在数据预处理中,我们需要采集前的数据是非常庞大的。不妨将数据集D视作一个矩阵,每一行对应一个样本,每一列对应某个特征。
而在现实生活中,例如文档分类任务,以每一个字词作为一个特征,特征属性多大成千上万,即数千数万列,而相当一部分特征对于所考虑的问题具有“稀疏性”,也就是矩阵中许多列与当前学习任务无关。这一部分涉及到了特征降维等知识。
在此之前,由于属性的繁多,并不是每一个样本都具有所有属性。矩阵的每一行都将充斥着相当一部分零元素。当样本具有这样的稀疏性时,对学习任务会有不少的好处!例如,线性支持向量机之所以能在文字处理上有良好的性能,恰是由于文本数据在使用字频时具有高度的稀疏性,使得大部分问题都线性可分。而为了存储的高效性,必须了解一些稀疏矩阵的存储方法。
一、Coordinate(COO)

图一、Coordinate存储方式示例
这是最简单的存储格式,每一个元素需要一个三元组来表示,分别是 行号、 列号 以及 数值。这种方式简单易理解,但是空间不是最优的。
二、Compressed Sparse Row(CSR)
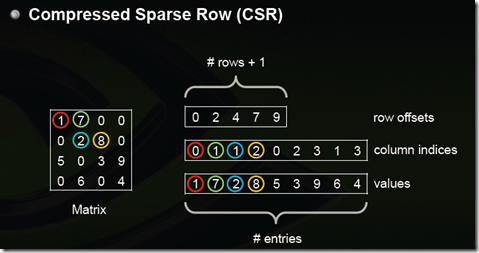
图二、Compressed Sparse Row存储方式示例一
CSR不是三元组,而是整体的编码方式。数值values和列号column indices与COO一致,表示一个元素以及其列号。行偏移row offsets表示某一行的第一个元素在数值values里面的起始偏移位置。如上图,行偏移长度为rows+1 (最后一个元素为矩阵内的样本总数,本例中为9)。设 i 表示第i行(矩阵索引号),i= 0, 1 , …… ,n ,当前行元素个数为num_i,则
num_i = rowoffsets[ i + 1 ]-rowoffsets[ i ]。
如第0行元素个数为2 - 0 = 2;第3行有元素[6 4],即rowoffsets[4]- rowoffsets[3] = 9-7 = 2。
下面再看一个CSR的例子:
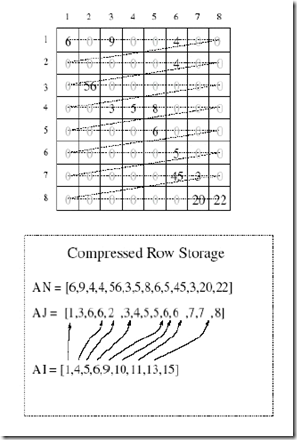
图三、Compressed Sparse Row存储方式示例二
Compressed Sparse Column(CSC) 是和CSR相对应的一种稀疏矩阵存储方式,即按列压缩的意思。一图二中CSR示例一矩阵为示范进行CSC存储:
Column Offsets:0 2 5 7 9
Row Indices: 0 2 0 1 3 1 2 2 3
Values: 1 5 7 2 6 8 3 9 4
三、ELLPACK(ELL)

图四、ELLPACK存储方式示例
ELLPACK用两个与原矩阵行相同的矩阵分别存储列号(column indices)和数值(values)。如果没有元素了可以用 * 代替。特别地,如果某一样本(特定一行)所包含的属性信息过多,会导致列号矩阵和数值矩阵变得异常的“胖”,其他行结尾存在许多 * 标记,浪费存储空间。
四、Hybrid(HYB) ELL+COO

图五、Hybrid存储方式示例
为了解决单独ELL存储时出现的:某一个样本(某一特定行)属性过多(非零元素过多)导致的存储空间浪费(补太多的符号 *),我们将ELL存储和COO存储结合。设定一个最大列数设定ELL存储时的数值矩阵和列号矩阵。将多余的元素再通过COO存储方式以三元组的方式进行存储。
五、Diagonal(DIA)

图六、Diagonal存储方式示例
顾名思义,对角线储存法以每一对角线的元素为对线,将其按列存入矩阵中。按照对角线方式存储时,存储矩阵的列代表对角线,行代表行。省略全零的对角线。
这里的行对应行,所以5 、6是分别在第三行第四行的,前面补上无效元素*。按照这种方式存储矩阵,如果源实矩阵就是一个对角性很好的矩阵那么压缩效率会非常高。比如图七的上图,而如果是随机矩阵的话(图七下图),效率会非常糟糕。
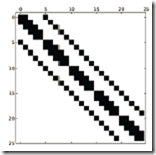
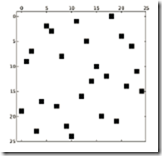
图七、Diagonal存储方式示意图

图八、存储方式实用性简单总结
选择稀疏矩阵存储格式的一些经验:
1. DIA和ELL格式在进行稀疏矩阵-矢量乘积(sparse matrix-vector products)时效率最高,所以它们是应用迭代法(如共轭梯度法)解稀疏线性系统最快的格式;
2. COO和CSR格式比起DIA和ELL来,更加灵活,易于操作;
3. ELL的优点是快速,而COO优点是灵活,二者结合后的HYB格式是一种不错的稀疏矩阵表示格式;
4. 根据Nathan Bell的工作,CSR格式在存储稀疏矩阵时非零元素平均使用的字节数(Bytes per Nonzero Entry)最为稳定(float类型约为8.5,double类型约为12.5),而DIA格式存储数据的非零元素平均使用的字节数与矩阵类型有较大关系,适合于StructuredMesh结构的稀疏矩阵(float类型约为4.05,double类型约为8.10),对于Unstructured Mesh以及Random Matrix,DIA格式使用的字节数是CSR格式的十几倍;
5. 从我使用过的一些线性代数计算库来说,COO格式常用于从文件中进行稀疏矩阵的读写,如matrix market即采用COO格式,而CSR格式常用于读入数据后进行稀疏矩阵计算。