含义:也就是除了最小生成树之外再选一个最小的生成树,可以用最小生成树的一些边,但是不能完全相同
思路: 最容易想到的是先求出最小生成树,然后去枚举最小生成树中的边,把它标记,然后再去建最小生成树,然后取最小就能得到次小生成树,但是这样的复杂度是O(n^3)的
所以我们不推荐使用,
我们还有一种更巧妙的方法,复杂度是O(n^2+m),
思想就是我们先用个dp数组求出最小生成树中每两点间的路中的最长那条边的权值,然后我们依次去枚举所有没有被最小生成树用到的边,把这两点间的最长删了再加上新加入的那条边,然后最后算出来的最小值就是次小生成树的值
这里给出克鲁斯卡尔的次小生成树 POJ 1679(判断最小生成树是否唯一)
下面标记位置了的代码下面会一 一解释
#include<cstdio> #include<cstring> #include<algorithm> #include<cmath> #include<iostream> #include<string> #include<vector> #include<map> #include<queue> #include<stack> #define mod 1000000007 #define eps 1e-6 using namespace std; typedef long long ll; struct sss { int x,y,z,vis; }a[10001]; int n,m; vector<int> mp[101]; int pre[101]; int mx[101][101]; int find(int x) { if(x==pre[x]) return x; else return pre[x]=find(pre[x]); } int cmp(struct sss x,struct sss y) { return x.z<y.z; } void krlus() { sort(a+1,a+m+1,cmp); for(int i=1;i<=n;i++){ pre[i]=i; mp[i].clear(); mp[i].push_back(i);// 标记行 } long long sum=0; for(int i=1;i<=m;i++){ int xx=find(a[i].x); int yy=find(a[i].y); if(xx!=yy) { int len1=mp[xx].size(); int len2=mp[yy].size(); for(int j=0;j<len1;j++){ // 标记行 for(int k=0;k<len2;k++) mx[mp[xx][j]][mp[yy][k]]=mx[mp[yy][k]][mp[xx][j]]=a[i].z; } sum+=a[i].z; a[i].vis=1; pre[xx]=yy; for(int j=0;j<len1;j++){ //标记行 mp[yy].push_back(mp[xx][j]); } } } long long csum=99999999; for(int i=1;i<=m;i++){ if(!a[i].vis) csum=min(csum,sum+a[i].z-mx[a[i].x][a[i].y]); //标记行 } //cout<<sum<<" "<<csum<<endl; if(csum==sum) printf("Not Unique! "); else printf("%lld ",sum); } int main() { int t; cin>>t; while(t--) { cin>>n>>m; for(int i=1;i<=m;i++){ cin>>a[i].x>>a[i].y>>a[i].z; a[i].vis=0; } krlus(); } }
首先克鲁斯卡尔的权值是依次递增的,所以也创建了一些方便的条件
for(int j=0;j<len1;j++){
for(int k=0;k<len2;k++)
mx[mp[xx][j]][mp[yy][k]]=mx[mp[yy][k]][mp[xx][j]]=a[i].z;
}
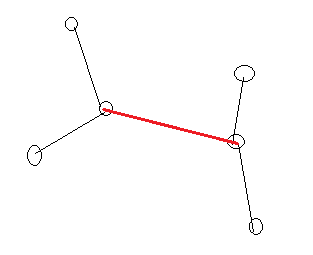
红色边是新加的那条边,我们每加入一条边的时候,我们就要对新加的那条边的两个端点各自的联通块里进行更新
左联通快的每个点都要与右联通快的每个点更新到,更新的最大值就是新加的那条边的权值,因为克鲁斯卡尔权值是按从小到大来的,
所以我们不需要判断,
因为最开始每个联通块就是自己
mp[i].push_back(i);
所以开始要加入本身
for(int i=1;i<=m;i++){
if(!a[i].vis)
csum=min(csum,sum+a[i].z-mx[a[i].x][a[i].y]);
}
这个其实也就是合并联通快,因为克鲁斯卡尔本身也是基于并查集的
csum=min(csum,sum+a[i].z-mx[a[i].x][a[i].y])
这个也就是我们枚举每一条边去看权值是否能更小