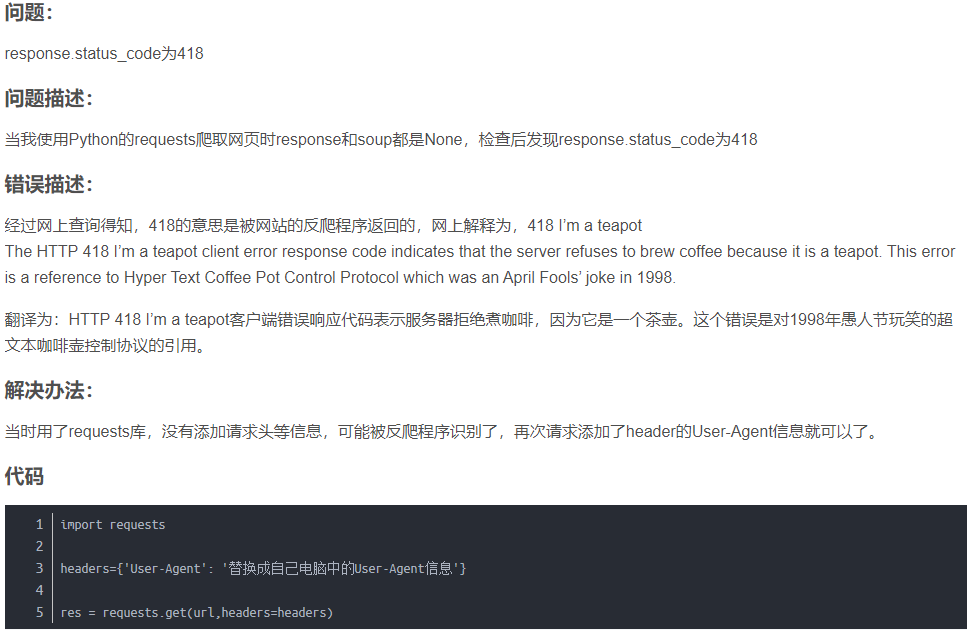
以上参考:https://blog.csdn.net/weixin_43902320/article/details/104342771
以下是自己的第一个爬虫小程序,虽然简单,但也值得记录下来:
import requests
import bs4
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/86.0.4240.198 Safari/537.36 QIHU 360EE'} #上一行内容由于太长了,用了换行符,但让也可以用三引号“”“ ”“”;
##此外,由于豆瓣用了反爬功能所以,要伪装成自己的真实浏览器,在浏览器地址栏输入:about:version,然后把显示出的用户代理后面的内容全部复制下来;
##放到headers中的User-Agent键对应的value中即可。
res = requests.get("https://movie.douban.com/top250",headers=headers)
# print(res)
soup = bs4.BeautifulSoup(res.text,"html.parser")
# print(soup)
targets = soup.find_all("div",class_="hd")
# print(targets)
for each in targets:
print(each.a.span.text)
输出:
肖申克的救赎
霸王别姬
阿甘正传
这个杀手不太冷
泰坦尼克号
美丽人生
千与千寻
辛德勒的名单
盗梦空间
忠犬八公的故事
星际穿越
楚门的世界
海上钢琴师
三傻大闹宝莱坞
机器人总动员
放牛班的春天
无间道
疯狂动物城
大话西游之大圣娶亲
熔炉
教父
当幸福来敲门
龙猫
怦然心动
控方证人
Process finished with exit code 0
因为此处的class和python中的关键字重复,所以在爬虫的python中用class_来代替,class_来表示hd的一个div
标签。然后把他们的标题都找出来,找出之后放到一个targets的列表中去。

所以,用for循环print(div.a.span.text)打印出来。#此处的div就是targets中的项。
当遇到Response [200]返回值问题时:
