第一印象
SolrCloud是Solr4.0引入的,主要应对与商业场景。它很像master-slave,却能自动化的完成以前需要手动完成的操作。利用ZooKeeper这个工具去监控整个Solr集群,以了解集群间各个机器的工作状态。
配置的区别
从配置来看,SolrCloud和master-slave的主要区别在于是否有ZooKeeper节点。从下面这个配置概念图可知,SolrCloud集群最小的节点数都大于master-slave节点数,当然ZK节点不需要很强大,因为它只是用来监视和维护SolrCloud中的节点状态。
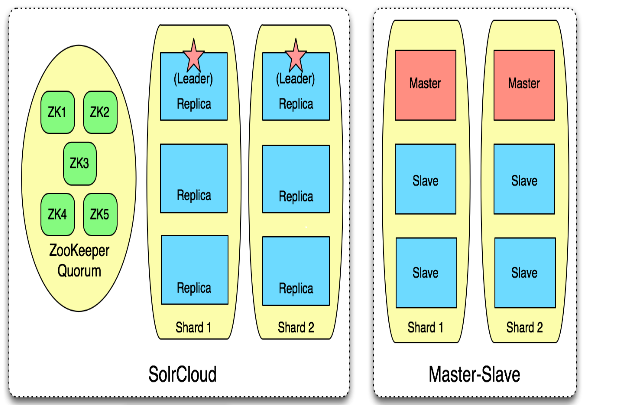
为什么有SolrCloud或者master-slave
- 分片(Sharding)
分片是在多台机器间拆分Solr索引。分片有时候是必须的,因为索引数据可能大到无法容纳在单台服务器上。通过分片,你可以在多台机器上分割索引,并持续增长而不会遇到问题。 - 近实时搜索和增量索引(NRT Search)
master-slave中每台机器上具有相同的索引数据,master负责索引数据,其他slaves负责检索数据。slaves在每隔固定的时间去master上拿新的索引数据。
SolrCloud在每个shard中都有一个leader,其他的replica与leader数据基本相同。leader的额外任务就是分发索引到该shard下的所有replica。发送到SolrCloud中的所有文档都会被路由给leader节点(当replica收到文档时,也就是要更新索引时,它会把该文档添加到事务日志中,然后报告给leader,由leader执行这个任务)。这样的机制可以分布式更新索引,并且是持久化的。 - 分布式查询和负载均衡(Load Balancing)
在master-slave中,查询哪个节点就只会返回该节点的数据。如果想用分布式搜索来查询某一个节点,可能需要外部负载均衡器的支持。
在SolrCloud中,分布式搜索可以自动被管理:查询任意一个节点,都会触发查询请求到其他shard中的某一个节点,只有聚合了所有分片的结果时,响应才返回。ZooKeeper知道所有的节点状态,一旦某个节点的挂了,就会向另一个节点发送查询请求。如果是leader节点挂了,还需要启动投票机制重新选leader。 - 高可用性(High Availability)
在master-slave中,如果master节点挂了,那么其他节点还是可以继续查询操作的,但是不能索引数据了,除非再手动添加master节点。这样一来,在重启master之前的更新操作会失败。
在SolrCloud中,当ZooKeeper发现leader节点挂了,会立即启动投票机制重新选举leader。直到了leader被选出来,所有的更新操作都会记录在事务日志中,在leader选出来后,继续同步工作,确保没有数据丢失。
无论是master-slave还是SolrCloud模式,都可以提供replication机制。但是SolrCloud是自动处理路由和恢复,而master-slave在某个节点没有响应以后,需要一些手动的操作才能恢复。
master-slave配置会简单很多,而SolrCloud需要配置ZooKeeper,为了保证系统能持续不断的工作,还需要给ZooKeeper配置集群,需要额外的资源。