为什么深度学习发展了
数据
计算
算法发展
Logistics Regression
Numpy
reshape的计算代价很小,所以你不确定数据维度的时候都可以放上
一些解决潜在bug的trick
做了归一化之后梯度下降更易收敛
激活函数
对于权值要做随机初始化
为什么要深层网络
Reference
数据
计算
算法发展
Logistics Regression
Numpy
reshape的计算代价很小,所以你不确定数据维度的时候都可以放上
一些解决潜在bug的trick
做了归一化之后梯度下降更易收敛
激活函数
对于权值要做随机初始化
为什么要深层网络
Reference
为什么深度学习发展了
数据
- 对于小量数据来说,神经网络表现比线性回归、SVM
- 对于大量数据来说神经网络比SVM好
- 对于大量数据来说,大的网络比小的网络好
- 由于电脑的大量使用数据越来越多
计算
- GPUs.
- Powerful CPUS.
- Distributed computing.
- ASICs
算法发展
Relu等新的技巧提出
Logistics Regression
Numpy
reshape的计算代价很小,所以你不确定数据维度的时候都可以放上
一些解决潜在bug的trick
- 如果不设置向量的维度,那么默认值会是(m,),并且转置操作不会使用,你必须将其reshape成(m,1)。尽量不要使用rank=1的矩阵
- 计算前尝试检验维度,如
assert(a.shape == (5,1))
- 如果发现了rank=1的矩阵,做reshape
做了归一化之后梯度下降更易收敛
激活函数
- tanh在隐层使用会比较好(mean=0)
- sigmoid和tanh会存在问题,因为当值极小或极大会造成梯度接近零
- relu更加常用
- 选择激活函数的准则:如果你的分类结果是0和1,用sigmoid,否则用relu
对于权值要做随机初始化
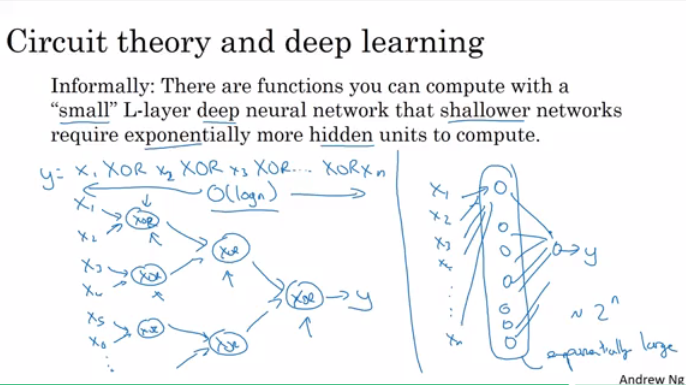
为什么要深层网络
- 一层层分析,类似人脑
- 几层的深度网络完成的功能,需要指数个数的隐藏单元来完成。
http://blog.csdn.net/column/details/17767.html
Reference
assert(a.shape == (5,1)) - tanh在隐层使用会比较好(mean=0)
- sigmoid和tanh会存在问题,因为当值极小或极大会造成梯度接近零
- relu更加常用
- 选择激活函数的准则:如果你的分类结果是0和1,用sigmoid,否则用relu
对于权值要做随机初始化
为什么要深层网络
- 一层层分析,类似人脑
- 几层的深度网络完成的功能,需要指数个数的隐藏单元来完成。
http://blog.csdn.net/column/details/17767.html
Reference
- 一层层分析,类似人脑
- 几层的深度网络完成的功能,需要指数个数的隐藏单元来完成。
http://blog.csdn.net/column/details/17767.html
Reference
https://github.com/mbadry1/DeepLearning.ai-Summary