吉哈地址:
>>>https://github.com/DreamFeather/031702113<<<
更新记录
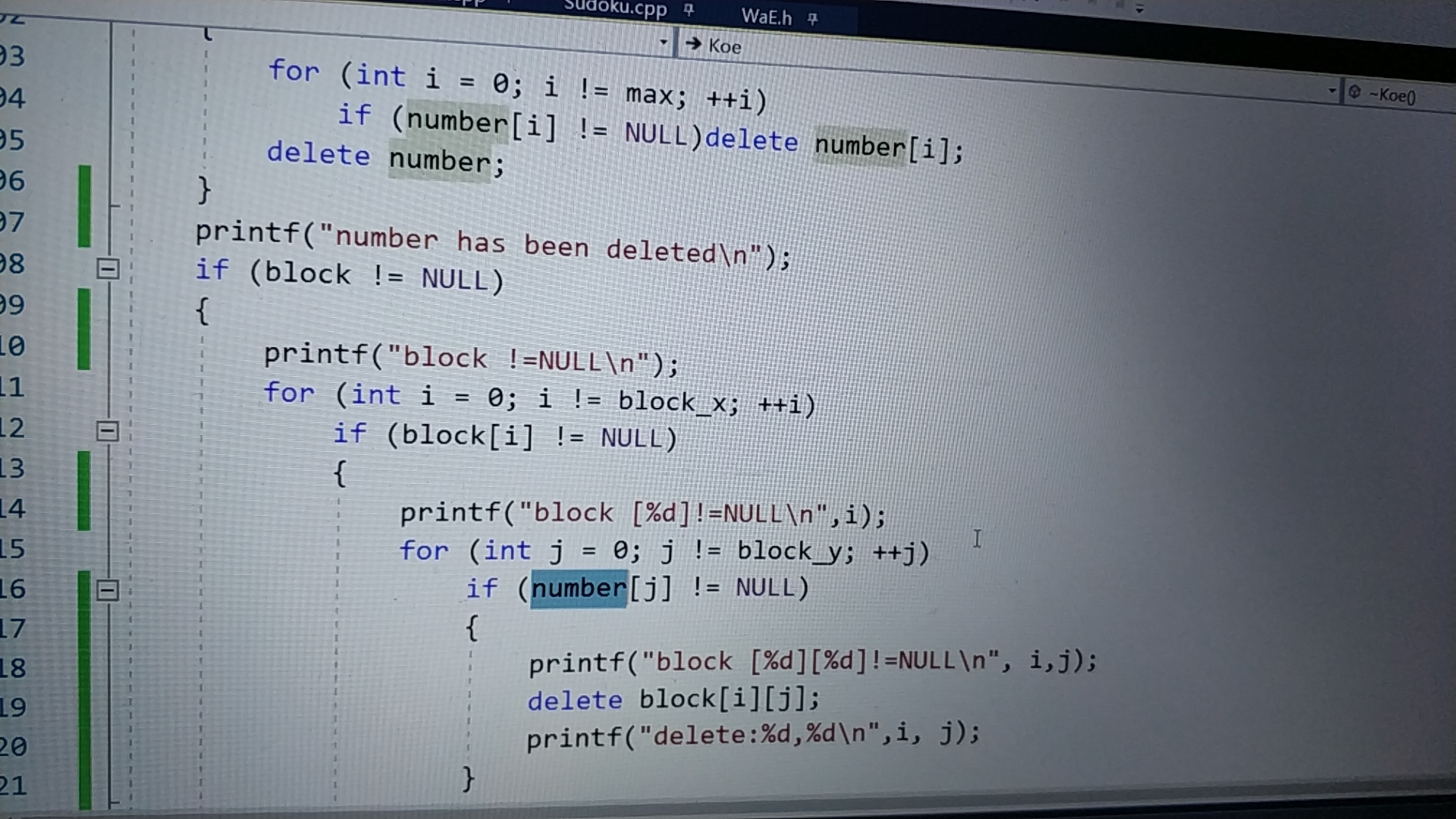
2019/9/30:程序运行时发现不可重现Bug,有几率导致程序停止运行。错误源自Koe::~Koe()中删除block指针时,错判用已经删除的number。已更正。
2019/9/30:博客内容删改:调整字体大小;PSP表格修改;添加流程图;添加拓展思考;重新进行代码分析;完善实例测试;
###PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| Estimate | 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 320 | 660 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 120 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 30 | 0 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| Design | 具体设计 | 20 | 120 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 10 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| **Reporting ** | 报告 | 160 | 320 |
| Test Report | 测试报告 | 20 | 120 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 180 |
| 合计 | 495 | 995 |
解题思路
看到题目是数独的时候,我大脑里第一反应是,游戏,数学家没事时玩的,一张报纸大的纸,一支铅笔,擦擦写写。好吧,这个游戏我听说过,但是从来没玩过,所以做的第一件事,在手机上装个数独游戏玩玩。这里我推荐“数独专业版”app,没有广告,界面简洁,小米商店评分4.9,下载来体验一把做数学家的惊险与刺激,简直是不二选择。边玩边思考,玩了两盘,灵感就来了。
首先,解一个数独题,其实就三步走:
第一,是最基本的,要知道哪些格子里有数,哪些格子没数。
第二,是最关键的,没数的格子里可以填哪些数。
第三,是最重要的,如何把格子填满。
第一步,用一个很简单的if语句就可以判断出哪些格子有没有数,没有数的要记录下来。我把它们放到一个队列里,排队等候填数
for (int i = 0; i != max; ++i)
{
number[i] = new int[max];
for (int j = 0; j != max; ++j)
{
number[i][j] = array[i][j]; //这里其实是Koe(宫格)类的初始化过程
if (number[i][j] == 0)space_x.push(i), space_y.push(j); //顺便找一下待处理的格子,将其坐标存入队列space
else if (divided)block[int(i*div_x)][int(j*div_y)][number[i][j]] = 1;//划分块,没宫的用不着
}
}
第二步,如果一个格子没数,如何得到它能填的数呢?从游戏规则上来讲是横竖不重复,分块内不重复。那就得从已存在的数入手
void Koe::available(int i, int j, queue<int> &rest) //找寻i行j列元素可用数,存放在rest队列
{
int m = 0, max_ = max + 1;
int *exist = new int[max_]; //因为要以存在数的值作为下标,所以得多开一点空间
while (m != max_)exist[m++] = 0;
for (m = 0; m != max; ++m)
{
exist[number[i][m]] = 1; //横竖同时判断,一个循环搞定
exist[number[m][j]] = 1; //不用跳过自己,反正必定有number[i][j]=0,再加判断只是空耗开销
}
if (divided) //从分块里再看
{
int x = int(i *div_x), y = int(j *div_y); //用i,j乘以分块划分比,即可得出i,j所在分块下标
for (int z = 1; z != max_; ++z)
{
if (block[x][y][z] == 1)exist[z] = 1; //block[x][y][z]=1的意思是,分块[x][y]中存在数字z
}
}
m = 1; //从1开始记录
while (m != max_)
{
if (exist[m] == 0)rest.push(m); //不存在的放入可用队列rest
++m;
}
delete []exist; //new出来的数组可以删了
exist=NULL;
}
第三步,怎么把格子填满?我用的是递归的方法,逐个处理在Koe初始化的时候,我已经把空位存入了队列space,所以我只要一个一个取出来填就行了,填什么?上面的的available方法已经给了答案(以下源码经过简化)
int Koe::deduce(queue<int>s_x,queue<int>s_y)
{
int x = s_x.front(), y = s_y.front();
queue<int> rest;
available(x, y, rest); //就当前位置找可用数字
s_x.pop(), s_y.pop();
int blk_x = int(x *div_x), blk_y = int(y * div_y);
int record = number[x][y]; //记录当前数字,保存现场。很没必要,我知道它一定是0
int answer = 0;
while (!rest.empty()) //可用数字不为空,就一直找下去
{
number[x][y] = rest.front(); //填一个数字
rest.pop();
if (divided)block[blk_x][blk_y][number[x][y]] = 1; //填好数字后相应的分块里要置1,表示占用
if (!s_x.empty())answer += deduce(s_x, s_y); //进入下一阶填空
......
if (divided)block[blk_x][blk_y][number[x][y]] = 0; //分块内数字取消占用
}
if (s_x.empty()) //空填完了,即找到了答案
{
......
}
number[x][y] = record; //恢复数字,等于0即可
return answer;
}
整个项目,主角就是Koe一个类,里面装的有点多,结构如下  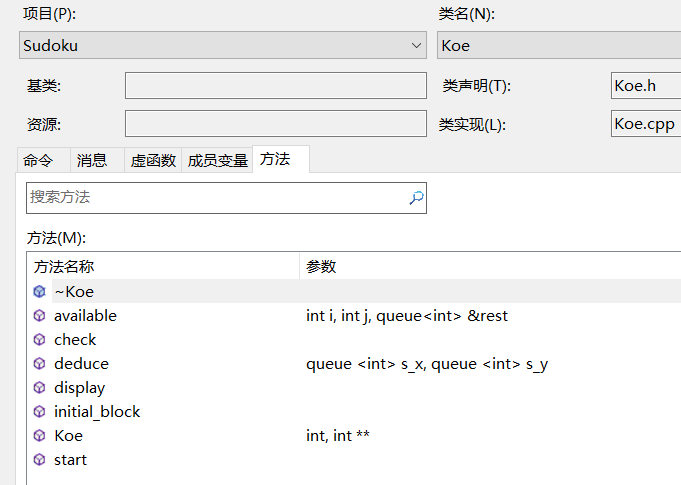
Sudoku里的main处理流程 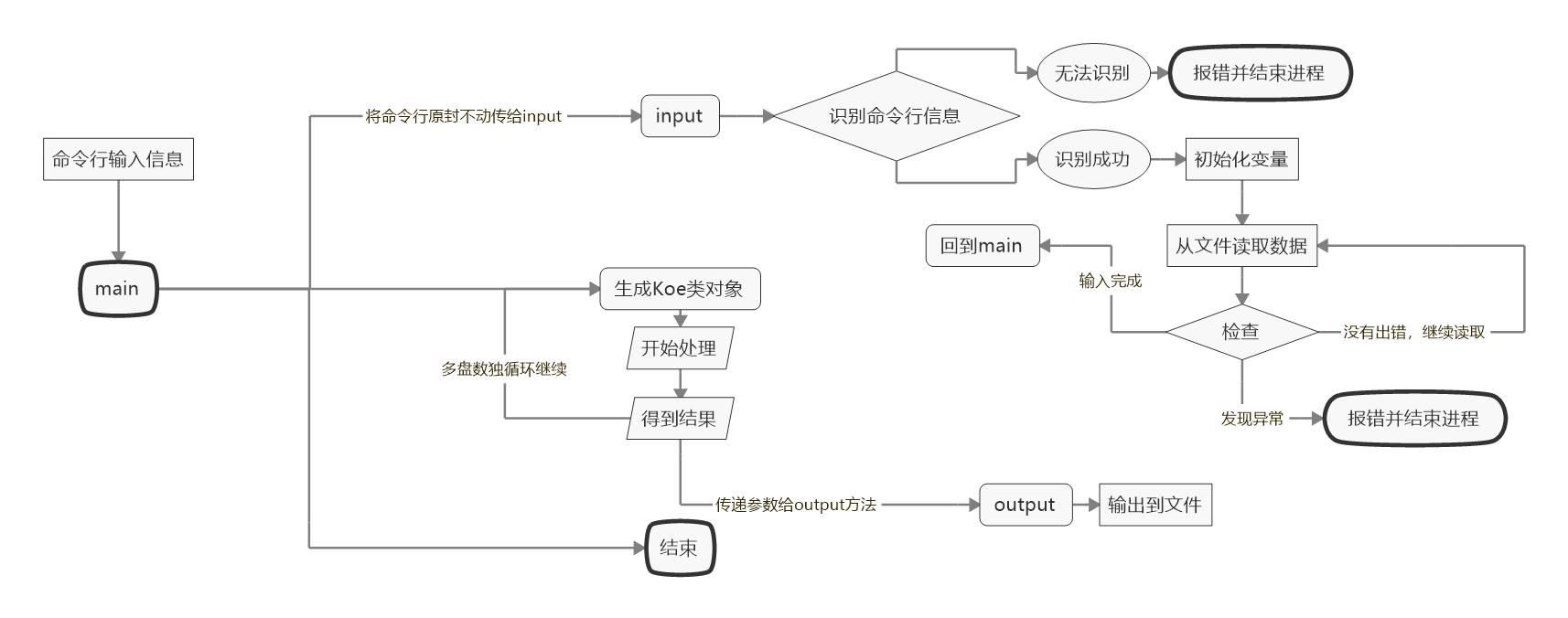
Koe类里的处理流程(略微简化) 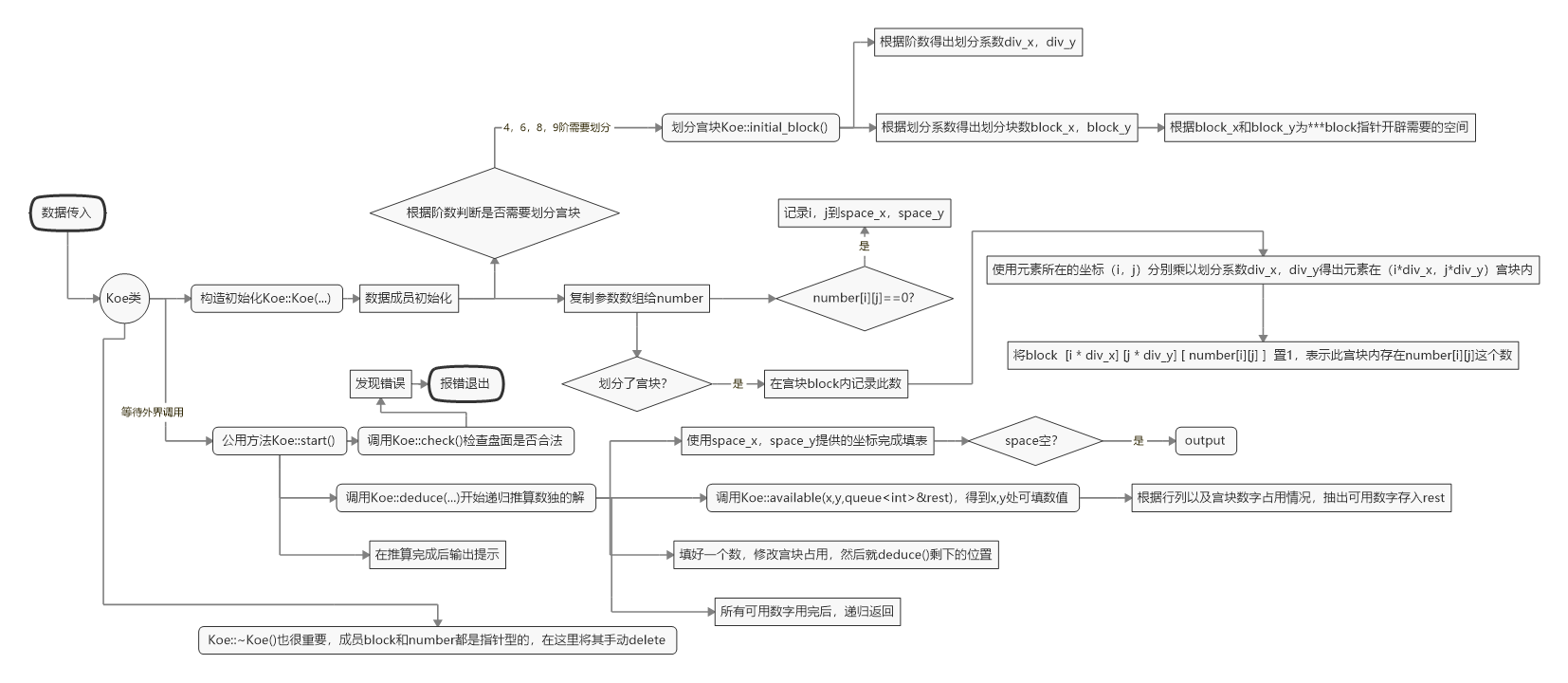
很多人会这觉得,解出数独即是完成了这次作业。解数独确实是这个项目的主要需求,也是整个项目构建起手之处,当然不排除有些人先构建IO啦。我是从解数独Koe类开始的,但是从新建一个项目到屏幕上可以正确输出只过了40分钟,准确地说43分钟,比我预想的要快得多。我想了想,我做完了吗?没有。停下来思考一下,总体完成度大概在66%左右,IO我还没处理呢。
这次作业还有一个关键点在于——对命令行的输入处理
并且,在作业要求里也有明确提到,对于错误的处理。我想了想,对于错误处理,在内部数据结构正确的情况下,出错基本是因为对输入处理得不够严谨,用正确的算法处理错误的数据,当然不会得到正确得结果。
我的目标是:对于任何输入,我的程序都能够有相应的反应。
- 只要命令参数里叙述的信息逻辑正确,符合规定,我就一定能提取出正确有效的信息。比如规定-m后是数独阶数,那么-m 3,3在-m后面,我就知道了,3带代表求解的数独阶数。
- 只要从命令行里能得到足够的、有效的输入信息,我的程序就一定能输出正确结果。
- 得不到足够的、有效的信息,或者无法识别输入信息,一定要有相应的错误提示,告诉用户有错误,可能错在哪里。
错误处理考虑:
-
命令行参数个数,最基本是要考虑到是有9个参数,Sudoku.exe -m 宫格阶数 -n 数独盘数 -i 输入文件 -o 输出文件,不是你期望的个数肯定就错了。我的为了实现多点的功能,参数有9,10,11三种可能。
-
命令行参数顺序,作业要求的原话是:“从-m之后获取盘面阶数,-n之后获取盘面数量,-i之后获取输入文件名,-o之后获取输出文件名。”输入顺序我不知道,我只知道从某个命令后获取到的数据代表什么,只要信息逻辑表达正确,我就能获取到正确有效的信息。
-
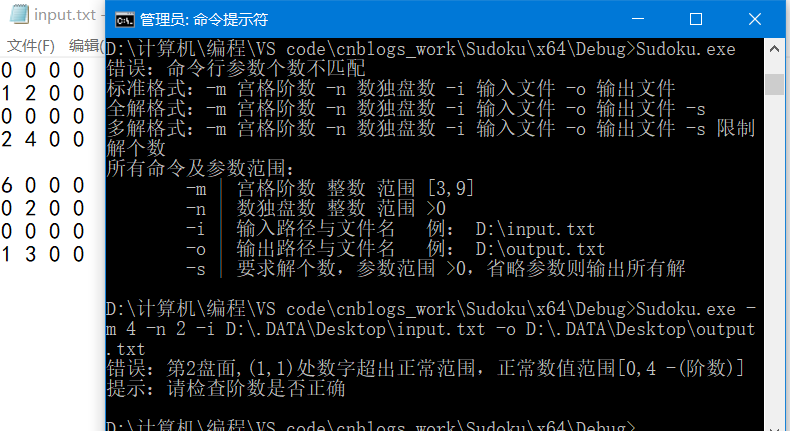
参数读到程序里来了,虽然正确有效符合逻辑,但还得确认它在我程序能处理的范围内。宫格阶数,整数范围[3,9];数独盘数,整数大于0就好;输入文件,首先能打开就好;输出文件的话,要求不高,不要和我的命令(-m,-n,-i,-o等)重名,(输出文件路径的问题有待考虑)。
-
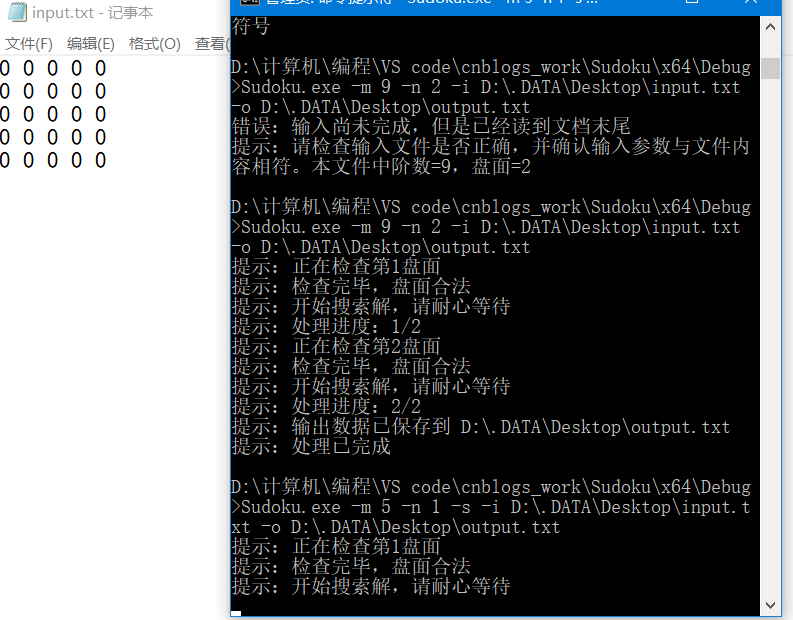
命令行的参数考虑到这里。另一个输入是在文件里,首先,我已经找到了,但是里面的数据不对,我肯定也处理不了。所以,先判断,文件有没有足够的内容,在读的过程中,要检查是否读到文档末尾了,我没读完就没了,那肯定不对,要报错,不是阶数错了就是文件错了。
-
文件内容人眼看上去是够的,5X5矩阵,9X9矩阵,非常整齐。但是万一其中插入了非数字字符呢?我测试过,fstream对象输入字符数据到int类型,程序可以是直接挂的,当场闪退。用户一脸黑人问号:闪一下就没了???辣鸡软件!!!用户肯定不会想到是自己的输入文件有问题,尤其还是那种喜欢把测试用例文件改来改去的(比如我室友 (눈_눈!) ),打上了一个字符也毫不知情,后面测试两小时你其实能想到我们在干嘛了,简直害skr人。好吧,在文件里检测到字符了或者其他非数字的输入,报错,精准到几行几列,检查盘数的时候输出现在是检查第几盘,所以报错后我们能迅速找到错误。
-
对于输入的处理我还不敢保证绝对完美,毕竟我个人的精力和脑回路是有限的,我暂时已经想不出还会有其他我没考虑到情况了。实际上我可能已经过度考虑了:虽然atoi函数只能返回int型,但要是阶数盘数输入出现小数我也会输出警告。此时,虽然程序已经获得到了可用有效的信息,但是我还是遗憾地选择终止进程,因为输入不符合规范,规范是整数。比如-m 3.8,我用atoi转换一下只能得到3,但是在*argv[]里我仍然能找到一个'.',基于人性化考虑我可以让它以3接着运行下去;基于严谨性我认为我获得了一个有效信息3,可是这个有效信息3和用户输入的原始信息3.8所表达的信息有出入。我该如何在这两者之间选择或者权衡?我最终还是选择了严谨。
错误处理相关输出

再到头来看,可能会有人觉得可笑了,因为用户输入小数的可能性很小啊,用户自己是想输入整数的,他也清楚自己要是输入小数那绝对也不对,总之输入的可能性超级小,而且还有atoi替我处理......好吧,不讨论这个了,越讨论越觉得这个处理没必要。
拓展思考
数独的无解,可以分为两种:一阶无解和高阶(潜在)无解(我说的)。
一阶无解:是指初始数字分布很不巧,使得有些空格无数可填。就像这个:
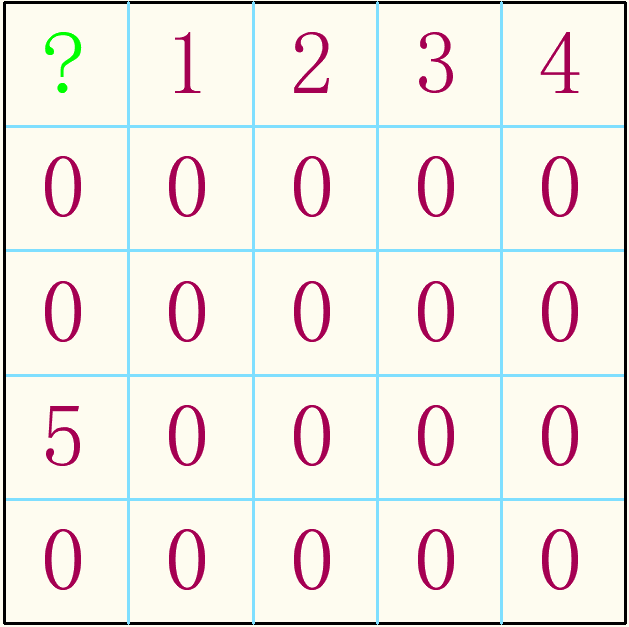
一眼看过去就能看出(1,1)无数可填。一个空位被其他位置制约我把它叫做一阶无解。
高阶(潜在)无解:是指初始时,每个空位都有可用的数字,但实际上这些空位的可用数字又有一些制约关系(即游戏规则),就是:你用了3,我就不能用3,我还有5可以用,那他也就不能用5了,要用其他的数字。而有的时候这些制约恰好使得这些空位可用数字不够用,而出现无解,就像6个空位,单独看,每个空位都可以填一个或者几个数,但又因为他们之间的制约关系,加起来不重复的可用数字却只有5个,6个空,5个数不重复当然填不了。但是通常情况下,我们都会去找这些数字的排列组合,以为换一个方式就有解了,其实不然,本身就无解。
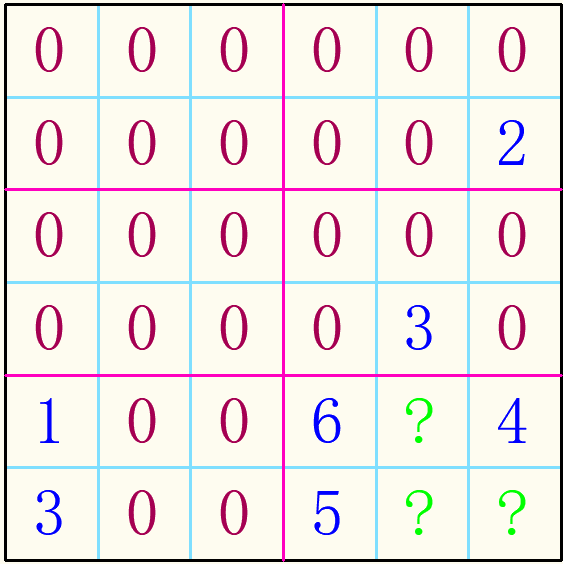
让我们再用一下这个词 “一眼看过去”,觉得没什么大问题。如果再一算,发现,确实出现了三个空只能用两个数的情况。无解吧,但是一般的递归非常的不甘心,都找到最后一个空了,前面填过的空换个数再试试,也只是徒劳而空耗性能资源。仔细一看,你就会发现,最后那个宫块,填不了3,被行列占用了。细看宫格规则发现,规则里规定,每个数字在每个宫格内必须出现并仅出现一次,所以这个是因为宫格的存在而多出来的一条规则、一个制约关系。
猜想:
制约规则多,制约关系太强,所以导致高阶无解出现。那么制约关系弱一点的3、5、7阶宫格又会怎样呢?我很快就大胆地断言:3、5、7阶宫格,因为制约关系较弱,所以要无解只会出现一阶无解,不会出现高阶无解的情况。我马上又回想到我的算法又可以优化了,3、5、7阶只需判断一阶无解就可知道有无解,判定一阶有解后,在推算解的过程中我就可以避开繁琐的有无解处理。脑细胞过度活跃的我发出了曾小贤的经典笑声,当时甚至还觉得3阶太简单可直接跳到5阶,并试图证明,没有宫格,就不会出现高阶无解。我马上开始绘图,以填图的形式来证明并理清证明思路。哪有啊,就是瞎想几个例子,尝试找到制约因素过多会直接出现一阶无解而中间不会高阶无解的例子。绘图过程中我逐渐恢复了理智,定了一个模型:陆续添加数字,让5阶数独(1,1)处出现在不出现一阶无解的情况下出现高阶无解。
第一步,在第一列加上2,3,4。使得(1,1)处只能用1和5(如果第一列填4个数的话,容易出现一阶无解)
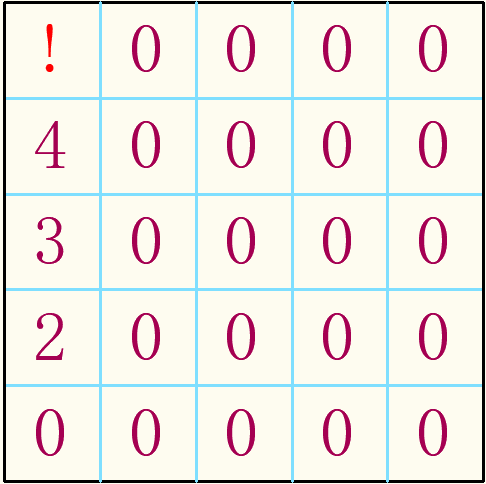
第二步,在第二列填上3,2,4,1。使得(1,2)处必定占用第一行的5
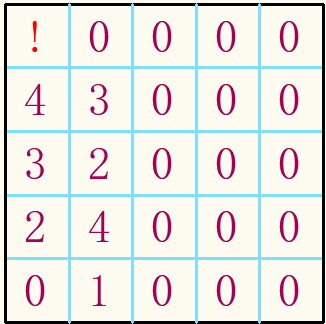
第三步,在第三列填上5,4,3,2。使得(1,3)处必定占用第一行的1
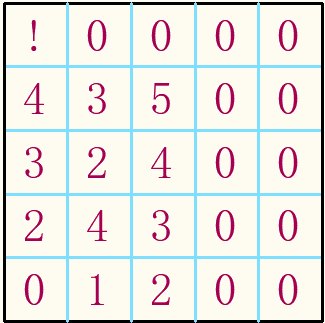
第四步,哎?(1,1)处好像已经出现了高阶无解???那我已经证明成功了,我成功证明了5阶数独可以有高阶无解。兴奋透顶的我又发出了曾小贤的经典笑声。
等我冷静下来才发现!我要证明的是:3、5、7阶数独不存在高阶无解......(笑容逐渐消失)
同样的我马上又发现了3阶的高阶无解,哦豁,7阶我想就不用证了吧。
这就是不动脑筋空动手的后果,白高兴一场。
好吧,其实我也并不是一无所获,至少我证明了3、5、7阶是存在高阶无解的,嘻嘻嘻。

可改进的地方
在写博客的过程中,我能想到很多在之前没有想到的事。
- 我觉得写代码的同时加上注释是一个十分重要的规范。在这里我把它当作规范而不是说好习惯,因为习惯看个人,规范看集体。我之前就把写注释当作习惯来看待,好坏与否我不是特别在乎。但是现在,我必须得注意了,除了有时候我自己看糊涂外,也是为了别人能更快地理解并读懂。写博客,大大地增加了我们代码的曝光度,写好注释,很重要。
- 代码结构还有需要改进的地方,首先是数独找0处理,还有优化的地方。我现在的处理方式是,从(0,0)扫瞄到(m,m)处,那么找出来的0的坐标在space队列里也是沿从坐到右,从上到下排列下来的,之后我直接就用这个顺序来执行递归搜索了,这种算法缺点就是没有优先度,若是碰到像上面那个6阶高阶无解,那一定会把所有排列组合找完才罢休。除了高阶无解,也许还会出现...额再造一个概念——假性高阶无解?,实际上是有解的,只要返回去改几个数就可以了。我想到的更优的算法是,将space队列里的坐标以该处可用数字个数从少到多进行一次排序,也就是可用数字更少的优先填,不然其他的地方先占用了,递归就要逐级返回搜索,直到将占用的地方改掉,才能继续往下走。如果真的无解,那么也能很快就发现,可用数字少的地方都填不下去了,就是无解的标志。再者毕竟题目要求只要一个解,最好的情况就是一路填下去填到最后一个space,把可用数字少的地方先填了,大概率实现所谓的一次找到,就算没有找到,递归返回的次数也会更少,这样递归深搜性能能得到极大优化。
- 我还是有点纠结那个命令行输入的操作,小数就不讨论了,我觉得能优化的地方是对于输出文件怎么决定,因为对于目前来说我在-o后面随便打什么(除了命令),它都能接受,比如-w,甚至乱码,dgh1214,它打不开它也能新建一个,而且文件用txt格式打开后也一字不差,这样太随意了。我目前能想到的就是判断输出文件路径最后四个字符是不是.txt,不是就不行。或者我可以人性化一点给它加上后缀?但是软工老师在课上说过这么一句话:“不是用户提出来的要求不要去做,做了白费精力。”所以嘞,考虑到严谨性我还是稍微做一下规范,仅输出一句提醒,不终止进程,仅此而已。
代码分析
以下,多图警告!(→ܫ→)
这是用m6n5的例子的性能分析。
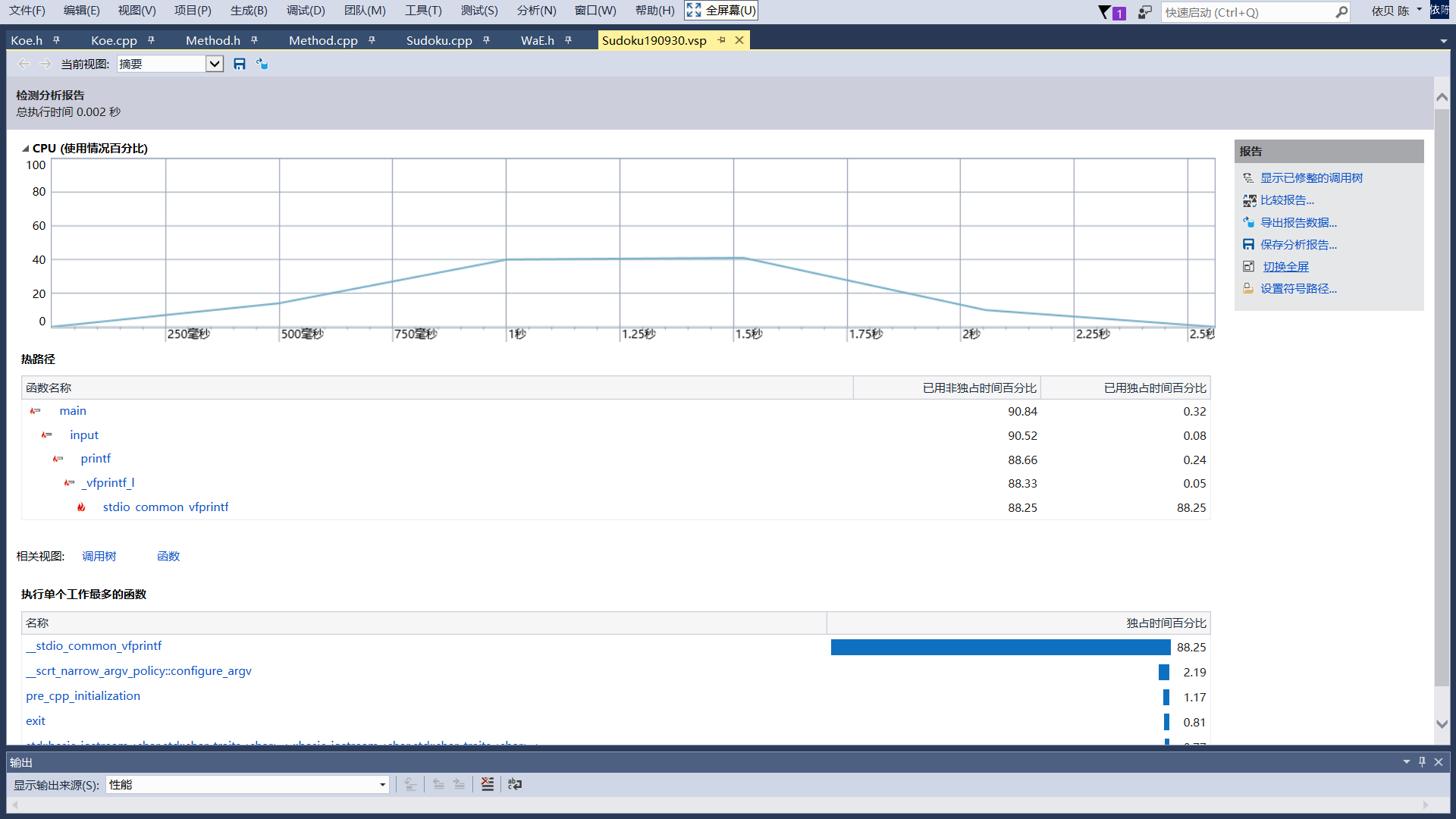
cpu占用最高达到40%,当然不够准确,应该是VS性能工具启动造成的。这种控制台窗口程序一般只会跑一个核,而我的电脑是四核,理论占用不超过25%,以我以往的经历,其实实际最高可以达到34%(死循环跑法)。并且我有留意,长时间耗cpu的程序,依系统调度会将其占用平均值控制在25%左右。比如这张图,5阶数独求10000解用了10分钟多(性能检测严重影响程序运行速度,实际只需40s),其占用就稳定在25%以下,单核并未跑满。(8分20秒之后我在使用电脑,导致占用偏高)
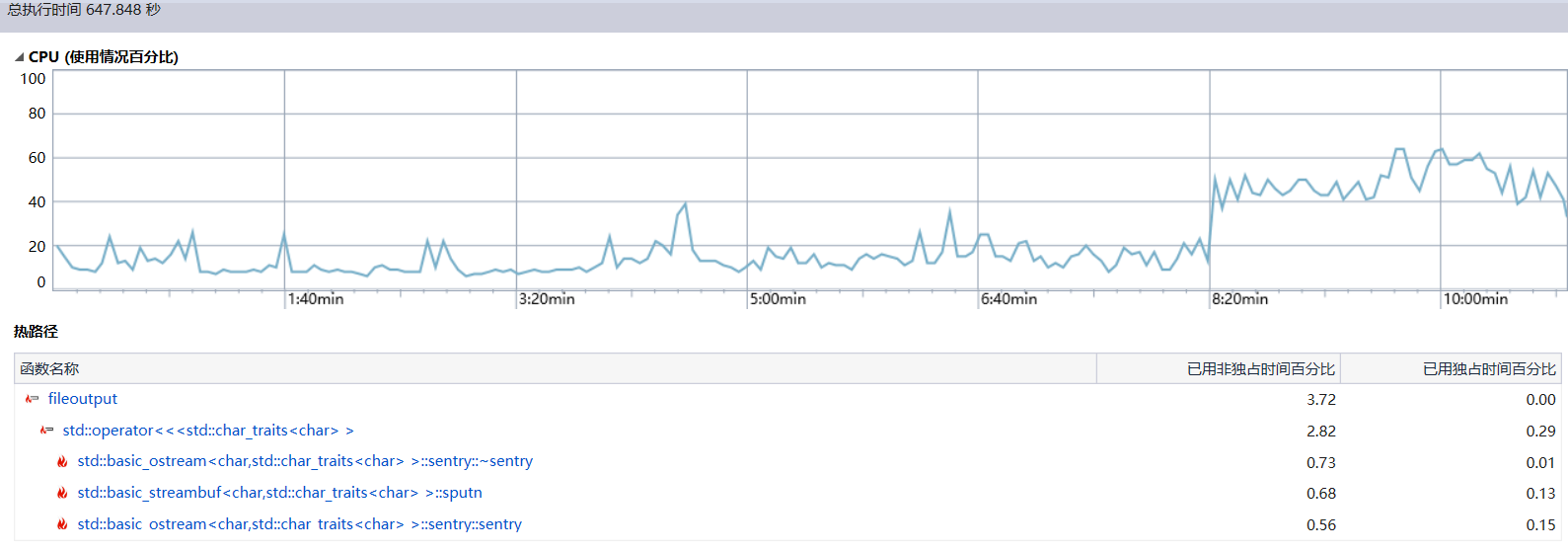
下面这张图展现的是sudoku.exe的调用树,一眼看过去,一个叫_stdio_common_vfprintf的函数独占时间最高,是关于输出的函数。我的窗口程序是有一些文字输出的,不过这个占用比例比我想象的要高得多,性能瓶颈在这,需要减少控制台输出来获得更快的运行速度。不过对比于之前,我已经优化过了,删掉了不必要的输出。
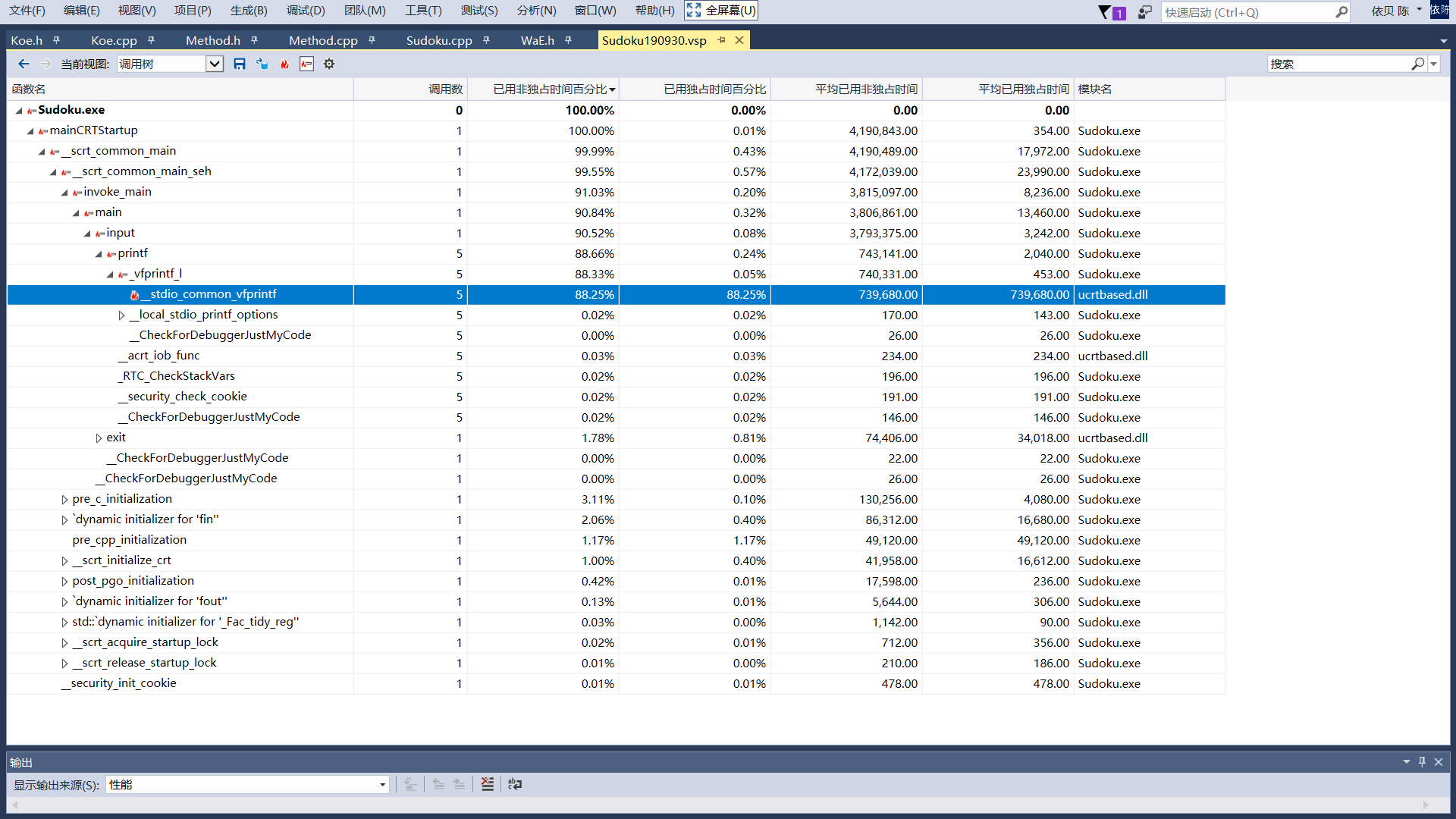
我依然好奇的是,我觉得最耗时的函数竟然没有上榜。
Koe::check()是用来检查数独盘面是否符合规范的,两层循环O(m^2),内层宫格空处调用Koe::available()寻找可用数字,复杂度O(2m);检测行列冲突,O(m);划分宫块内冲突两层循环,O((m * div_x * m * div_y)。所以Koe::check()总复杂度为O(m^2 * (m+2m+(m^2)))=O(g(m) * m4+3m3)(令g(m)为阶数m的划分系数div积,取值1/9,1/8,1/6,1/4,1),6阶就是1/6 * 6^4+3 * 6^3=4 * 6^3,不低了。
Koe::deduce()递归推算,令有k个0,每次都调用Koe::available(),复杂度O(k*m)不高于O(m^2),理想情况下确实不高。
Error是不能有的,Warning也不行。以至于double强转int我都显示转换了
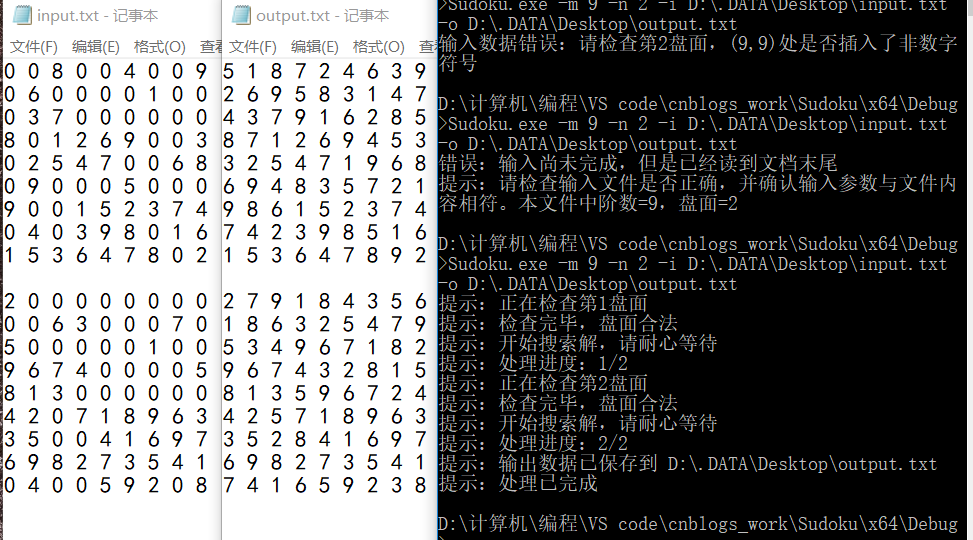
实例测试
基本测试:
九阶
八阶
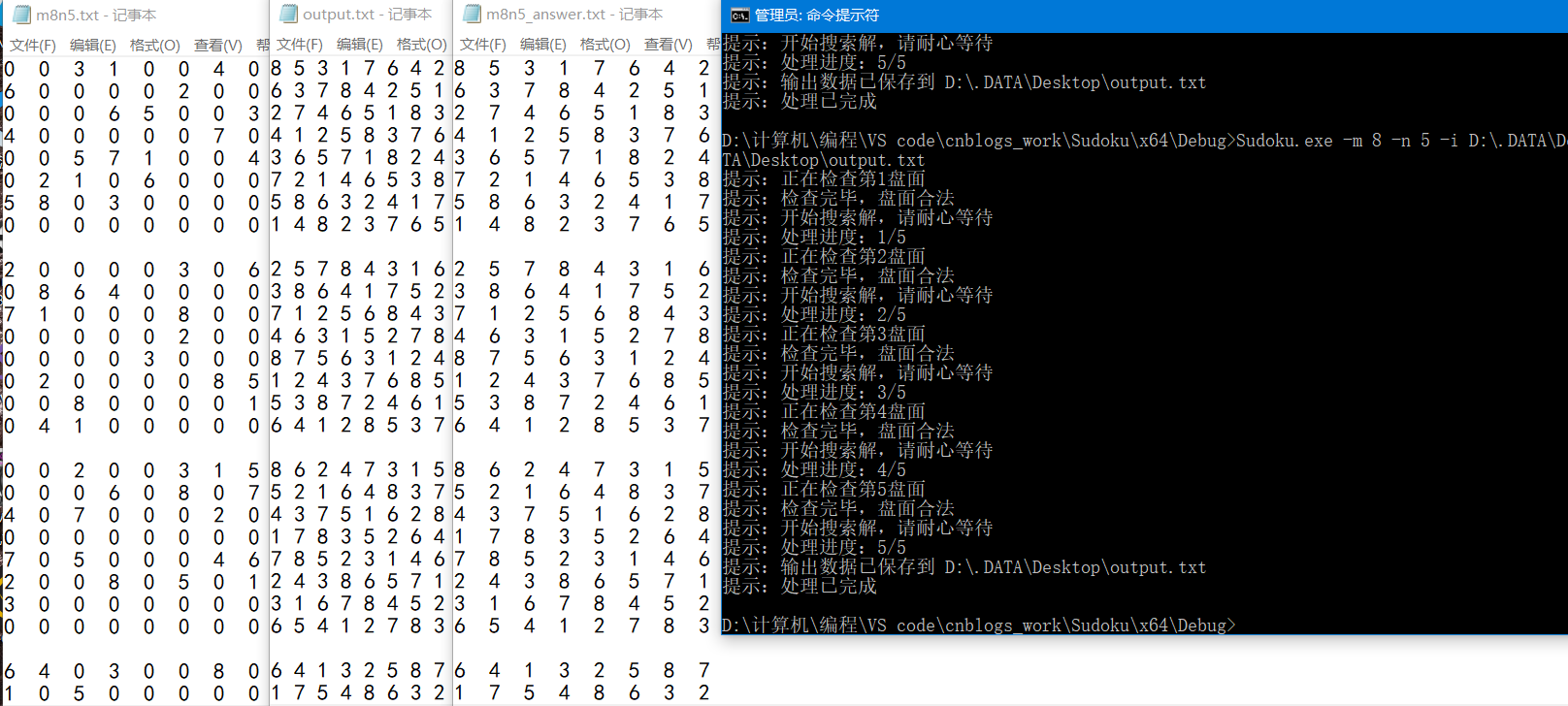
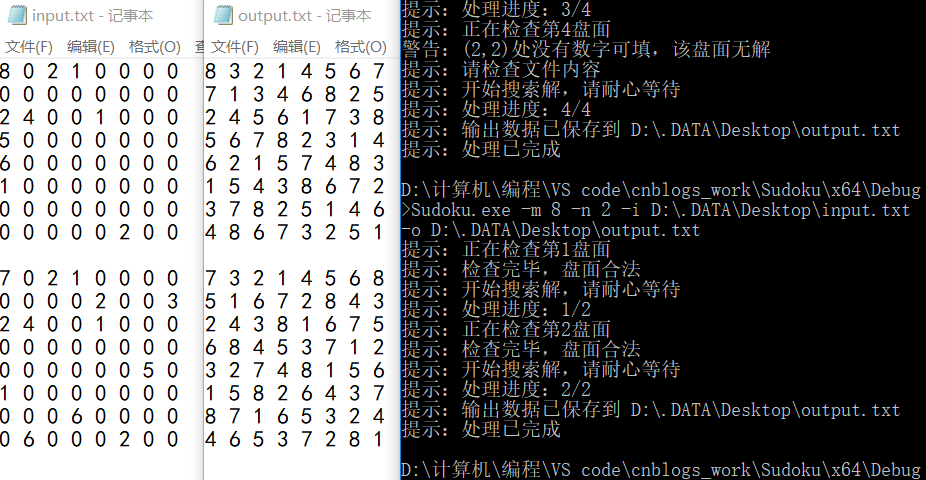
七阶
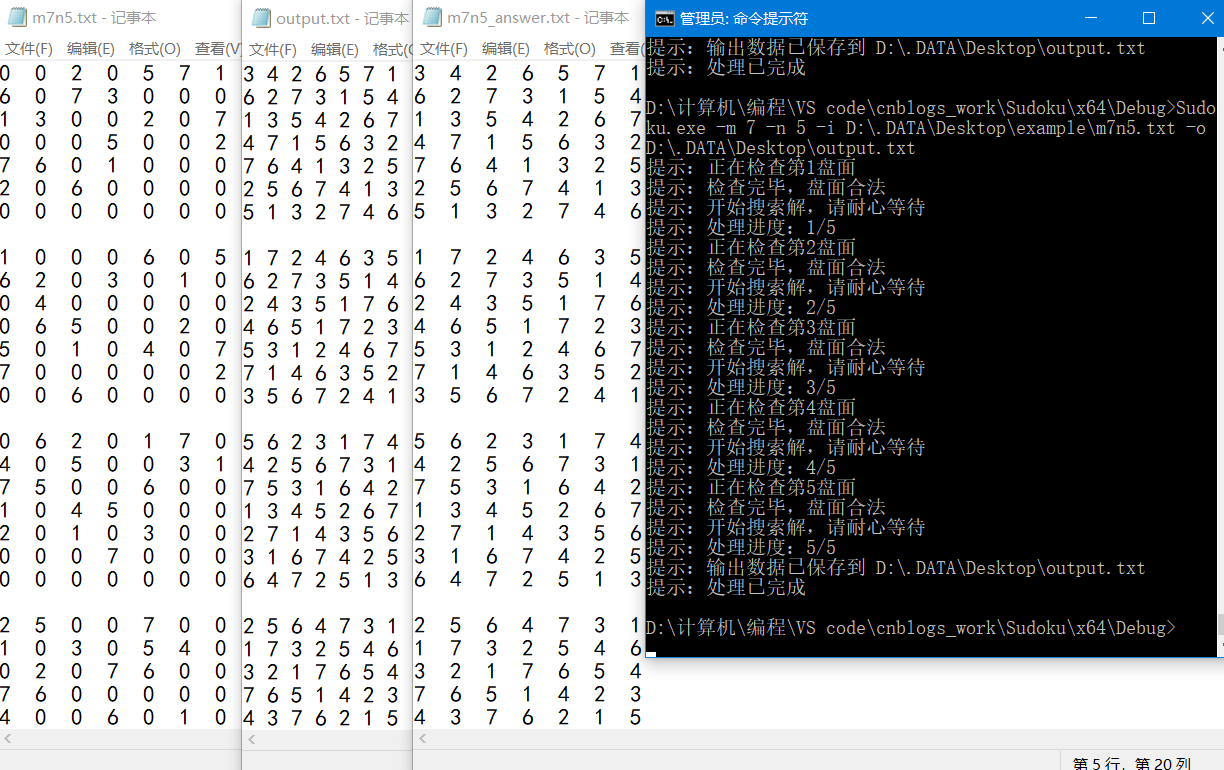
六阶
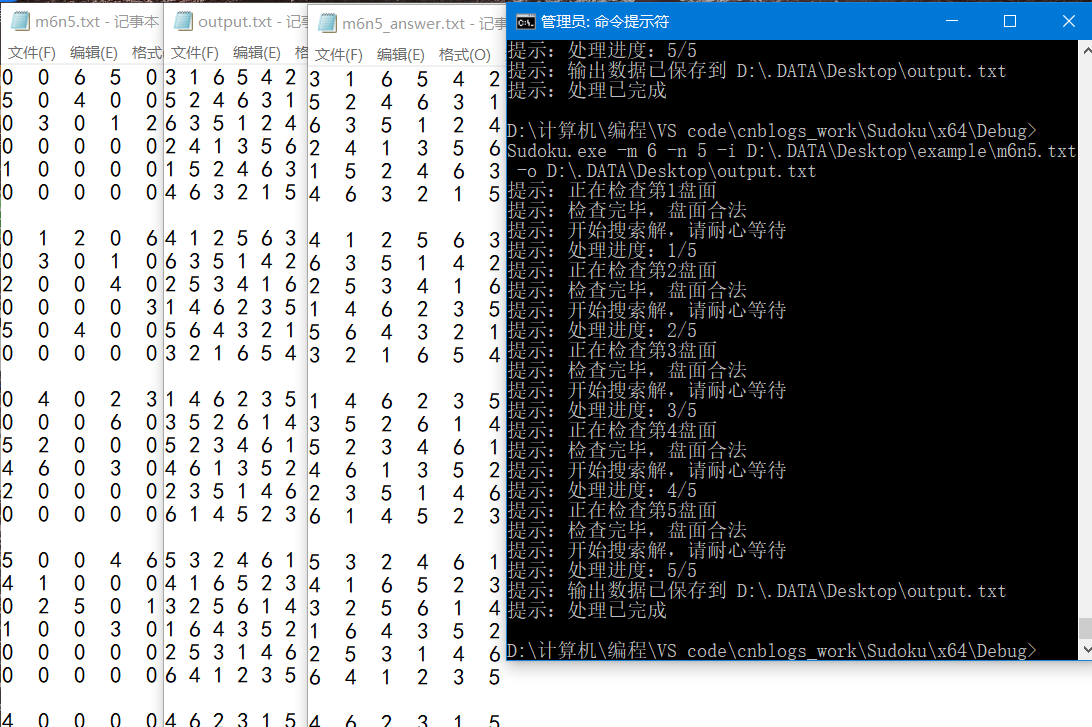
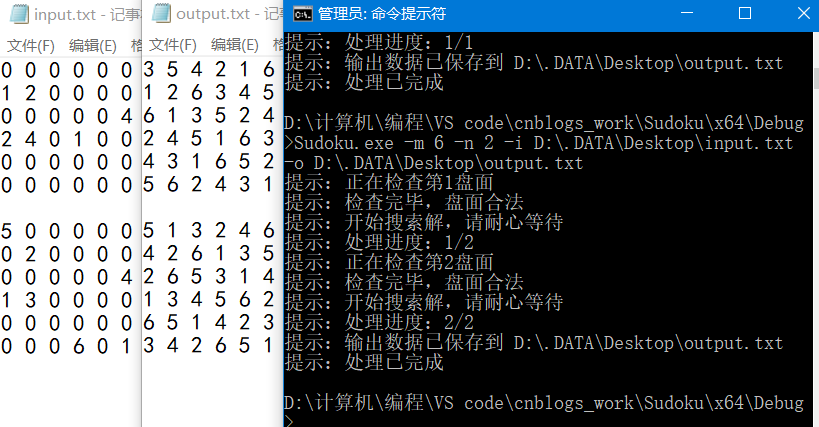
五阶
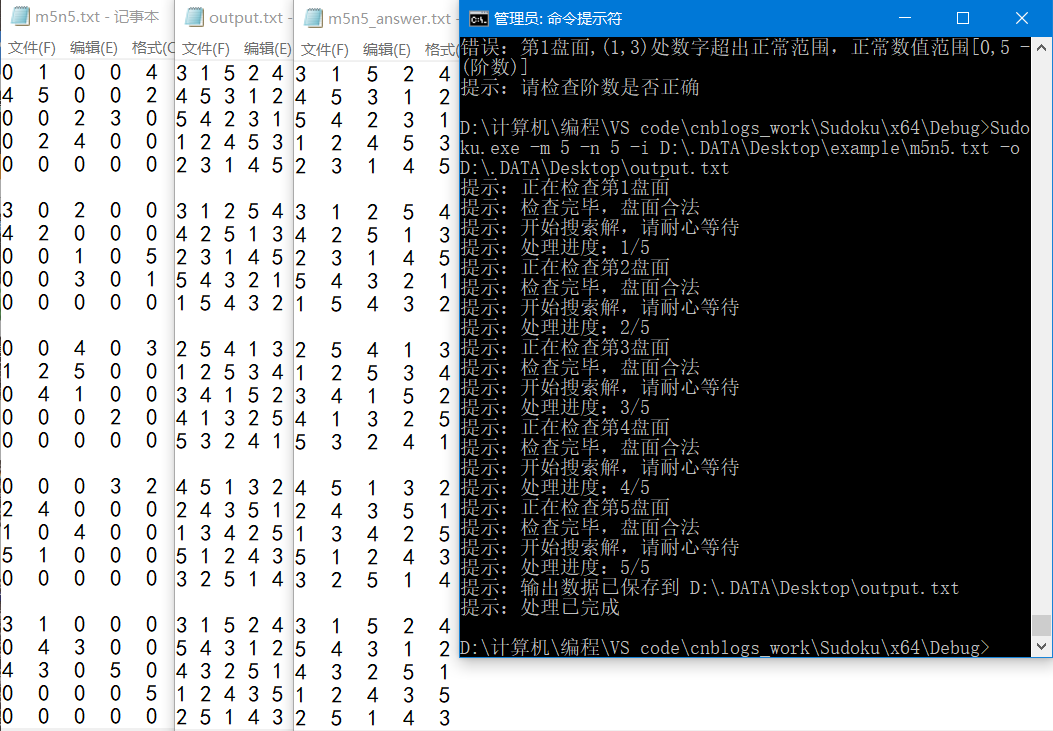
四阶
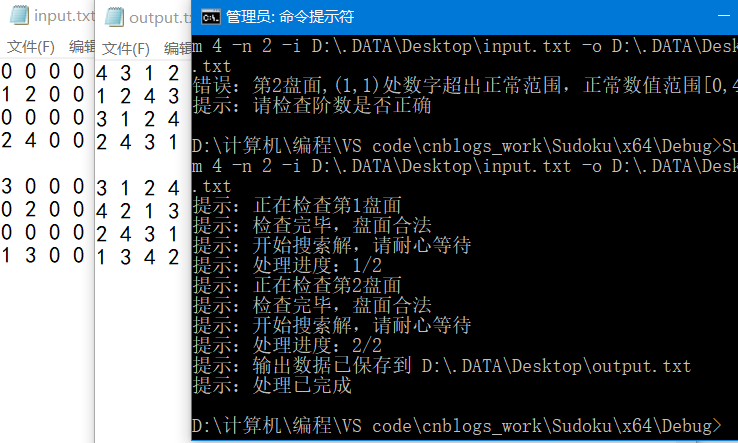
三阶
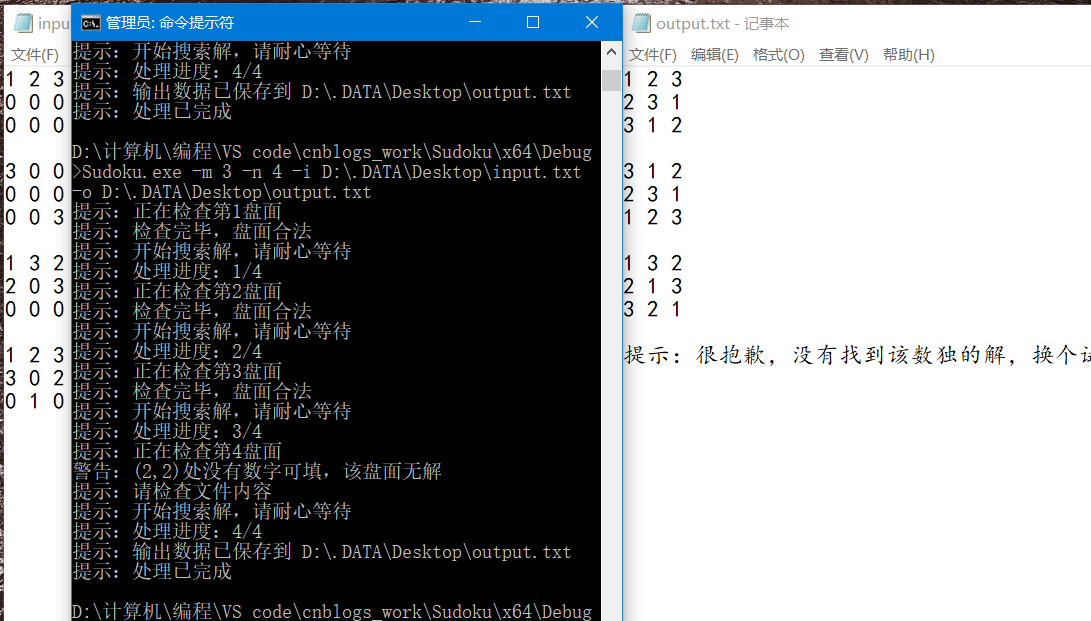
拓展测试:
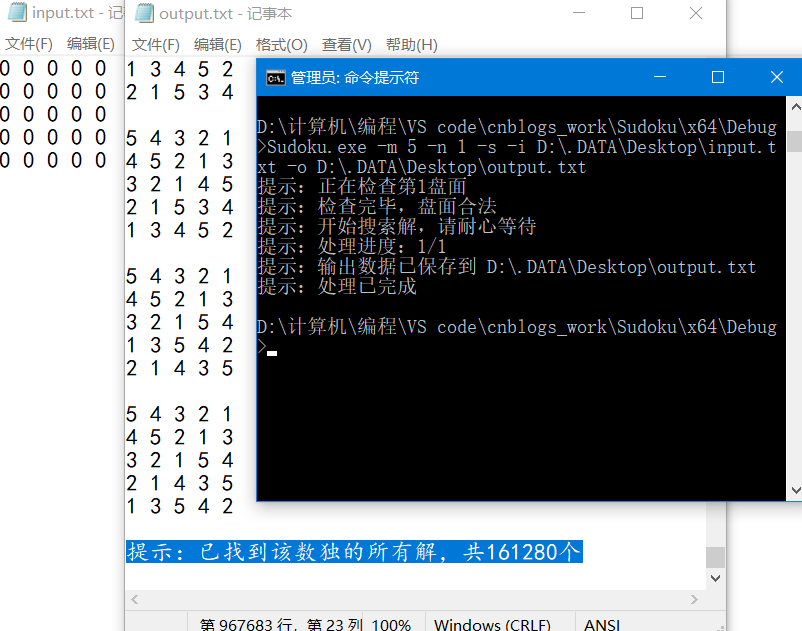
命令提示
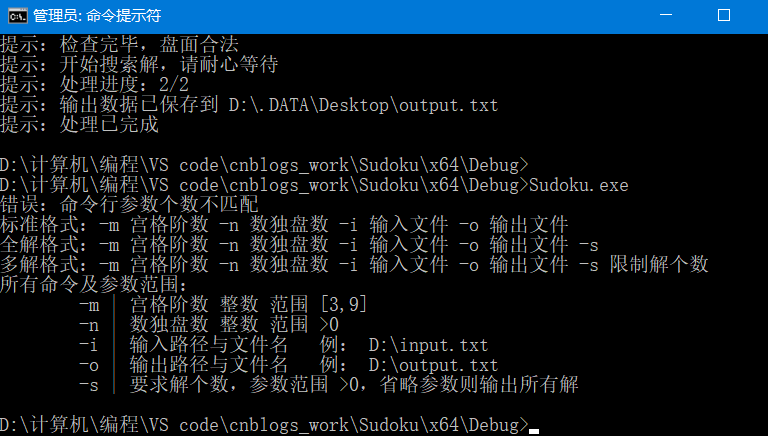
文档输入检测
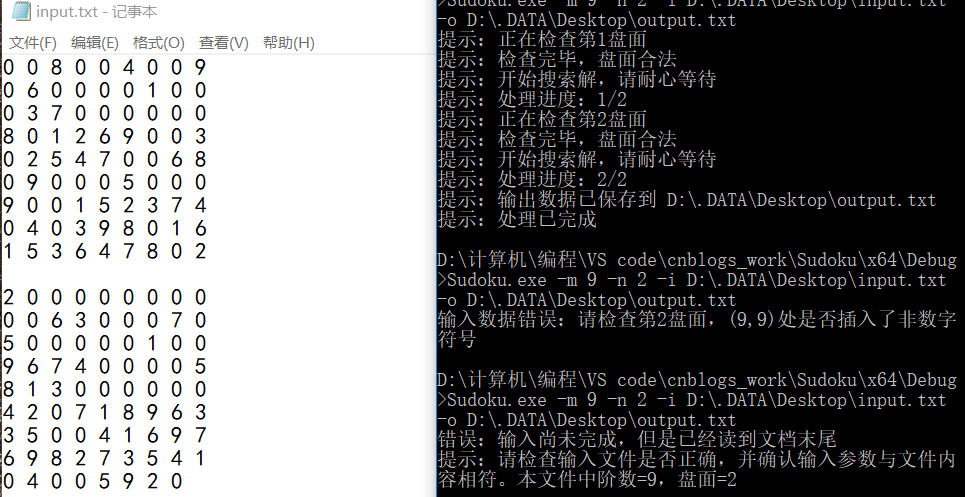
多解模式(求40个)
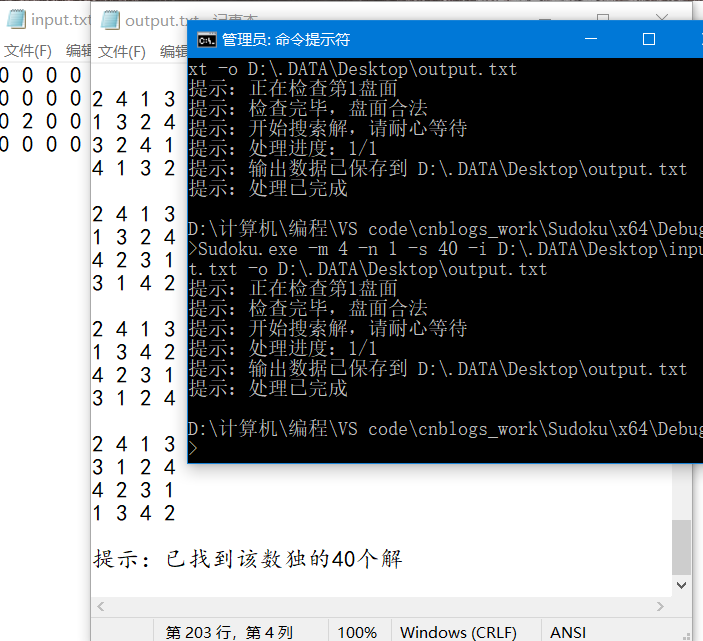
小小的错误提示
全解模式的话,可能要等一会了
16W+个,真实!