这段时间肯定经常听到一句话“我命由我不由天”,没错,就是我们国产动漫---哪咤,今天我们通过python还有上次写的pyquery库来爬取豆瓣网评论内容
爬取豆瓣网评论
1、找到我们想要爬取的电影---小哪咤

2、查看影片评论
点击查看我们的影评,发现只能查看前200个影评,这里就需要登录了

分析出来全部影评的接口地址

好巧用到了上次写的通过requests登录豆瓣网,然后通过session会话访问评论内容-----post请求登录豆瓣网
# coding:utf-8 import requests # 登录请求地址 s = requests.session() url = 'https://accounts.douban.com/j/mobile/login/basic' # 请求头 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } # body数据 data = { 'name':"xxxxx", # 账号 "password":"xxxx", # 密码 "remember":"false" } # 发送请求 r = s.post(url,headers=headers,data=data) # 全部评论内容 url2 = 'https://movie.douban.com/subject/26794435/comments?start=20&limit=20&sort=new_score&status=P' r2 = s.get(url2,headers=headers).content
3、通过pyquery解析html
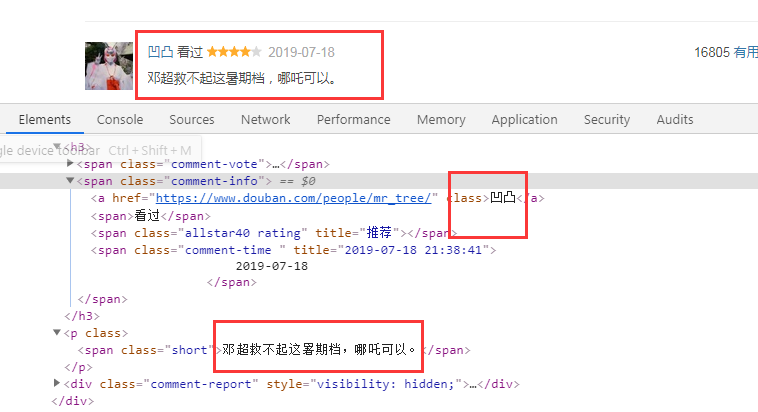
导入pyquery解析html内容,分析html数据
评论人的在 class =‘comment-info’下的a标签中;
影评内容在class=‘short’中
4、提取html上我们想要的内容
已经分析出来我们想要的数据在哪里,那么接下来就是提取数据了
# 解析html doc = pq(r2) items = doc('.comment-item').items() # 循环读取信息 for i in items: # 评论昵称 name = i('.comment-info a').text() print(name) # 评论内容 content = i('.short').text() print(content)

5、循环读取全部评论并且写入txt文件中
这个地方用到的知识点写入应该不用在具体说了;
循环读取全部评论就要查看分页情况了。找到2个url进行对比就可以看出来了
url1:https://movie.douban.com/subject/26794435/comments?status=P
url2:https://movie.douban.com/subject/26794435/comments?start=20&limit=20&sort=new_score&status=P
通过对比我们发现分页通过start这个参数进行控制,这次我们通过while进行控制分页内容
import requests from pyquery import PyQuery as pq import time import random s = requests.session() def data_html(): url = 'https://accounts.douban.com/j/mobile/login/basic' headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } data = { 'name':"1", "password":"xxxxx", "remember":"false" } r = s.post(url,headers=headers,data=data,verify = False) if '安静' in r.text: print('登录成功') else: print('登录失败') def data_shuju(count=0): print('开始爬取第%d页' % int(count)) start = int(count * 20) headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } url2 = 'https://movie.douban.com/subject/26794435/comments?start=%d&limit=20&sort=new_score&status=P' %(start) r2 = s.get(url2,headers=headers).content doc = pq(r2) items = doc('.comment-item').items() for i in items: name = i('.comment-info a').text() if not name: return 0 content= i('.short').text() with open('12.txt','a+',encoding='utf-8')as f: f.write('{name}: {pinglun} '.format(name=name,content=content)) return 1
def data_data():
data_html()
count = 0
while data_shuju(count):
count += 1
time.sleep(random.random() * 3)
print('爬取完毕')
data_data()