

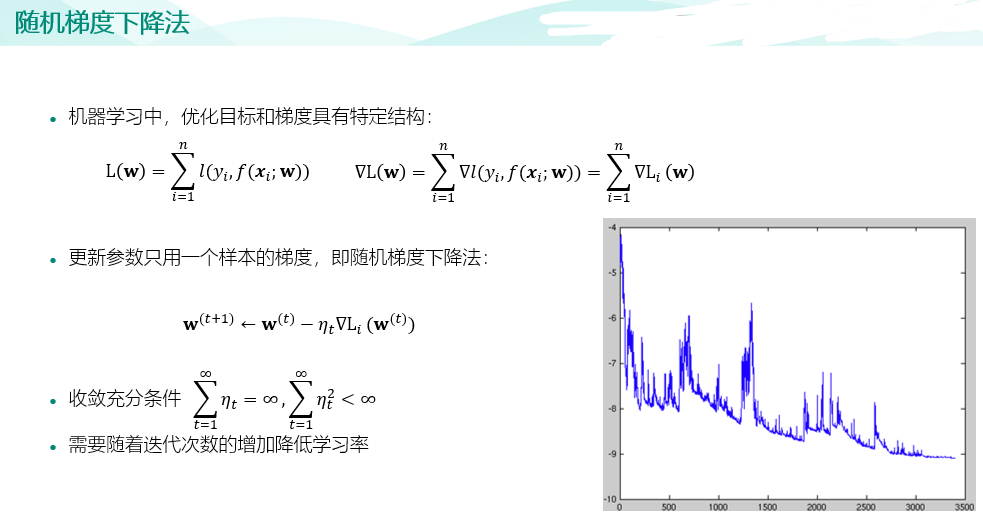







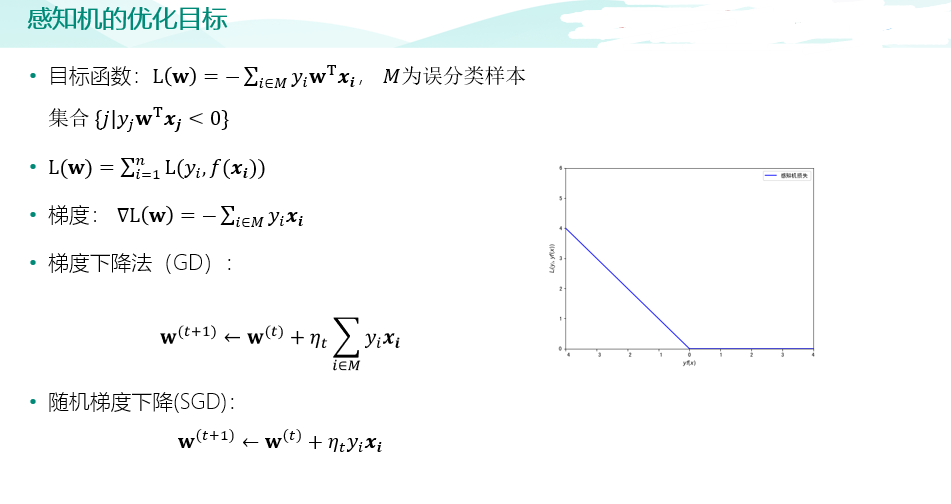


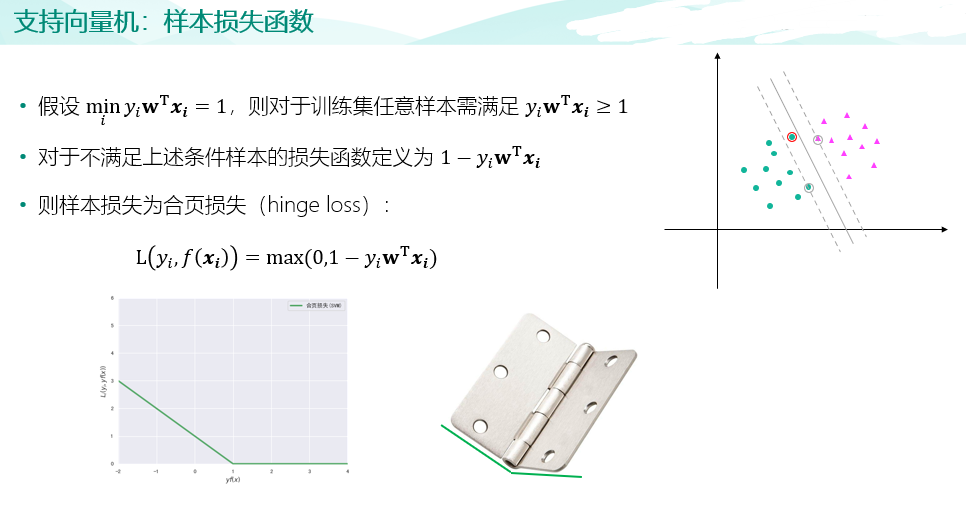





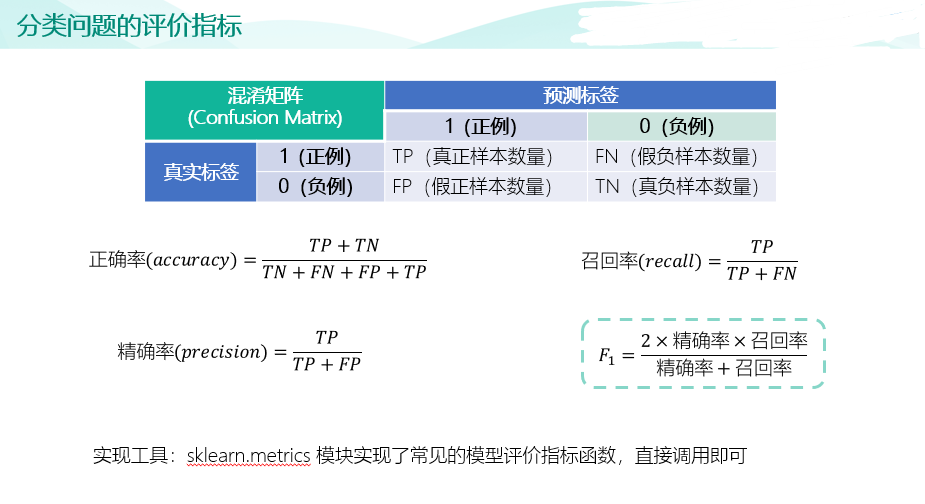
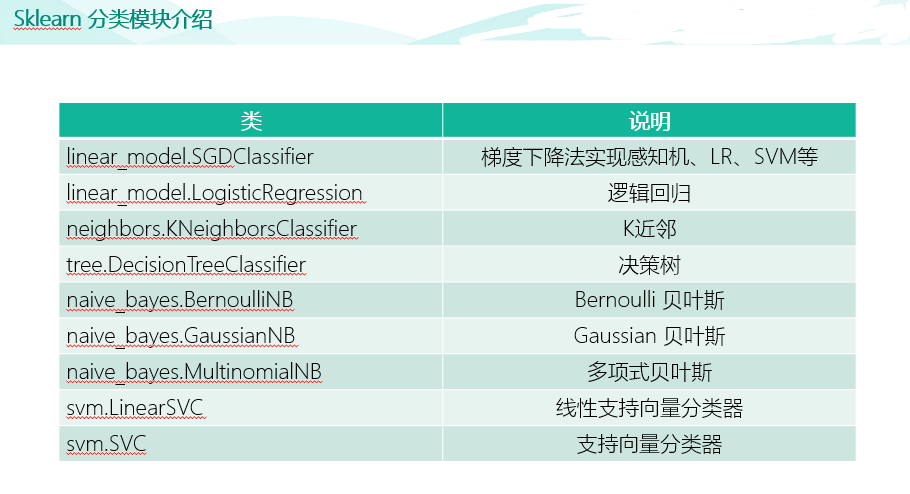
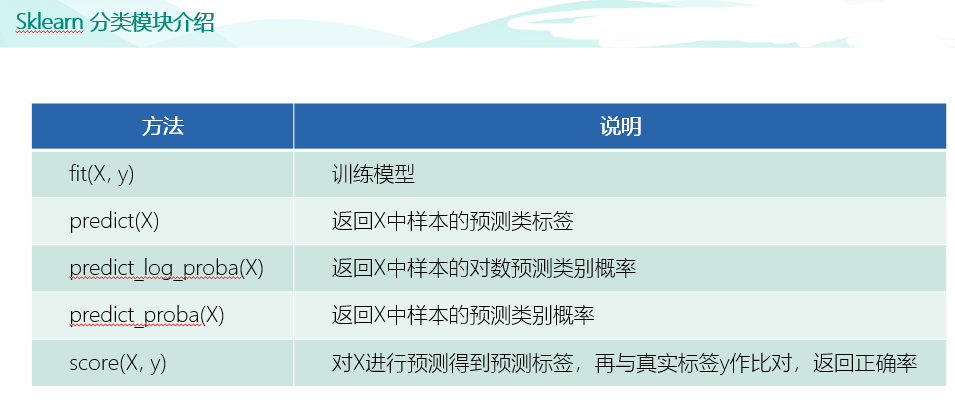

import pandas as pd raw_train = pd.read_csv("input/chinese_news_cutted_train_utf8.csv",sep=" ",encoding="utf8") raw_test = pd.read_csv("input/chinese_news_cutted_test_utf8.csv",sep=" ",encoding="utf8") raw_train_binary = raw_train[((raw_train["分类"] == "科技") | (raw_train["分类"] == "文化"))] raw_test_binary = raw_test[((raw_test["分类"] == "科技") | (raw_test["分类"] == "文化"))] stop_words = [] file = open("input/stopwords.txt",encoding='UTF-8') for line in file: stop_words.append(line.strip()) file.close() from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer(stop_words=stop_words) X_train = vectorizer.fit_transform(raw_train_binary["分词文章"]) X_test = vectorizer.transform(raw_test_binary["分词文章"]) random_state=111 from sklearn.linear_model import SGDClassifier percep_clf = SGDClassifier(loss="perceptron",penalty=None,learning_rate="constant",eta0=1.0,max_iter=1000,random_state=111) lr_clf = SGDClassifier(loss="log",penalty=None,learning_rate="constant",eta0=1.0,max_iter=1000,random_state=111) lsvm_clf = SGDClassifier(loss="hinge",penalty="l2",alpha=0.0001,learning_rate="constant",eta0=1.0,max_iter=1000,random_state=111) # 训练感知机模型 percep_clf.fit(X_train,raw_train_binary["分类"]) # 输出测试集分类正确率 print(round(percep_clf.score(X_test,raw_test_binary["分类"]),2)) # 训练逻辑回归模型 lr_clf.fit(X_train,raw_train_binary["分类"]) # 输出测试集分类正确率 print(round(lr_clf.score(X_test,raw_test_binary["分类"]),2)) # 训练线性支持向量机模型 lsvm_clf.fit(X_train,raw_train_binary["分类"]) # 输出测试集分类正确率 print(round(lsvm_clf.score(X_test,raw_test_binary["分类"]),2)) from sklearn.metrics import confusion_matrix import seaborn as sns import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(5,5)) # 设置正常显示中文 plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签 plt.rcParams['axes.unicode_minus']=False #这两行需要手动设置 # 绘制热力图 y_svm_pred = lsvm_clf.predict(X_test) # 预测标签 y_test_true = raw_test_binary["分类"] #真实标签 confusion_matrix = confusion_matrix(y_svm_pred,y_test_true)#计算混淆矩阵 ax = sns.heatmap(confusion_matrix,linewidths=.5,cmap="Greens", annot=True, fmt='d',xticklabels=lsvm_clf.classes_, yticklabels=lsvm_clf.classes_) ax.set_ylabel('真实') ax.set_xlabel('预测') ax.xaxis.set_label_position('top') ax.xaxis.tick_top() ax.set_title('混淆矩阵热力图') plt.show()