1.创建函数、查找函数
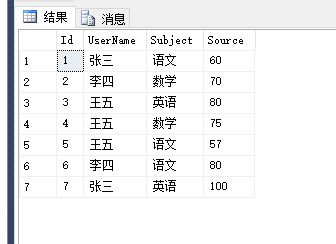
/*创建带参数的函数,返回单个*/ CREATE FUNCTION [dbo].[GETGrade](@userName nvarchar(10),@subject nvarchar(10)) returns nvarchar(10) as begin declare @grade nvarchar(10) if @userName='张三' set @grade=(select [source] from TestRows2Columns where username=@userName and [subject]=@subject) if @userName='李四' set @grade=(select [source] from TestRows2Columns where username=@userName and [subject]=@subject) if @userName='王五' set @grade=(select [source] from TestRows2Columns where username=@userName and [subject]=@subject) return @grade end
执行函数
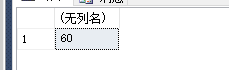
select dbo.GETGrade('张三','语文')
返回表函数
/*创建函数,返回表*/ CREATE FUNCTION GETGrade2(@userName nvarchar(10),@subject nvarchar(10)) RETURNS @TempTable TABLE(userName nvarchar(10),subject nvarchar(10),[Source] nvarchar(50)) AS BEGIN INSERT INTO @TempTable(userName,[subject],[Source]) SELECT [UserName],[Subject],[Source] from [TestRows2Columns] where username=@userName and [subject]=@subject RETURN END
执行函数
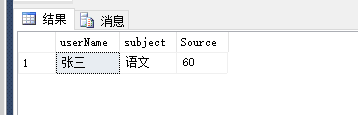
SELECT * from dbo.GETGrade2('张三','语文')
创建储存过程、查找储存过程
CREATE PROC P_View(@userName nvarchar(10),@subject nvarchar(10)) AS BEGIN SELECT * FROM TestRows2Columns where username=@userName and [subject]=@subject END
执行储存过程
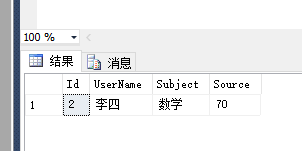
EXEC P_View '李四','数学'
本质上没区别。只是函数有如:只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行。执行的本质都一样。
函数限制比较多,比如不能用临时表,只能用表变量.还有一些函数都不可用等等.而存储过程的限制相对就比较少
1. 一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
2. 对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
3. 存储过程一般是作为一个独立的部分来执行(EXEC执行),而函数可以作为查询语句的一个部分来调用(SELECT调用),由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
4. 当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
Procedure cache中保存的是执行计划 (execution plan) ,当编译好之后就执行procedure cache中的execution plan,之后SQL SERVER会根据每个execution plan的实际情况来考虑是否要在cache中保存这个plan,评判的标准一个是这个execution plan可能被使用的频率;其次是生成这个plan的代价,也就是编译的耗时。保存在cache中的plan在下次执行时就不用再编译了。