本章是特意为 Python 新手准备的。通过对本章的学习,读者可以快速掌握 Python 的基础语法,这是编写自动化测试必须要掌握的。
3.1 Python 哲学
在具体学习 Python 之前,我们先来看一些有趣的东西。在 Python IDLE 的 Shell 模式下输入「import this」,将会看到如图 3-1 所示的一段话。
图 3-1 Python 之禅(The Zen of Python)
Beautiful is better than ugly.优美胜于丑陋。
Explicit is better than implicit.明了胜于晦涩。
Simple is better than complex.简单胜过复杂。
Complex is better than complicated.复杂胜过凌乱。
Flat is better than nested.扁平胜于嵌套。
Sparse is better than dense.间隔胜于紧凑。
Readability counts.可读性很重要。
Special cases aren't special enough to break the rules.即使假借特例的实用性之名,也不能违背这些原则。
Although practicality beats purity.虽然实用性次于纯度。
Errors should never pass silently.错误不应该被无声地忽略。
Unless explicitly silenced.除非明确的沉默。
In the face of ambiguity,refuse the temptation to guess.当存在多种可能时,不要尝试去猜测。
There should be one-and preferably only one-obvious way to do it.应该有一个,最好只有一个,很明显可以做到这一点。
Although that way may not be obvious at first unless you're Dutch.虽然这种方式可能不容易,除非你是 Python 之父。
Now is better than never.现在做总比不做好。
Although never is often better than*right*now.虽然过去从未比现在好。
If the implementation is hard to explain,it's a bad idea.如果这个实现不容易解释,那么它肯定是个坏主意。
If the implementation is easy to explain,it may be a good idea.如果这个实现容易解释,那么它很可能是个好主意。
Namespaces are one honking great idea-let's do more of those!命名空间是一种绝妙的理念,应当多加利用!
这就是 Python 之禅,也可以看作 Python 设计哲学。在接下来的 Python 学习中可体会到这种设计哲学。
3.2 输出
一般编程语言的教程都是从打印「Hello World!」开始的,我们这里也不免俗,下面就从打印「Hello Python」开始。
3.2.1 打印
Python 提供了 print()方法来打印信息,在 PyCharm 中输入以下信息。


可打印出「hello Python」字符串。但是,有时候我们打印的信息并不是固定的,下面来看如何格式化输出。

这里分别定义了 name 和 age 变量,并用三种方式实行格式化输出。
第一种通过连接符(+)进行拼接。注意,age 是整型,所以需要通过 str()方法将整型转换成字符串。
第二种通过格式符(%s、%d)进行替换,其中,%s 用于指定字符串,%d(digit)用于指定数字。如果不确定待打印的数据的类型,则可以用%r 表示。
第三种通过格式化函数 format()进行格式化。这种方式是大多数程序员推荐的。如果不指定位置,就按照默认顺序。当然,也可以通过{0}、{1}指定位置,或者用变量指定对应关系,示例如下。

3.2.2 引号与注释
在 Python 中是不区分单引号('')与双引号(')的。也就是说,单引号和双引号都可以用来表示一个字符串。

单引号与双引号可以互相嵌套使用,但不能交叉使用。

再来看看注释,基本上每种语言都会提供单行注释和多行注释。Python 的单行注释用井号(#)表示。创建一个 2_annotation.py 文件。
单行注释一般写在代码的前一行或代码末尾。
多行注释用三引号表示,同样不区分单、双引号。
# 单行注释 print("hell world") # 打印hello world """ 功能:自动化测试 作者:kangmf 日期:2020-09-06 """ ''' This is a Multi line comment '''
3.3 分支与循环
结构化程序实际上是由顺序、分支和循环三种基本结构组成的。
3.3.1 if 语句
和大多数语言一样,Python 通过 if 语句实现分支判断,一般语法为 if…else。创建 3_if.py 文件。
a = 2 b = 3 if a > b: print("a max!") else: print("b max!")
上面的语句分别对 a 和 b 赋值,通过 if 语句判断 a 和 b 的大小。如果 a 大于 b,则输出「a max!」,否则输出「b max!」。
需要强调的是,Python 没有像其他大多数语言一样使用「{}」表示语句体,而是通过语句的缩进来判断语句体,缩进默认为 4 个空格。
if 语句通过「==」运算符判断相等,通过「!=」运算符判断不相等。
if 2+2 == 4: print("true") else: print("false")
除此之外,if 语句还可以用「in」和「not in」判断字符串是否包含。
s = "hello" ss = "hello world" if s in ss: print("Contain") else: print("Not Contain")
if 语句还可以进行布尔(True/False)类型的判断。
if True: print("true") else: print("false")
下面通过一个多重条件判断来结束 if 语句的学习。
# 成绩 result = 72 if result >= 90: print('优秀') elif result >= 70: print('良好') elif result >= 60: print('及格') else: print('不及格')
根据结果划分为四个级别,分别为「优秀」、「良好」、「及格」和「不及格」。72 分属于哪个级别呢,运行一下上面的代码吧!
3.3.2 for 语句
Python 同样提供了 while 循环,但从大多数程序员的习惯来看,它的使用频率远不及 for 循环,所以这里重点介绍 for 循环的使用。Python 中 for 循环的使用更加简单灵活。例如,我们可以直接对一个字符串进行循环遍历。

运行程序,结果如下。

当然,也可以对一个列表(稍后学习 Python 中的列表)进行循环遍历。
# 循环遍历列表 fruits = ['banana', 'apple', 'mango'] for fruit in fruits: print(fruit)
如果需要进行一定次数的循环,则需要借助 range()函数。
# 循环遍历5次 for i in range(5): print(i)
输出结果为:0~4。range()函数默认从 0 开始循环,我们也可以为其设置起始位置和步长。例如,打印 1 到 10 之间的奇数。
# 打印1~10之间的奇数 for i in range(1, 10, 2): print(i)
在 range()函数中,start 表示起始位置,end 表示结束位置,step 表示每次循环的步长。运行上面的程序,输出结果为「1 3 5 7 9」。
3.4 列表、元组与字典
列表、元组与字典是最常见的用于存放数据的形式,在 Python 中,它们的用法非常灵活。
3.4.1 列表
列表(即 list,也可以称为「数组」)用方括号([])表示,里面的每个元素用逗号(,)隔开。
""" 列表(list)基本用法 """ # 定义列表 lists = [1, 2, 3, 'a', 5] # 打印列表 print(lists) # 打印列表中的第1个元素 print(lists[0]) # 打印列表中的第5个元素 print(lists[4]) # 打印列表中的最后一个元素 print(lists[-1]) # 修改列表中的第5个元素为“b” lists[4] = 'b' print(lists) # 向列表末尾添加元素 lists.append('c') print(lists) # 删除列表中的第一个元素 lists.pop(0) print(lists)
Python 允许在一个列表里面任意地放置数字或字符串。列表的下标是从 0 开始的,所以,lists[0]会输出列表中的第一个元素。append()方法可以向列表末尾追加新的元素,pop()方法用于删除指定位置的元素。
3.4.2 元组
Python 的元组与列表类似,元组使用小括号(())表示。
4_tuple.py
""" 元组基本使用 """ # 定义元组 tup1 = ('a', 'b', 3, 4) tup2 = (1, 2, 3) # 查看元组 print(tup1[0]) print(tup2[0:2]) # 连接元组 tup3 = tup1 + tup2 print(tup3) # 元组复制 tup4 = ("Hi!") print(tup4 * 3)
那么元组与列表有什么区别呢?唯一的区别是:列表是可变的,即可以追加、修改或删除其中的元素,而元组是不可变的。下面通过例子演示两者的区别。

元组并不提供 append()方法来追加元素,所以,当不确定元素个数时建议使用列表,当提前知道元素数量时使用元组,因为元素的位置很重要。
3.4.3 字典
字典用花括号({})表示,每个元素由一个 key 和一个 value 组成,key 与 value 之间用冒号(:)分隔,不同的元素之间用逗号(,)分隔。
4_dict.py
# 定义字典 dicts = {"username":"zhangsan",'password':123456} # 打印字典中的所有key print(dicts.keys()) # 打印字典中的所有value print(dicts.values()) # 向字典中添加键/值对 dicts["age"] = 22 # 循环打印字典key 和value for k, v in dicts.items(): print("dicts keys is %r " %k) print("dicts values is %r " %v) # 删除键是'password'的项 dicts.pop('password') # 打印字典以列表方法返回 print(dicts.items())
注意:Python 规定一个字典中的 key 必须是独一无二的,value 可以相同。
keys()方法返回字典 key 的列表,values()方法返回字典 value 的列表,items()方法将所有的字典元素以列表形式返回,这些列表中的每一项都包含 key 和 value。pop()方法通过指定 key 来删除字典中的某元素。
3.5 函数、类和方法
如果想编写更复杂的程序,就必须学会函数、类和方法。
3.5.1 函数
在 Python 中用 def 关键字来定义函数。

创建一个 add()函数,此函数接收 a、b 两个参数,通过 print()打印 a+b 的结果。下面调用 add()函数,并且传 3 和 5 两个参数给 add()函数。

通常 add()函数不会直接打印结果,而是将结果通过 return 关键字返回。所以,需要使用变量 c 接收 add()函数的返回值,并通过 print()方法打印。
如果不想调用 add()函数为其传参数,那么也可以为 add()函数设置默认参数。

如果调用时不传参数,那么 add()函数会使用默认参数进行计算,否则计算参数的值。
3.5.2 类和方法
在面向对象编程的世界里,一切皆为对象,抽象的一组对象就是类。例如,汽车是一个类,而张三家的奇瑞汽车就是一个具体的对象。
在 Python 中,用 class 关键字创建类。
""" 类、方法的使用 """ # 定义MyClass类 class MyClass(object): def say_hello(self, name): return "hello, " + name # 调用MyClass类 mc = MyClass() print(mc.say_hello("tom"))
上面创建了一个 MyClass 类(在 Python 3 中,object 为所有类的基类,所有类在创建时默认继承 object,所以不声明继承 object 也可以),在类下面创建一个 add()方法。方法的创建同样使用 def 关键字,与函数的唯一区别是,方法的第一个参数必须声明,一般习惯命名为「self」,但在调用这个方法时并不需要为该参数设置数值。
一般在创建类时会先声明初始化方法__init__()。
注意:init 的两侧是双下画线,当我们调用该类时,可以用来进行一些初始化工作。
class A: def __init__(self, a, b): self.a = int(a) self.b = int(b) def add(self): return self.a + self.b # 调用类时需要传入初始化参数 count = A('4', 5) print(count.add())
当我们调用 A 类时,会执行它的__init__()方法,所以需要给它传参数。初始化方法将输入的参数类型转化为整型,这样可以在一定程度上保证程序的容错性。而 add()方法可以直接拿初始化方法__init__()的 self.a 和 self.b 两个数进行计算。所以,我们在调用 A 类下面的 add()方法时,不需要再传参数。
继续创建 B 类,并继承 A 类。
class A: def __init__(self, a, b): self.a = int(a) self.b = int(b) def add(self): return self.a + self.b # B类继承A类 class B(A): def sub(self, a, b): return a - b # 调用类时需要传入初始化参数 count = A('4', 5) print(count.add()) print(B(2, 3).add())
在 B 类中实现 sub()方法。因为 B 类继承 A 类,所以 B 类自然也拥有 add()方法,从而可以直接通过 B 类调用 add()方法。
3.6 类库
python的类库,一般也被称为模块、模组。在实际开发中,我们不可避免地会用到 Python 的标准模块和第三方库。如果要实现与时间有关的功能,就需要调用 Python 标准模块 time。如果要实现 Web 自动化测试,就需要调用 Python 第三方库 Selenium。
3.6.1 调用模块
通过 import 关键字调用 time 模块。
# 导入time模块 import time print(time.ctime())
time 模块下的 ctime()函数用于获得当前时间,格式为 Thu Mar 15 15:52:31 2018。
当然,如果确定只会用到 time 模块下面的 ctime()函数,那么也可以用 from import 直接导入 ctime()函数。
# 直接导入ctime()方法 from time import ctime print(ctime())
这里不必告诉 Python,ctime()函数是 time 模块提供的。有时候我们可能还会用到 time 模块下面的其他函数,如 time()函数、sleep()函数等,可以用下面的方法导入多个函数。
# 直接导入模块下的多个方法 from time import time, sleep
假设我们会用到 time 模块下面的所有函数,但又不想在使用过程中为每个函数加 time.前缀,那么可以使用星号(*)一次性把 time 模块下面的所有函数都导入进来。
# 导入time模块下的所有方法 from time import * print(ctime()) print("休眠两秒") sleep(2) print(ctime())
星号「*」用于表示模块下面的所有函数,但并不推荐这样做。
如果导入的函数刚好与自己定义的函数重名,那么可以用「as」对导入的函数重命名。
# 对导入的sleep模块重命名 from time import sleep as sys_sleep def sleep(sec): print("this is I defined sleep() ") print(sleep(1))
这里将 time 模块下面的 sleep()函数重命名为 sys_sleep,用于区别当前文件中定义的 sleep()函数。
你可能会好奇,time 模块到底在哪儿?为什么 import 进来就可以用了?这是 Python 提供的核心方法,而且经过了编译,所以我们无法看到 ctime()函数是如何获取系统当前时间的。不过,我们可以通过 help()方法查看 time 模块的帮助说明。
import time help(time)
Python 安装的第三方库或框架默认存放在..Python37Libsite-packages目录下面,如果你已经学习了第 2 章并安装了 Selenium,那么可以在该目录下找到 Selenium 目录。调用第三方库的方式与调用 Python 自带模块的方式一致。
3.6.2 自定义模块
除可调用 Python 自带模块和第三方库外,我们还可以自己创建一些模块。对于一个软件项目来说,不可能把所有代码都放在一个文件中实现,一般会根据功能划分为不同的模块,存放在不同的目录和文件中。
下面创建一个目录 project1,并在目录下创建两个文件,结构如下:

在 calculator.py 文件中创建 add()函数。

在相同的目录下再创建一个文件 test.py,导入 calculator.py 文件中的 add()函数。

这样就实现了跨文件的函数导入。
知识延伸:如果你细心,一定会发现在运行 test.py 程序之后,project 目录下多了一个__pycache__/calculator.cpython-37.pyc 文件,它的作用是什么呢?
为了提高模块加载速度,每个模块都会在__pycache__文件夹中放置该模块的预编译模块,命名为 module.version.pyc。version 是模块的预编译版本编码,通常会包含 Python 的版本号。例如,在 CPython 发行版 3.7 中,calculator.py 文件的预编译文件是:__pycache__/calculator.cpython-37.pyc
3.6.3 跨目录调用文件
如果调用文件与被调用文件在同一个目录下,则可以非常方便地调用。如果调用文件与被调用文件不在同一个目录下,那么应怎样调用呢?假设文件目录结构如下:

test.py 文件要想调用 calculator.py 文件就比较麻烦了。我们先来弄明白另一个问题:Python 是如何查找 import 模块的。
先在 test.py 文件中编写如下代码并执行。
import sys print(sys.path)
打印结果如下:

当我们调用(import)一个文件时,如调用 calculator.py 文件,Python 将按照这个列表,由上到下依次在这些目录中查找名为 calculator 的目录或文件。显然这个列表中并没有 calculator.py 文件。
所以,自然无法调用 calculator 文件。
calculator.py 文件的绝对路径是:

明白了这一点,跨目录调用文件的问题就很好解决了,我们只需将 calculator.py 文件所属的目录添加到系统的 Path 中即可。
# import sys # sys.path.append("D:\git\book-code\python_base\project2\module") # from calculator import add # print(add(2, 3))
这样,问题就解决了。但是,当代码中出现 D:\git\book-code\python_base\project2\module 这样的绝对路径时,项目的可移植性就会变得很差,因为你写的代码需要提交到 Git,其他开发人员需要拉取这些代码并执行,你不能要求所有开发人员的项目路径都和你保持一致。所以,我们应该避免在项目中写绝对路径(硬编码)。
进一步优化上面的代码如下。
import sys from os.path import dirname, abspath project_path = dirname(dirname(abspath(__file__))) sys.path.append(project_path + "\module") from calculator import add print(add(2, 3))
__file__用于获取文件所在的路径,调用 os.path 下面的 abspath(__file__) 可以得到文件的绝对路径:

dirname()函数用于获取上级目录,所以当两个 dirname()函数嵌套使用时,得到的目录如下:

将该路径与「\module」目录拼接,可得到 calculator.py 文件的所属目录,添加到 Path 即可。这样做的好处是,只要 project2 项目中的目录结构不变,在任何环境下都可以正常执行。
3.7 异常
Python 用异常对象(Exception Object)来表示异常情况。在遇到错误后,异常对象会引发异常。如果异常对象并未被处理或捕捉到,则程序会用回溯(Traceback,一种错误信息)来终止程序。
3.7.1 认识异常
下面来看程序在执行时所抛出的异常。

首先,我们通过 open()方法以读「r」的方式打开一个 abc.txt 文件。然后,Python 抛出一个 FileNotFoundError 类型的异常,它告诉我们:
No such file or directory:“abc.txt”(没有 abc.txt 这样的文件或目录)
当然找不到了,因为我们根本就没有创建这个文件。
既然知道当打开一个不存在的文件时会抛出 FileNotFoundError 异常,那么我们就可以通过 Python 提供的 try except 语句来捕捉并处理这个异常。创建 abnormal.py 文件,代码如下。
try: open("abc.txt", 'r') except FileNotFoundError: print("异常了!")
再来运行程序,因为已经用 try except 捕捉到 FileNotFoundError 异常,所以「异常了!」会被打印出来。修改程序,使其打印一个没有定义的变量a。
try: print(a) except FileNotFoundError: print("异常了!")
这次依然会抛出异常信息。

不是已经通过 try except 去接收异常了吗,为什么又报错了?细心查看错误信息就会发现,这一次抛出的是 NameError 类型的错误,而 FileNotFoundError 只能接收找不到文件的错误。这就好像在冬天洗冷水澡,本应准备感冒药,但准备的是治疗胃痛的药,显然是没有帮助的。
这里我们只需将捕捉异常类型修改为 NameError 即可。
知识延伸:异常的抛出机制?
1.如果在运行时发生异常,那么解释器会查找相应的处理语句(称为 handler)。
2.如果在当前函数里没有找到相应的处理语句,那么解释器会将异常传递给上层的调用函数,看看那里能不能处理。
3.如果在最外层函数(全局函数 main())也没有找到,那么解释器会退出,同时打印 Traceback,以便让用户找到错误产生的原因。
注意:虽然大多数错误会导致异常,但异常不一定代表错误,有时候它们只是一个警告,有时候是一个终止信号,如退出循环等。
在 Python 中,所有的异常类都继承自 Exception。但自 Python 2.5 版本之后,所有的异常类都有了新的基类 BaseException。Exception 同样也继承自 BaseException,所以我们可以使用 BaseException 来接收所有类型的异常。
try: open("abc.txt", 'r') print(a) except BaseException: print("异常了!")
对于上面的例子,只要其中一行出现异常,BaseException 就能捕捉到并打印「异常了!」。但是我们并不知道具体哪一行代码引起了异常,如何让 Python 直接告诉我们异常的原因呢?
try: open("abc.txt", 'r') print(a) except BaseException as msg: print(msg)
我们在 BaseException 后面定义了 msg 变量来接收异常信息,并通过 print()将其打印出来。运行结果如下。

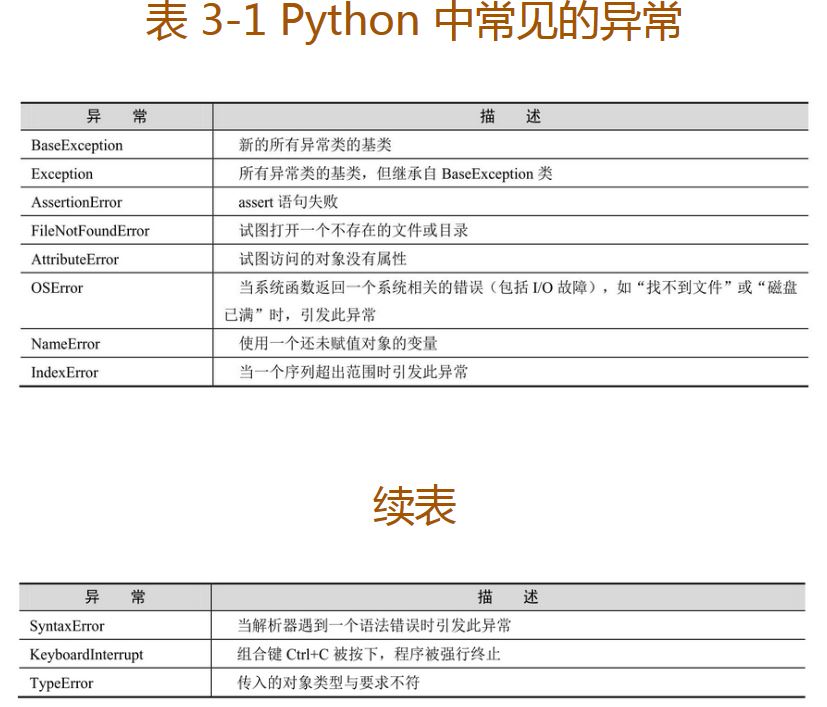
Python 中常见的异常如表 3-1 所示。
表 3-1 Python 中常见的异常
3.7.2 更多异常用法
通过对前面的学习,我们了解了异常的一般用法,下面学习异常的更多用法,如 try except else 用法。
try: a = "异常测试:" print(a) except NameError as msg: print(msg) else: print("没有异常时执行!")
这里我们对变量 a 进行了赋值,如果没有异常,则会执行 else 语句后面的内容。
有时候,我们希望不管是否出现异常,有些操作都会被执行,例如,文件的关闭、锁的释放、把数据库连接返还给连接池等。我们可以使用 try…except…finally 实现这样的需求。
try: print(a) except NameError as msg: print(msg) finally: print("不管是否异常,都会被执行。")
我们给变量 a 赋值后,再次运行上面的代码,验证 finally 语句体是否被执行。
3.7.3 抛出异常
如果你开发的是一个第三方库或框架,那么在程序运行出错时抛出异常会更为专业。在 Python 中,raise 关键字可用来抛出一个异常信息。下面的例子演示了 raise 的用法。
# 定义say_hello()函数 def say_hello(name=None): if name is None: raise NameError('"name" cannot be empty') else: print("hello, %s" %name) # 调用say_hello()函数 say_hello()
首先定义 say_hello()函数,设置参数 name 为 None。在函数中判断参数 name 如果为 None,则抛出 NameError 异常,提示「「name」 cannot be empty」;否则,打印 hello,……。
当我们调用 say_hello()函数不传参数时,结果如下。

需要注意的是,raise 只能使用 Python 提供的异常类,如果想要 raise 使用自定义异常类,则自定义异常类需要继承 Exception 类。
3.8 新手常犯的错误
本章的最后,列举一些 Python 初学者常犯的错误。
(1)Python 没有使用{}来表示语句体,当碰到冒号(:)结尾的语句时,一定要用四个空格或 Tab 键进行缩进。但在一个语句体中不要混合使用四个空格和 Tab 键。
(2)大部分方法两边带的下画线多半是双下画线,如「__init__」,不要写成「_init_」。
(3)项目不要都创建在 Python 的安装目录中,初学者可能会误以为只有把程序建在 Python 的安装目录下才能运行,其实不然,只要正确地把 Python 目录配置到环境变量 Path 下,任何目录下的 Python 程序都可以被执行。
(4)在 Python 程序文件路径中,应尽量避免出现中文或空格。例如,D:自动化测试xx 项目 est case list est.py。这可能会导致有些编辑器无法运行该程序。
(5)创建的目录与文件名不要与引用类库同名。例如,D:seleniumwebdriver.py。在创建目录与文件夹时一定要避免。