简单线性:用一个量化验的解释变量预测一个量化的响应变量
多项式:用一个量化的解决变量预测一个量化的响应变量,模型的关系是n阶多项式
多元线性:用两个或多个量化的解释变量预测一个量化的响应变量
多变量:用一个或多个解释变量预测多个响应变量
Logistic:用一个或多个解释变量预测一个类别型响应变量
泊松:用一个或多个解释变量预测一个代表频数的响应变量
Cox比例风险:用一个或多个解释变量预测一个事件发生的时间
时间序列:对误差项相关的时间序列数据建模
非线性:用一个或多个量化的解释变量预测一个量化的响应变量,不过模型是非线性的
非参数:用一个或多个量化的解释变量预测一个量化的响应变量,模型的形式源自数据形式,不事先设定
稳健:用一个或多个量化的解释变量预测一个量化的响应变量,能抵御强影响点的干扰
8.1.1
OLS回归:普通最小二乘回归法:包括简单线性,多项式回归和多元线性回归。
OLS回归是通过预测变量的加权和来预测量化的因变量,其中权重是通过数据估计而得的参数。
例:一个工程师想找到跟桥梁退化有关的最重要的因素,比如使用年限,交通流量,桥梁设计,建造材料和建造方法,建造质量以及天气情况,并确定它们之间的数学关系。他拟合了一系列模型,检验它们是否符合相应的统计假设,探索了所有异常的发现,最终从许多可能的模型中选择了最佳的模型,如果成功,那么结果将会帮助他完成以下任务。
1.在众多变量中判断哪些对预测桥梁退化是有用的,得到它们的相对重要性,从而关注重要的变量。
2.根据回归所得的等式预测新的桥梁的退化情况,找出那些可能会有麻烦的桥梁
3.利用对异常桥梁的分析,获得一些意外的信息。比如他发现某些桥梁的退化速度比预测的更快或更慢,那么研究这些“离群点”可能会有重大的发现,能够帮助理解桥梁退化的机制。
OLS回归拟合模型的形式:
Y=B0+B1X1+B2X2+...+BnXn
目标是通过减少响应变量的真实值与预测值的差值来获得模型参数,使得残差平方和最小。
为了能够恰当解释OLS模型的系数,数据必须满足以下统计假设:
1.正态性:对于固定的自变量值,因变量值成正态分布。
2.独立性:Y值之间相互独立
3.线性:因变量与自变量成线性关系
4.同方差性:因变量的方差不随自变量的水平不同而变化,也可称为不变方差,但是说同方差性感觉上更犀利。
如果违背以上假设,你的统计显著性检验结果和所得的置信区间很可能就不精确。
8.2.1 用lm拟合回归模型
summary:
coefficients:列出拟合模型的模型参数(截距和斜率)
confint:提供模型参数的置信区间
fitted:列出拟合模型的预测值
residuals:列出拟合模型的残差值
anova:生成一个拟合模型的方差分析表,或者比较两个或更多拟合模型的方差分析表
vcov:列出模型参数的协方差矩阵
AIC:输出AIC统计量
plot:
predict:
简单线性回归:一个因变量和一个自变量
多项式回归:一个预测变量,同时包含变量的幂
多元线性回归:不止一个预测变量
8.2.2 线性回归
fit <- lm(weight ~ height, data = women)
summary(fit)
fitted(fit) #列出预测值
residuals(fit) #列出残差
plot(women$height, women$weight, main = "Women Age 30-39", xlab = "Height (in inches)", ylab = "Weight (in pounds)")
abline(fit)
8.2.3 多项式回归
线性回归的图表明,可以通过添加一个二次项X平方来提高回归的预测精度
fit2 <- lm(weight ~ height + I(height^2), data = women)
summary(fit2)
plot(women$height, women$weight, main = "Women Age 30-39", xlab = "Height (in inches)", ylab = "Weight (in lbs)")
lines(women$height, fitted(fit2))
library(car)
scatterplot(weight ~ height, data = women, spread = FALSE, lty.smooth = 2, pch = 19, main = "Women Age 30-39", xlab = "Height (inches)", ylab = "Weight (lbs.)")
8.2.4 多元线性回归
states <- as.data.frame(state.x77[, c("Murder", "Population", "Illiteracy", "Income", "Frost")])
cor(states)
library(car)
scatterplotMatrix(states, spread = FALSE, lty.smooth = 2, main = "Scatterplot Matrix")
8.2.5 有交互项的多远线性回归
#ht和wt
fit <- lm(mpg ~ hp + wt + hp:wt, data = mtcars)
summary(fit)
8.3 回归诊断
8.3.1 标准方法
fit <- lm(weight ~ height, data = women)
par(mfrow = c(2, 2))
plot(fit)
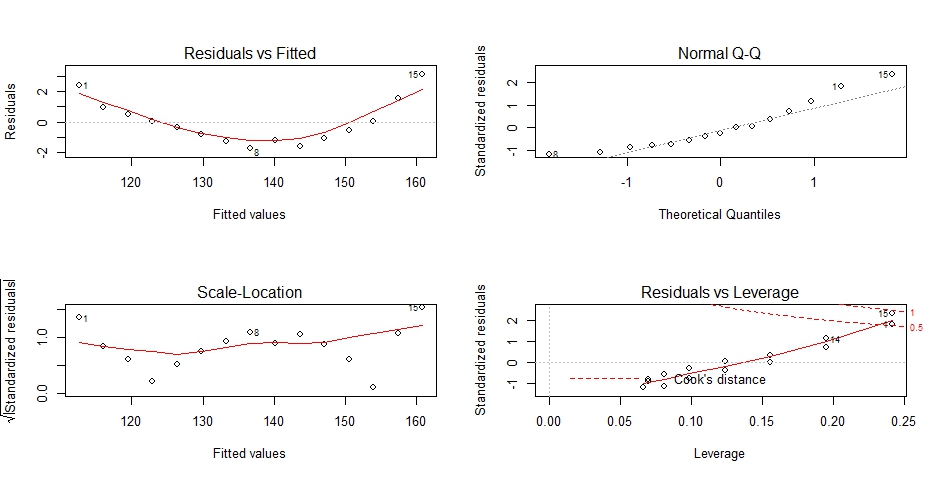
OLS的回归统计假设,
1.正态性:当预测变量值固定时,因变量成正态分布,则残差值也应该是一个均值为0的正态分布,上图的右上角。
2.独立性:满足
3.线性:若因变量与自变量线性相关,那么残差值与预测(拟合)值就没有任何系统关联。在“残差图与拟合图”(左上)可以清楚地看到一个曲线关系,这说明你可能需要对回归模型加上一个二次项。
4.同方差性:若满足不变方差假设,那么在位置尺度图(左下)中,水平线周围的点应该随机分布。该图满足此假设。
最后一幅图提供了可能关注的单个观测点的信息。从图形可以鉴别出离群点,高杠杆值点和强影响点。
1.一个观测点是离群点,表明拟合回归模型对其预测效果不佳(产生巨大的或正或负的残差)
2.一个观测点有很高的杠杆值,表明它是一个异常的预测变量值的组合。也就是说,在预测变量空间中,它是一个离群点。因变量值不参与计算一个观测点的杠杆值。
3.一个观测点是强影响点,表明它对模型参数的估计产生的影响过大,非常不成比例。强影响点可以通过Cook距离即Cook's D统计量来鉴别。
以下对模型加了一个平方项
newfit <- lm(weight ~ height + I(height^2), data = women)
par(mfrow = c(2, 2))
plot(newfit)

与上图的差别,左上图应该没有任何关联,右上图应该尽可能落在45度角的直线上。左下图随机分布,右下识别离群点强影响点。从左上和右上图看效果比较好。
删除离群点
newfit <- lm(weight ~ height + I(height^2), data = women[-c(13, 15),])
par(mfrow = c(2, 2))
plot(newfit)

换个例子
fit <- lm(Murder ~ Population + Illiteracy + Income + Frost, data = states)
par(mfrow = c(2, 2))
plot(fit)

8.3.2 改进的方法
library(car)
fit <- lm(Murder ~ Population + Illiteracy + Income + Frost, data = states)
qqPlot(fit, labels = FALSE, simulate = TRUE, main = "Q-Q Plot")
如下图,右上角那个点在置信区间之外,表明模型低估了该州的谋杀率

residplot <- function(fit, nbreaks=10) {
z <- rstudent(fit)
hist(z, breaks=nbreaks, freq=FALSE,xlab="Studentized Residual",main="Distribution of Errors")
rug(jitter(z), col="brown")
curve(dnorm(x, mean=mean(z), sd=sd(z)),
add=TRUE, col="blue", lwd=2)
lines(density(z)$x, density(z)$y,
col="red", lwd=2, lty=2)
legend("topright",
legend = c( "Normal Curve", "Kernel Density Curve"),lty=1:2, col=c("blue","red"), cex=.7)
}
residplot(fit)

2.误差的独立性
durbinWatsonTest(fit)
#lag Autocorrelation D-W Statistic p-value
#1 -0.2006929 2.317691 0.248
#Alternative hypothesis: rho != 0
p值0.282表明无自相关性,误差项之间独立,lag为1表明数据集中每个数据都是与其后一个数据进行比较的。该检验适用于时间独立的数据,对于非聚集型数据并不适用。
3.线性
crPlots(fit, one.page = TRUE, ask = FALSE)
若图形存在非线性,说明需要添加一些曲线成分,比如多项式项,或对一个或多个变量进行变换。

4.同方差性
library(car)
ncvTest(fit)
spreadLevelPlot(fit)
应该呈随机分布,满足方差不变假设,若不满足,会看到一个非水平的曲线。

8.3.3 线性模型假设的综合验证
library(gvlma)
gvmodel <- gvlma(fit)
summary(gvmodel)
#Value p-value Decision
#Global Stat 2.7728 0.5965 Assumptions acceptable.
#Skewness 1.5374 0.2150 Assumptions acceptable.
#Kurtosis 0.6376 0.4246 Assumptions acceptable.
#Link Function 0.1154 0.7341 Assumptions acceptable.
#Heteroscedasticity 0.4824 0.4873 Assumptions acceptable.
8.3.4 多重共线性
vif(fit)
sqrt(vif(fit)) > 2 #>2说明有多重共线性
Population Illiteracy Income Frost
FALSE FALSE FALSE FALSE
8.4 异常观测值
8.4.1 离群点
library(car)
outlierTest(fit)
8.4.2 高杠杆值点
hat.plot <- function(fit){
p <- length(coefficients(fit))
n <- length(fitted(fit))
plot(hatvalues(fit), main = "Index Plot of Hat Values")
abline(h = c(2, 3) * p/n, col = "red", lty = 2)
identify(1:n, hatvalues(fit), names(hatvalues(fit)))
}
hat.plot(fit)

8.4.3 强影响点
cutoff <- 4/(nrow(states) - length(fit$coefficients) - 2)
plot(fit, which = 4, cook.levels = cutoff)
abline(h = cutoff, lty = 2, col = "red")

avPlots(fit, ask = FALSE, onepage = TRUE, id.method = "identify")
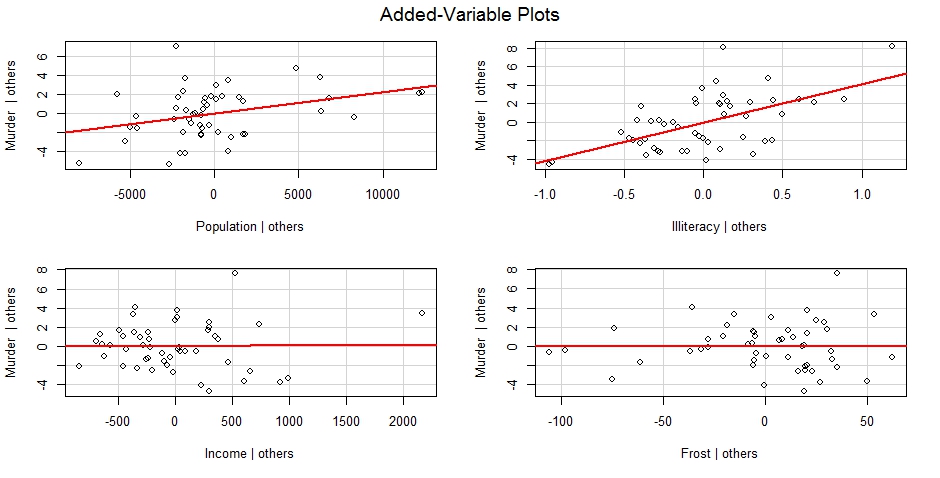
influencePlot(fit, id.method = "identify", main = "Influence Plot", sub = "Circle size is proportial to Cook's Distance")

8.5 改进措施
8.5.1 删除观测点
8.5.2 变量变换
library(car)
summary(powerTransform(states$Murder))
结果如下,0.6055说明应该用Murder的0.6次方来代替,可以使用0.5次方即平方根,但lambda=1的P值无法拒绝原假设,因此需要变量变换
bcPower Transformation to Normality
Est.Power Std.Err. Wald Lower Bound Wald Upper Bound
states$Murder 0.6055 0.2639 0.0884 1.1227
Likelihood ratio tests about transformation parameters
LRT df pval
LR test, lambda = (0) 5.665991 1 0.01729694
LR test, lambda = (1) 2.122763 1 0.14512456
library(car)
boxTidwell(Murder ~ Population + Illiteracy, data = states)
结果如下:表明应该是Population的0.87次方,Illiteracy的1.36次方,但是P值>0.05又表明不需要变换
Score Statistic p-value MLE of lambda
Population -0.3228003 0.7468465 0.8693882
Illiteracy 0.6193814 0.5356651 1.3581188
iterations = 19
8.5.3 增删变量
如果只是做预测,那么多重共线性不是问题,但是如果还要做解释,那么就必须解决问题。
8.6 选择“最佳”的回归模型
8.6.1 模型比较
fit1 <- lm(Murder ~ Population + Illiteracy + Income + Frost, data = states)
fit2 <- lm(Murder ~ Population + Illiteracy, data = states)
anova(fit2, fit1)
结果如下:p值>0.05说明不需要将这两个变量添加到线性模型中,可以删除
Model 1: Murder ~ Population + Illiteracy
Model 2: Murder ~ Population + Illiteracy + Income + Frost
Res.Df RSS Df Sum of Sq F Pr(>F)
1 47 289.25
2 45 289.17 2 0.078505 0.0061 0.9939
fit1 <- lm(Murder ~ Population + Illiteracy + Income + Frost, data = states)
fit2 <- lm(Murder ~ Population + Illiteracy, data = states)
AIC(fit1, fit2)
结果如下:AIC值越小的模型要优先选择,所以选模型2
df AIC
fit1 6 241.6429
fit2 4 237.6565
8.6.2 变量选择
1.逐步回归
library(MASS)
fit1 <- lm(Murder ~ Population + Illiteracy + Income + Frost, data = states)
stepAIC(fit, direction = "backward")
2.全子集回归
library(leaps)
leaps <- regsubsets(Murder ~ Population + Illiteracy + Income + Frost, data = states, nbest = 4)
plot(leaps, scale = "adjr2")

library(car)
subsets(leaps, statistic = "cp", main = "Cp Plot for All Subsets Regression")
abline(1, 1, lty = 2, col = "red")
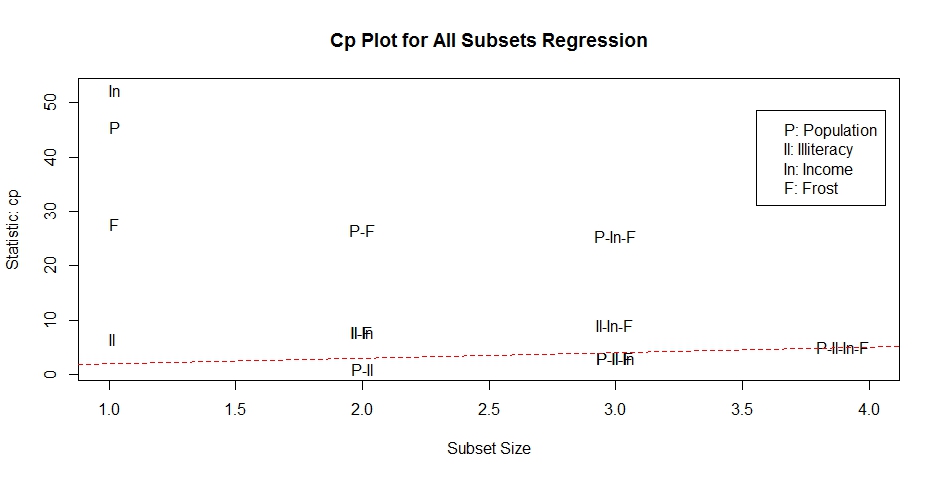
8.7 深层次分析
8.7.1 交叉验证:在k重交叉验证中,样本被分成k个子样本,轮流将k-1个子样本组合作为训练集,另外1个子样本作为测试集。记录k个结果,求平均值。
shrinkage <- function(fit, k = 10) {
require(bootstrap)
# define functions
theta.fit <- function(x, y) {
lsfit(x, y)
}
theta.predict <- function(fit, x) {
cbind(1, x) %*% fit$coef
}
# matrix of predictors
x <- fit$model[, 2:ncol(fit$model)]
# vector of predicted values
y <- fit$model[, 1]
results <- crossval(x, y, theta.fit, theta.predict, ngroup = k)
r2 <- cor(y, fit$fitted.values)^2
r2cv <- cor(y, results$cv.fit)^2
cat("Original R-square =", r2, "
")
cat(k, "Fold Cross-Validated R-square =", r2cv, "
")
cat("Change =", r2 - r2cv, "
")
}
# using shrinkage()
fit <- lm(Murder ~ Population + Income + Illiteracy + Frost, data = states)
shrinkage(fit)
#Loading required package: bootstrap
#Original R-square = 0.5669502 初始结果
#10 Fold Cross-Validated R-square = 0.4562456 交叉验证结果
#Change = 0.1107046
fit2 <- lm(Murder ~ Population + Illiteracy, data = states)
shrinkage(fit2)
#Original R-square = 0.5668327
#10 Fold Cross-Validated R-square = 0.5171145
#Change = 0.0497182 比全变量减少的R平方,说明这个比较好
8.7.2相对重要性
zstates <- as.data.frame(scale(states))
zfit <- lm(Murder ~ Population + Income + Illiteracy + Frost, data = zstates)
coef(zfit)
(Intercept) Population Income Illiteracy Frost
-9.405788e-17 2.705095e-01 1.072372e-02 6.840496e-01 8.185407e-03
relweights <- function(fit, ...) {
R <- cor(fit$model)
nvar <- ncol(R)
rxx <- R[2:nvar, 2:nvar]
rxy <- R[2:nvar, 1]
svd <- eigen(rxx)
evec <- svd$vectors
ev <- svd$values
delta <- diag(sqrt(ev))
# correlations between original predictors and new orthogonal variables
lambda <- evec %*% delta %*% t(evec)
lambdasq <- lambda^2
# regression coefficients of Y on orthogonal variables
beta <- solve(lambda) %*% rxy
rsquare <- colSums(beta^2)
rawwgt <- lambdasq %*% beta^2
import <- (rawwgt/rsquare) * 100
lbls <- names(fit$model[2:nvar])
rownames(import) <- lbls
colnames(import) <- "Weights"
# plot results
barplot(t(import), names.arg = lbls, ylab = "% of R-Square",
xlab = "Predictor Variables", main = "Relative Importance of Predictor Variables",
sub = paste("R-Square = ", round(rsquare, digits = 3)),
...)
return(import)
}
# using relweights()
fit <- lm(Murder ~ Population + Illiteracy + Income +
Frost, data = states)
relweights(fit, col = "lightgrey")
