概
GNN 有一个很严重的弊端: over-smoothing, 这会导致 GNN 的层数不能过深. 这篇文章指出, 影响网络性能的可能并不是 over-smoothing (或者说它并不罪魁祸首), 真正的问题是特征的 over-correlation. 于是作者通过最小化特征间的相关度, 最大化特征和初始特征的互信息来解决这一问题.
符号说明
- \(\mathcal{G} = (\mathcal{V}, \mathcal{E}, X)\), 图;
- \(\mathcal{V} = \{v_1, v_2, \ldots, v_N\}\), 结点;
- \(\mathcal{E} \subset \mathcal{V \times V}\), 边;
- \(X \in \mathbb{R}^{N \times d}\), 结点的特征;
- \(A \in \{0, 1\}^{N \times N}\), 邻接矩阵;
- 一般的 GNN layer:\[H_{i,:}^{(l)} = \text{Transform}(\text{Propagate} (H_{j,:}^{(l-1)}|v_j \in \mathcal{N}(v_i) \cup \{v_i\}) ) \]其中 \(\mathcal{N}(v_i)\) 表示 \(v_i\) 的一阶邻居.
over-correlation 的现象
-
pearson correlation coefficient:
\[\rho(x, y) = \frac{\sum_{i=1}^N (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^N (x_i - \bar{x})^2 \sum_{i=1}^N (y_i - \bar{y})^2}}; \] -
由此, 我们可定义特征 \(H \in \mathbb{R}^{N \times d}\) 上维度间的相关度:
\[\rho(H_{:,i}, H_{:, j}), \: \forall i, j \in [d]:= \{1, 2, \ldots, d\}; \] -
由此定义整个特征 \(H\) 的一个相关度指标:
\[Corr(H) := \frac{1}{d(d-1)} \sum_{i \not = j} |p(H_{:,i}, H_{:, j})| \in [0, 1], \]注意到, 当 \(H_{:, i}, H_{:, j} \forall i, j\) 是线性相关的时候, \(Corr(H)\) 达到极端的 \(1\).
-
同时我们定义整个特征 \(H\) 上的一个平滑度:
\[SMV(H) := \frac{1}{N(N-1)} \sum_{i \not= j} D(H_{i,:}, H_{j,:}) \in [0, 1], \]其中
\[D(x, y) = \frac{1}{2} \|\frac{x}{\|x\|} - \frac{y}{\|y\|}\|_2, \]当所有的结点都成比例, 即 \(H_{i,:} = cH_{j,:}\), 此时有一个最光滑的情况 \(SMV(H) = 0\).
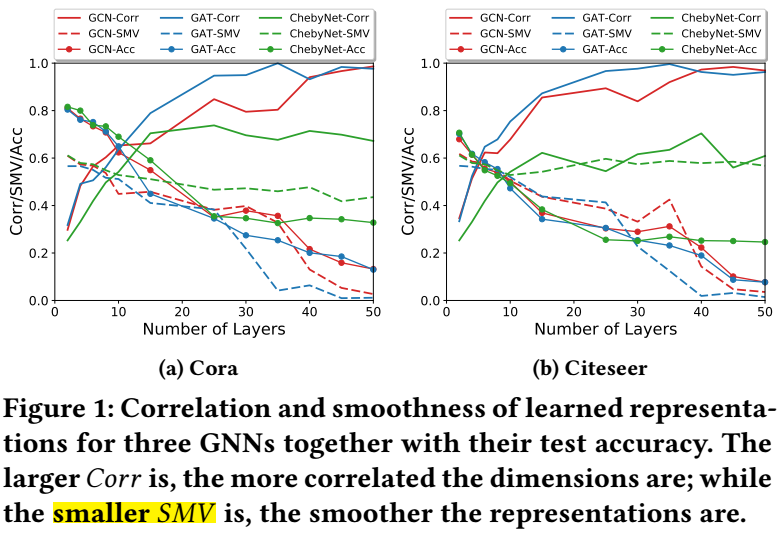
由上图所示, 当层数逐渐增加的时候, 结点的特征间的相关度 \(Corr(H)\) 会迅速上升, 最后达到接近 \(1\) 的峰值, 此时 GNN 几乎丧失了判断能力. 此外, 虽然在层数增加的过程中, \(SMV(H)\) 也在逐步下降, 但是并不如 \(Corr(H)\) 来的显著.
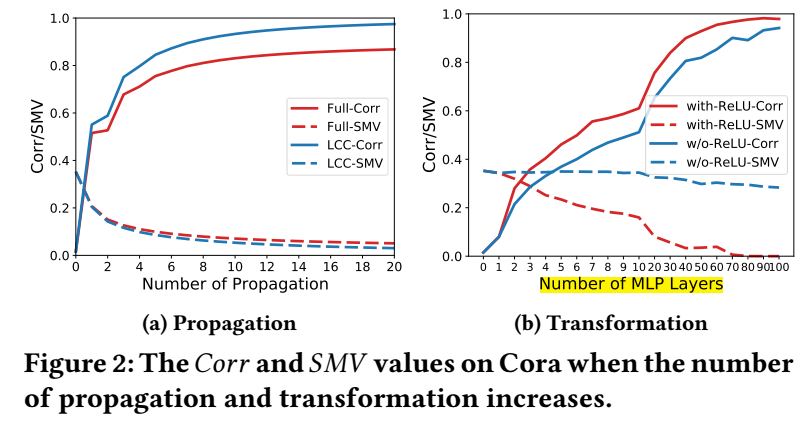
另一个很有意思的现象是, 当我们采用 \(\text{Transform}\) 为 MLPs, 并加多 MLP 的层数的时候, 网络的会逐步趋向过拟合. 此时如下图 (b) 所示, \(Corr\) 的增长非常迅速, 且无论 ReLU 是否采用, 而 \(SMV\) 则并不一定, 这也说明特征间的相关度更像是罪魁祸首. 此外, 过参数化的网络更容易招致这一点.
解决方法
-
作者希望直接最小化特征间的相关度:
\[\min_H \quad \frac{1}{N - 1} \|\underbrace{(H - \bar{H})^T (H - \bar{H})}_{\text{Cov Matrix}} - I \|_F^2; \] -
这类似于下列的标准化后的损失:
\[\ell_D(H) = \|\frac{(H - \bar{H})^T (H - \bar{H})}{\|(H - \bar{H})^T (H - \bar{H})\|_F} - \frac{I}{\sqrt{d}} \|_F^2, \]于是在各层上的损失可以归结为:
\[\mathcal{L}_D = \sum_{i=1}^{K-1} \ell_D (H^{(i)}); \] -
此外, 除了减少相关度外, 我们还希望特征 \(H\) 不丧失太多输入特征 \(X\) 的信息, 我们希望最大化二者的互信息:
\[\max \: \text{MI}(H, X); \] -
我们没法直接计算出二者的互信息 (因为我们并不知道分布), 故我们采用最大化它的一个下界:
\[\text{MI}(H, X) \ge \mathbb{E}_{P(H, X)} [f(H, X)] - \log \mathbb{E}_{P(X)P(H)} [e^{f(A, X)}], \]这里 \(f(H, X)\) 为 energy function;
-
具体的, 这里
\[\ell_M (H^{(k)}, X) =- \mathbb{E}_{P(h_i^{(k)}, x_i)} [f(h_i^{(k)}, x_i)] + \log\mathbb{E}_{P(h_i^{(k)})P(x_i)} [e^{f(h_i^{(k)}, x_i)}], \]其中 \(f(\cdot, \cdot)\) 是一个二分类函数:
\[f(h_i, x_i) = \sigma(x_i^T Wh_i), \]话说, 从 energy 的角度来说, 应该没有 \(\sigma\) 吧. 最后在各层上的损失就为
\[\mathcal{L}_M = \sum_{i \in [t, 2t, \cdots, \frac{K-1}{t}t]} \ell_M(H^{(i)}, X), \]注意, 这里作者每隔 \(t\) 层加一个损失, 用于加速训练;
-
最后总的损失为
\[\mathcal{L} = \mathcal{L}_{class} + \alpha \mathcal{L}_D + \beta \mathcal{L}_M. \]
代码
[official]