Redis是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度,可以说Redis是实现网站高并发不可或缺的一部分。
我们使用Redis时,会接触Redis的5种对象类型(字符串、哈希、列表、集合、有序集合),丰富的类型是Redis相对于Memcached等的一大优势。在了解Redis的5种对象类型的用法和特点的基础上,进一步了解Redis的内存模型,对Redis的使用有很大帮助,
例如:
1、估算Redis内存使用量。目前为止,内存的使用成本仍然相对较高,使用内存不能无所顾忌;根据需求合理的评估Redis的内存使用量,选择合适的机器配置,可以在满足需求的情况下节约成本。
2、优化内存占用。了解Redis内存模型可以选择更合适的数据类型和编码,更好的利用Redis内存。
3、分析解决问题。当Redis出现阻塞、内存占用等问题时,尽快发现导致问题的原因,便于分析解决问题。
一、Redis内存监控和内存消耗。
工欲善其事必先利其器,在说明Redis内存之前首先说明如何统计Redis使用内存的情况。在客户端通过redis-cli连接服务器后(后面如无特殊说明,客户端一律使用redis-cli),通过info命令可以查看内存使用情况:
1 info memory
显示结果
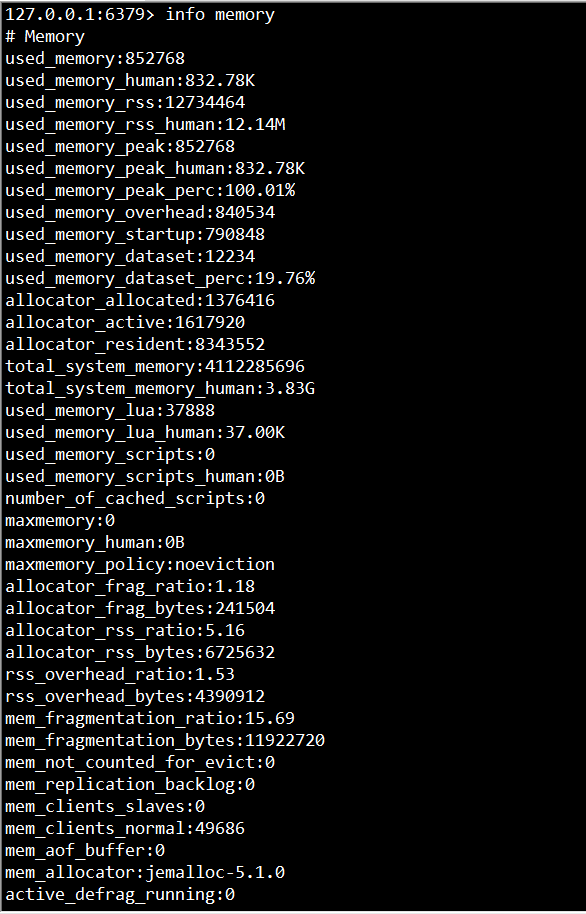
其中,info命令可以显示redis服务器的许多信息,包括服务器基本信息、CPU、内存、持久化、客户端连接信息等等;memory是参数,表示只显示内存相关的信息。
(1)used_memory:Redis分配器分配的内存总量(单位是字节),包括使用的虚拟内存(即swap);Redis分配器后面会介绍。used_memory_human只是显示更友好。
(2)used_memory_rss:Redis进程占据操作系统的内存(单位是字节),与top及ps命令看到的值是一致的;除了分配器分配的内存之外,used_memory_rss还包括进程运行本身需要的内存、内存碎片等,但是不包括虚拟内存。
因此,used_memory和used_memory_rss,前者是从Redis角度得到的量,后者是从操作系统角度得到的量。二者之所以有所不同,一方面是因为内存碎片和Redis进程运行需要占用内存,使得前者可能比后者小,另一方面虚拟内存的存在,使得前者可能比后者大。
由于在实际应用中,Redis的数据量会比较大,此时进程运行占用的内存与Redis数据量和内存碎片相比,都会小得多;因此used_memory_rss和used_memory的比例,便成了衡量Redis内存碎片率的参数;这个参数就是mem_fragmentation_ratio。
(3)mem_fragmentation_ratio:内存碎片比率,该值是used_memory_rss / used_memory的比值。
mem_fragmentation_ratio一般大于1,且该值越大,内存碎片比例越大。mem_fragmentation_ratio<1,说明Redis使用了虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。
一般来说,mem_fragmentation_ratio在1.03左右是比较健康的状态(对于jemalloc来说);上面截图中的mem_fragmentation_ratio值很大,是因为还没有向Redis中存入数据,Redis进程本身运行的内存使得used_memory_rss 比used_memory大得多。
(4)mem_allocator:Redis使用的内存分配器,在编译时指定;可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc;截图中使用的便是默认的jemalloc。
当 Redis 内存超出可以获得内存时,操作系统会进行 swap,将旧的页写入硬盘。从硬盘读写大概比从内存读写要慢5个数量级。used_memory 指标可以帮助判断 Redis 是否有被swap的风险或者它已经被swap。
建议要设置和内存一样大小的交换区,如果没有交换区,一旦 Redis 突然需要的内存大于当前操作系统可用内存时,Redis 会因为 out of memory 而被 Linix Kernel 的 OOM Killer 直接杀死。虽然当 Redis 的数据被换出 (swap out) 时,Redis的性能会变差,但是总比直接被杀死的好。
Redis 使用 maxmemory 参数限制最大可用内存。限制内存的目的主要有:
- 用于缓存场景,当超出内存上限 maxmemory 时使用 LRU 等删除策略释放空间。
- 防止所用的内存超过服务器物理内存,导致 OOM 后进程被系统杀死。
maxmemory 限制的是 Redis 实际使用的内存量,也就是 used_memory 统计项对应的内存。实际消耗的内存可能会比 maxmemory 设置的大,要小心因为这部内存导致 OOM。所以,如果你有 10GB 的内存,最好将 maxmemory 设置为 8 或者 9G
二、Redis内存划分
Redis作为内存数据库,在内存中存储的内容主要是数据(键值对);通过前面的叙述可以知道,除了数据以外,Redis的其他部分也会占用内存。Redis 进程内消耗主要包括:自身内存 + 对象内存 + 缓冲内存 + 内存碎片,其中 Redis 空进程自身内存消耗非常少,通常 usedmemoryrss 在 3MB 左右时,used_memory 一般在 800KB 左右,一个空的 Redis 进程消耗内存可以忽略不计。
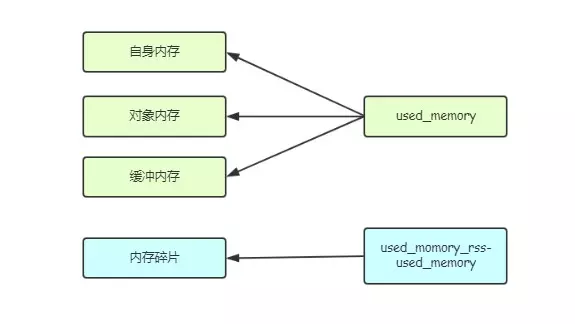
2.1 对象内存
对象内存是 Redis 内存占用最大的一块,存储着用户所有的数据。Redis 所有的数据都采用 key-value 数据类型,每次创建键值对时,至少创建两个类型对象:key 对象和 value 对象。对象内存消耗可以简单理解为这两个对象的内存消耗之和(还有类似过期之类的信息)。键对象都是字符串,在使用 Redis 时很容易忽略键对内存消耗的影响,应当避免使用过长的键。有关 Redis 对象系统的详细内容,请看我之前的文章Redis5.02源码分析---对象系统。
2.2 缓冲内存
缓冲内存主要包括:客户端缓冲、复制积压缓冲区和、AOF 缓冲区以及AOF重写缓存区。客户端缓冲指的是所有接入到 Redis 服务器 TCP 连接的输入输出缓冲。
2.2.1 客户端缓存
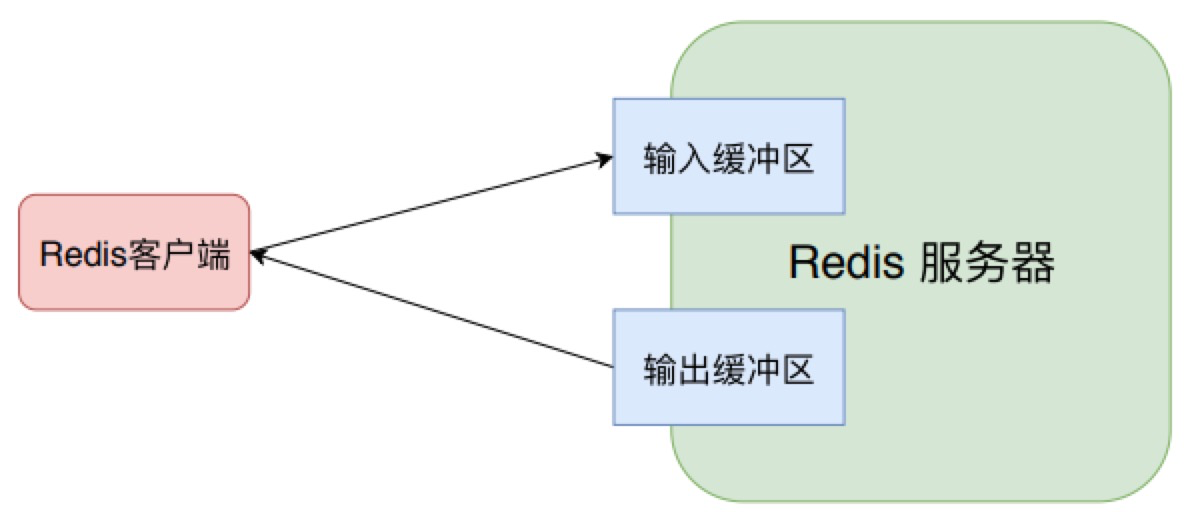
2.2.1.1输入缓存
2.2.1.1.1 输入缓存区大小
输入缓冲无法控制,最大空间为 1G,如果超过将断开连接。而且输入缓冲区不受 maxmemory 控制,假设一个 Redis 实例设置了 maxmemory 为 4G,已经存储了 2G 数据,但是如果此时输入缓冲区使用了 3G,就已经超出了 maxmemory 限制,可能导致数据丢失、键值淘汰或者 OOM。
2.2.1.1.2 输入缓存区溢出原因
输入缓冲区过大主要是因为 Redis 的处理速度跟不上输入缓冲区的输入速度,并且每次进入输入缓冲区的命令包含了大量的 bigkey。
2.2.1.2 输出缓存
2.2.1.2.1 控制参数(hard limit 、soft limit、soft seconds)
输出缓冲通过参数 client-output-buffer-limit 控制,其格式如下所示。
1 client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
hard limit 是指一旦缓冲区大小达到了这个阈值,Redis 就会立刻关闭该连接。而 soft limit 和时间soft seconds共同生效,比如说 soft time 为 64mb、soft seconds 为 60,则只有当缓冲区持续 60s 大于 64mb 时,Redis 才会关闭该连接。
2.2.1.2.2 普通客户端的输出缓存区
普通客户端是除了复制和订阅的客户端之外的所有连接。Reids 对其的默认配置是 client-output-buffer-limit normal 0 0 0 , Redis 并没有对普通客户端的输出缓冲区做限制,一般普通客户端的内存消耗可以忽略不计,但是当有大量慢连接客户端接入时这部分内存消耗就不能忽略,可以设置 maxclients 做限制,从而限制连接到redis服务器的客户端数目。特别当使用大量数据输出的命令且数据无法及时推送到客户端时,如 monitor 命令,容易造成 Redis 服务器内存突然飙升。相关案例可以查看这篇文章美团在Redis上踩过的一些坑-3.redis内存占用飙升。
2.2.1.2.3 主从复制连接中输出缓存区
从客户端用于主从复制,主节点会为每个从节点单独建立一条连接用于命令复制,默认配置为 client-output-buffer-limit slave 256mb 64mb 60。当主从节点之间网络延迟较高或主节点挂载大量从节点时这部分内存消耗将占用很大一部分,建议主节点挂载的从节点不要多于 2 个,主从节点不要部署在较差的网络环境下,如异地跨机房环境,防止复制客户端连接缓慢造成溢出。与主从复制相关的一共有两类缓冲区,一个是从客户端输出缓冲区,另外一个是下面会介绍到的复制积压缓冲区。
2.2.1.2.3 订阅客户端的输出缓存区
订阅客户端用于发布订阅功能,连接客户端使用单独的输出缓冲区,默认配置为 client-output-buffer-limit pubsub 32mb 8mb 60,当订阅服务的消息生产快于消费速度时,输出缓冲区会产生积压造成内存空间溢出。
2.2.1.2 输入和输出缓存区的监控
输入输出缓冲区在大流量场景中容易失控,造成 Redis 内存不稳定,需要重点监控。可以定期执行 client list 命令,监控每个客户端的输入输出缓冲区大小和其他信息。
| 属性名 | 属性说明 |
|---|---|
| qbuf | 查询缓冲区的长度(字节为单位, 0 表示没有分配查询缓冲区) |
| qbuf-free | 查询缓冲区剩余空间的长度(字节为单位, 0 表示没有剩余空间) |
| obl | 输出缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区) |
| oll | 输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里) |
client list执行:
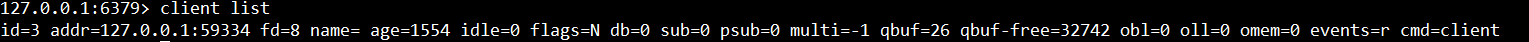
lient list 命令执行速度慢,客户端较多时频繁执行存在阻塞redis的可能,所以一般可以先使用 info clients 命令获取最大的客户端缓冲区大小。
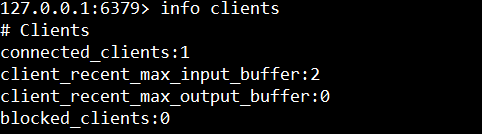
2.2.2 复制积压缓存区
复制积压缓冲区repl_backlog是Redis 在 2.8 版本后提供的一个可重用的固定大小缓冲区,用于实现部分复制功能。根据 repl-backlog-size 参数控制,默认 1MB。对于复制积压缓冲区整个主节点只有一个,所有的从节点共享此缓冲区。因此可以设置较大的缓冲区空间,比如说 100MB,可以有效避免全量复制。
2.2.3 AOF缓存区
AOF缓存区(aof_buf)是用来记录redis数据库的数据更改命令的,主要是在AOF持久化中使用,命令追加就是先追加到AOF缓存中,然后再进行文件写入等。
2.2.4 AOF重写缓存区
AOF 重写缓冲区:这部分空间用于在 Redis AOF 重写期间保存最近的写入命令。AOF 重写缓冲区的大小用户无法控制,取决于 AOF 重写时间和写入命令量,不过一般都很小。
2.3 Redis 内存碎片
Redis 默认的内存分配器采用 jemalloc,可选的分配器还有:glibc、tcmalloc。内存分配器为了更好地管理和重复利用内存,分配内存策略一般采用固定范围的内存块进行分配。但是 Redis 正常碎片率一般在 1.03 左右(为什么是这个值)。但是当存储的数据长度长度差异较大时,以下场景容易出现高内存碎片问题:
- 频繁做更新操作,例如频繁对已经存在的键执行 append、setrange 等更新操作。
- 大量过期键删除,键对象过期删除后,释放的空间无法得到重复利用,导致碎片率上升。
2.4 子进程内存消耗
2.4.1 写时复制计数
子进程内存消耗主要指执行 AOF 重写或者进行 RDB 保存时 Redis 创建的子进程内存消耗。Redis 执行 fork 操作产生的子进程内存占用量表现为与父进程相同,理论上需要一倍的物理内存来完成相应的操作。但是 Linux 具有写时复制技术 (copy-on-write),父子进程会共享相同的物理内存页,当父进程处理写请求时会对需要修改的页复制出一份副本完成写操作,而子进程依然读取 fork 时整个父进程的内存快照。
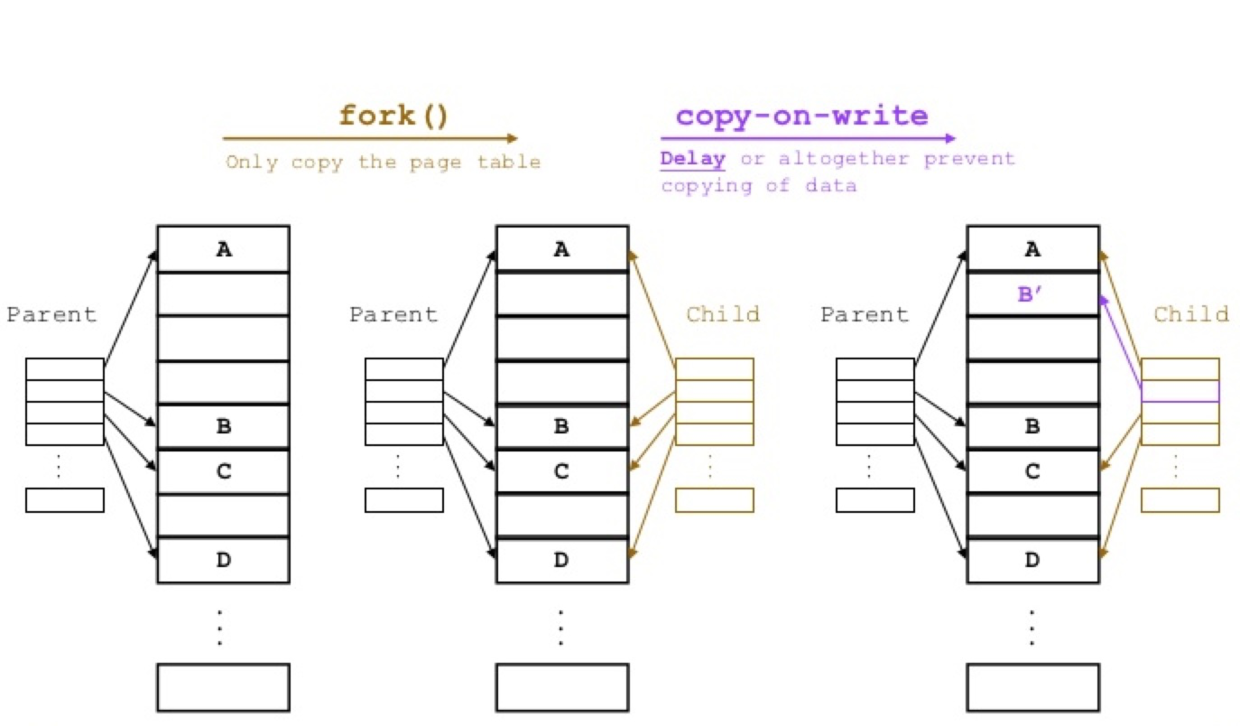
如上图所示,fork 时只拷贝 page table,也就是页表。只有等到某一页发生修改时,才真正进行页的复制。
2.4.2 Transparent Huge Pages (THP) 机制
但是 Linux Kernel 在 2.6.38 内存增加了 Transparent Huge Pages (THP) 机制,简单理解,它就是让页大小变大,本来一页为 4KB,开启 THP 机制后,一页大小为 2MB。它虽然可以加快 fork 速度( 要拷贝的页的数量减少 ),但是会导致 copy-on-write 复制内存页的单位从 4KB 增大为 2MB,如果父进程有大量写命令,会加重内存拷贝量,都是修改一个页的内容,但是页单位变大了,从而造成过度内存消耗。例如,以下两个执行 AOF 重写时的内存消耗日志:
1 // 开启 THP
2 C * AOF rewrite: 1039 MB of memory used by copy-on-write
3 // 关闭 THP
4 C * AOF rewrite: 9MB of memory used by copy-on-write
这两个日志出自同一个 Redis 进程,used_memory 总量是 1.5GB,子进程执行期间每秒写命令量都在 200 左右。当分别开启和关闭 THP 时,子进程内存消耗有天壤之别。所以,在高并发写的场景下开启 THP,子进程内存消耗可能是父进程的数倍,造成机器物理内存溢出。
2.4.3 小结
所以说,Redis 产生的子进程并不需要消耗 1 倍的父进程内存,实际消耗根据期间写入命令量决定,所以需要预留一些内存防止溢出。并且建议关闭系统的THP机制,防止 copy-on-write 期间内存过度消耗。不仅是 Redis,部署 MySQL 的机器一般也会关闭 THP。
三、Redis 内存管理机制和实现
Redis是一个基于内存的键值数据库,其内存管理是非常重要的。本文内存管理的内容包括:过期键的懒性删除、过期删除、内存溢出控制策略。
3.1 最大内存限制
Redis使用 maxmemory 参数限制最大可用内存,默认值为0,表示无限制。限制内存的目的主要有:
- 用于缓存场景,当超出内存上限 maxmemory 时使用 LRU 等删除策略释放空间。
- 防止所用内存超过服务器物理内存。因为 Redis 默认情况下是会尽可能多使用服务器的内存,可能会出现服务器内存不足,导致 Redis 进程被杀死。
maxmemory 限制的是Redis实际使用的内存量,也就是 used_memory统计项对应的内存。由于内存碎片率的存在,实际消耗的内存可能会比maxmemory设置的更大,实际使用时要小心这部分内存溢出。
Redis默认无限使用服务器内存,为防止极端情况下导致系统内存耗 尽,建议所有的Redis进程都要配置maxmemory。 在保证物理内存可用的情况下,系统中所有Redis实例可以调整 maxmemory参数来达到自由伸缩内存的目的。
3.2 内存回收策略
Redis 回收内存大致有两个机制:一是删除到达过期时间的键值对象;二是当内存达到 maxmemory 时触发内存移除控制策略,强制删除选择出来的键值对象。
3.2.1 删除过期键对象
Redis 所有的键都可以设置过期属性,内部保存在过期表中,键值表和过期表的结果如下图所示。当 Redis保存大量的键,对每个键都进行精准的过期删除可能会导致消耗大量的 CPU,会阻塞 Redis 的主线程,拖累 Redis 的性能,因此 Redis 采用惰性删除和定期删除机制实现过期键的内存回收。
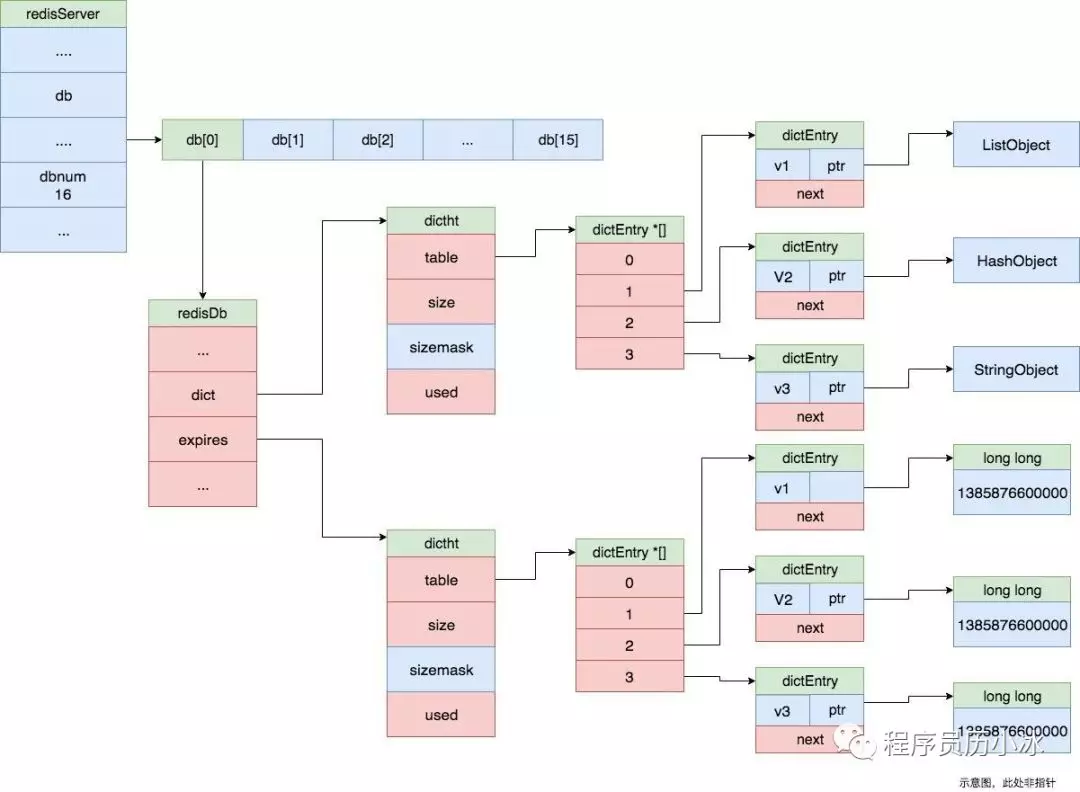
3.2.1.1 惰性删除
惰性删除是指当客户端操作带有超时属性的键时,会检查是否超过键的过期时间,然后会同步或者异步执行删除操作并返回键已经过期。这样可以节省 CPU成本考虑,不需要单独维护过期时间链表来处理过期键的删除。
过期键的惰性删除策略由 db.c/expireifNeeded 函数实现,所有对数据库的读写命令执行之前都会调用 expireifNeeded 来检查命令执行的键是否过期。如果键过期,expireifNeeded 会将过期键从键值表和过期表中删除,然后同步或者异步释放对应对象的空间。源码展示的是 Redis 5.0.2 版本。
3.2.1.2 过期键的删除
3.2.1.2.1 过期键的删除流程
expireIfNeeded 先从过期表中获取键对应的过期时间,如果当前时间已经超过了过期时间(lua脚本执行则有特殊逻辑,详看代码注释),则进入删除键流程。删除键流程主要进行了三件事:
- 一是删除操作命令传播,通知 slave 实例并存储到 AOF 缓冲区中
- 二是记录键空间事件,
- 三是根据 lazyfreelazyexpire 是否开启进行同步删除或者异步删除操作。
源码如下:
1 /* This function is called when we are going to perform some operation
2 * in a given key, but such key may be already logically expired even if
3 * it still exists in the database. The main way this function is called
4 * is via lookupKey*() family of functions.
5 *
6 * The behavior of the function depends on the replication role of the
7 * instance, because slave instances do not expire keys, they wait
8 * for DELs from the master for consistency matters. However even
9 * slaves will try to have a coherent return value for the function,
10 * so that read commands executed in the slave side will be able to
11 * behave like if the key is expired even if still present (because the
12 * master has yet to propagate the DEL).
13 *
14 * In masters as a side effect of finding a key which is expired, such
15 * key will be evicted from the database. Also this may trigger the
16 * propagation of a DEL/UNLINK command in AOF / replication stream.
17 *
18 * The return value of the function is 0 if the key is still valid,
19 * otherwise the function returns 1 if the key is expired. */
20 int expireIfNeeded(redisDb *db, robj *key) {
21 if (!keyIsExpired(db,key)) return 0;
22
23 /**
24 * If we are running in the context of a slave, instead of
25 * evicting the expired key from the database, we return ASAP:
26 * the slave key expiration is controlled by the master that will
27 * send us synthesized DEL operations for expired keys.
28 *
29 * Still we try to return the right information to the caller,
30 * that is, 0 if we think the key should be still valid, 1 if
31 * we think the key is expired at this time.
32 * 当本实例是slave时,过期键的删除由master发送过来的
33 * del 指令控制。但是这个函数还是将正确的信息返回给调用者。
34 */
35 if (server.masterhost != NULL) return 1;
36
37 /* Delete the key */
38 // 代码到这里,说明键已经过期,而且需要被删除
39 server.stat_expiredkeys++;
40 // 命令传播,到 slave 和 AOF
41 propagateExpire(db,key,server.lazyfree_lazy_expire);
42 // 键空间通知使得客户端可以通过订阅频道或模式, 来接收那些以某种方式改动了 Redis 数据集的事件。
43 notifyKeyspaceEvent(NOTIFY_EXPIRED,
44 "expired",key,db->id);
45 // 如果是惰性删除,调用dbAsyncDelete,否则调用 dbSyncDelete
46 return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
47 dbSyncDelete(db,key);
48 }
49
50 /* Check if the key is expired. */
51 int keyIsExpired(redisDb *db, robj *key) {
52 // 获取键的过期时间
53 mstime_t when = getExpire(db,key);
54
55 // 键没有过期时间
56 if (when < 0) return 0; /* No expire for this key */
57
58 /* Don't expire anything while loading. It will be done later. */
59 // 实例正在从硬盘 laod 数据,比如说 RDB 或者 AOF
60 if (server.loading) return 0;
61
62 /**
63 * If we are in the context of a Lua script, we pretend that time is
64 * blocked to when the Lua script started. This way a key can expire
65 * only the first time it is accessed and not in the middle of the
66 * script execution, making propagation to slaves / AOF consistent.
67 * See issue #1525 on Github for more information.
68 * 当执行lua脚本时,只有键在lua一开始执行时
69 * 就到了过期时间才算过期,否则在lua执行过程中不算失效
70 */
71 mstime_t now = server.lua_caller ? server.lua_time_start : mstime();
72
73 return now > when;
74 }
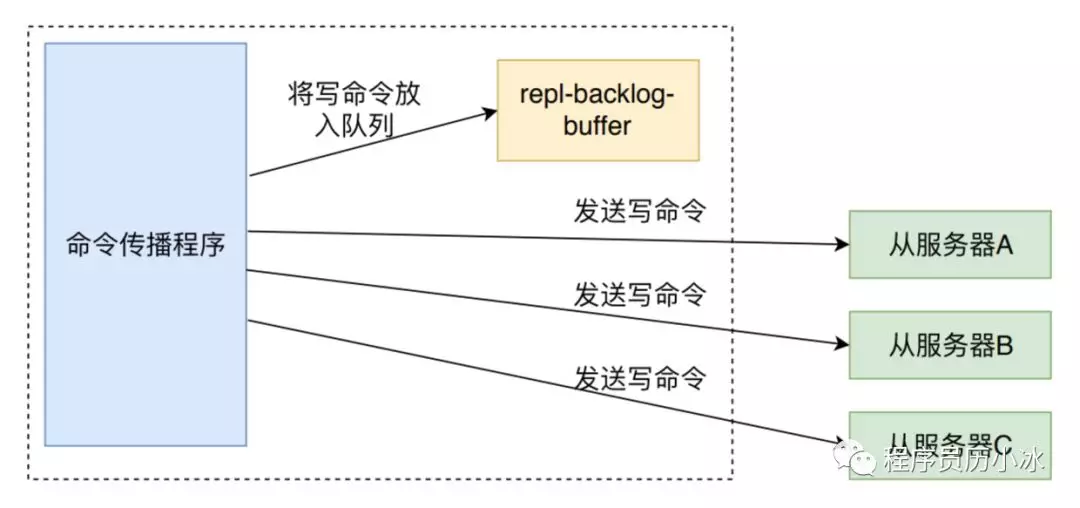
3.2.1.2.2 命令传播
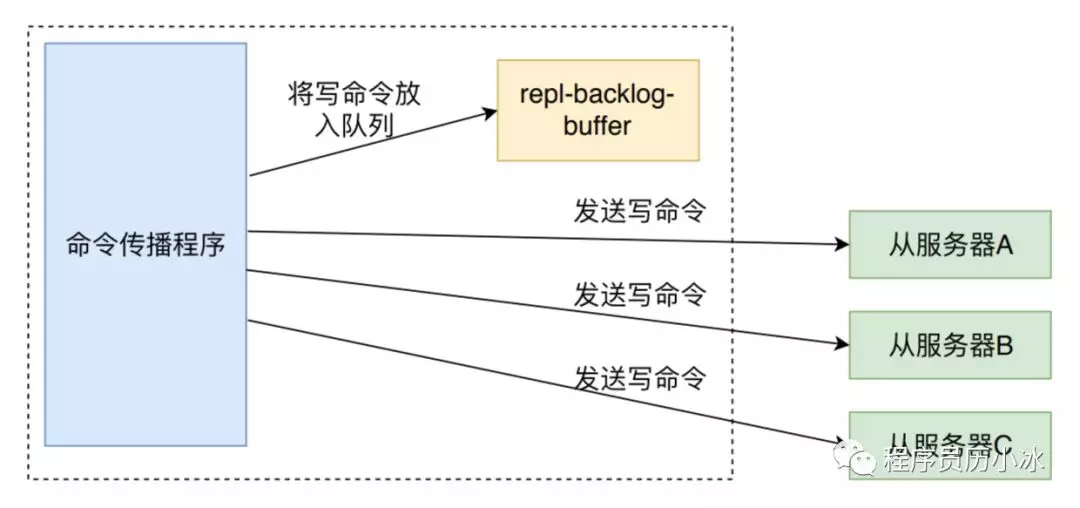
上图是写命令传播的示意图,删除命令的传播和它一致。propagateExpire 函数先调用 feedAppendOnlyFile 函数将命令同步到 AOF 的缓冲区中,然后调用 replicationFeedSlaves函数将命令同步到所有的 slave 中。函数源码如下:
1 /**
2 * Propagate expires into slaves and the AOF file.
3 * When a key expires in the master, a DEL operation for this key is sent
4 * to all the slaves and the AOF file if enabled.
5 *
6 * This way the key expiry is centralized in one place, and since both
7 * AOF and the master->slave link guarantee operation ordering, everything
8 * will be consistent even if we allow write operations against expiring
9 * keys.
10 * 将命令传递到slave和AOF缓冲区。maser删除一个过期键时会发送Del命令到所有的slave和AOF缓冲区
11 */
12 void propagateExpire(redisDb *db, robj *key, int lazy) {
13 robj *argv[2];
14
15 // 生成同步的数据
16 argv[0] = lazy ? shared.unlink : shared.del;
17 argv[1] = key;
18 incrRefCount(argv[0]);
19 incrRefCount(argv[1]);
20
21 // 如果开启了 AOF 则追加到 AOF 缓冲区中
22 if (server.aof_state != AOF_OFF)
23 feedAppendOnlyFile(server.delCommand,db->id,argv,2);
24 // 同步到所有 slave
25 replicationFeedSlaves(server.slaves,db->id,argv,2);
26
27 decrRefCount(argv[0]);
28 decrRefCount(argv[1]);
29 }
3.2.1.2.2 传出过期键并释放对象空间
流程:
- 调用dictDelete来删除过期表中的键
- 调用dictUnlink删除键值表中过期键对应的元素(注意dictDelete和dictUnlink的区别)
- 获取删除对象占用的空间大小val
- 如果val大于阈值,则使用bioCreateBackgroundJob来异步释放这个val对象的内存空间,否则直接同步调用dictFreeUnlinkedEntry释放对象的内存空间。
dbAsyncDelete 函数会先调用 dictDelete 来删除过期表中的键,然后处理键值表中的键值对象。它会根据值的占用的空间来选择是直接释放值对象,还是交给 bio 异步释放值对象。判断依据就是值的估计大小是否大于 LAZYFREE_THRESHOLD 阈值。键对象和 dictEntry 对象则都是直接被释放。
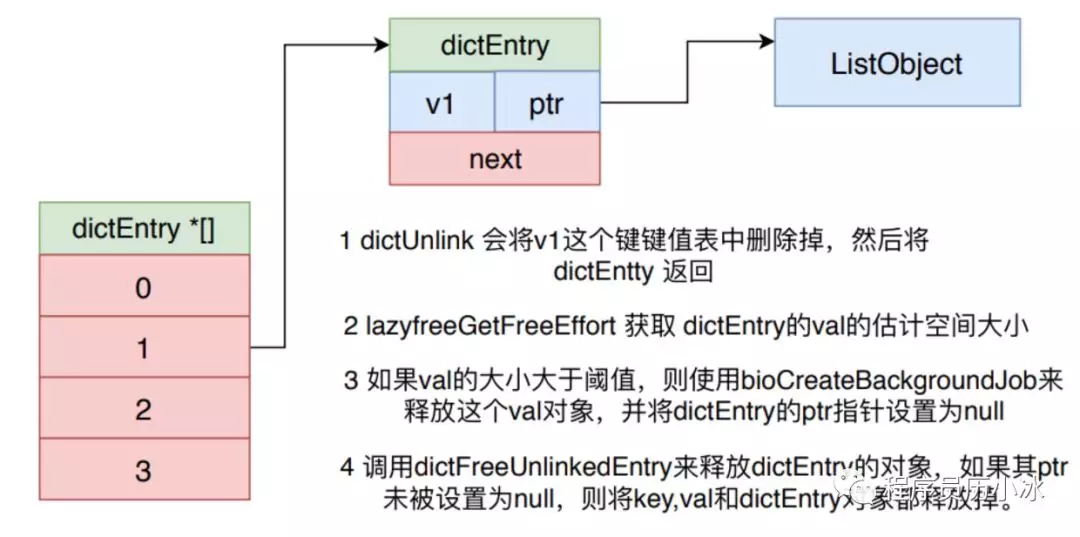
函数源码如下:
1 /**
2 * Delete a key, value, and associated expiration entry if any, from the DB.
3 * If there are enough allocations to free the value object may be put into
4 * a lazy free list instead of being freed synchronously. The lazy free list
5 * will be reclaimed in a different bio.c thread.
6 * dbAsyncDelete 函数会先调用 dictDelete 来删除过期表中的键,然后处理键值表中的键值对象。
7 * 它会根据值的占用的空间来选择是直接释放值对象,还是交给 bio 异步释放值对象。
8 * 判断依据就是值的估计大小是否大于 LAZYFREE_THRESHOLD(64M) 阈值。键对象和 dictEntry 对象则都是直接被释放。
9 */
10 #define LAZYFREE_THRESHOLD 64
11 int dbAsyncDelete(redisDb *db, robj *key) {
12 /**
13 * Deleting an entry from the expires dict will not free the sds of
14 * the key, because it is shared with the main dictionary.
15 * 删除该键在过期表中对应的entry
16 */
17 if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
18
19 /**
20 * If the value is composed of a few allocations, to free in a lazy way
21 * is actually just slower... So under a certain limit we just free
22 * the object synchronously.
23 * unlink 该键在键值表对应的entry
24 */
25 dictEntry *de = dictUnlink(db->dict,key->ptr);
26 // 如果该键值占用空间非常小,懒删除反而效率低。所以只有在一定条件下,才会异步删除
27 if (de) {
28 robj *val = dictGetVal(de);
29 size_t free_effort = lazyfreeGetFreeEffort(val);
30
31 /* If releasing the object is too much work, do it in the background
32 * by adding the object to the lazy free list.
33 * Note that if the object is shared, to reclaim it now it is not
34 * possible. This rarely happens, however sometimes the implementation
35 * of parts of the Redis core may call incrRefCount() to protect
36 * objects, and then call dbDelete(). In this case we'll fall
37 * through and reach the dictFreeUnlinkedEntry() call, that will be
38 * equivalent to just calling decrRefCount(). */
39 // 如果释放这个对象消耗很多,并且值未被共享(refcount == 1)则将其加入到懒删除列表
40 if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) {
41 atomicIncr(lazyfree_objects,1);
42 bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL);
43 dictSetVal(db->dict,de,NULL);
44 }
45 }
46
47 /* Release the key-val pair, or just the key if we set the val
48 * field to NULL in order to lazy free it later. */
49 // 释放键值对,或者只释放key,而将val设置为NULL来后续懒删除
50 if (de) {
51 dictFreeUnlinkedEntry(db->dict,de);
52 // slot 和 key 的映射关系是用于快速定位某个key在哪个 slot中。
53 if (server.cluster_enabled) slotToKeyDel(key);
54 return 1;
55 } else {
56 return 0;
57 }
58 }
3.2.1.2.3 dictUnlink和dictDelete的区别
dictUnlink 会将键值从键值表中删除,但是却不释放 key、val和对应的表entry对象,而是将其直接返回,然后再调用dictFreeUnlinkedEntry进行释放。dictDelete 是它的兄弟函数,但是会直接释放相应的对象。二者底层都通过调用 dictGenericDelete来实现。dbAsyncDelete 的兄弟函数 dbSyncDelete 就是直接调用dictDelete来删除过期键。
1 void dictFreeUnlinkedEntry(dict *d, dictEntry *he) {
2 if (he == NULL) return;
3 // 释放key对象
4 dictFreeKey(d, he);
5 // 释放值对象,如果它不为null
6 dictFreeVal(d, he);
7 // 释放 dictEntry 对象
8 zfree(he);
9 }
3.2.1.2.4 bio 机制
其实BIO全称为Background I/O,而不是代表磁盘IO请求的那个bio(阻塞IO),是Redis的后台IO服务,实现了将工作放在后台执行的功能。BIO是多线程执行的。
应用场景:
- AOF 落盘(刷新缓存)
- 懒删除逻辑
- 关闭大文件fd(AOF close操作,关闭旧的AOF文件)
- AOF重写
- RDB 持久化
- 网络IO与命令解析(6.0出现)
Redis 有自己的 bio 机制,主要是处理 AOF 落盘、懒删除逻辑和关闭大文件fd。bioCreateBackgroundJob 函数将释放值对象的 job 加入到队列中,bioProcessBackgroundJobs会从队列中取出任务,根据类型进行对应的操作。
1 void *bioProcessBackgroundJobs(void *arg) {
2 struct bio_job *job;
3 unsigned long type = (unsigned long) arg;
4 sigset_t sigset;
5
6 /* Check that the type is within the right interval. */
7 if (type >= BIO_NUM_OPS) {
8 serverLog(LL_WARNING,
9 "Warning: bio thread started with wrong type %lu",type);
10 return NULL;
11 }
12
13 /* Make the thread killable at any time, so that bioKillThreads()
14 * can work reliably. */
15 pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, NULL);
16 pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, NULL);
17
18 pthread_mutex_lock(&bio_mutex[type]);
19 /* Block SIGALRM so we are sure that only the main thread will
20 * receive the watchdog signal. */
21 sigemptyset(&sigset);
22 sigaddset(&sigset, SIGALRM);
23 if (pthread_sigmask(SIG_BLOCK, &sigset, NULL))
24 serverLog(LL_WARNING,
25 "Warning: can't mask SIGALRM in bio.c thread: %s", strerror(errno));
26
27 while(1) {
28 listNode *ln;
29
30 /* The loop always starts with the lock hold. */
31 if (listLength(bio_jobs[type]) == 0) {
32 pthread_cond_wait(&bio_newjob_cond[type],&bio_mutex[type]);
33 continue;
34 }
35 /* Pop the job from the queue. */
36 ln = listFirst(bio_jobs[type]);
37 job = ln->value;
38 /* It is now possible to unlock the background system as we know have
39 * a stand alone job structure to process.*/
40 pthread_mutex_unlock(&bio_mutex[type]);
41
42 /* Process the job accordingly to its type. */
43 if (type == BIO_CLOSE_FILE) {
44 close((long)job->arg1);
45 } else if (type == BIO_AOF_FSYNC) {
46 redis_fsync((long)job->arg1);
47 } else if (type == BIO_LAZY_FREE) {
48 /**
49 * What we free changes depending on what arguments are set:
50 * arg1 -> free the object at pointer.
51 * arg2 & arg3 -> free two dictionaries (a Redis DB).
52 * only arg3 -> free the skiplist.
53 * 根据参数来决定要做什么。有参数1则要释放它,
54 * 有参数2和3是释放两个键值表过期表,也就是释放db 只有参数三是释放跳表
55 */
56 if (job->arg1)
57 lazyfreeFreeObjectFromBioThread(job->arg1);
58 else if (job->arg2 && job->arg3)
59 lazyfreeFreeDatabaseFromBioThread(job->arg2,job->arg3);
60 else if (job->arg3)
61 lazyfreeFreeSlotsMapFromBioThread(job->arg3);
62 } else {
63 serverPanic("Wrong job type in bioProcessBackgroundJobs().");
64 }
65 zfree(job);
66
67 /* Lock again before reiterating the loop, if there are no longer
68 * jobs to process we'll block again in pthread_cond_wait(). */
69 pthread_mutex_lock(&bio_mutex[type]);
70 listDelNode(bio_jobs[type],ln);
71 bio_pending[type]--;
72
73 /* Unblock threads blocked on bioWaitStepOfType() if any. */
74 pthread_cond_broadcast(&bio_step_cond[type]);
75 }
76 }
77
78 /* Return the number of pending jobs of the specified type. */
79 unsigned long long bioPendingJobsOfType(int type) {
80 unsigned long long val;
81 pthread_mutex_lock(&bio_mutex[type]);
82 val = bio_pending[type];
83 pthread_mutex_unlock(&bio_mutex[type]);
84 return val;
85 }
86
87 /* If there are pending jobs for the specified type, the function blocks
88 * and waits that the next job was processed. Otherwise the function
89 * does not block and returns ASAP.
90 *
91 * The function returns the number of jobs still to process of the
92 * requested type.
93 *
94 * This function is useful when from another thread, we want to wait
95 * a bio.c thread to do more work in a blocking way.
96 */
97 unsigned long long bioWaitStepOfType(int type) {
98 unsigned long long val;
99 pthread_mutex_lock(&bio_mutex[type]);
100 val = bio_pending[type];
101 if (val != 0) {
102 pthread_cond_wait(&bio_step_cond[type],&bio_mutex[type]);
103 val = bio_pending[type];
104 }
105 pthread_mutex_unlock(&bio_mutex[type]);
106 return val;
107 }
dbSyncDelete 则是直接删除过期键,并且将键、值和 DictEntry 对象都释放。
1 /**
2 * Delete a key, value, and associated expiration entry if any, from the DB
3 * 直接删除过期键,并且将键、值和 DictEntry 对象都释放。
4 */
5 int dbSyncDelete(redisDb *db, robj *key) {
6 /**
7 * Deleting an entry from the expires dict will not free the sds of
8 * the key, because it is shared with the main dictionary.
9 * 删除过期表中的entry
10 */
11 if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
12 // 删除键值表中的entry
13 if (dictDelete(db->dict,key->ptr) == DICT_OK) {
14 // 如果开启了集群,则删除slot 和 key 映射表中key记录。
15 if (server.cluster_enabled) slotToKeyDel(key);
16 return 1;
17 } else {
18 return 0;
19 }
20 }
但是单独用这种方式存在内存泄露的问题,当过期键一直没有访问将无法得到及时删除,从而导致内存不能及时释放。正因为如此,Redis还提供另一种定时任务删除机制作为惰性删除的补充。
3.2.1.2 定期删除
Redis 内部维护一个定时任务,默认每秒运行10次(通过配置控制)。定时任务中删除过期键逻辑采用了自适应算法,根据键的过期比例、使用快慢两种速率模式回收键,流程如下图所示。
- 1)定时任务首先根据快慢模式( 慢模型扫描的键的数量以及可以执行时间都比快模式要多 )和相关阈值配置计算计算本周期最大执行时间、要检查的数据库数量以及每个数据库扫描的键数量。
- 2) 从上次定时任务未扫描的数据库开始,依次遍历各个数据库。
- 3)从数据库中随机选手 ACTIVEEXPIRECYCLELOOKUPSPER_LOOP 个键,如果发现是过期键,则调用 activeExpireCycleTryExpire 函数删除它。
- 4)如果执行时间超过了设定的最大执行时间,则退出,并设置下一次使用慢模式执行。
- 5)未超时的话,则判断是否采样的键中是否有25%的键是过期的,如果是则继续扫描当前数据库,跳到第3步。否则开始扫描下一个数据库。
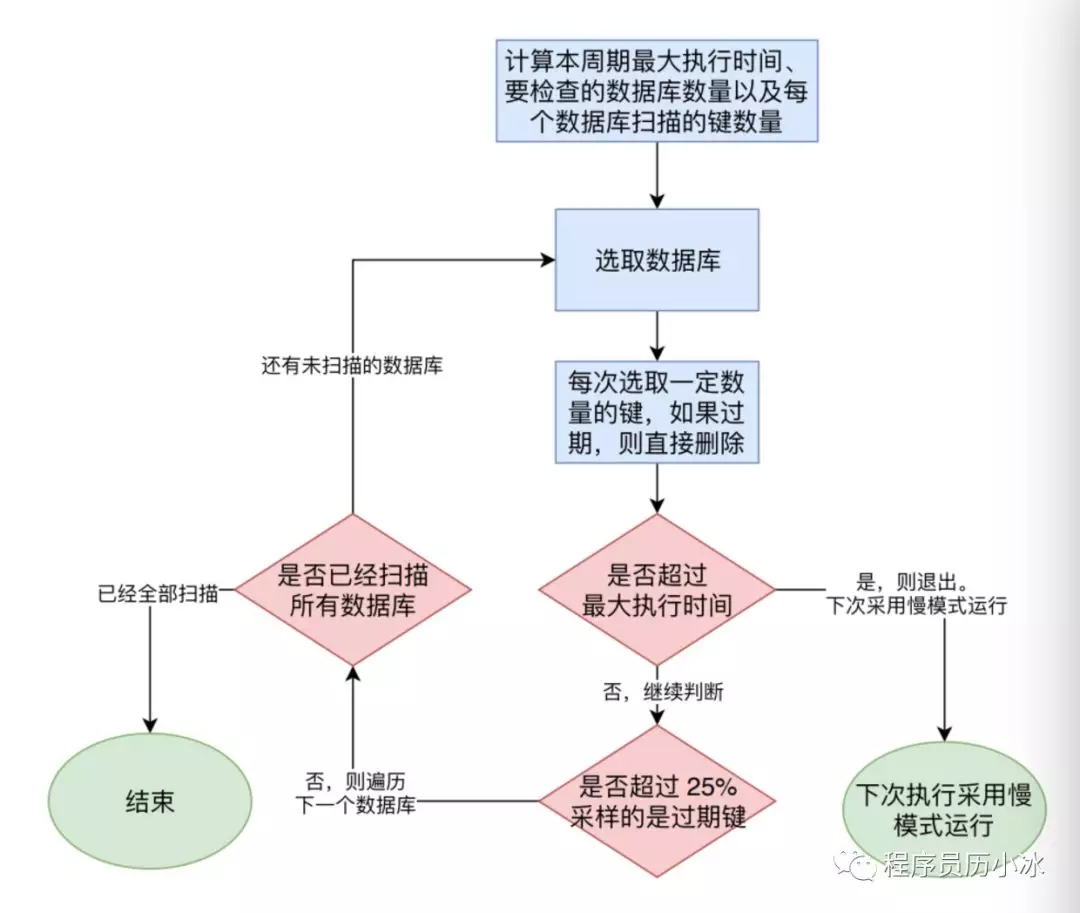
定期删除策略由 expire.c/activeExpireCycle 函数实现。在redis事件驱动的循环中的eventLoop->beforesleep和周期性操作 databasesCron 都会调用 activeExpireCycle 来处理过期键。但是二者传入的 type 值不同,一个是ACTIVEEXPIRECYCLESLOW,另外一个是ACTIVEEXPIRECYCLEFAST。activeExpireCycle 在规定的时间,分多次遍历各个数据库,从 expires 字典中随机检查一部分过期键的过期时间,删除其中的过期键,相关源码如下所示。


1 /* Try to expire a few timed out keys. The algorithm used is adaptive and 2 * will use few CPU cycles if there are few expiring keys, otherwise 3 * it will get more aggressive to avoid that too much memory is used by 4 * keys that can be removed from the keyspace. 5 * 6 * No more than CRON_DBS_PER_CALL databases are tested at every 7 * iteration. 8 * 9 * This kind of call is used when Redis detects that timelimit_exit is 10 * true, so there is more work to do, and we do it more incrementally from 11 * the beforeSleep() function of the event loop. 12 * 13 * Expire cycle type: 14 * 15 * If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a 16 * "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION 17 * microseconds, and is not repeated again before the same amount of time. 18 * 19 * If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is 20 * executed, where the time limit is a percentage of the REDIS_HZ period 21 * as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. */ 22 23 void activeExpireCycle(int type) { 24 /* This function has some global state in order to continue the work 25 * incrementally across calls. */ 26 // 上次检查的db 27 static unsigned int current_db = 0; /* Last DB tested. */ 28 // 上次检查的最大执行时间 29 static int timelimit_exit = 0; /* Time limit hit in previous call? */ 30 // 上一次快速模式运行时间 31 static long long last_fast_cycle = 0; /* When last fast cycle ran. */ 32 33 int j, iteration = 0; 34 // 每次检查周期要遍历的DB数 35 int dbs_per_call = CRON_DBS_PER_CALL; 36 long long start = ustime(), timelimit, elapsed; 37 38 // 一些状态时不进行检查,直接返回 39 40 /* When clients are paused the dataset should be static not just from the 41 * POV of clients not being able to write, but also from the POV of 42 * expires and evictions of keys not being performed. */ 43 if (clientsArePaused()) return; 44 45 if (type == ACTIVE_EXPIRE_CYCLE_FAST) { 46 /* Don't start a fast cycle if the previous cycle did not exit 47 * for time limit. Also don't repeat a fast cycle for the same period 48 * as the fast cycle total duration itself. */ 49 if (!timelimit_exit) return; 50 if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return; 51 last_fast_cycle = start; 52 } 53 54 /* We usually should test CRON_DBS_PER_CALL per iteration, with 55 * two exceptions: 56 * 57 * 1) Don't test more DBs than we have. 58 * 2) If last time we hit the time limit, we want to scan all DBs 59 * in this iteration, as there is work to do in some DB and we don't want 60 * expired keys to use memory for too much time. */ 61 // 如果上次周期因为执行达到了最大执行时间而退出,则本次遍历所有db,否则遍历db数等于 CRON_DBS_PER_CALL 62 if (dbs_per_call > server.dbnum || timelimit_exit) 63 dbs_per_call = server.dbnum; 64 65 /* We can use at max ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC percentage of CPU time 66 * per iteration. Since this function gets called with a frequency of 67 * server.hz times per second, the following is the max amount of 68 * microseconds we can spend in this function. */ 69 // 根据ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC计算本次最大执行时间 70 timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100; 71 timelimit_exit = 0; 72 if (timelimit <= 0) timelimit = 1; 73 74 // 如果是快速模式,则最大执行时间为ACTIVE_EXPIRE_CYCLE_FAST_DURATION 75 if (type == ACTIVE_EXPIRE_CYCLE_FAST) 76 timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION; /* in microseconds. */ 77 78 /* Accumulate some global stats as we expire keys, to have some idea 79 * about the number of keys that are already logically expired, but still 80 * existing inside the database. */ 81 // 采样记录 82 long total_sampled = 0; 83 long total_expired = 0; 84 85 // 依次遍历 dbs_per_call 个 db 86 for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) { 87 int expired; 88 redisDb *db = server.db+(current_db % server.dbnum); 89 90 /* Increment the DB now so we are sure if we run out of time 91 * in the current DB we'll restart from the next. This allows to 92 * distribute the time evenly across DBs. */ 93 // 将db数增加,一遍下一次继续从这个db开始遍历 94 current_db++; 95 96 /* Continue to expire if at the end of the cycle more than 25% 97 * of the keys were expired. */ 98 do { 99 // 申明变量和一些情况下 break 100 unsigned long num, slots; 101 long long now, ttl_sum; 102 int ttl_samples; 103 iteration++; 104 105 /* If there is nothing to expire try next DB ASAP. */ 106 if ((num = dictSize(db->expires)) == 0) { 107 db->avg_ttl = 0; 108 break; 109 } 110 slots = dictSlots(db->expires); 111 now = mstime(); 112 113 /* When there are less than 1% filled slots getting random 114 * keys is expensive, so stop here waiting for better times... 115 * The dictionary will be resized asap. */ 116 if (num && slots > DICT_HT_INITIAL_SIZE && 117 (num*100/slots < 1)) break; 118 119 /* The main collection cycle. Sample random keys among keys 120 * with an expire set, checking for expired ones. */ 121 expired = 0; 122 ttl_sum = 0; 123 ttl_samples = 0; 124 125 if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP) 126 num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP; 127 128 // 主要循环,在过期表中进行随机采样,判断是否比率大于25% 129 while (num--) { 130 dictEntry *de; 131 long long ttl; 132 133 if ((de = dictGetRandomKey(db->expires)) == NULL) break; 134 ttl = dictGetSignedIntegerVal(de)-now; 135 // 删除过期键 136 if (activeExpireCycleTryExpire(db,de,now)) expired++; 137 if (ttl > 0) { 138 /* We want the average TTL of keys yet not expired. */ 139 ttl_sum += ttl; 140 ttl_samples++; 141 } 142 total_sampled++; 143 } 144 // 记录过期总数 145 total_expired += expired; 146 147 /* Update the average TTL stats for this database. */ 148 if (ttl_samples) { 149 long long avg_ttl = ttl_sum/ttl_samples; 150 151 /* Do a simple running average with a few samples. 152 * We just use the current estimate with a weight of 2% 153 * and the previous estimate with a weight of 98%. */ 154 if (db->avg_ttl == 0) db->avg_ttl = avg_ttl; 155 db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50); 156 } 157 158 /* We can't block forever here even if there are many keys to 159 * expire. So after a given amount of milliseconds return to the 160 * caller waiting for the other active expire cycle. */ 161 // 即使有很多键要过期,也不阻塞很久,如果执行超过了最大执行时间,则返回 162 if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */ 163 elapsed = ustime()-start; 164 if (elapsed > timelimit) { 165 timelimit_exit = 1; 166 server.stat_expired_time_cap_reached_count++; 167 break; 168 } 169 } 170 /* We don't repeat the cycle if there are less than 25% of keys 171 * found expired in the current DB. */ 172 } while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);// 当比率小于25%时返回 173 } 174 175 // 更新一些server的记录数据 176 elapsed = ustime()-start; 177 latencyAddSampleIfNeeded("expire-cycle",elapsed/1000); 178 179 /* Update our estimate of keys existing but yet to be expired. 180 * Running average with this sample accounting for 5%. */ 181 double current_perc; 182 if (total_sampled) { 183 current_perc = (double)total_expired/total_sampled; 184 } else 185 current_perc = 0; 186 server.stat_expired_stale_perc = (current_perc*0.05)+ 187 (server.stat_expired_stale_perc*0.95); 188 }
activeExpireCycleTryExpire 函数的实现就和 expireIfNeeded 类似。
1 /* Helper function for the activeExpireCycle() function.
2 * This function will try to expire the key that is stored in the hash table
3 * entry 'de' of the 'expires' hash table of a Redis database.
4 *
5 * If the key is found to be expired, it is removed from the database and
6 * 1 is returned. Otherwise no operation is performed and 0 is returned.
7 *
8 * When a key is expired, server.stat_expiredkeys is incremented.
9 *
10 * The parameter 'now' is the current time in milliseconds as is passed
11 * to the function to avoid too many gettimeofday() syscalls. */
12 int activeExpireCycleTryExpire(redisDb *db, dictEntry *de, long long now) {
13 long long t = dictGetSignedIntegerVal(de);
14 if (now > t) {
15 sds key = dictGetKey(de);
16 robj *keyobj = createStringObject(key,sdslen(key));
17
18 propagateExpire(db,keyobj,server.lazyfree_lazy_expire);
19 if (server.lazyfree_lazy_expire)
20 dbAsyncDelete(db,keyobj);
21 else
22 dbSyncDelete(db,keyobj);
23 notifyKeyspaceEvent(NOTIFY_EXPIRED,
24 "expired",keyobj,db->id);
25 decrRefCount(keyobj);
26 server.stat_expiredkeys++;
27 return 1;
28 } else {
29 return 0;
30 }
31 }
定期删除策略的关键点就是删除操作执行的时长和频率:
- 如果删除操作太过频繁或者执行时间太长,就对 CPU 时间不是很友好,CPU 时间过多的消耗在删除过期键上。
- 如果删除操作执行太少或者执行时间太短,就不能及时删除过期键,导致内存浪费。
3.3 内存溢出控制策略
当Redis所用内存达到maxmemory上限时会触发相应的溢出控制策略。 具体策略受maxmemory-policy参数控制,Redis支持6种策略,如下所示:
- 1)noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返 回客户端错误信息(error)OOM command not allowed when used memory,此 时Redis只响应读操作。
- 2)volatile-lru:根据LRU算法删除设置了超时属性(expire)的键,直 到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略。
- 3)allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性, 直到腾出足够空间为止。
- 4)allkeys-random:随机删除所有键,直到腾出足够空间为止。
- 5)volatile-random:随机删除过期键,直到腾出足够空间为止。
- 6)volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。
内存溢出控制策略可以使用 config set maxmemory-policy {policy} 语句进行动态配置。Redis 提供了丰富的空间溢出控制策略,我们可以根据自身业务需要进行选择。
当设置 volatile-lru 策略时,保证具有过期属性的键可以根据 LRU 剔除,而未设置超时的键可以永久保留。还可以采用allkeys-lru 策略把 Redis 变为纯缓存服务器使用。
当Redis因为内存溢出删除键时,可以通过执行 info stats 命令查看 evicted_keys 指标找出当前 Redis 服务器已剔除的键数量。
每次Redis执行命令时如果设置了maxmemory参数,都会尝试执行回收内存操作。当Redis一直工作在内存溢出(used_memory>maxmemory)的状态下且设置非 noeviction 策略时,会频繁地触发回收内存的操作,影响Redis 服务器的性能,这一点千万要引起注意。
四、参考文章
https://blog.csdn.net/qq_35433716/article/details/82179168
https://www.cnblogs.com/remcarpediem/p/11687524.html
https://www.cnblogs.com/remcarpediem/p/11755860.html