/**
* 使用Java API操作HDFS文件系统
* 关键点:
* 1)创建 Configuration
* 2)获取 FileSystem
* 3)...剩下的就是 HDFS API的操作了
*/
先上代码
1 public class HDFSApp { 2 public static void main(String[] args) throws Exception { 3 Configuration configuration = new Configuration(); 4 5 FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop000:8020"),configuration,"hadoop"); 6 7 Path path = new Path("/hdfsapi/test"); 8 boolean result = fileSystem.mkdirs(path); 9 System.out.println(result); 10 } 11 }
对于方法的源码是我们在学习的时候必须的,我们可以按住Ctrl然后点击对应的方法类名进去进行源码的下载。
首先要对HDFS进行操作我们就必须获取FileSystem,
Ctrl点进FileSystem源码,我们能看到最顶部的注释介绍(附上了中文翻译):
1 /**************************************************************** 2 * An abstract base class for a fairly generic filesystem. It 3 * may be implemented as a distributed filesystem, or as a "local" 4 * one that reflects the locally-connected disk. The local version 5 * exists for small Hadoop instances and for testing. 6 * 7 * <p> 8 * 9 * All user code that may potentially use the Hadoop Distributed 10 * File System should be written to use a FileSystem object. The 11 * Hadoop DFS is a multi-machine system that appears as a single 12 * disk. It's useful because of its fault tolerance and potentially 13 * very large capacity. 14 * 15 * <p> 16 * The local implementation is {@link LocalFileSystem} and distributed 17 * implementation is DistributedFileSystem. 18 *****************************************************************/ 19 /********************************************** 20 21 *一个相当通用的文件系统的抽象基类。它可以实现为分布式文件系统,也可以实现为“本地” 22 *反映本地连接磁盘的磁盘。本地版本 23 *存在于小型Hadoop实例和测试中。 24 *所有可能使用Hadoop分布式的用户代码 25 *应该写入文件系统以使用文件系统对象。这个Hadoop DFS是一个多机系统,显示为单个磁盘。它是有用的,因为它的容错性和潜在的容量很大。 26 *< P> 27 *本地实现是@link localfilesystem和分布式的 28 *实现是分布式文件系统。 29 ***********************************************/
写作的开门见山,第一句话能够概括全文中心---> 这是 一个相当通用的文件系统的抽象基类。,所以我们使用Java API操作HDFS文件系统需要获取FileSystem。
使用FileSystem的get方法获取fileSystem,FileSystem有三种get方法:

不知道怎么用?哪里不会Ctrl点哪里!
首先看只有一个参数的get方法:get(Configuration conf):
1 /** 2 * Returns the configured filesystem implementation. 3 * @param conf the configuration to use 4 */ 5 /** 6 *返回配置的文件系统实现。 7 *@参数conf 要使用的配置 8 */ 9 public static FileSystem get(Configuration conf) throws IOException { 10 return get(getDefaultUri(conf), conf); 11 }
从源码的介绍中可以知道 Configuration 是某种配置,具体是什么?Ctrl点一点:
Provides access to configuration parameters.//提供对配置参数的访问。
源码中configuration的注释介绍第一句已经介绍了这是对配置参数的访问,所以,使用Java API操作HDFS文件系统需要创建configuration:Configuration configuration = new Configuration();
跳过两个参数的get方法,我们来看包含三个参数的get方法,Ctrl 点进去:
1 /** 2 * Get a filesystem instance based on the uri, the passed 3 * configuration and the user 4 * @param uri of the filesystem 5 * @param conf the configuration to use 6 * @param user to perform the get as 7 * @return the filesystem instance 8 * @throws IOException 9 * @throws InterruptedException 10 */ 11 /** 12 *获取基于URI的文件系统实例,配置和用户 13 *@参数uri 文件系统的uri 14 *@参数conf 要使用的配置 15 *@参数user 要执行get as的用户 16 *@返回文件系统实例 17 *@引发IOException 18 *@引发InterruptedException 19 */ 20 public static FileSystem get(final URI uri, final Configuration conf, 21 final String user) throws IOException, InterruptedException { 22 String ticketCachePath = 23 conf.get(CommonConfigurationKeys.KERBEROS_TICKET_CACHE_PATH); 24 UserGroupInformation ugi = 25 UserGroupInformation.getBestUGI(ticketCachePath, user); 26 return ugi.doAs(new PrivilegedExceptionAction<FileSystem>() { 27 @Override 28 public FileSystem run() throws IOException { 29 return get(uri, conf); 30 } 31 }); 32 }
重点看方法上面的注释,介绍了方法的功能、参数解释、返回值以及可能引发的异常。
我们要对HDFS操作,是不是需要知道我们要对哪个HDFS操作(URI),是不是要指定用什么样的配置参数进行操作(configuration),是不是需要确认是用什么用户进行操作(user),这样我们才能够准确地使用正确的用户以及正确的配置访问正确的HDFS。
此时我们拿到的fileSystem已经是我们需要的fileSystem了,那么剩下的操作就是对HDFS API的操作了,例如我们创建一个文件夹:
使用fileSystem的mkdirs方法,mkdirs方法不知道怎么用?Ctrl点!
1 /** 2 * Call {@link #mkdirs(Path, FsPermission)} with default permission. 3 */ 4 public boolean mkdirs(Path f) throws IOException { 5 return mkdirs(f, FsPermission.getDirDefault()); 6 }
我们可以看到mkdir方法接收的参数是一个Path路径,返回值是boolean类型判断是否创建成功,所以我们可以写:
Path path = new Path("/hdfsapi/test");//创建一个Path
boolean result = fileSystem.mkdirs(path);
System.out.println(result);//输出result查看是否创建成功
此时我们可以通过终端控制台进行查看文件夹是否创建成功:


当然也可以通过浏览器查看是否创建成功:输入 地址IP:50070 回车, 例如 192.168.42.110:50070 回车,
进去点击Utilities下拉列表的Browse the fiel system,点Go!就能看到:

点进去hdfsapi:
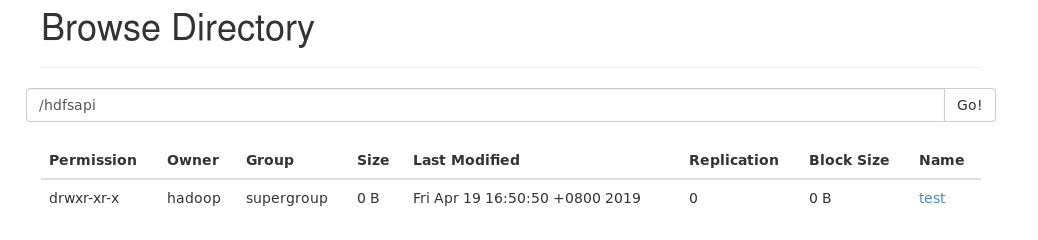
操作成功。