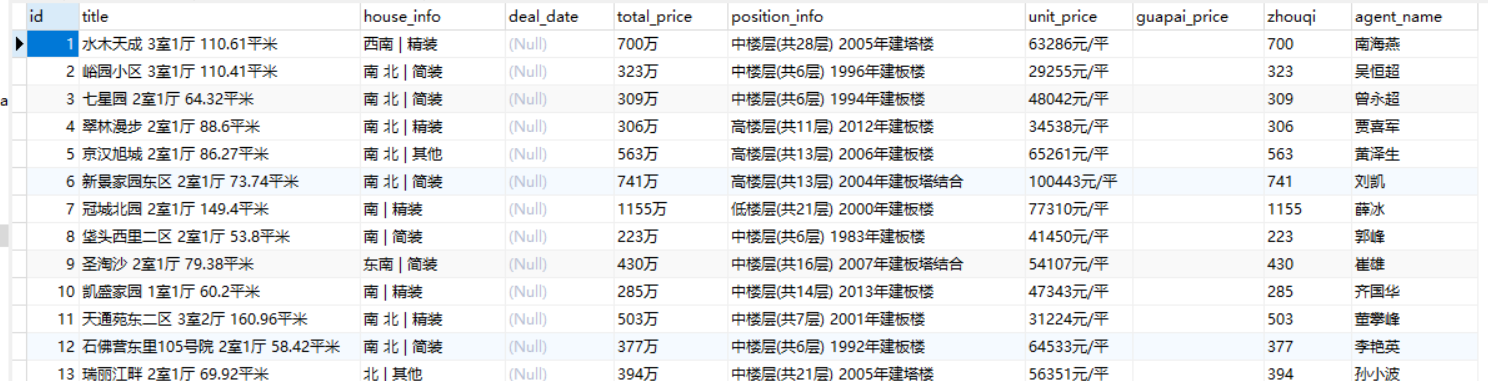
1、爬取链家二手房信息,存入数据库(MySQL)数据来源:链家
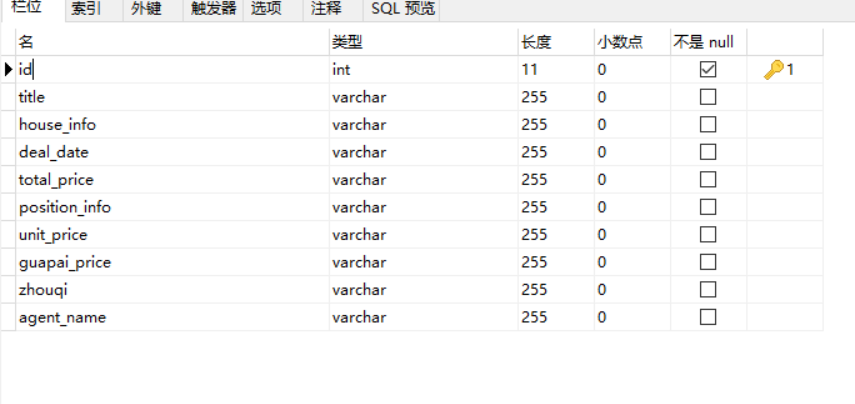
2、数据库表结构
3、代码


'''使用面向对象的方式,搭建项目框架''' import requests from bs4 import BeautifulSoup import pymysql class LianJiaSpider(): mydb = pymysql.connect("localhost", "root", "123456", "pythontest", charset='utf8') mycursor = mydb.cursor() #初始化 def __init__(self): self.url='https://bj.lianjia.com/chengjiao/pg{0}/'#初始化请求的url #将其伪装成浏览器,对付反爬的 self.headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'} #发送请求的方法 def send_request(self,url): resp=requests.get(url,headers=self.headers) if resp.status_code==200: return resp #解析html获取有用的数据 def parse_content(self,resp): html=resp.text bs=BeautifulSoup(html,'html.parser')#第一个参数是要解析的内容,第二个参数是解析器 #查找自己想要的内容 ul=bs.find('ul',class_='listContent') #在劜中获取所有的li li_list=ul.find_all('li') #遍历 lst=[] for item in li_list: title=item.find('div',class_='title').text#标题 house_info=item.find('div',class_='houseInfo').text#房屋描述 deal_date=item.find('div',class_='dealData')#成交的日期 total_price=item.find('div',class_='totalPrice').text#总价 position_info=item.find('div',class_='positionInfo').text#楼层信息 unit_price=item.find('div',class_='unitPrice').text#单价 span_list = item.find_all('span') # 获取挂牌价和成交周期 agent_name = item.find('a', class_='agent_name').text # 销售 lst.append((title,house_info,deal_date,total_price,position_info,unit_price,span_list[0].text,span_list[1].text,agent_name)) #数据解析完毕,需要存储到数据库 self.write_mysql(lst) def write_mysql(self,lst): sql_cixian = "INSERT INTO ershoufang values (0,%s,%s,%s,%s,%s,%s,%s,%s,%s)" self.mycursor.executemany(sql_cixian, lst) self.mydb.commit() print('添加成功') self.mydb.close() #写入数据库 def write_mysal(self): pass #启动爬虫程序 def start(self): for i in range(1,2): full_url=self.url.format(i) resp=self.send_request(full_url)#发送请求 if resp: self.parse_content(resp)#传入数据 if __name__=='__main__': #创建类的对象 lianjia=LianJiaSpider() lianjia.start()
4、结果