哈希表
相关概念
避免碰撞 — 构造哈希函数、再散列函数法、哈希表加链表
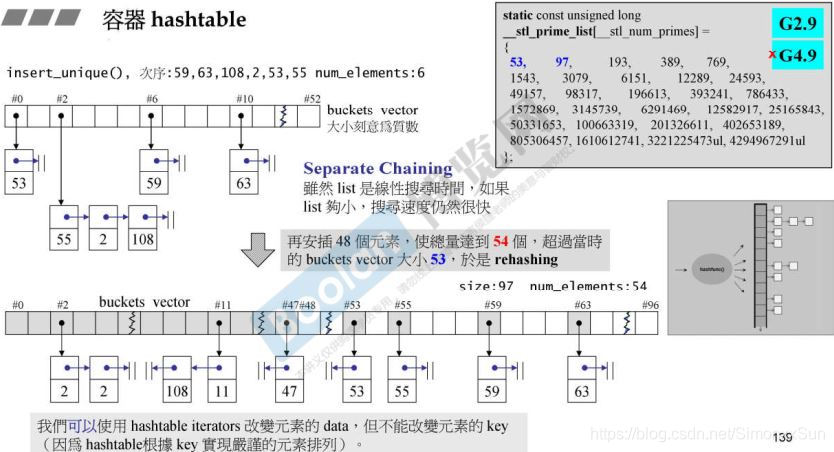
- 虽然很好的处理了碰撞的问题,但是当单链表很长时,遍历链表的速度会很慢。
- 当链表太长时(经验法则:当元素个数比 bucket
数还要多时),想办法将其打散 — 将 bucket 扩充大约两倍。选择53的倍数附近的素数 53 -> 97 -> 193........。(G2.9适用,其他的不一定。) - 哈希表的成长过程:bucket 会增加、 所有的元素所在的 bucket 会重新计算一遍,会花费一定的时间
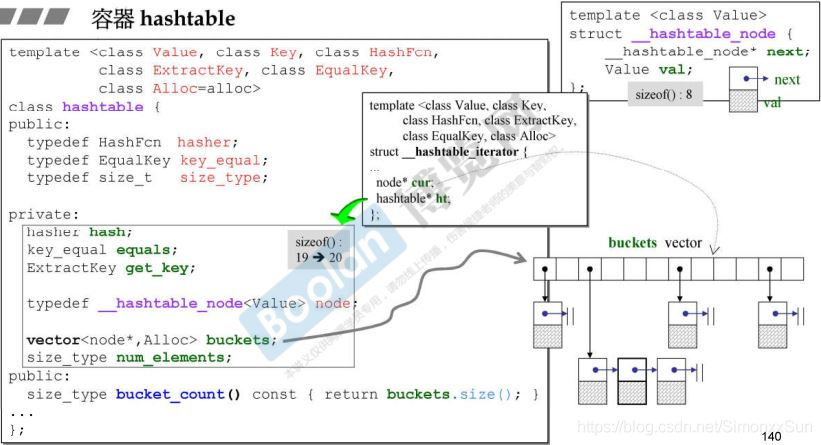
- HashFcn 由元素对象抽象出哈希码的函数
- ExtraKey 如何从元素(可能是 pair 等)取出 key 值的函数
- EqualKey 如何判断 key 相等的函数
哈希表本身的大小为20个字节:3个函数对象、1个 Vector、1个 unsigned int。
hashtable_node 为节点构成的单向链表(VC中为双向链表)。
迭代器必须实现智能的 ++ 等操作,在链表末端后重新定位回 bucket ,其中有两个指针,一个指向节点,一个指向哈希表本身。
//Application
hashtable<const char*,
const char*,
hash<const char*>,
identity<const char*>,
eqstr,
alloc>
ht(50,hash<const char*>(),eqstr());
ht.insert_unique("kiwi");
ht.insert_unique("plum");
ht.insert_unique("apple");
struct eqstr{
bool operator()(const char* s1,
const char* s2,) const
{return strcmp(s1,s2) == 0;}
};
关于 hashfcn:当模板参数为简单类型时,传入的简单类型的值可以直接作为抽象的哈希编码,其他:

其中的 hash_string(处理 c 风格字符串) 方案也是经验设计。
由 hash code%number_of_bucket 的除数取余算法方案是业内公认的做法。

find 和 operator 是哈希表中的一些成员函数,其中要计算元素会落在哪个篮子里。按其调用的路径,最后都会归结到 hash(key)%n 。
首先生成哈希值,然后使用hash code%number_of_bucket计算元素位置
hash_set与hash_multiset
相关概念
- hash_set是以hashtable为底层机制实现的。故对hash_set的各种操作可以转调用hashtable来实现。
- hash_set与set的不同:hash_set的底层机制是hashtable,而set的底层机制是RB-tree;set的元素能够自动排序,而hash_set的元素没有排序功能
- hash_set中键值就是实值,实值就是键值。
- hash_multiset的与hash_set有很大的相同性,其唯一差别就是hash_multiset中的元素可以重复。hash_set中的插入函数使用的是hashtable中的insert_unique(),而hash_multiset中的插入函数使用的是hashtable中的insert_equal()。
实现
// hash_set类定义
template <class Value, class HashFcn = hash<Value>,
class EqualKey = equal_to<Value>,
class Alloc = alloc>
class hash_set
{
private:
typedef hashtable<Value, Value, HashFcn, identity<Value>,
EqualKey, Alloc> ht;
ht rep; //底层机制 hashtable
public:
....
hash_set() : rep(100, hasher(), key_equal()) {} //缺省使用100个篮子,
//最后将被调整成对应的质数193
hash_set(size_type n, const hasher& hf) : rep(n, hf, key_equal()) {} //构造函数
hash_set(size_type n, const hasher& hf, const key_equal& eql) //构造函数
: rep(n, hf, eql) {}
//方法,通过hash table实现
size_type size() const { return rep.size(); }
size_type max_size() const { return rep.max_size(); }
bool empty() const { return rep.empty(); }
void swap(hash_set& hs) { rep.swap(hs.rep); }
friend bool operator== __STL_NULL_TMPL_ARGS (const hash_set&,
const hash_set&);
iterator begin() const { return rep.begin(); }
iterator end() const { return rep.end(); }
hash_map 与 hash_multimap
相关概念
SGI在STL标准外提供了hash_map,以hashtable作为底层机制。运用map为的是能够根据键值快速搜索元素,这一点RB-tree或是hashtable都能够实现。但RB-tree有自动排序能力而hashtable没有,其结果就是set元素会自动排序而hash_set不会。map和hash_map一样,拥有键和值,它们的使用方法也一样。
需要很简单:
1、hash函数(库有则使用库,没有则自己提供仿函数)。
2、key大小比较函数(库有,则使用库提供的模板实例化类,否则自己编写仿函数)
3、使用很简单,插入的时候,注意 insert 和 [ ] 方法的不同。
实现
int main(void){
hash_map<const char * , int , __gnu_cxx::hash<const char*> , eqstr> Mymap;
Mymap["January"] = 31;//设置map特有的操作符重载,下面重点讲解,将hashmap键和值可以用来计算键的次数
Mymap["February"] = 28;
Mymap["March"] = 31;
Mymap["April"] = 30;
Mymap["May"] = 31;
Mymap["June"] = 30;
Mymap["July"] = 31;
Mymap["August"] = 31;
Mymap["September"] = 30;
Mymap["October"] = 31;
Mymap["November"] = 30;
Mymap.insert( pair<const char * , int>("December" , 31) );//产生临时对象,并pair起来
//测试输出对应的键和值
cout << "December " << Mymap["December"] << endl;
cout << "June " << Mymap["June"] << endl;
cout << "April " << Mymap["April"] << endl;
cout << "March " << Mymap["March"] << endl;
cout << endl << "测试遍历操作" << endl;
for(hash_map<const char * , int , __gnu_cxx::hash<const char*> , eqstr>::const_iterator ite = Mymap.begin() ; ite!= Mymap.end() ; ite++)
cout << (*ite).first << " " << ite->second << endl;//记住这两种操作符重载类型
cout << endl;
}
这是最重要的地方,通过key获取对应的value。如果key存在,则返回value的引用,如果key不存在,则插入并且将value初始化为默认值并返回其引用,对应int,就相当于int()那么就是0。
T& operator[](const key_type& key) {
return rep.find_or_insert(value_type(key, T())).second;
}//这个是最重要的方法,区别与set的,很重要,直接调用了find_or_insert
find_or_insert的功能在前一讲hashtable已经详细说明,反正返回的是hashtable第一个模板参数类型。若key存在则返回存在的,否则插入hashtable并返回对应的引用。
所以这里可以将IP地址作为key,IP出现的频率作为value,用来统计每个IP出现的频率,在大数据的时候特别有用,所以这个就是map牛逼的地方,存储和查找都非常块。
