转自:https://zhuanlan.zhihu.com/p/35394369
YOLOv3的前世今生
2013年,R-CNN横空出世,目标检测DL世代大幕拉开。
各路豪杰快速迭代,陆续有了SPP,fast,faster版本,至R-FCN,速度与精度齐飞,区域推荐类网络大放异彩。
奈何,未达实时检测之基准,难获工业应用之青睐。
此时,凭速度之长,网格类检测异军突起,先有YOLO,继而SSD,更是摘实时检测之桂冠,与区域推荐类二分天下。然准确率却时遭世人诟病。
遂有JR一鼓作气,并coco,推v2,增加输出类别,成就9000。此后一年,作者隐遁江湖,逍遥twitter。偶获灵感,终推v3,横扫武林!
准确率不再是短板
自从YOLO诞生之日起,它就被贴上了两个标签,
1.速度很快。
2.不擅长检测小物体。
而后者,成为了很多人对它望而却步的原因。
由于原理上的限制,YOLO仅检测最后一层卷积输出层,小物体像素少,经过层层卷积,在这一层上的信息几乎体现不出来,导致难以识别。
YOLOv3在这部分提升明显。先看看小物体的识别。

YOLOv3的识别结果
直观地看下和YOLOv2的对比图如下。可以看出,对于小物体的识别,提高非常明显。

无论是传统的模式识别图像检测,还是基于CNN的视觉检测,对于紧凑密集或者高度重叠目标的检测通常是非常困难的。比如对合影的人群检测在YOLOv2上的结果:

而下面是v3的结果:
前方高能预警。。。。。。。。。。。。。。。。
一次检测到图中90%的人,还增加了tie(领带)这个新类别,非常惊艳!

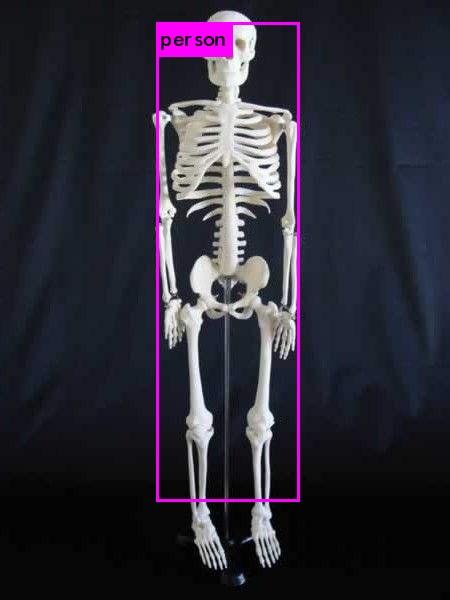
再看看模型的泛化能力如何:
骷髅并不在训练数据集中,但是通过训练模型强大的泛化能力,自动将其归类到了人类。(也算是最为合理的近似处理了)
这在YOLOv2中是检测不到的。
那么,模型泛化能力很强的副作用,就是分类结果跑偏,比如下面这张coser的识别图,最左侧的人识别成了马:

训练和检测都很快
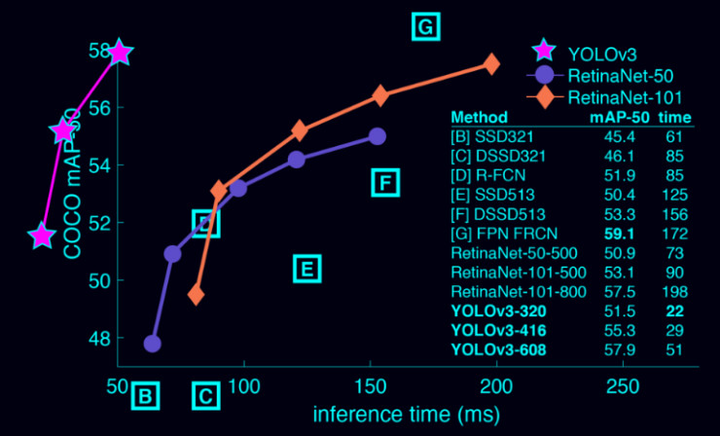
论文中做了详尽的对比。
和前辈们比,YOLO 的速度非常快,比 R-CNN 快 1000 倍,比 Fast R-CNN 快 100 倍。
和同辈们比,YOLOv3-608检测准确率比DSSD更高,接近FPN,但是检测时间却只用了后面两者的三分之一不到。
原因如论文中所说,它在测试时观察整张图像,预测会由图像中的全局上下文(global context)引导。它还通过单一网络评估做出预测,而不像 R-CNN 这种系统,一张图就需要成千上万次预测。
用了哪些黑科技?
- 多级预测:终于为yolo增加了top down 的多级预测,解决了yolo颗粒度粗,对小目标无力的问题。v2只有一个detection,v3一下变成了3个,分别是一个下采样的,feature map为13*13,还有2个上采样的eltwise sum,feature map为26*26,52*52,也就是说v3的416版本已经用到了52的feature map,而v2把多尺度考虑到训练的data采样上,最后也只是用到了13的feature map,这应该是对小目标影响最大的地方。在论文中从单层预测五种boundingbox变成每层3种boundongbox;
- loss不同:作者v3替换了v2的softmax loss 变成logistic loss,由于每个点所对应的bounding box少并且差异大,每个bounding与ground truth的matching策略变成了1对1。当预测的目标类别很复杂的时候,采用logistic regression进行分类是更有效的,比如在Open Images Dataset数据集进行分类。在这个数据集中,会有很多重叠的标签,比如女人、人,如果使用softmax则意味着每个候选框只对应着一个类别,但是实际上并不总是这样。复合标签的方法能对数据进行更好的建模。
- 加深网络: 采用简化的residual block 取代了原来 1×1 和 3×3的block; (其实就是加了一个shortcut,也是网络加深必然所要采取的手段)。这和上一点是有关系的,v2的darknet-19变成了v3的darknet-53,为啥呢?就是需要上采样啊,卷积层的数量自然就多了,另外作者还是用了一连串的3*3、1*1卷积,3*3的卷积增加channel,而1*1的卷积在于压缩3*3卷积后的特征表示。
- router:由于top down 的多级预测,进而改变了router(或者说concatenate)时的方式,将原来诡异的reorg改成了upsample
下一代YOLO长啥样?
- mAP会继续提高。随着模型训练越来越高效,神经网络层级的不断加深,信息抽象能力的不断提高,以及一些小的修修补补,未来的目标检测应用mAP会不断提升。
- 实时检测会成为标配。目前所谓的“实时”,工业界是不认可的。为什么呢,因为学术圈的人,验证模型都是建立在TitanX或者Tesla这类强大的独立显卡上,而实际的潜在应用场景中,例如无人机/扫地/服务机器人/视频监控等,是不会配备这些“重型装备”的。所以,在嵌入式设备中,如FPGA,轻量级CPU上,能达到的实时,才是货真价实的。
- 模型小型化成为重要分支。类似于tiny YOLO的模型分支会受到更多关注。模型的小型化是应用到嵌入式设备的重要前提。而物联网机器人无人机等领域还是以嵌入式设备为主的。模型剪枝/二值化/权值共享等手段会更广泛的使用。
说点题外话:
YOLO让人联想到龙珠里的沙鲁(cell),不断吸收同化对手,进化自己,提升战斗力:YOLOv1吸收了SSD的长处(加了 BN 层,扩大输入维度,使用了 Anchor,训练的时候数据增强),进化到了YOLOv2;
吸收DSSD和FPN的长处, 仿ResNet的Darknet-53,仿SqueezeNet的纵横交叉网络,又进化到YOLO第三形态。
但是,我相信这一定不是最终形态。。。让我们拭目以待吧!