Chapter 7 Data Cleaning and Preparation
Sometimes the way that data is stored in files or databases is not in the right format for a particular task.
Handling Missing Data
All of the descriptive statistics on pandas objects exclude missing data data by default.
For numeric data, pandas uses the floating-point value NaN (Not a Number) to represent missing data. We call this a sentinel value that can be easily detected.
When cleaning up data for analysis, it is often important to do analysis on the missing data itself to identify data collection problems or potential biases in the data caused by missing data.
大概意思就是说要注意对丢失的数据进行分析,来确定是数据收集的问题还是数据本身导致的偏差。(这句话还是不太懂。。。)
继承 R 语言的习惯,用 NA 表示统计数据中的缺失值,同时 python 内置的 None 也被认为是 NA。
下面是一些处理 NA 的方法:
-
dropna
主要功能是删去有 NA 的行或列,axis=0 or 'index'表示去掉有 NA 的行;axis=1 or 'columns'表示去掉有 NA 的列;thresh 表示对 NA 的容忍程度; -
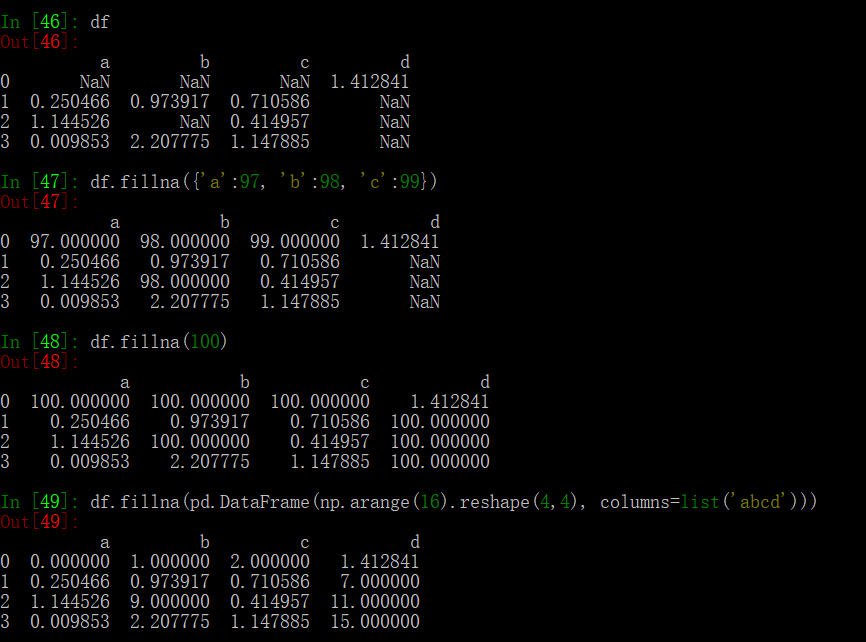
fillna
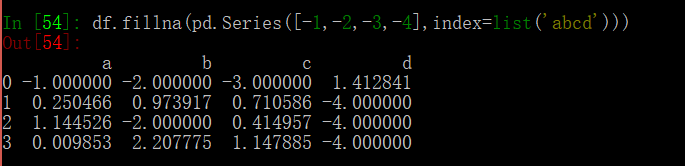
其中 value 参数的使用需要注意一下,是 scalar 时所有的 NA 会被替换;是 dict 时相应的 columns 会被替换;是 Series 时对应 column 的各个 index 上的 NA 会被替换;是 DataFrame 时直接看代码吧,描述起来十分拗口:
Filtering Out Missing Data
一种简单直接的办法就是去掉缺失值,这样在缺失值很少时较好用,缺失值如果较多就会丧失数据的内部特征。主要使用 dropna 这个方法,详细的用法和参数意义请看前面的链接。
Filling in Missing Data
主要使用 fillna 方法,主要用法和参数意义参看前面链接。
一种补全缺失值的方法是使用平均值。
Data Transformation
Removing Duplicates
df.duplicated 返回一个 boolean DataFrame。
df.drop_duplicates 去掉重复的数据。
详细的用法看文档。
Transforming Data Using a Function or Mapping
map 方法根据编写的映射规则对数据进行映射。也可以在 map 中使用根据映射规则写成的函数。
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon', 'Pastrami', 'corned beef', 'Bacon', 'pastrami', 'honey ham', 'nova lox'], 'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
meat_to_animal = { 'bacon': 'pig', 'pulled pork': 'pig', 'pastrami': 'cow', 'corned beef': 'cow', 'honey ham': 'pig', 'nova lox': 'salmon' }
lowercased = data['food'].str.lower()
data['animal'] = lowercased.map(meat_to_animal)
# another method
data['animal'] = data['food'].map(lambda x: meat_to_animal[x.lower()])
Replacing Values
df.replace() 用一些值替换一些值。
The data.replace method is distinct from data.str.replace, which performs string substitution element-wise. We look at these string methods on Series later in the chapter.
Renaming Axis Indexes
可以使用 function 或者 mapping 来修改 label 名称,包括 index 和 columns.
书中对于 rename 是这么说的:
If you want to create a transformed version of a dataset without modifying the original, a useful method is rename.
但是我觉得 map 好像也没有 modify the original。。。这应该不是必须使用 rename 的理由。
Discretization and Binning
有时候会将连续数据划分到多个组 (bins) 中,例如月收入在 1000 元以内的属于类别1, 1000-2000的属于类别2等,pandas 提供了 cut 方法进行处理:
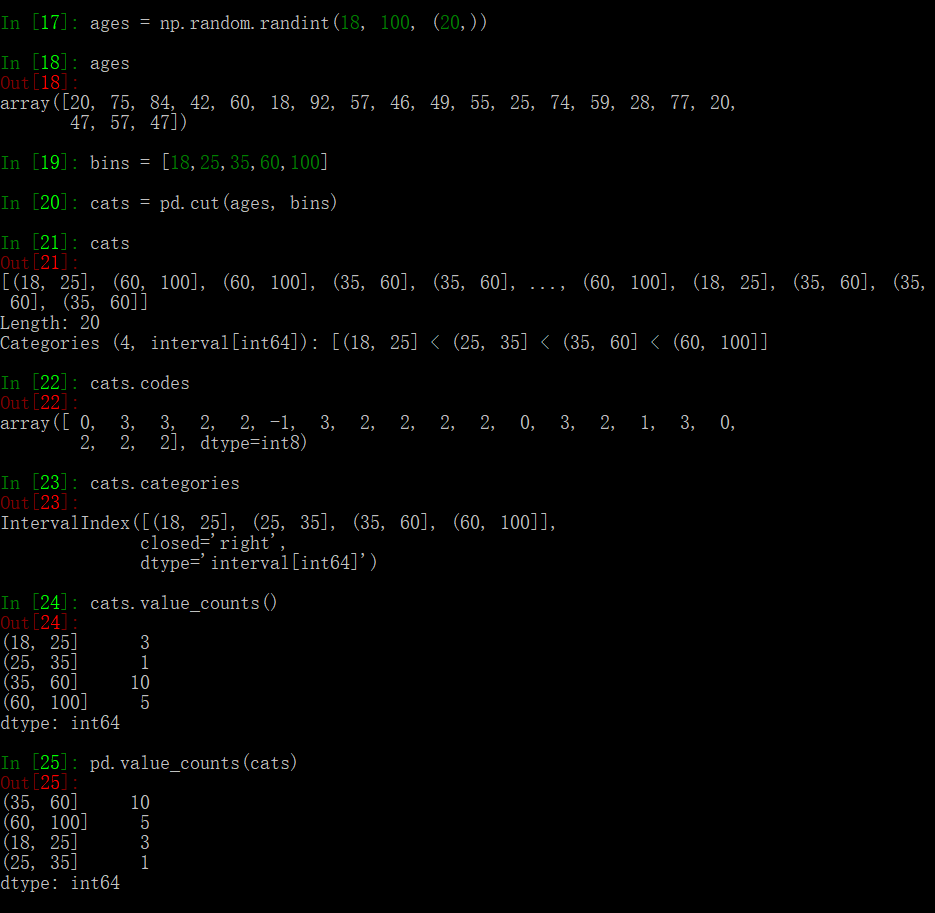
与 cut 类似的是 qcut,qcut 在指定 bin number 时,default 情况会以各个 bin 的 value_counts 相等为原则进行分类。
与 cut 相比,qcut 可以自定义分位点,比较灵活。
Detecting and Filtering Outliers
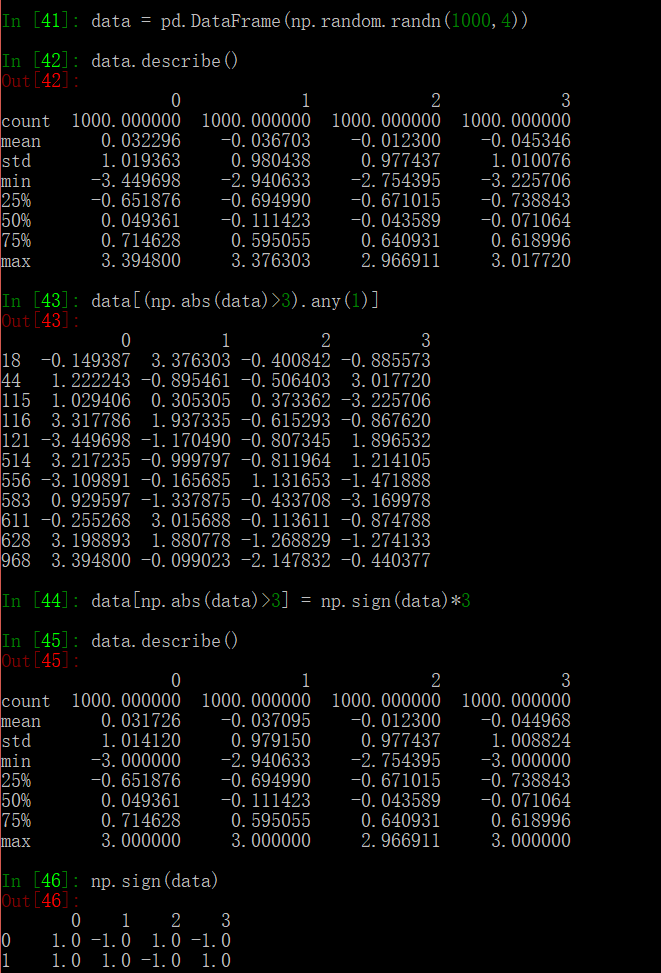
本质上还是 boolean index 的应用,我认为这里主要是要引入 sign 这个方法的使用,不然使用 where 方法也是可以完成这个功能的。
Permutation and Random Sampling
使用 np.random.permutation 方法生成一个随机的排列,如果 df 是 default 的 index,那么可以用 take 方法进行 index 的随机调换。
也可以用 sample 方法进行随机采样,replace 参数表示是否允许重复的采样。
Computing Indicator/Dummy Variables
这里用 get_dummies 得到 one-hot 向量:
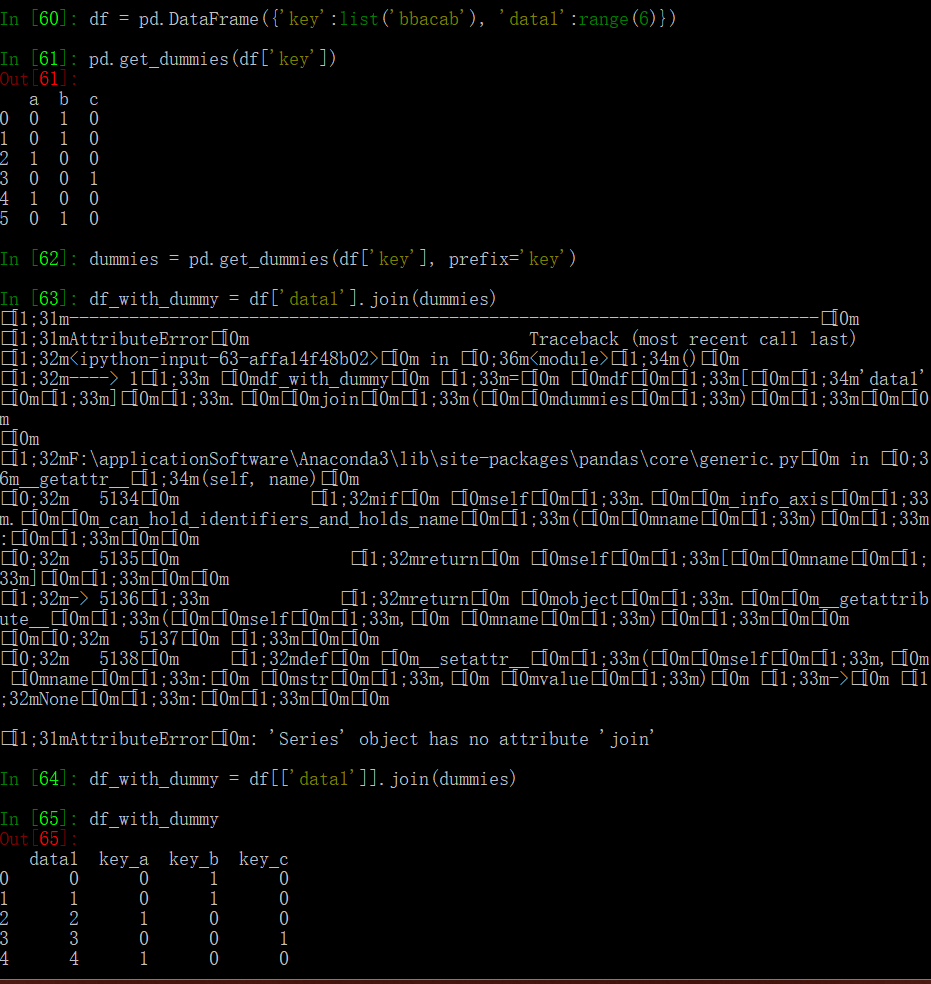
这里看到,Series 是没有 join 方法的。DataFrame.join 的 pandas 文档
这种方法适合单分类器,但是如果是多分类的情况,就需要一些稍微复杂的处理,首先需要构造一个 one-hot 矩阵,(shape = N_{index} * N_{classes}),之后分析每一行属于哪几类,使用 iloc 对相应的类别进行赋值。
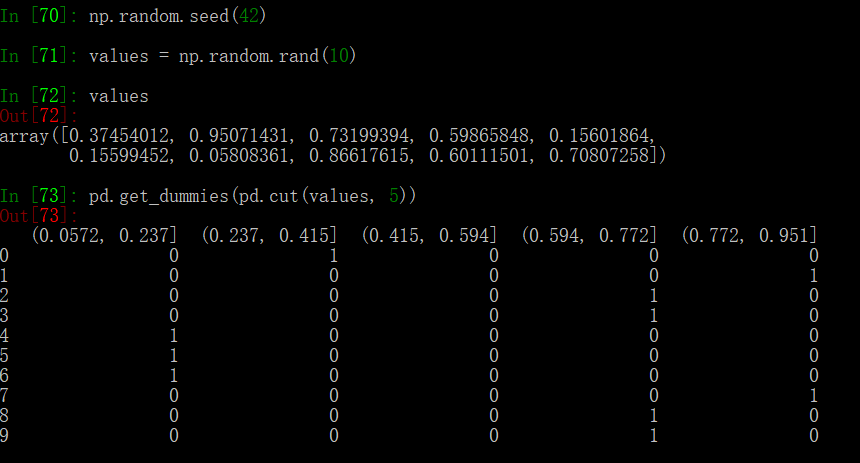
get_dummies 方法可以和 pd.cut 结合使用:
String Manipulation
String Object Methods
这部分介绍了一些 python 内置的 string 的用法。

这里稍微介绍一下 casefold,这个方法功能类似于 lowercase,但是更加 aggressive,会把所有的字符转换成可比较的形式,具体的例子请看 python 中关于 casefold 的文档。
Regular Expression
正则表达式,不看语法永远不会用系列QAQ。菜鸟教程
Vectorized String Functions in pandas
这部分主要讲的是用上部分的正则表达式和 str 自带的方法进行 str 数据的处理。
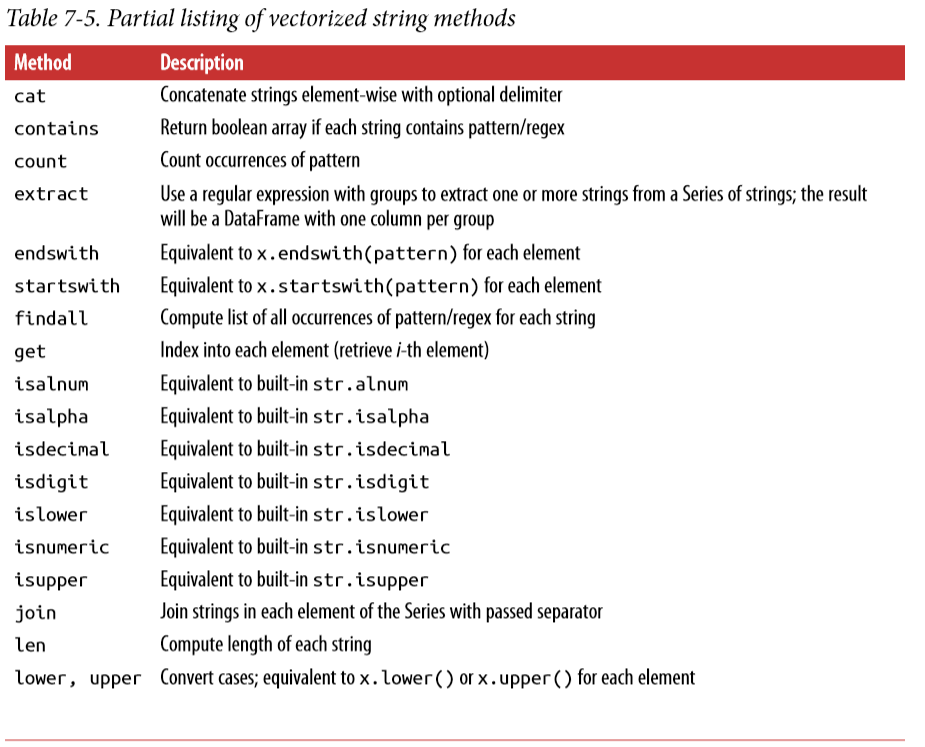

还是字符串处理和正则的混用。
Conclusion
Effective data preparation can significantly improve productive by enabling you to spend more time analyzing data and less time getting it ready for analysis. We have explored a number of tools in this chapter, but the coverage here is by no means comprehensive. In the next chapter, we will explore pandas’s joining and grouping functionality.
个人感觉这一章读起来还是比较轻松,很多地方都是点到为止,没有详细解释有些方法的具体用法,果然还是查文档学习起来最有效。