下面的分析相当于一个框架,搞懂之后,对于类似的文字爬取,我们也可以实现。就算不能使用Ajax方法,我们也能够使用相同思想去爬取我们想要的数据。
豆瓣电影排行榜分析
首先我们打开网页的审查元素,选中Network==》XHR==》电影相关信息网页文件
筛选并比较以下数据(三个文件数据)
请求地址
Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=40
查询参数
type:movie tag:热门 sort:recommend page_limit:20 page_start:0 type:movie tag:热门 sort:recommend page_limit:20 page_start:20 type:movie tag:热门 sort:recommend page_limit:20 page_start:40
请求报头
Host:movie.douban.com Referer:https://movie.douban.com/explore User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 X-Requested-With:XMLHttpRequest
通过比较请求地址和查询参数,得出
请求地址 = baseurl+type+tag+sort+page_limit+page_start baseurl:https://movie.douban.com/j/search_subjects? type:固定为movie tag:关键字,需要将utf-8转换为urlencode sort:固定为recommend page_limit:表示一页显示的电影数量,固定20 page_start:表示电影页数,从0开始,20为公差的递增函数
由此我们获取到了我们需要的数据,可以将爬虫分为三步
- 获取网页json格式代码
- 从代码中获取电影名和电影海报图片链接
- 将获得的图片命名为电影名
流程
准备工作
在函数外部定义伪装的请求报头
headers={ 'Host': 'movie.douban.com', 'Referer': 'https://movie.douban.com/explore', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest' }
获取json格式代码
def get_page(page): #请求参数 params={ 'type': 'movie', 'tag': '奥特曼', 'sort': 'recommend', 'page_limit': '20', 'page_start': page, } #基本网页链接 base_url = 'https://movie.douban.com/j/search_subjects?' #将基本网页链接与请求参数结合在一起 url = base_url + urlencode(params) try: #获取网页代码 resp = requests.get(url, headers=headers) print(url) #返回json数据格式代码 if 200 == resp.status_code: print(resp.json()) return resp.json() except requests.ConnectionError: return None
筛选数据
通过观察电影列表代码文件的preview,进行数据筛选
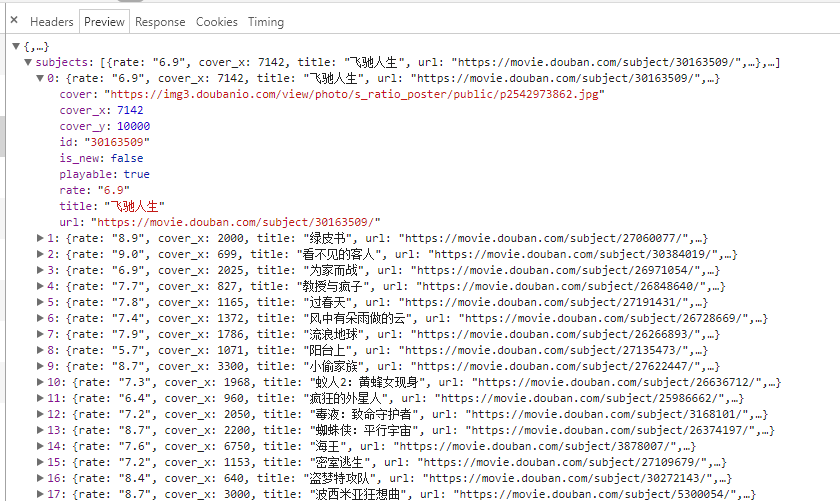
def get_image(json): if(json.get('subjects')): data=json.get('subjects') for item in data: title=item.get('title') imageurl=item.get('cover') #返回"信息"字典 yield { 'title':title, 'images':imageurl, }
存储图片文件
def save_page(item): #文件夹名称 file_name = '奥特曼电影大全' if not os.path.exists(file_name): os.makedirs(file_name) #获取图片链接 response=requests.get(item.get('images')) #储存图片文件 if response.status_code==200: file_path = file_name + os.path.sep + item.get('title') + '.jpg' with open(file_path, 'wb') as f: f.write(response.content)
多线程处理
def main(page): json = get_page(page) for item in get_image(json): print(item) save_page(item) if __name__ == '__main__': pool = Pool() pool.map(main, [i for i in range(0, 200, 20)]) pool.close() pool.join()

总代码
import requests from urllib.parse import urlencode import os from multiprocessing.pool import Pool headers={ 'Host': 'movie.douban.com', 'Referer': 'https://movie.douban.com/explore', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest' } def get_page(page): #请求参数 params={ 'type': 'movie', 'tag': '奥特曼', 'sort': 'recommend', 'page_limit': '20', 'page_start': page, } #基本网页链接 base_url = 'https://movie.douban.com/j/search_subjects?' #将基本网页链接与请求参数结合在一起 url = base_url + urlencode(params) try: #获取网页代码 resp = requests.get(url, headers=headers) print(url) #返回json数据格式代码 if 200 == resp.status_code: print(resp.json()) return resp.json() except requests.ConnectionError: return None def get_image(json): if(json.get('subjects')): data=json.get('subjects') for item in data: title=item.get('title') imageurl=item.get('cover') #返回"信息"字典 yield { 'title':title, 'images':imageurl, } def save_page(item): #文件夹名称 file_name = '奥特曼电影大全' if not os.path.exists(file_name): os.makedirs(file_name) #获取图片链接 response=requests.get(item.get('images')) #储存图片文件 if response.status_code==200: file_path = file_name + os.path.sep + item.get('title') + '.jpg' with open(file_path, 'wb') as f: f.write(response.content) def main(page): json = get_page(page) for item in get_image(json): print(item) save_page(item) if __name__ == '__main__': pool = Pool() pool.map(main, [i for i in range(0, 200, 20)]) pool.close() pool.join()
本来是准备使用https://movie.douban.com/tag/#/ 不过在后面,刷新网页时,总是出现服务器问题。不过下面的代码还是可以用。
import requests from urllib.parse import urlencode import os from hashlib import md5 from multiprocessing.pool import Pool headers={ 'Host': 'movie.douban.com', 'Referer': 'https://movie.douban.com/tag/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', } def get_page(page): params={ 'sort':'U', 'range':'0,10', 'tags':'奥特曼', 'start': page, } base_url = 'https://movie.douban.com/j/new_search_subjects?' url = base_url + urlencode(params) try: resp = requests.get(url, headers=headers) print(url) if 200 == resp.status_code: print(resp.json()) return resp.json() except requests.ConnectionError: return None def get_image(json): if(json.get('data')): data=json.get('data') for item in data: title=item.get('title') imageurl=item.get('cover') yield { 'title':title, 'images':imageurl, } def save_page(item): file_name='奥特曼大全'+os.path.sep+item.get('title') if not os.path.exists(file_name): os.makedirs(file_name) try: response=requests.get(item.get('images')) if response.status_code==200: file_path = '{0}/{1}.{2}'.format(file_name, md5(response.content).hexdigest(), 'jpg') if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(response.content) else: print('Already Downloaded', file_path) except requests.ConnectionError: print('Failed to Save Image') def main(page): json = get_page(page) for item in get_image(json): print(item) save_page(item) if __name__ == '__main__': pool = Pool() pool.map(main, [i for i in range(0, 200, 20)]) pool.close() pool.join()