背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
在之前的系列文章中,分析到了Buddy System的页框分配,Slub分配器的小块内存对象分配,这些分配的地址都是物理内存连续的。当内存碎片后,连续物理内存的分配就会变得困难,可以使用vmap机制,将不连续的物理内存页框映射到连续的虚拟地址空间中。vmalloc的分配就是基于这个机制来实现的。
还记得下边这张图吗?
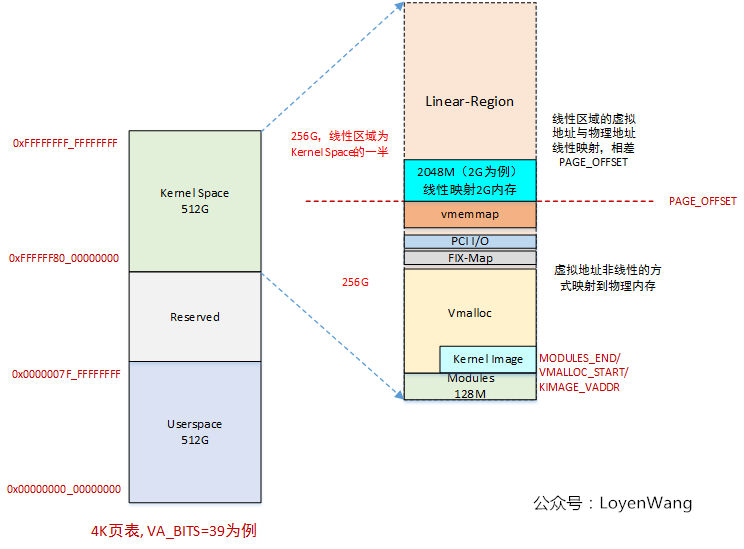
vmap/vmalloc的区域就是在VMALLOC_START ~ VMALLOC_END之间。
开启探索之旅吧。
2. 数据结构
2.1 vmap_area/vm_struct
这两个数据结构比较简单,直接上代码:
struct vm_struct {
struct vm_struct *next;
void *addr;
unsigned long size;
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
phys_addr_t phys_addr;
const void *caller;
};
struct vmap_area {
unsigned long va_start;
unsigned long va_end;
unsigned long flags;
struct rb_node rb_node; /* address sorted rbtree */
struct list_head list; /* address sorted list */
struct llist_node purge_list; /* "lazy purge" list */
struct vm_struct *vm;
struct rcu_head rcu_head;
};
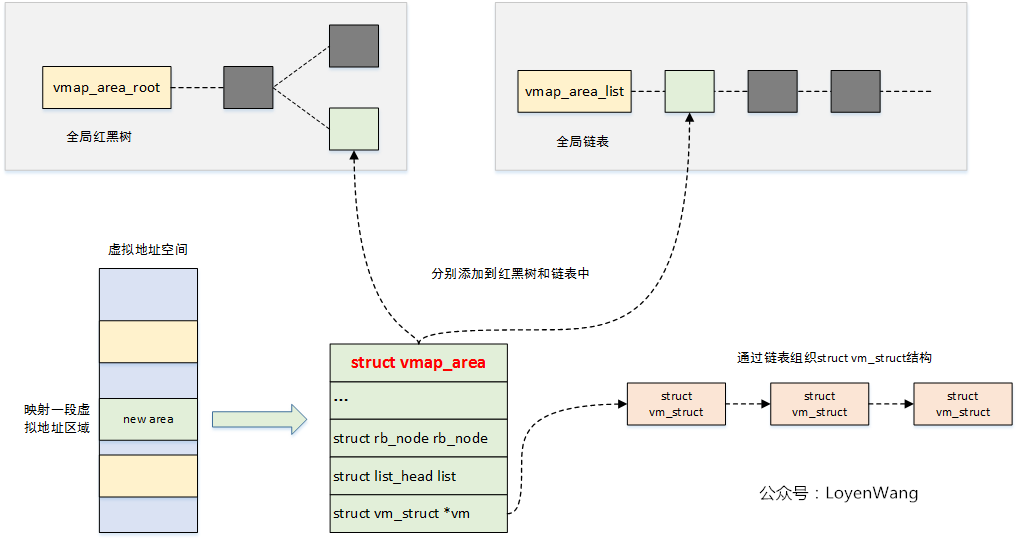
struct vmap_area用于描述一段虚拟地址的区域,从结构体中va_start/va_end也能看出来。同时该结构体会通过rb_node挂在红黑树上,通过list挂在链表上。
struct vmap_area中vm字段是struct vm_struct结构,用于管理虚拟地址和物理页之间的映射关系,可以将struct vm_struct构成一个链表,维护多段映射。
关系如下图:
2.2 红黑树
红黑树,本质上是一种二叉查找树,它在二叉查找树的基础上增加了着色相关的性质,提升了红黑树在查找,插入,删除时的效率。在红黑树中,节点已经进行排序,对于每个节点,左侧的的元素都在节点之前,右侧的元素都在节点之后。
红黑树必须满足以下四条规则:
- 每个节点不是红就是黑;
- 红黑树的根必须是黑;
- 红节点的子节点必须为黑;
- 从节点到子节点的每个路径都包含相同数量的黑节点,统计黑节点个数时,空指针也算黑节点;
定义如下:
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
/* The alignment might seem pointless, but allegedly CRIS needs it */

由于内核会频繁的进行vmap_area的查找,红黑树的引入就是为了解决当查找数量非常多时效率低下的问题,在红黑树中,搜索元素,插入,删除等操作,都会变得非常高效。至于红黑树的算法操作,本文就不再深入分析,知道它的用途即可。
3. vmap/vunmap分析
3.1 vmap
vmap函数,完成的工作是,在vmalloc虚拟地址空间中找到一个空闲区域,然后将page页面数组对应的物理内存映射到该区域,最终返回映射的虚拟起始地址。
整体流程如下:
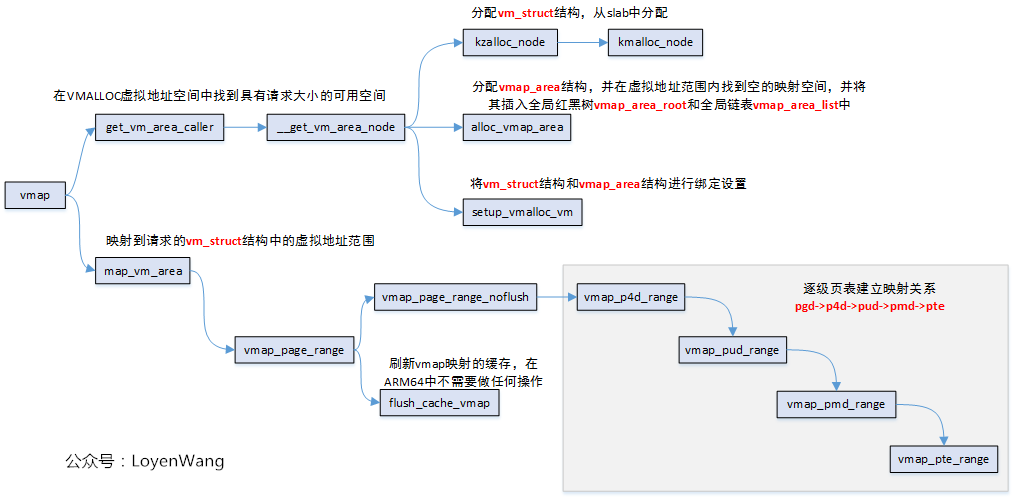
操作流程比较简单,来一个样例分析,就清晰明了了:

vmap调用中,关键函数为alloc_vmap_area,它先通过vmap_area_root二叉树来查找第一个区域first vm_area,然后根据这个first vm_area去查找vmap_area_list链表中满足大小的空间区域。
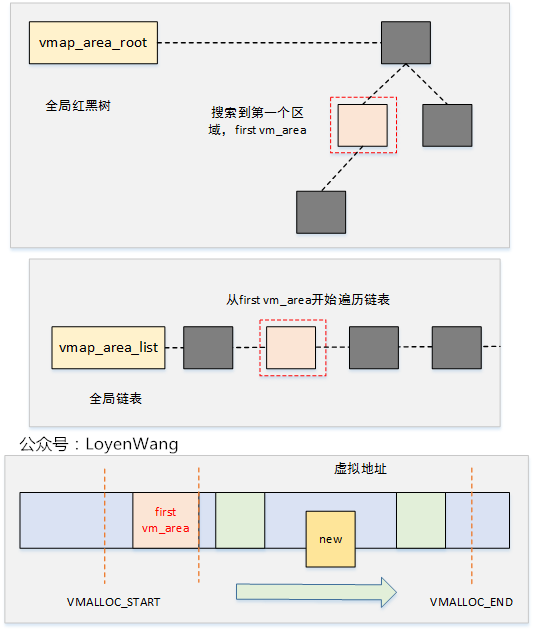
在alloc_vmap_area函数中,有几个全局的变量:
static struct rb_node *free_vmap_cache;
static unsigned long cached_hole_size;
static unsigned long cached_vstart;
static unsigned long cached_align;
用于缓存上一次分配成功的vmap_area,其中cached_hole_size用于记录缓存vmap_area对应区域之前的空洞的大小。缓存机制当然也是为了提高分配的效率。
3.2 vunmap
vunmap执行的是跟vmap相反的过程:从vmap_area_root/vmap_area_list中查找vmap_area区域,取消页表映射,再从vmap_area_root/vmap_area_list中删除掉vmap_area,页面返还给伙伴系统等。由于映射关系有改动,因此还需要进行TLB的刷新,频繁的TLB刷新会降低性能,因此将其延迟进行处理,因此称为lazy tlb。
来看看逆过程的流程:

4. vmalloc/vfree分析
4.1 vmalloc
vmalloc用于分配一个大的连续虚拟地址空间,该空间在物理上不连续的,因此也就不能用作DMA缓冲区。vmalloc分配的线性地址区域,在文章开头的图片中也描述了:VMALLOC_START ~ VMALLOC_END。
直接分析调用流程:
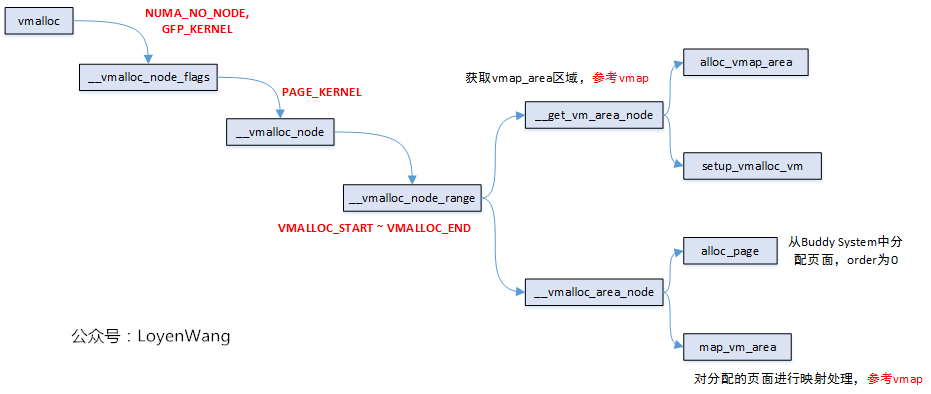
从过程中可以看出,vmalloc和vmap的操作,大部分的逻辑操作是一样的,比如从VMALLOC_START ~ VMALLOC_END区域之间查找并分配vmap_area, 比如对虚拟地址和物理页框进行映射关系的建立。不同之处,在于vmap建立映射时,page是函数传入进来的,而vmalloc是通过调用alloc_page接口向Buddy System申请分配的。
vmalloc VS kmalloc
到现在,我们应该能清楚vmalloc和kmalloc的差异了吧,kmalloc会根据申请的大小来选择基于slub分配器或者基于Buddy System来申请连续的物理内存。而vmalloc则是通过alloc_page申请order = 0的页面,再映射到连续的虚拟空间中,物理地址不连续,此外vmalloc可以休眠,不应在中断处理程序中使用。
与vmalloc相比,kmalloc使用ZONE_DMA和ZONE_NORMAL空间,性能更快,缺点是连续物理内存空间的分配容易带来碎片问题,让碎片的管理变得困难。
4.2 vfree
直接上代码:
void vfree(const void *addr)
{
BUG_ON(in_nmi());
kmemleak_free(addr);
if (!addr)
return;
if (unlikely(in_interrupt()))
__vfree_deferred(addr);
else
__vunmap(addr, 1);
}
如果在中断上下文中,则推迟释放,否则直接调用__vunmap,所以它的逻辑基本和vunmap一致,不再赘述了。
