课程:《程序设计与数据结构》
班级: 1723
姓名: 王禹涵
学号:20172323
实验教师:王志强
实验日期:2018年11月20日
必修/选修: 必修
1.实验内容
查找与排序-1
定义一个Searching和Sorting类,并在类中实现linearSearch(教材P162 ),SelectionSort方法(P169),最后完成测试。
要求不少于10个测试用例,提交测试用例设计情况(正常,异常,边界,正序,逆序),用例数据中要包含自己学号的后四位
提交运行结果图。
查找与排序-2
重构你的代码
把Sorting.java Searching.java放入 cn.edu.besti.cs1723.(姓名首字母+四位学号) 包中(例如:cn.edu.besti.cs1723.G2301)
把测试代码放test包中
重新编译,运行代码,提交编译,运行的截图(IDEA,命令行两种)
查找与排序-3
参考http://www.cnblogs.com/maybe2030/p/4715035.html 在Searching中补充查找算法并测试
提交运行结果截图
查找与排序-4
补充实现课上讲过的排序方法:希尔排序,堆排序,二叉树排序等(至少3个)
测试实现的算法(正常,异常,边界)
提交运行结果截图
查找与排序-5
编写Android程序对各种查找与排序算法进行测试
提交运行结果截图
推送代码到码云
2. 实验过程及结果
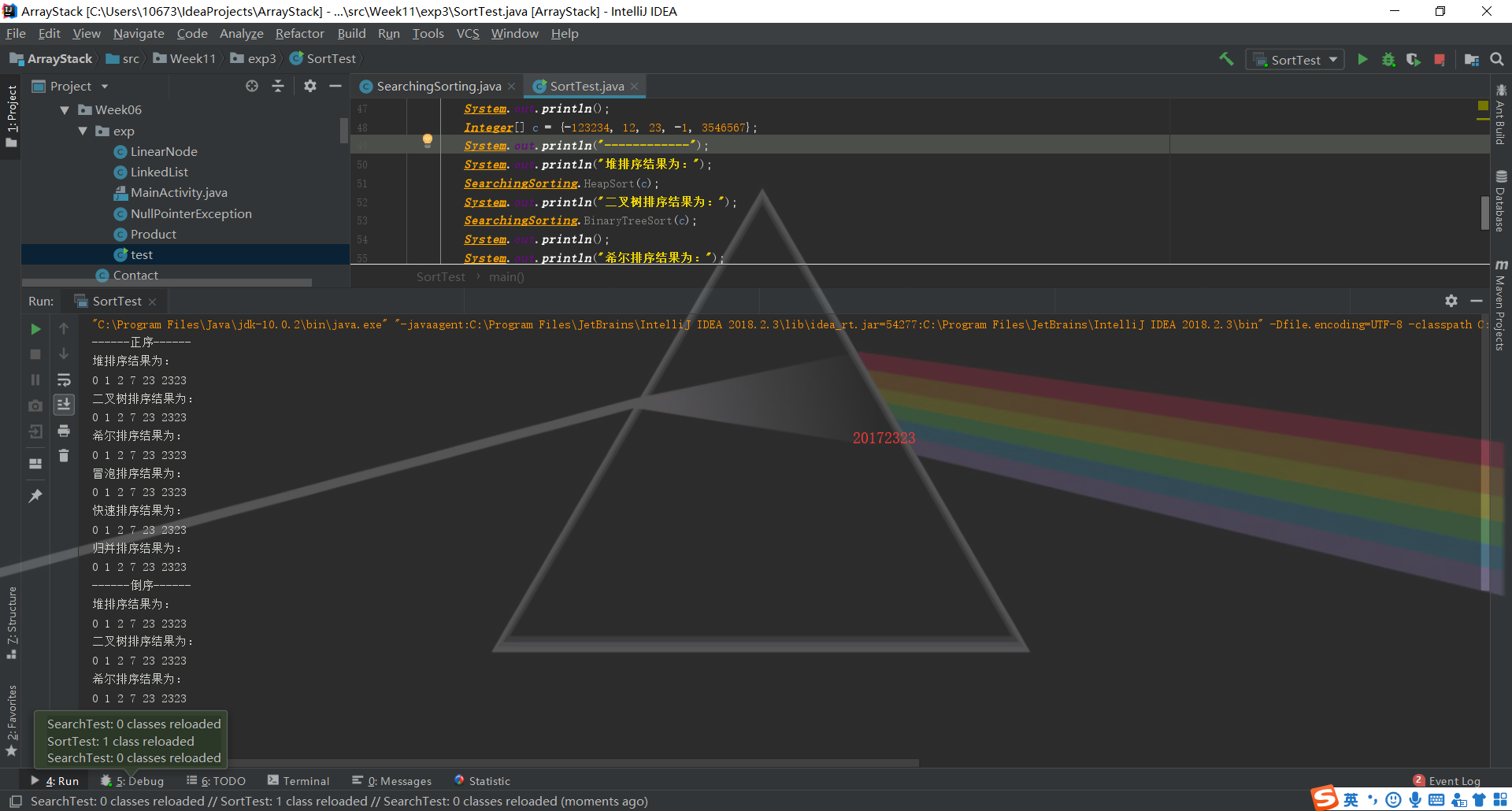
查找与排序-1
- 第一部分代码类不太难,直接书上的代码copy一下子就好了。难点在于测试类的编写,JUnit测试确实是很久没有写过了,但是依葫芦画瓢还是差不多解决了
测试时需要考虑题目要求的正常,异常,边界,正序,逆序五种情况,所以在数组的赋值上包含了正整数、负整数、小数和字母几种情况的数组。在查找和排序方面都测试了查找边界值和查找不存在的值,正序的一串数和逆序的一串数的排序。
测试结果如下
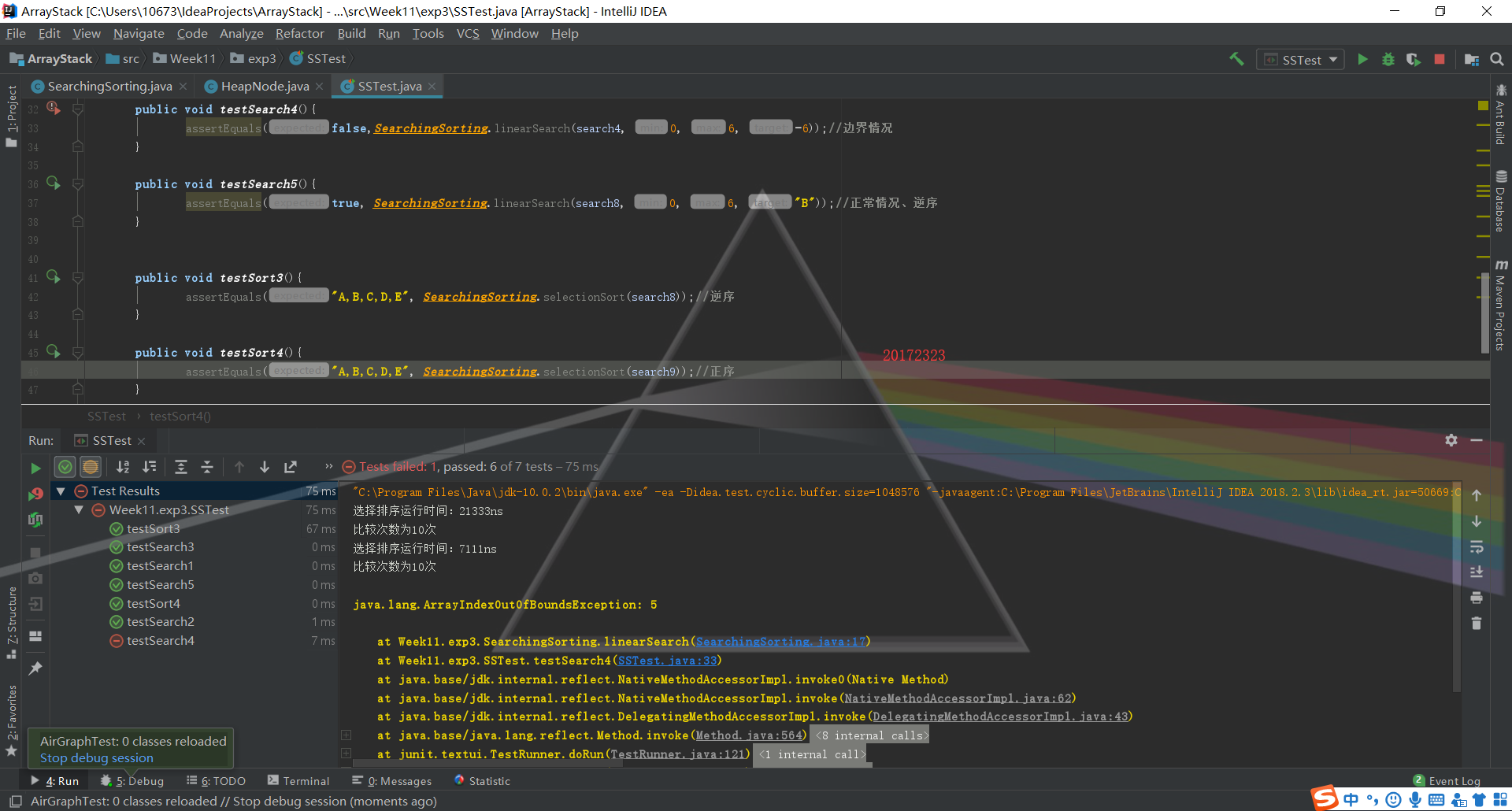
测试的代码(参照上学期的资源)
public void testSearch1() {
assertEquals(true, SearchingSorting.linearSearch(search1, 0, 6, 2323));
}
左下角反映了测试通过与否
查找与排序-2
第二部分看似简单,其实花费了我不少时间。
首先把代码类放在一个新的包内,另一个测试类其实应该放在专门的test包内,而不应该随便就在src下建一个test包,这点在单元测试的讲解中有提到过,即
test目录中放的也是Java代码,但IDEA不知道test中放的是源代码。在命令行中我们知道要设置
SOURCEPATH环境变量,在IDEA中我们右键单击test目录,在弹出的菜单中选择Mark Directory as->Test Sources Root就可以了
另一个在命令行上测试,我重写了测试方法,没有再用JUnit测试,因为多次使用cmd运行都提示找不到或无法加载主类,重写之后,找到编译文件所在的位置java SSTest1。特别奇怪的一个地方是,我只能在编译文件所在的包外运行该代码,如果是在包内又会报错。
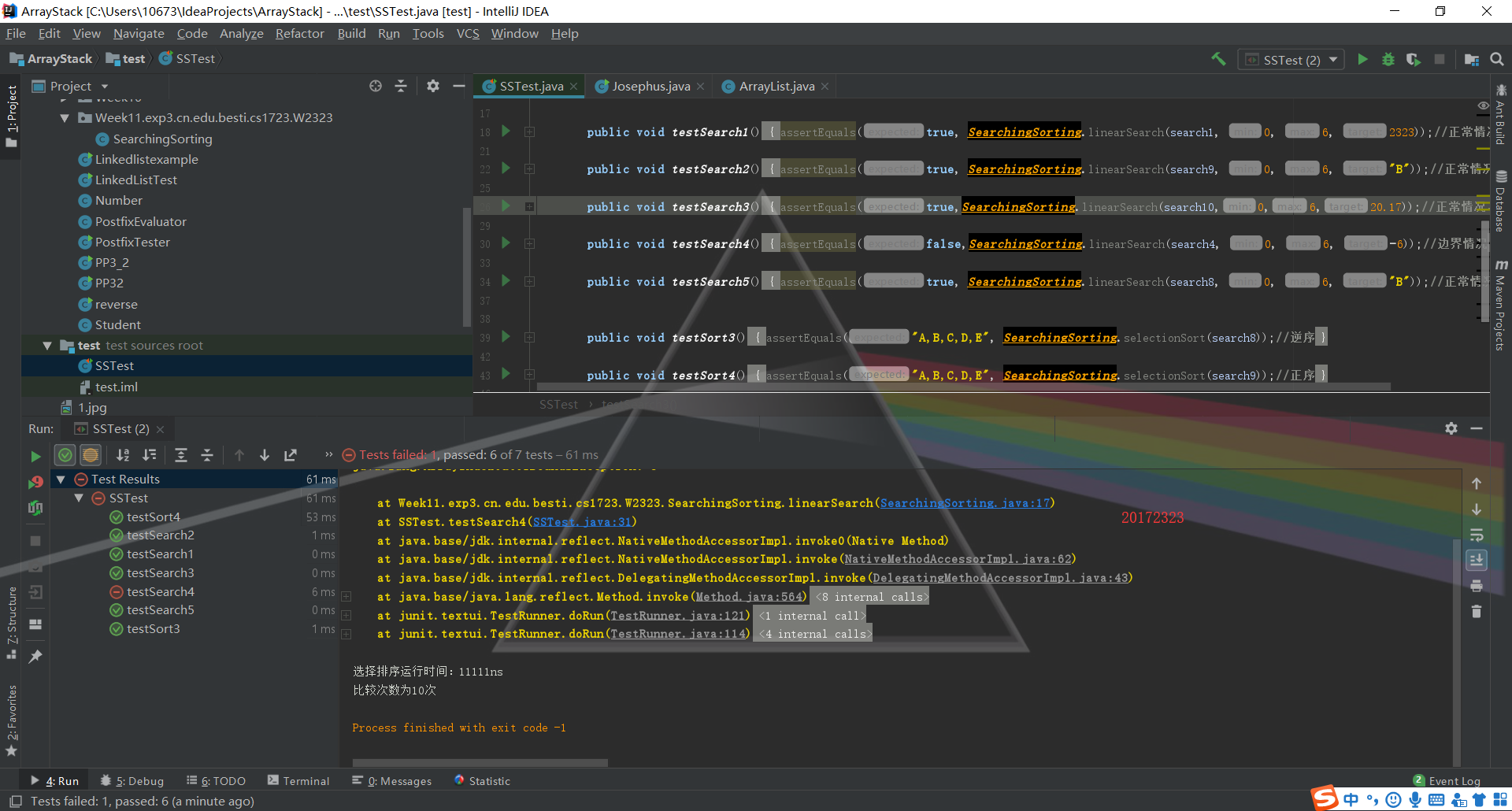
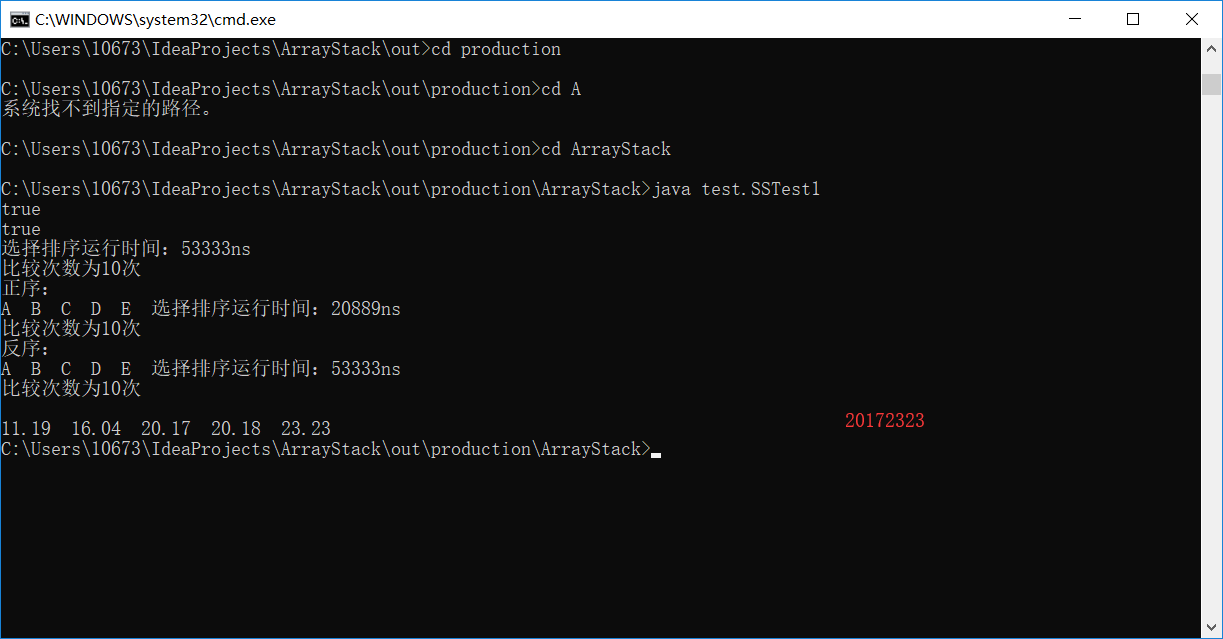
查找与排序-3
需要理解几种查找算法,这部分比较困难,但是需要自己做的地方不难,因为代码基本都给了出来。重点需要新学的是斐波拉契查找和插值查找
- [插值查找] 基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
代码分析
int InsertionSearch(int a[], int value, int low, int high)
{
int mid = low+(value-a[low])/(a[high]-a[low])*(high-low);
if(a[mid]==value)
return mid;
if(a[mid]>value)
return InsertionSearch(a, value, low, mid-1);
if(a[mid]<value)
return InsertionSearch(a, value, mid+1, high);
}
其他地方都和折半查找类似,主要是定位查找点的方法int mid = low+(value-a[low])/(a[high]-a[low])*(high-low);不好理解
- 因为插值查找适合分布较为均匀的数组,所以就假定有一个存储值1-20的数组,对应索引值分别为0~19.现在要查找2这个值,对应索引值为1,适合插值查找这种方法。此时
value = 2;
low = 0;
high = 19;
mid = 1;
此时a[mid] = a[1] = 2,就查找到了需要的元素。
我想这个算法的核心在于(high - low)反映了要查找的数组的长度,(value-a[low])/(a[high]-a[low])定位了查找点大致在数组几分之几的位置上(因为数组内的元素分布是比较均匀的)。
-
[斐波那契查找] 二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。
-
斐波那契查找与折半查找很相似,他是根据斐波那契序列的特点对有序表进行分割的。他要求开始表中记录的个数为某个斐波那契数小1,及n=F(k)-1;。
-
代码分析
写出这代码的核心思想是什么我还无法理解,只能跟着代码走一遍。首先他需要将数组内的元素复制到一个斐波那契数长度的数组中,多出来的位置全部填充原数组的最后一位。然后通过变换mid的值不断缩小查找的范围,如果查找值小于temp[mid]的值,说明待查找的元素在[low,mid-1]范围内,反之说明待查找的元素在[mid+1,high]范围内。这里刚好前面一部分与后面一部分的比值约为0.618,将数组扩展到F[k]-1长度也是出于此考虑,之后类似于二分查找不断缩小范围逼近查找值。但最后的值有可能在扩展的数组中,需要返回n-1(为什么最多只会找到扩展数组的第一个位置还没有弄明白)
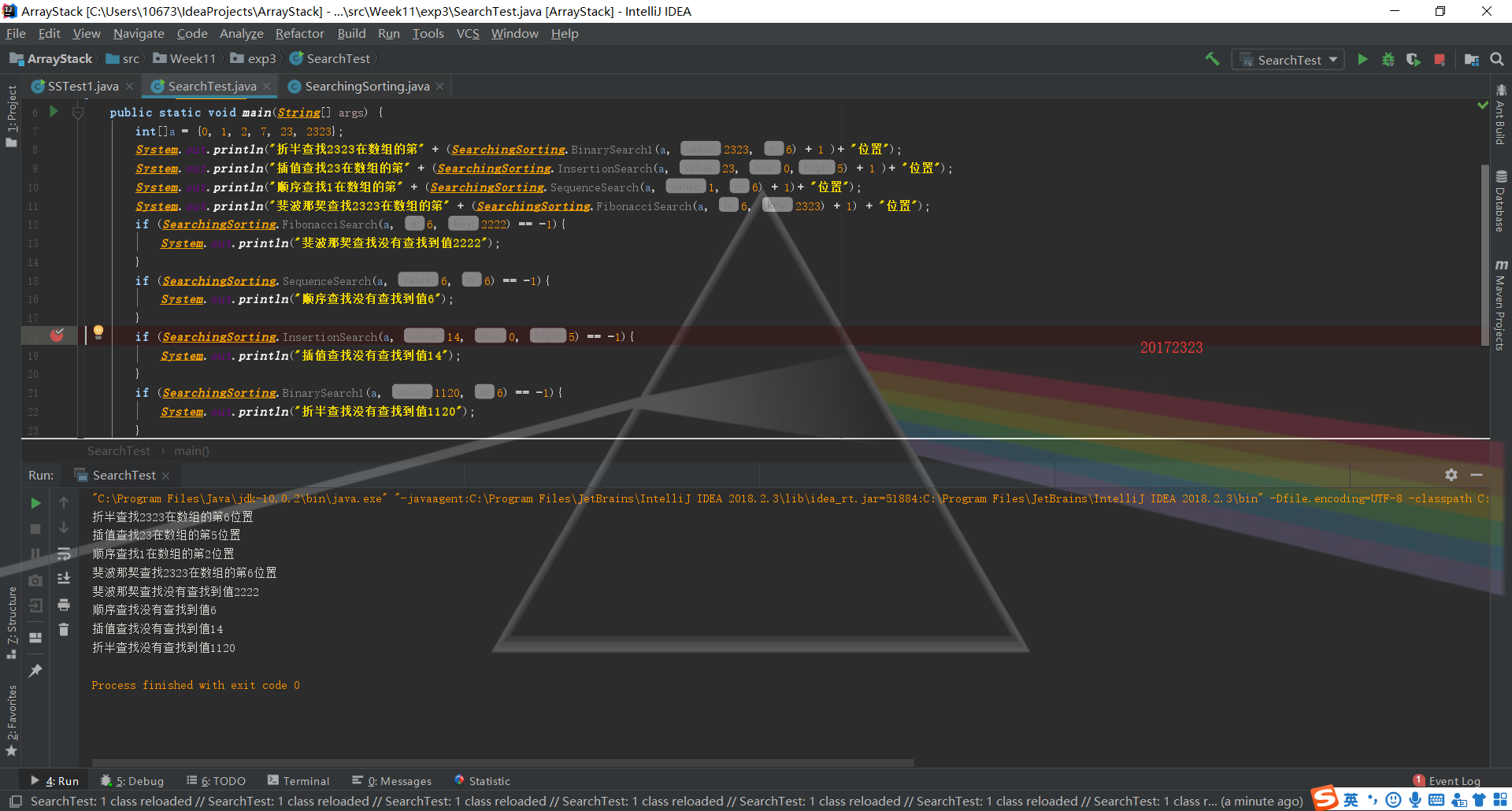
查找与排序-4
题目给出的三种排序算法,堆排序在之前的项目中已经有了实现的方法,二叉树排序也不困难,只需要将数组内的元素依次序添加进二叉树中,然后按照中序输出的方法也能达到排序的效果。主要是希尔排序没有遇到过
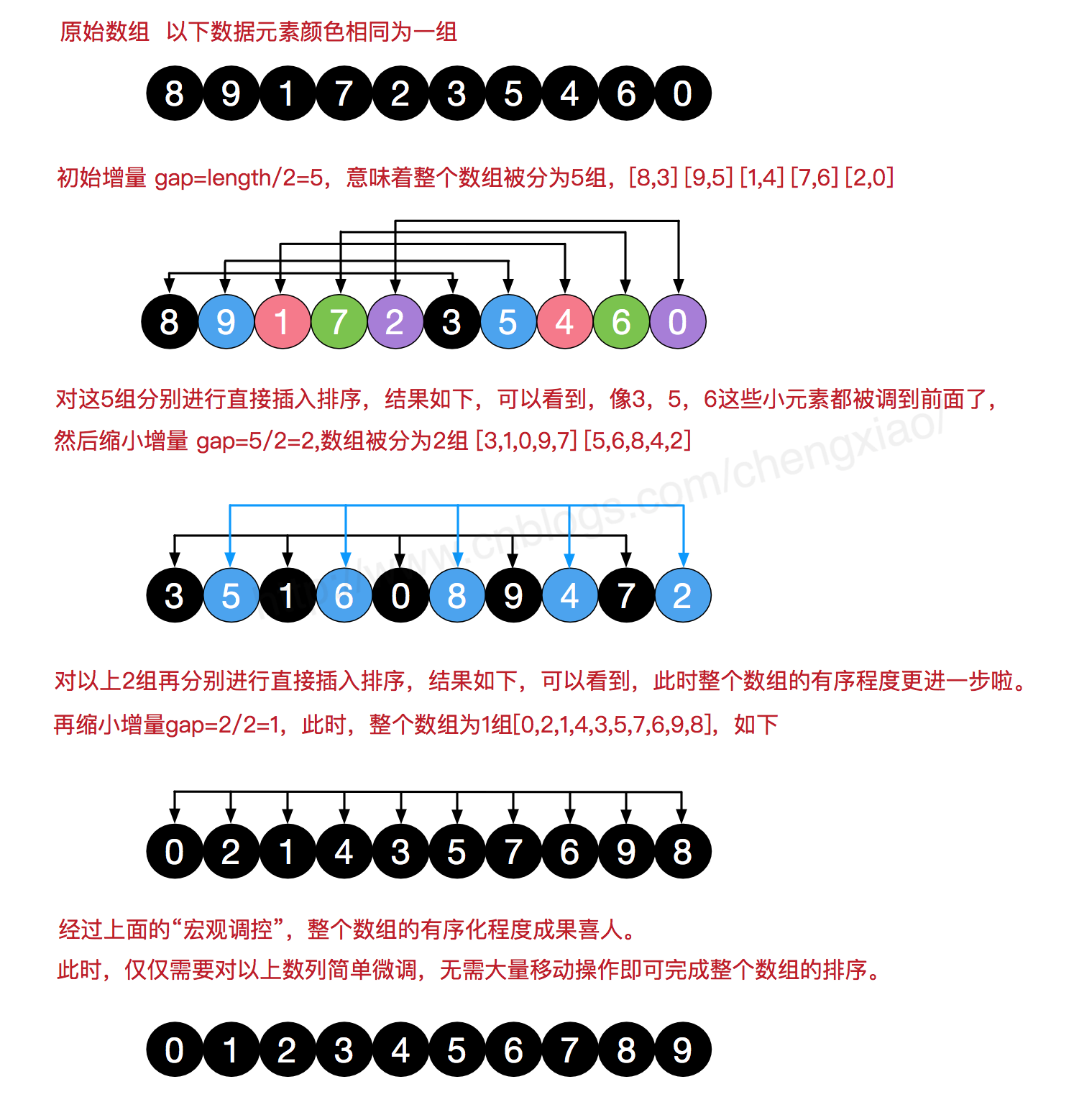
- 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
- 实例讲解,从网上找到的图示,比我瞎讲应该要有用得多
代码实现
public static void sort(Integer[] data){
if(data == null || data.length <= 1){
return;
}
//增量
int incrementNum = data.length/2;
while(incrementNum >=1){
for(int i=0;i<data.length;i++){
//进行插入排序
for(int j=i;j<data.length-incrementNum;j=j+incrementNum){
if(data[j]>data[j+incrementNum]){
int temple = data[j];
data[j] = data[j+incrementNum];
data[j+incrementNum] = temple;
}
}
}
//设置新的增量
incrementNum = incrementNum / 2;
}
String str = "";
for (int n = 0; n < data.length; n++){
str += data[n] + " ";
}
System.out.println(str);
}
从算法的实现可以看出,希尔排序是有些类似与间隔排序的,它通过设置增量,将相同间隔的元素放在一堆然后排好序,再将增量扩大,直至所有元素都在一个数组中且进行排序,这时即排序完成
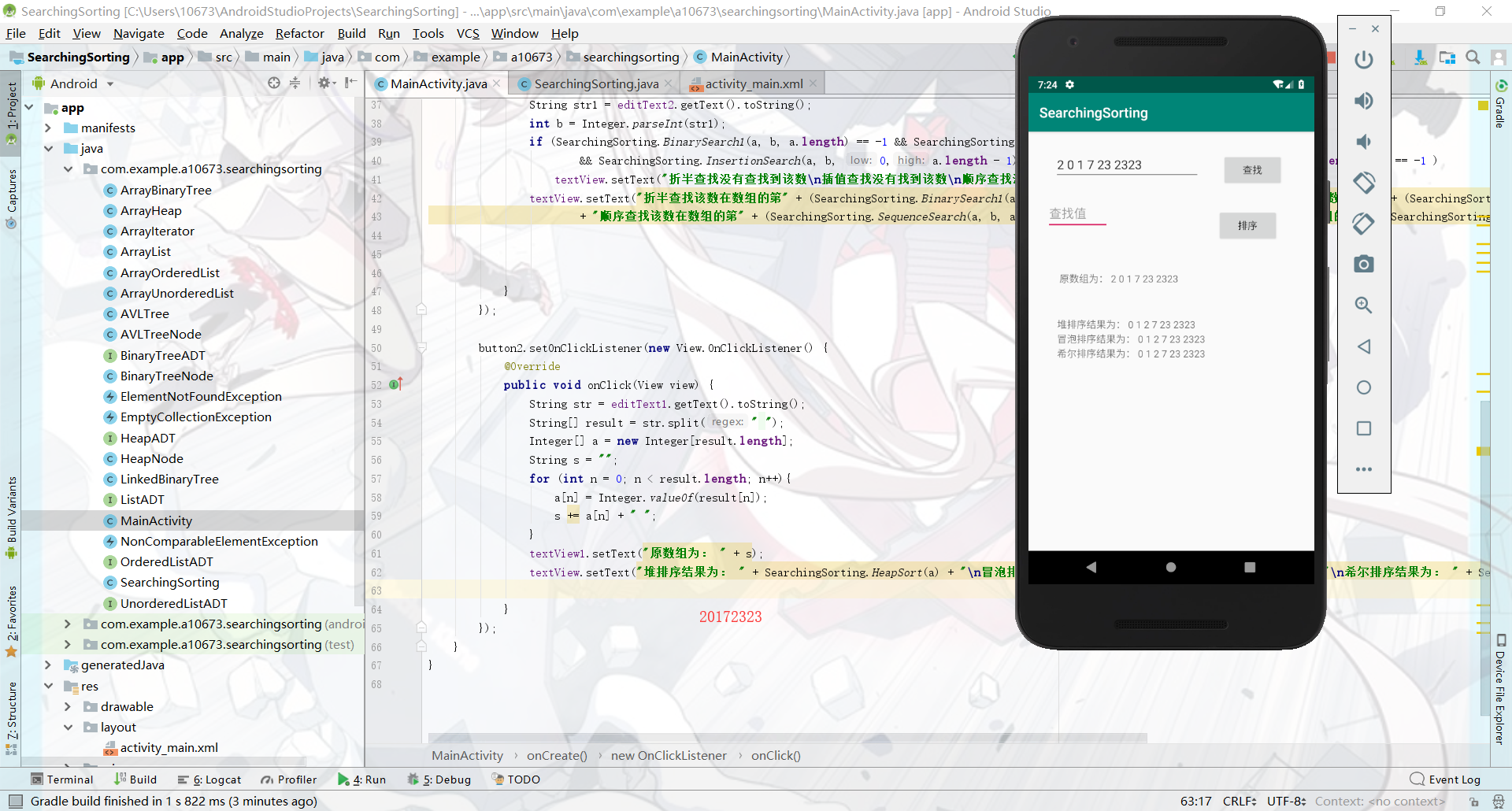
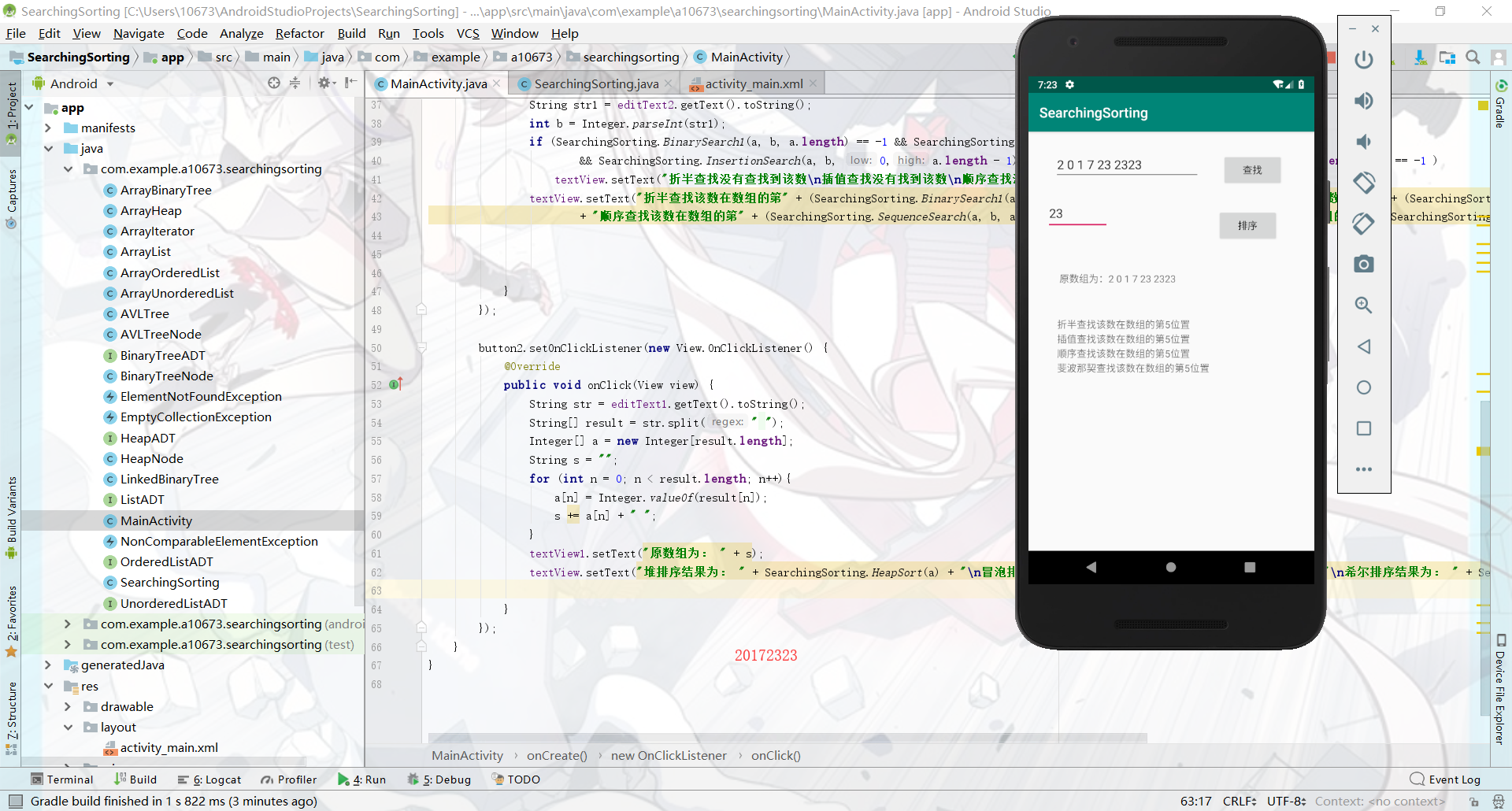
查找与排序-5
这部分还算比较简单,就把之前的代码移动到AS里,不过同时还需要移动一大堆的相关文件过去。我比较省事地只添加了两个按钮,一键就调用所有的排序或者查找方法。然后textview.setView()中输出一大堆返回信息,如图
3. 实验过程中遇到的问题和解决过程
问题1:进行插值查找时,查找一个数组中不存在的数,出现如下的错误
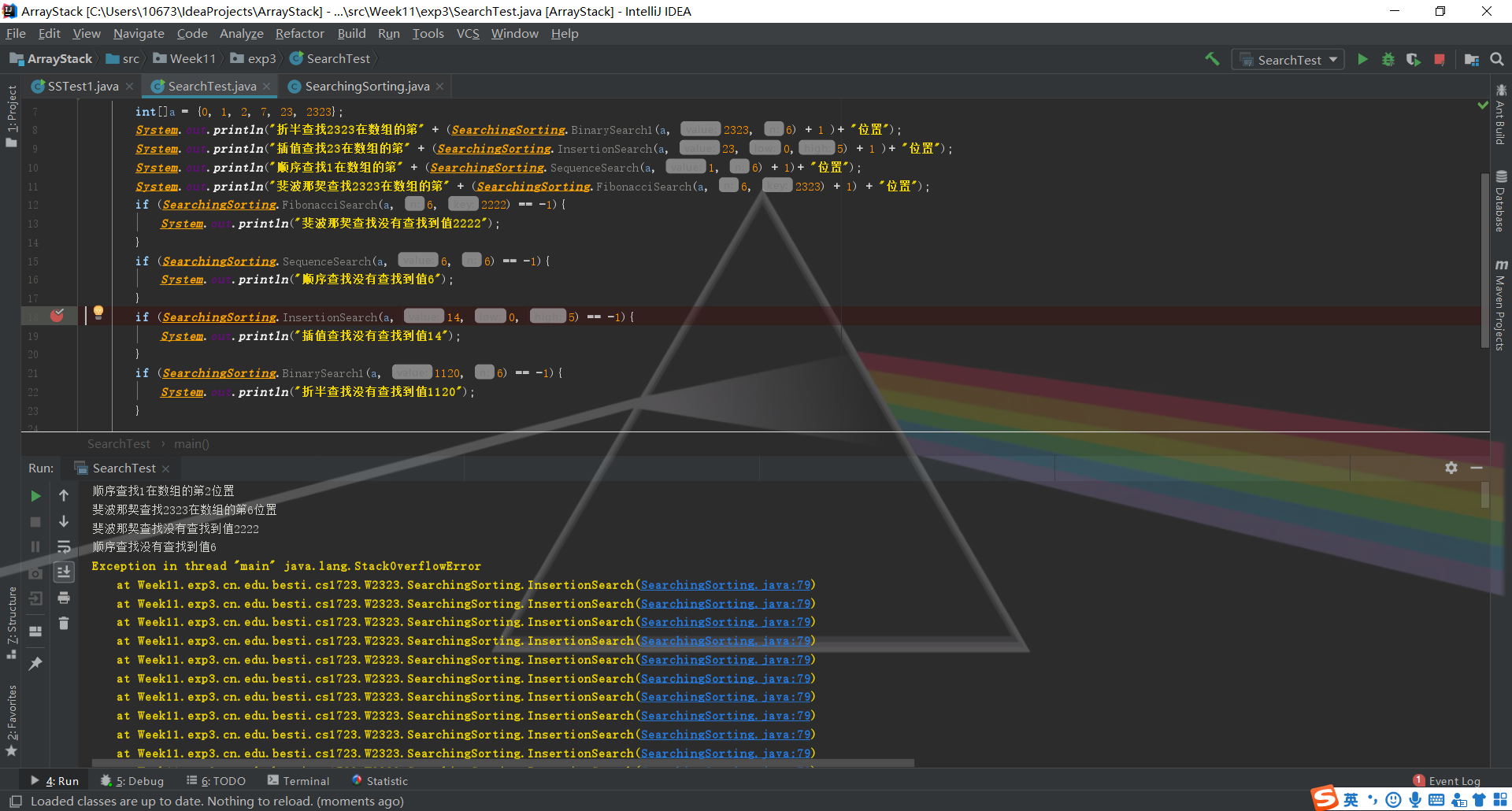
问题1解决方案:debug之后发现在进行分区域的时候,会出现low>high的情况,而程序没有能处理这种情况的能力。参照斐波那契查找代码中对于出现low>high情况的处理,在外部加上一个while循环,当出现low>high时,直接return -1这样一来错误情况就处理掉了。
问题2:int型与Interger型的区别
问题2解决方案:以前从来没有考虑到过这个问题(可能是没有认真学习的原因),总之到这次实验时才发觉他俩好像是有点小小的区别,因为第一部分的实验新创的数组都是Comparable型的,但后来因为实验需要有一些方法有需要转换成int型,所以数值的比较方法也需要大改。按理说data[min].compareTo(data[j]) > 0就需要改成data[min] > data[j]但是改成Interger型这些都不需要改变。所以查了一下他俩的一些区别
Integer 类和 int 的区别
①、Integer 是 int 包装类,int 是八大基本数据类型之一(byte,char,short,int,long,float,double,boolean)
②、Integer 是类,默认值为null,int是基本数据类型,默认值为0;
③、Integer 表示的是对象,用一个引用指向这个对象,而int是基本数据类型,直接存储数值。
Interger型相当于是一个包装盒,里面包含的是int型的对象,所以可以使用CompareTo的方法。
4.其他
这次实验相对来说理论的学习很重要,要优于自己动手写代码。通过这次实验,我对几种查找和排序算法都有了更深刻的了解,同时还了解了一些没有接触过的查找算法。比较意外的一个收获是,我对一些数据类型的了解也更加深刻了
5.参考资料
-
《Java程序设计与数据结构教程(第二版)》
-
《Java程序设计与数据结构教程(第二版)》学习指导