我们在今后的爬虫学习过程中,要爬许许多多的网站。
唯有掌握如何对不同网站寻找到正确的post地址,才是任务之重。
比如,我访问了一个别的网站,这儿用人人网做例子。
在人人网登陆界面,使用F12进入开发者模式,找到整个登陆界面的源码:
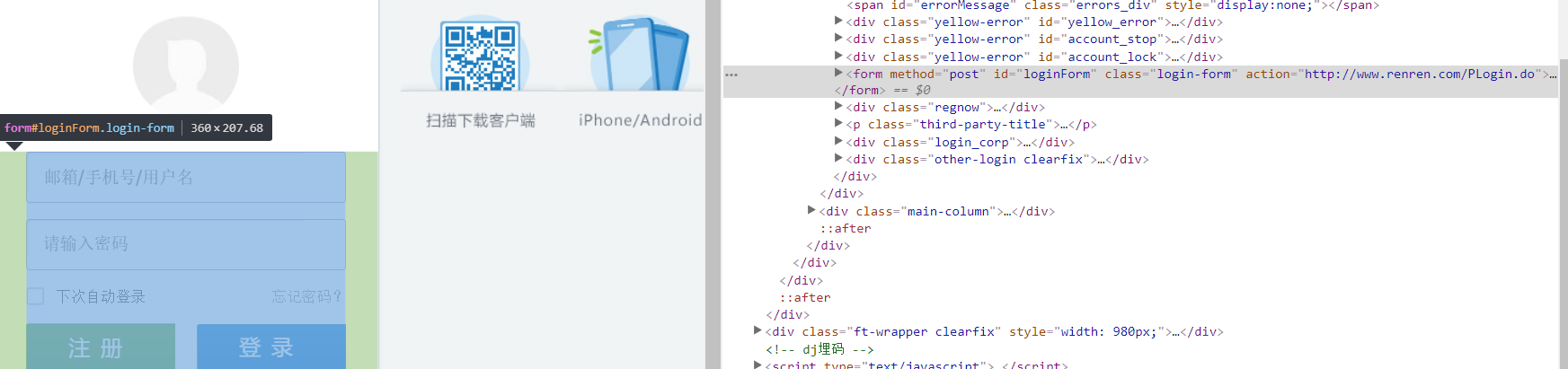
所以,我们可以看到关键的登录模块源码有一个关键的参数,这个参数是action,存储登陆的url地址。
action="http://www.renren.com/Plogin.do"
寻找登陆的post地址:
在form表单中寻找action对应的url地址,post的数据是input标签中的name的值作为键,真正的用户名密码作为值的字典。post的url地址就是action对应的url地址。
寻找post的数据,结合定位js:
1.在开发者模式中,选择会触发js时间的按钮,点击event listener,找到js的位置。
2.通过chrome中的search all file来搜索url中的关键字。
3.抓包,寻找登陆的url,反复调试对比,确定不会变的参数。
那么,我们来优化使用post参数请求百度翻译的代码:
我们要养成一个好的习惯,在敲代码之前,我们要打出代码的草稿如下:
import requests
class BaiduFanyi:
def __init__(self): # 1.1 准备post的url地址,post_data
pass
def parse_url(self): # 1.2 发送post的数据,获取响应
pass
def get_ret(self): # 4.提取翻译的结果
pass
def run(self): # 实现主要逻辑
pass
# 1.获取语言类型
# 1.1 准备post的url地址,post_data
# 1.2 发送post的数据,获取响应
# 1.3 提取语言类型
# 2.准备post的数据
# 3.发送请求,获取响应
# 4.提取翻译的结果
if __name__ == "__main__":
baidu_fanyi = BaiduFanyi()
baidu_fanyi.run()
我们需要花很长时间想好主要逻辑,然后打上草稿,之后我们就可以一一详细化,完成最终的代码。
import requests
import json
class BaiduFanyi:
def __init__(self, trans_str): # 1.1 准备post的url地址,post_data
self.trans_str = trans_str
self.lang_detect_url = "https://fanyi.baidu.com/langdetect"
self.headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) CriOS/56.0.2924.75 Mobile/14E5239e Safari/602.1"
}
self.trans_url = "https://fanyi.baidu.com/basetrans"
def parse_url(self, url, data): # 1.2 发送post的数据,获取响应
response = requests.post(url, data=data, headers=self.headers)
return json.loads(response.content.decode())
def get_ret(self, dict_respsonse): # 4.提取翻译的结果
ret = dict_respsonse["trans"][0]["dst"]
print("翻译的结果是:", ret)
def run(self): # 实现主要逻辑
# 1.获取语言类型
# 1.1 准备post的url地址,post_data
lang_detect_data = {"query": self.trans_str}
# 1.2 发送post的数据,获取响应
lang = self.parse_url(self.lang_detect_url, lang_detect_data)["lan"]
# 1.3 提取语言类型
# 在网页源码中查看langdetect的response数据,在1.2末尾处加上一个“lan”
# 2.准备post的数据
trans_data = {"query": self.trans_str, "from": "zh", "to": "en"} if lang == "zh" else
{"query": self.trans_str, "from": "en", "to": "zh"}
# 3.发送请求,获取响应
dict_respsonse = self.parse_url(self.trans_url, trans_data)
# 4.提取翻译的结果
self.get_ret(dict_respsonse)
if __name__ == "__main__":
baidu_fanyi = BaiduFanyi("大家好哦")
baidu_fanyi.run()
输出结果:
翻译的结果是: Hello everyone!
这段代码对比之前的代码,得到的优化有:
①可以指定翻译的初始语言和目标语言。
②实现的翻译功能更加迅速。