree(elf_phdata); 503 goto out; 504 }
ELF文件格式结构体:
1 static struct linux_binfmt elf_format = {
2 .module = THIS_MODULE,
3 .load_binary = load_elf_binary,
4 .load_shlib = load_elf_library,
5 .core_dump = elf_core_dump,
6 .min_coredump = ELF_EXEC_PAGESIZE,
7 };
load_elf_binary 的最后调用 start_thread 函数。修改 int 0x80 压入内核堆栈的 EIP,当 load_elf_binary 执行完毕,返回至 do_execve 再返回至 sys_execve 时,系统调用的返回地址,即 EIP 寄存器,已经被改写成了被装载的 ELF 程序的入口地址了。
小结:
1、可执行程序的产生:
C语言代码–>编译器预处理–>编译成汇编代码–>汇编器编译成目标代码–>链接成可执行文件,再由操作系统加载到内存中执行。
2、ELF格式中主要有3种可执行文件:可重定位文件.o,可执行文件,共享目标文件。
3、ELF可执行文件会被默认映射到0x8048000这个地址。
4、命令行参数和环境变量是如何进入新程序的堆栈的?
Shell程序–>execve–>sys_execve,然后在初始化新程序堆栈时拷贝进去。
先函数调用参数传递,再系统调用参数传递。
5、当前程序执行到execve系统调用时陷入内核态,在内核中用execve加载可执行文件,把当前进程的可执行文件覆盖掉,execve系统调用返回到新的可执行程序的起点。
6、动态链接库的装载过程是一个图的遍历过程,
ELF格式中的.interp和.dynamic需要依赖动态链接器来解析,entry返回到用户态时不是返回到可执行程序规定的起点,返回到动态链接器的程序入口。
2.5 静态链接
几个目标文件进行链接时,每个目标文件都有其自身的代码段、数据段等,链接器需要将它们各个段的合并到输出文件中,具体有两种合并方法:
- 按序叠加:将输入的目标文件按照次序叠加起来。
- 相似段合并:将相同性质的段合并到一起,比如将所有输入文件的”.text”合并到输出文件的”.text”段,接着是”.data”段、”.bss”段等。
第一种方法会产生很多零散的段,而且每个段有一定的地址和空间对齐要求,会造成内存空间大量的内部碎片。所以现在的链接器空间分配基本采用第二种方法,而且一般采用一种称为两步链接的方法:
- 空间与地址分配。扫描所有输入的目标文件,获得他们各个段的长度、属性和位置,收集它们符号表中所有的符号定义和符号引用,统一放到一个全局符号表中。此时,链接器可以获得所有输入目标文件的段长度,将他们合并,计算出输出文件中各个段合并后的长度与位置并建立映射关系。
- 符号解析与重定位。使用上面收集到的信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等。
经过第一步后,输入文件中的各个段在链接后的虚拟地址已经确定了,链接器开始计算各个符号的虚拟地址。各个符号在段内的相对地址是固定的,链接器只需要给他们加上一个偏移量,调整到正确的虚拟地址即可。
ELF中每个需要重定位的段都有一个对应的重定位表,也称为重定位段。重定位表中每个需要重定位的地方叫一个重定位入口,包含:
- 重定位入口的偏移:对于可重定位文件来说,偏移指该重定位入口所要修正的位置的第一个字节相对于该段的起始偏移。
- 重定位入口的类型和符号:低8位表示重定位入口的类型,高24位表示重定位入口的符号在符号表的下标。
不同的处理器指令对于地址的格式和方式都不一样,对于每一个重定位入口,根据其重定位类型使用对应的指令修正方式修改其指令地址,完成重定位过程。
2.5.1 使用静态链接的可执行文件的装载分析
32位硬件平台上进程的虚拟地址空间的地址为0到2^32-1:0×00000000~0xFFFFFFFF,即通常说的4GB虚拟空间大小。在Linux操作系统下,4GB被划分成两部分,操作系统本身占用了0xC00000000到0xFFFFFFFF共1GB的空间,剩下的从0×00000000到0xBFFFFFFFF共3GB的空间留给进程使用。
可执行文件只有被装载到内存以后才能运行,最简单的办法是把所有的指令和数据全部装入内存,但这可能需要大量的内存,为了更有效地利用内存,根据程序运行的局部性原理,我们可以把程序中最常用的部分驻留内存,将不太常用的数据放在磁盘中,即动态装入。
现在大部分操作系统采用的是页映射的方法进行程序装载。页映射并不是一下把程序的所有数据和指令都装入内存,而是将内存和所有磁盘中的数据和指令按照”页(Page)”为单位划分成若干个页,以后所有的装载和操作的单位就是页。目前一般的页大小为4K=4096字节。装载管理器负责控制程序的装载问题,当运行到的某条指令不在内存的时候,会将该指令所在的页装载到内存中的一个地方,然后继续程序的运行。如果内存中已经没有位置,装载管理器会根据一定的算法放弃某个正在使用的页,并用新的页来替代,然后程序可以继续运行。
可执行文件中包含代码段、数据段、BSS段等一系列的段,其中很多段都要映射进进程的虚拟地址空间。当段的数量增加时,会产生空间浪费问题。因为ELF文件被映射时是以系统的页长度为单位进行的,一个段映射的长度应为页长度的整数倍,如果不是,那么多余部分也将占用一个页,从而产生内存浪费。
实际上操作系统并不关心可执行文件各个段所包含的实际内容,它只关心一些跟装载有关的问题,最主要的是段的权限(可读、可写、可执行)。ELF中,段的权限组合可以分成三类:
- 以代码段为代表的权限为可读可执行的段。
- 以数据段和BSS段为代表的权限为可读可写的段。
- 以只读数据段为代表的权限为只读的段。
于是,对于相同权限的段,可以把它们合并到一起当做一个段进行映射,这样可以把原先的多个段当做一个整体进行映射,明显地减少页面内部碎片,节省内存空间。这个称为”Segment”,表示一个或多个属性类似的”Section”,可以认为”Section”是链接时的概念,”Segment”是装载时的概念。链接器会把属性相似的”Section”放在一起,然后系统会按照这些”Section”组成的”Segment”来映射并装载可执行文件。
进程的虚拟地址空间中除了被用来映射可执行文件的各个”Segment”之外,还有包括栈(Stack)和堆(Heap)的空间,一个进程中的栈和堆在也是以虚拟内存区域(VMA, Virtual Memrory Area)的形式存在。操作系统通过给进程空间划分出一个个的VMA来管理进程的虚拟空间,基本原则是将相同权限属性的、有相同映像文件的映射成一个VMA,一个进程基本可以分为如下几种VMA区域:
- 代码VMA,权限只读,可执行,有映像文件。
- 数据VMA,权限可读写,可执行,有映像文件。
- 堆VMA,权限可读写,可执行,无映像文件,匿名,可向上扩展。
- 栈VMA,权限可读写,不可执行,无映像文件,匿名,可向下扩展。
2.6 动态链接
静态链接允许不同程序开发者相对独立地开发和测试自己的程序模块,促进程序开发的效率,但其也有相应的缺点:
- 浪费内存和磁盘空间。在多进程操作系统下,每个程序内部都保留了公用的库函数及其他数量可观的库函数及辅助数据结构,浪费大量空间。
- 程序开发和发布困难。一个程序如果使用了很多第三方的静态库,那么程序中一旦有任何库的更新,整个程序就要重新链接并重新发布给客户,非常不方便。
动态链接可以解决空间浪费和更新困难的问题,它不对那些组成程序的目标文件进行链接,而是等到程序运行时才进行链接。使用了动态链接之后,当我们运行一个程序时,系统会首先加载该程序依赖的其他的目标文件,如果其他目标文件还有依赖,系统会按照同样方法将它们全部加载到内存。当所需要的所有目标文件加载完毕之后,如果依赖关系满足,系统开始进行链接工作,包括符号解析及地址重定位等。完成之后,系统把控制权交回给原程序,程序开始运行。此时如果运行第二个程序,它依赖于一个已经加载过的目标文件,则系统不需要重新加载目标文件,而只要将它们连接起来即可。
动态链接可以解决共享的目标文件存在多个副本浪费磁盘和内存空间的问题,因为同一个目标文件在内存中只保存一份。另外,当一个程序所依赖的库升级之后,只需要将简单地用新的库将旧的覆盖掉,无需将所有的程序再重新链接一遍,当程序下次运行时,新版本的库会被自动加载到内存并链接起来,程序仍然可以正常运行,并且完成了升级过程。
对于静态链接的可执行文件来说,整个进程只有一个文件要被映射,那就是可执行文件本身。但是对于动态链接来说,除了可执行文件本身,还有它所依赖的共享目标文件,此时,它们都是被操作系统用同样的方法映射进进程的虚拟地址空间,只是它们占用的虚拟地址和长度不同。另外,动态链接器也和普通共享对象一样被映射到进程的地址空间。系统开始运行程序之前,会把控制权交给动态链接器,由它完成所有的动态链接工作,然后再把控制权交回给程序,程序就开始执行。
2.6.1 装载时重定位
动态链接的共享对象在被装载时,其在进程虚拟地址空间的位置是不确定的,为了使共享对象能够在任意地址装载,可以参考静态链接时的重定位(Link Time Relocation)思想,在链接时对所有的绝对地址的引用不做重定位,把这一步推迟到装载时再完成(静态库在链接的阶段就会进行重定位,动态库将其推迟到了程序装载的时候)。一旦模块装载完毕,其地址就确定了,即目标地址确定,系统就对程序中所有的绝对地址引用进行重定位。这种装载时重定位(Load Time Relocation)又称为基址重置(Rebasing)。
但是动态链接模块被装载映射至虚拟空间后,指令部分是在多个进程之间共享的,由于装载时重定位的方法需要修改指令,所以没有办法做到同一份指令被多个进程共享,因为指令被重定位之后对于每个进程来讲是不同的,但是实际上同一个可执行程序的代码段是公用的,也就是指令是一样的,这就存在这问题,可以使用地址无关代码技术(PIC)解决。当然,动态链接库中的可修改的数据部分对于不同的进程来说有多个副本,所以它们可以采用装载时重定位的方法来解决。
2.6.2 地址无关代码(指令修改问题的解决方案)
装载时重定位导致指令部分无法在多个进程之间共享,失去了动态链接节省内存的一大优势。为了程序模块中共享的指令部分在装载时不需要因为装载地址的改变而改变,可以把指令中那些需要改变的部分分离出来,跟数据部分放在一起,这样指令部分就可以保持不变了,而数据部分可以在每个进程中拥有一个副本。这种方案称为地址无关代码(PIC, Position-independent Code)技术。
我们把共享对象模块中的地址引用按照是否跨模块分成模块内部引用和模块外部引用,按照不同的引用方式分成指令引用和数据引用,然后把得到的4种情况分别进行处理:
- 模块内部调用或跳转。因为被调用的函数和调用者处于同一个模块,相对位置固定,而现代的系统对于模块内部的跳转、函数调用可以采用相对地址调用或者给予寄存器的相对调用,所以这种指令不需要重定位,其是地址无关的。
- 模块内部数据访问。显然指令不能包含数据的绝对地址,那么只有进行相对寻址。因为一个模块前面一半是若干个页的代码,然后是若干个也的数据,这些页之间的相对位置是固定的,即任何一条指令与它所需要访问的模块颞部数据之间的相对位置是固定的,那么只需要相对当前指令加上固定的偏移量就可以访问模块内部数据了。现代的体系结构中,数据的相对寻址往往没有相对当前指令地址(PC)的寻址方式,ELF中使用了巧妙的办法获取当前的PC值,然后再加上一个偏移量达到访问相应变量的目的。
- 模块间数据访问。模块间的数据访问目标地址要等到装载时才能确定,这些变量的地址跟模块的装载地址相关。ELF在数据段里建立一个指向这些变量的指针数组,称为全局偏移表(GOT, Global Offset Table),当代码需要引用该全局变量时,可以通过GOT中相对应的项间接引用。当指令需要一个其他模块的变量时,程序会先找到GOT,然后根据GOT中变量对应的项找到该变量的目标地址。每个变量对应一个4字节的地址,链接器在装载模块的时候会查找每个变量所在的地址,然后填充GOT的各个项,以确保每个指针所指向的地址都正确。由于GOT本身放在数据段,它可以在被模块装载时修改,并且每个进程都可以有独立的副本,相互不受影响。
- 模块间调用、跳转。采用上述类似的方法,不同的是,GOT中相应保存的是目标函数的地址,当模块需要调用目标函数时,可以通过GOT中的项进行间接跳转。调用一个函数时,先得到当前指令地址PC,然后加上一个偏移得到函数地址在GOT中的偏移,然后进行间接调用。
于是,四种地址引用方式在理论上都实现了地址无关性
2.6.3 数据段地址无关性
以上的方法能够保证共享对象中代码部分地址无关,但数据部分并不是地址无关的,比如:
1 static int a;
2 static int* p = &a;
指针p的地址是绝对地址,指向变量a,但a的地址会随着共享对象的装载地址改变而变。
数据段在每个进程都有一份独立的副本,并不担心被进程改变,于是可以选择装载时重定位的方法来解决数据段中绝对地址引用的问题。对于共享对象(代码段如果使用绝对地址,也会被放在数据段,地址无关代码技术)来说,如果数据段中有绝对地址的引用,那么编译器和链接器会产生一个重定位表,这个表中包含了”R_386_RELATIVE”类型的重定位入口来解决上述问题。当动态链接器装载共享对象时,如果发现共享对象上有这样的重定位入口,就会对该共享对象进行重定位。
其实对代码段也可以使用装载时重定位而不是地址无关代码的方法,只是它存在着一定的缺陷,它有以下特点:
-
- 代码段不是地址无关,不能被多个进程共享,失去了节省内存的有点。
- 运行速度比地址无关代码的共享对象块,因为它省去了地址无关代码中每次访问全局数据和函数时都要做一次计算当前地址以及间接地址寻址的过程。
2.6.4 动态链接相关结构
动态链接下可执行文件的装载与静态链接下基本一样,首先操作系统会读取可执行文件的头部,检查文件的合法性,然后从头部中的”Program Header”中读取每个”Segment”的虚拟地址、文件地址和属性,并将它们映射到进程虚拟空间的相应位置,这些步骤跟前面的静态链接情况下的装载基本无异。在静态链接情况下,操作系统接着就可以把控制权交给可执行文件的入口地址,然后程序开始执行。但在动态链接情况下,操作系统会先启动一个动态链接器,动态链接器得到控制权后,开始执行一系列自身的初始化操作,然后根据当前的环境参数,开始对可执行文件进行动态链接工作。当所有动态链接工作完成以后,动态链接器会将控制权转交到可执行文件的入口地址,程序开始正式执行。
动态链接涉及到的段主要如下:
- “.interp”段。在Linux中,操作系统在对可执行文件进行加载时,会寻找装载该可执行文件需要的相应的动态链接器,即”.interp”段指定的路径的共享对象。
- “.dynamic”段。动态链接ELF中最重要的结构,保存了动态链接器需要的基本信息,比如依赖于哪些共享对象、动态链接符号表的位置、动态链接重定位表的位置、共享对象初始化代码的地址等。”.dynamic”段保存的信息类似于ELF文件头,只是ELF文件头保存的是静态链接相关的内容,这里换成动态链接所使用的相应信息。
- 动态符号表。ELF中专门保存符号信息的段为”.dynsym”。类似于”.symtab”,但”.dynsym”只保存与动态链接相关的符号,而”.symtab”则保存了所有的符号,包括”.synsyms”中的符号。同样地,动态符号表也需要一些辅助的表,如保存符号名的字符串表,静态链接时叫符号字符串表”.strtab”,在这里就是动态符号字符串表”.dynstr”(Dynamic String Table)。为了加快动态链接下程序符号查找的过程,往往还有扶着的符号哈希表”.hash”。动态链接符号表的结构与静态链接的符号表几乎一样,可以简单地将导入函数看做是对其他目标文件函数的引用,把导出函数看做是在本目标文件定义的函数即可。
- 动态链接重定位表。动态链接下,可执行文件一旦依赖于其他共享对象,它的代码或数据中就会有对于导入符号的引用,这些导入符号的地址在运行时才确定,所以需要在运行时将这些导入符号的引用修正,即需要重定位。如果共享对象不是以PIC编译的,那么它需要在装载是被重定位;如果它是PIC编译的,虽然代码段不需要重定位,但是数据段还包含了绝对地址的引用,其绝对地址被分离出来成了GOT,而GOT是数据段的一部分,需要重定位。
装载时重定位跟静态链接中的目标文件重定位十分相似。静态链接中,目标文件里包含专门用于重定位信息的重定位表,如”.rel.txt”表示代码段的重定位表,”.rel.data”表示数据段的重定位表。类似地,动态链接中,重定位表分别为”.rel.dyn”和”.rel.plt”,前者是对数据引用的修正,修正的位置位于”.got”以及数据段,后者是对于函数引用的修正,修正的位置位于”.got.plt”。
2.6.5 动态链接的步骤
动态链接的步骤基本上分为3步:启动动态链接器本身,然后是装载所有需要的共享对象,最后是重定位和初始化。
- 动态链接器自举。普通共享对象文件的重定位工作由动态链接器完成,动态链接器本身本身不可以依赖于其他共享对象,其重定位工作由其自身完成,这需要动态链接器在启动时有一段非常精巧的代码可以完成这项艰巨的工作而同时不能用到全局和静态变量,甚至不能调用函数,这种具有一定限制的启动代码称为自举(Bootstrap)。
动态链接器获得控制权后,自举代码开始执行。自举代码首先找到自己的GOT,而GOT的第一个入口即是”.dynamic”段的偏移地址,由此找到了动态链接器本身的”.dynamic”段。通过”.dynamic”的信息,自举代码可以获得动态链接器本身的重定位表和符号表,从而得到动态链接器本身的重定位入口,先将他们全部重定位,然后动态链接器代码可以使用自己的全局变量和静态变量。 - 装载共享对象。自举完成后,动态链接器将可执行文件盒链接器本身的符号表合并到一个全局符号表中,然后开始寻找可执行文件依赖的共享对象。通过”.dynamic”段中类型的入口是DT_NEEDED的项,链接器可以列出可执行文件所依赖的所有共享对象,将他们的名字放入一个装载集合中。然后从集合中取出一个共享对象的名字,找到相应的文件后打开,读取相应的ELF文件头”.dynamic”段,然后将它相应的代码段和数据段映射到进程空间。如果这个ELF共享对象还依赖其他共享对象,则将所依赖的共享对象的名字放入装载集合中。如此循环把所有依赖对象都装载进内存为止。如果把依赖关系看做一个图的话,装载过程就是图的遍历过程,可以使用广度优先或深度优先搜索的顺序进行编译。
- 重定位和初始化。上述步骤完成后,链接器开始重新遍历可执行文件和每个共享对象的重定位表,将他们的GOT/PLT中的每个需要重定位的位置进行修正。因为此时动态链接器已经拥有了进程的全局符号表,所以这个修正过程比较容易,和前面的地址重定位原理基本相同。
重定位完成后,如果共享对象有”.init”段,那么动态链接器会执行”.init”段的代码,用来实现共享对象特有的初始化过程,比如共享对象中C++的全局/静态对象的构造。相应地,如果有”.finit”段,当进程退出时会执行”.finit”段中的代码,比如类似的C++全局对象的析构。而进程的可执行文件本身的的”.init”和”.finit”段不是由动态链接器执行,而是有运行库的初始化部分代码负责执行。
2.6.6 显式运行时链接
动态链接还有一种更加灵活的模块加载方式,称为显式运行时链接(Explicit Run-time Linking),也叫运行时加载。就是让程序自己在运行时控制加载指定的模块,并且可以在不需要该模块时将其卸载。一般的共享对象不需要进行任何修改就可以进行运行时加载,称为动态装载库(Dynamic Loading Library)。动态库的装载通过以下一系列的动态链接器API完成:
- dlopen:打开一个动态库,加载到进程的地址空间,完成初始化过程。
- dlsym:通过指定的动态库句柄找到制定的符号的地址。
- dlerror:每次调用dlopen()、dlsym()或dlclose()以后,可以调用dlerror()来判断上一次调用是否成功。
- dlclose:将一个已经加载的模块卸载。系统会维持一个加载引用计数器,每次使用dlopen()加载时,计数器加一;每次使用dlclose()卸载时,计数器减一。当计数器减到0时,模块才真正地卸载。
下面是一个简单的例子,这个程序将数学库模块用运行时加载的方法加载到进程中,然后获取sin()函数符号地址,调用sin()并且返回结果。
1 #include <stdio.h>
2 #include <dlfcn.h>
3 int mian ()
4 {
5 void *handle;
6 double (*func)(double);
7 char *error;
8
9 handle = dlopen(argv[1], RTLD_NOW);
10 if (handle == NULL)
11 {
12 printf("Open library %s error: %s
", argv[1], dlerror());
13 return -1;
14 }
15
16 func = dlsym(handle, "sin");
17 if ( (error = dlerror()) != NULL)
18 {
19 printf("Symbol sin not found: %s
", error);
20 goto exit_runso;
21 }
22
23 printf("%f
", func(3.1415926/2));
24
25 exit_runso:
26 dlclose(handle);
27 }
编译运行结果如下:
1 $gcc -o RunSoSimple RunSoSimple.c -ldl
2 $./RunSoSimple /lib/libm-2.6.1.so
3 1.000000
GOT表
ELF(Executable and Linking Format)格式的共享库使用 PIC 技术使代码和数据的引用与地址无关,程序可以被加载到地址空间的任意位置。PIC在代码中的跳转和分支指令不使用绝对地址。PIC 在 ELF 可执行映像的数据段中建立一个存放所有全局变量指针的全局偏移量表GOT
对于模块外部引用的全局变量和全局函数,用 GOT表的表项内容作为地址来间接寻址;对于本模块内的静态变量和静态函数,用 GOT表的首地址作为一个基准,用相对于该基准的偏移量来引用,因为不论程序被加载到何种地址空间,模块内的静态变量和静态函数与GOT 的距离是固定的,并且在链接阶段就可知晓其距离的大小。这样,PIC 使用 GOT来引用变量和函数的绝对地址,把位置独立的引用重定向到绝对位置。
对于 PIC代码,代码段内不存在重定位项,实际的重定位项只是在数据段的 GOT 表内。共享目标文件中的重定位类型有R_386_RELATIVE、R_386_GLOB_DAT 和R_386_JMP_SLOT,用于在动态链接器加载映射共享库或者模块运行的时候对指针类型的静态数据、全局变量符号地址和全局函数符号地址进行重定位。
PLT表
过程链接表用于把位置独立的函数调用重定向到绝对位置。通过 PLT动态链接的程序支持惰性绑定模式。每个动态链接的程序和共享库都有一个PLT,PLT 表的每一项都是一小段代码,对应于本运行模块要引用的一个全局函数。程序对某个函数的访问都被调整为对 PLT入口的访问。
每个 PLT 入口项对应一个GOT 项,执行函数实际上就是跳转到相应 GOT 项存储的地址,该 GOT 项初始值为 PLTn项中的 push指令地址(即 jmp 的下一条指令,所以第 1次跳转没有任何作用),待符号解析完成后存放符号的真正地址。动态链接器在装载映射共享库时在 GOT 里设置 2 个特殊值:在GOT+4( 即 GOT[1]) 设置动态库映射信息数据结构link_map 地址;在 GOT+8(即GOT[2])设置动态链接器符号解析函数的地址_dl_runtime_resolve。
PLT 的第 1 个入口 PLT0是一段访问动态链接器的特殊代码。程序对 PLT 入口的第 1 次访问都转到了 PLT0,最后跳入GOT[2]存储的地址执行符号解析函数。待完成符号解析后,将符号的实际地址存入相应的 GOT项,这样以后调用函数时可直接跳到实际的函数地址,不必再执行符号解析函数
操作系统运行程序时,首先将解释器程序即动态链接器ld.so 映射到一个合适的地址,然后启动ld.so。ld.so先完成自己的初始化工作,再从可执行文件的动态库依赖表中指定的路径名查找所需要的库,将其加载映射到内存。
Linux用一个全局的库映射信息结构 structlink_map链表来管理和控制所有动态库的加载,动态库的加载过程实际上是映射库文件到内存中,并填充库映射信息结构添加到链表中的过程。结构struct link_map描述共享目标文件的加载映射信息,是动态链接器在运行时内部使用的一个结构,通过它保持对已装载的库和库中符号的跟踪。
link_map使用双向链接中间件“l_next”和“l_prev”链接进程中所有加载的共享库。当动态链接器需要去查找符号的时候,可以向前或向后遍历这个链表,通过访问链表上的每一个库去搜索需要查找的符号。Link_map 链表的入口由每个可执行映像的全局偏移表的第 2个入口(GOT[1])指向,查找符号时先从 GOT[1]读取 link_map 结点地址,然后沿着link-map结点进行搜索。
在ELF文件中,全局偏移表(Global OffsetTable,GOT)能够把位置无关的地址定位到绝对地址,程序连接表也有类似的作用,它能够把位置无关的函数调用定向到绝对地址。连接编辑器(linkeditor)不能解决程序从一个可执行文件或者共享库目标到另外一个的执行转移。结果,连接编辑器只能把包含程序转移控制的一些入口安排到程序连接表(PLT)中。在system V体系中,程序连接表位于共享正文中,但是它们使用私有全局偏移表(private globaloffsettable)中的地址。动态连接器(例如:ld-2.2.2.so)会决定目标的绝对地址并且修改全局偏移表在内存中的影象。因而,动态连接器能够重定向这些入口,而勿需破坏程序正文的位置无关性和共享特性。可执行文件和共享目标文件有各自的程序连接表。
elf的动态连接库是内存位置无关的,就是说你可以把这个库加载到内存的任何位置都没有影响。这就叫做position independent。在编译内存位置无关的动态连接库时,要给编译器加上-fpic选项,让编译器产生的目标文件是内存位置无关的还会尽量减少对变量引用时使用绝对地址。把库编译成内存位置无关会带来一些花费,编译器会保留一个寄存器来指向全局偏移量表(global offset table (or GOT forshort)),这就会导致编译器在优化代码时少了一个寄存器可以使用,但是在最坏的情况下这种性能的减少只有3%,在其他情况下是大大小于3%的。
参考文章
https://blog.csdn.net/liushengxi_root/article/details/78798130
https://blog.csdn.net/ven_kon/article/details/69850776
https://blog.csdn.net/u013265795/article/details/44538775?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EsearchFromBaidu%7Edefault-1.pc_relevant_baidujshouduan&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EsearchFromBaidu%7Edefault-1.pc_relevant_baidujshouduan
https://docs.oracle.com/cd/E38902_01/html/E38861/chapter6-1235.html