利用kettle Spoon从oracle或mysql定时增量更新数据到Elasticsearch
https://blog.csdn.net/jin110502116/article/details/79690483
背景:
目前的业务数据数据已经很大了,关于查询内的需求比较多,传统数据库已经不能满足目前的需要。必须得使用全文检索了,了解了相关资料,发现Elasticsearch这个工具比较强大。于是就开始新一段的爬坑之旅了...
Elasticsearch安装什么的很方便,但是更新却是个很大的问题。开始尝试了Logstash这个工具,各种尝试后,还是放弃了。主要原因是速度慢,数据源是oracle数据库的时候,不能增量更新,生成的索引文档id各种问题,果断放弃...
后面尝试了Kettle spoon,换了n多个版本,都没有找到一个跟Elasticsearch兼容的比较好的版本。查了n多资料,发现没一个能够说清楚解决思路的。自己也想过放弃,但项目上有刚需,只得硬着头皮弄了。功夫不负有心人,终于成功了...
分享:
写在前面:第一篇博客,不喜勿喷哈。之前一直潜水,这次想奉献一下~
目的:将mysql或oracle里面的数据定时增量抽取到ES。
思路:利用spoon发送http post请求,然后获取索引中最大的时间,然后将数据库中查出大于该时间的记录,定时导入到ES即可。(还有一种常见的是,将每种类型的数据更新完后,存入到一张管理表总,下次抽取大于这个时间的)
工具下载链接:
Spoon 7.1修复版本:链接:https://pan.baidu.com/s/1bPAjMWt_ur7BqPI6zkkE4g 密码:v1li
Elasticsearch2.3.2 : 链接:https://pan.baidu.com/s/1FlyvCCSjEIqZJB1F59qkzg 密码:w49r
Elasticsearch-head : 链接:https://pan.baidu.com/s/1pCf9e-WH3N9b5JFSMFPpAg 密码:1959
方案步骤(举例):
1、新建索引,设置分片数,备份数
2、新建索引类型(举个例子)
注意:需要使用统计功能的字段类型不能设置为String
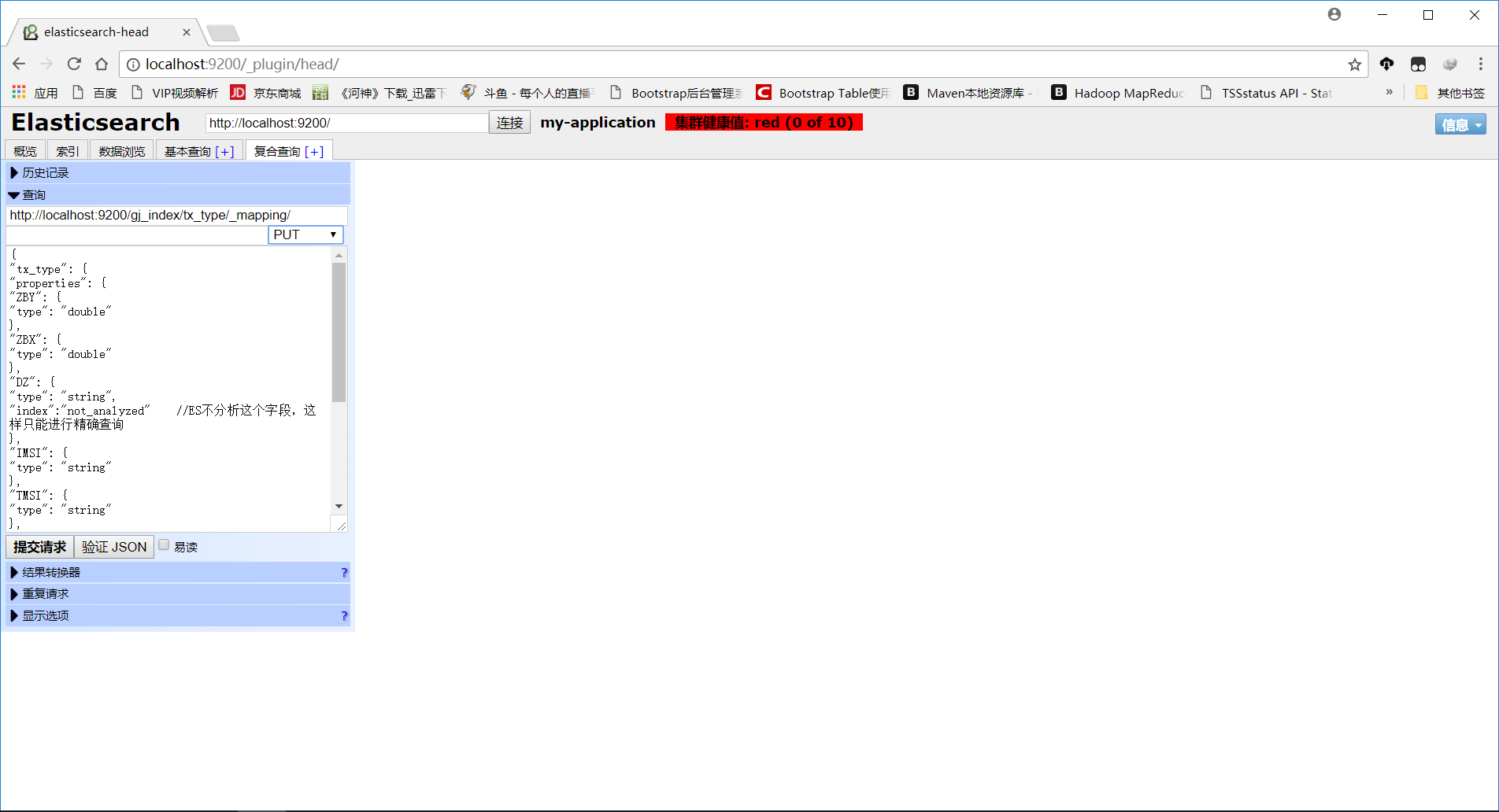
请求地址:http://localhost:9200/gj_index/tx_type/_mapping/
请求类型:put
请求参数:
{
"tx_type": {
"properties": {
"ZBY": {
"type": "double"
},
"ZBX": {
"type": "double"
},
"DZ": {
"type": "string",
"index":"not_analyzed" //ES不分析这个字段,这样只能进行精确查询
},
"IMSI": {
"type": "string"
},
"TMSI": {
"type": "string"
},
"IMEI": {
"type": "string"
},
"JLSJ": {
"type": "long" //时间戳,不能使用String,否则无法统计。这边转成了秒
},
"SBID": {
"type": "string"
},
"LAC": {
"type": "string"
}
}
}}
截图如下:
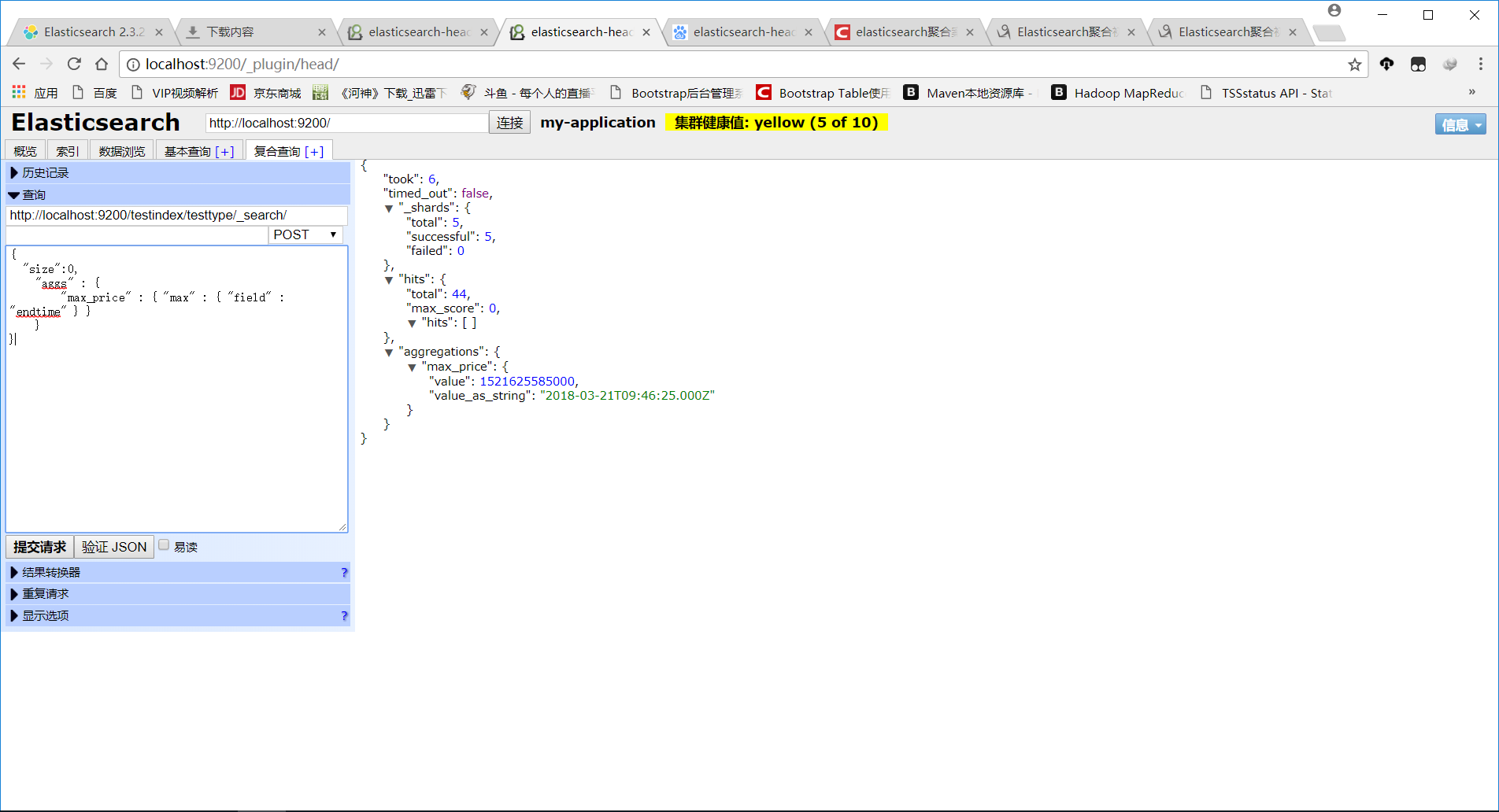
3、先模拟请求,找到索引中某类型(testtype)中最大的时间字段(endtime),如图所示:
4、新建Spoon转换、任务
获取到索引中最大的时间戳(模拟请求,获取该索引中endtime最大的那个值)
a、整体效果图:
b、设置请求参数
c、发送post请求
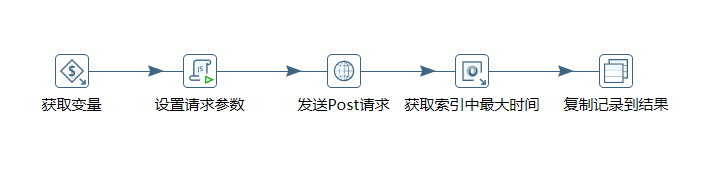
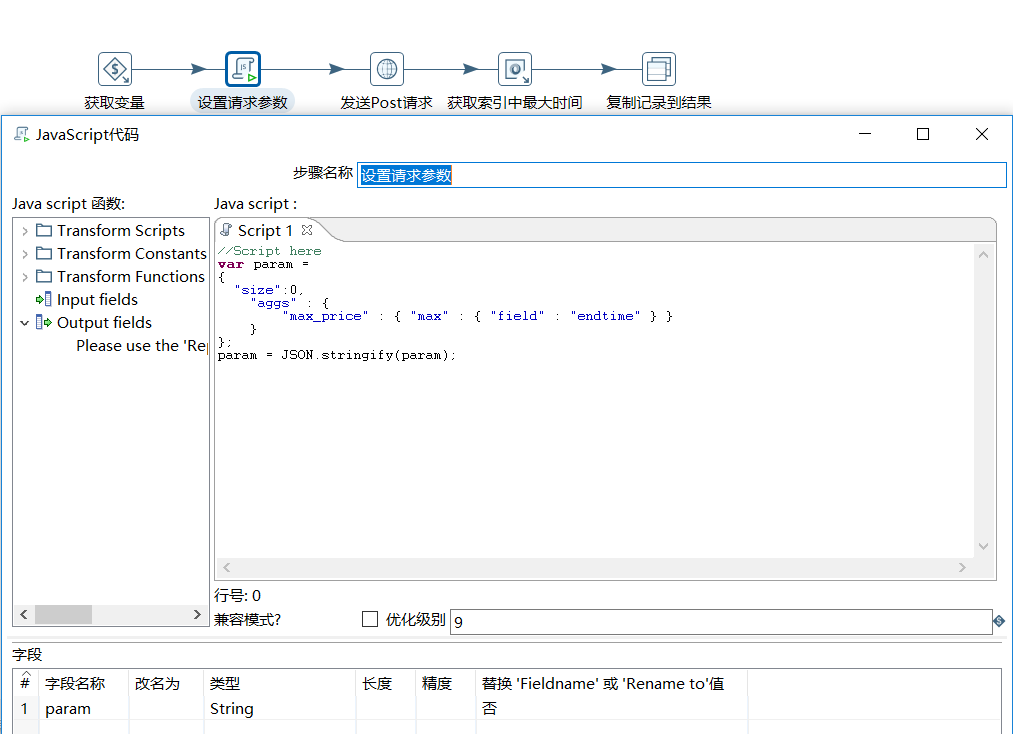
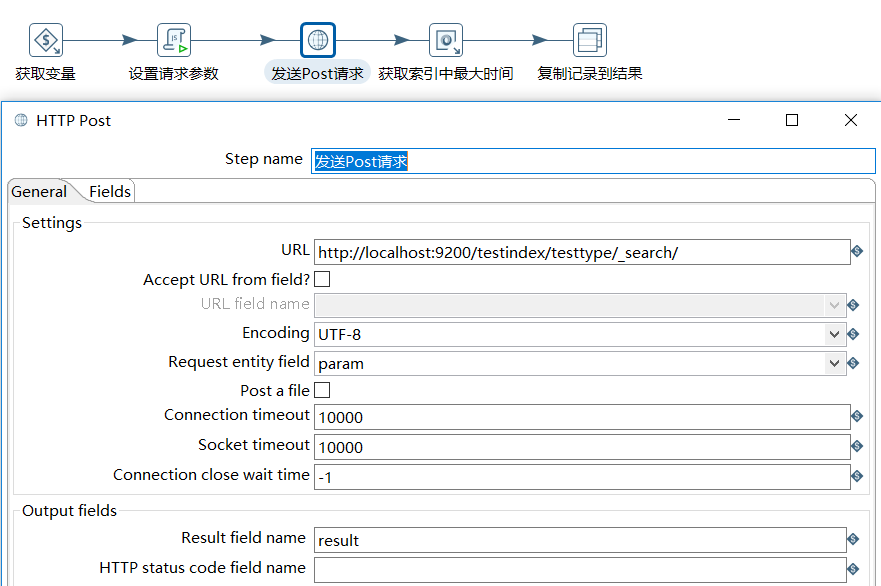
d、获取当前类型中最大的时间
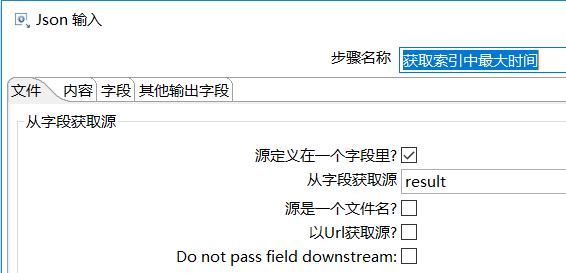
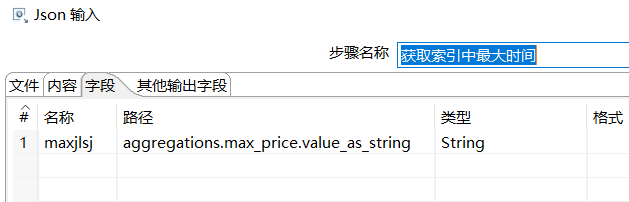
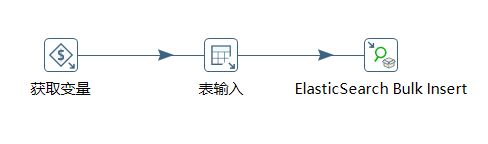
新建插入索引转换,将大于此时间的记录获取到,直接插入到ES中
a、整体效果图
b、表输入
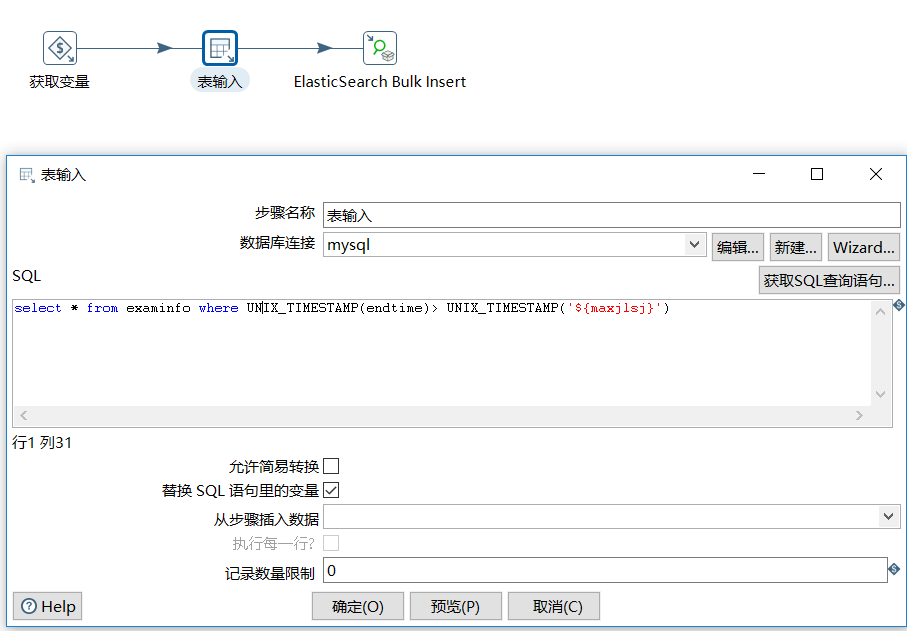

c、插入到索引
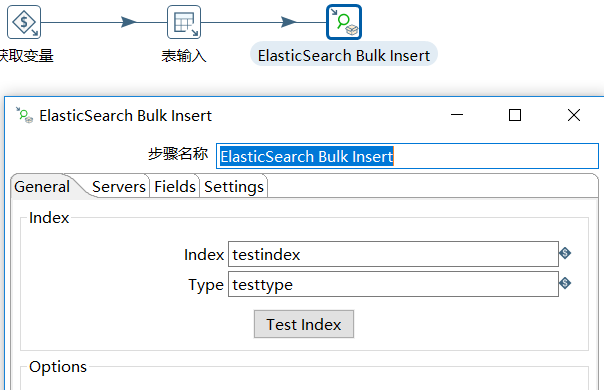
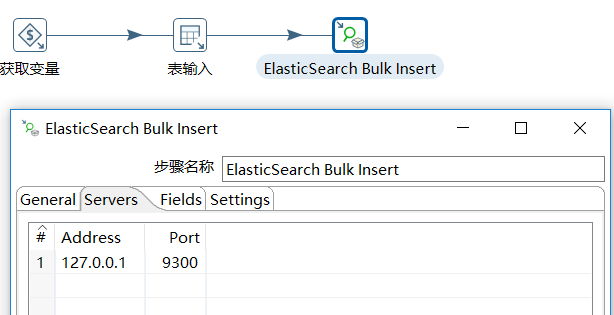
新建定时任务,定时增量抽取数据
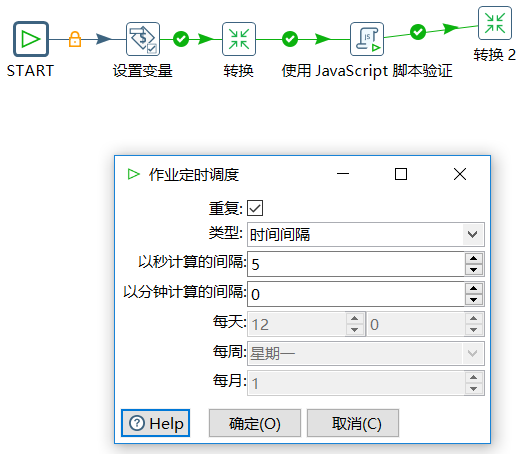
a、 每隔5秒执行一次增量更新任务
b、设置job变量 maxjlsl
c、添加转换(获取索引中最大时间)
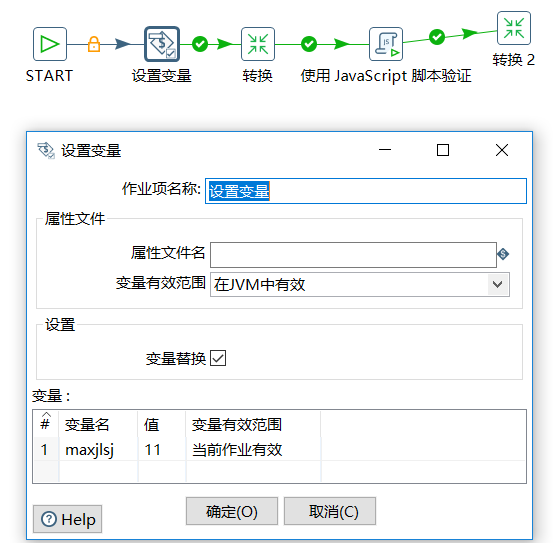
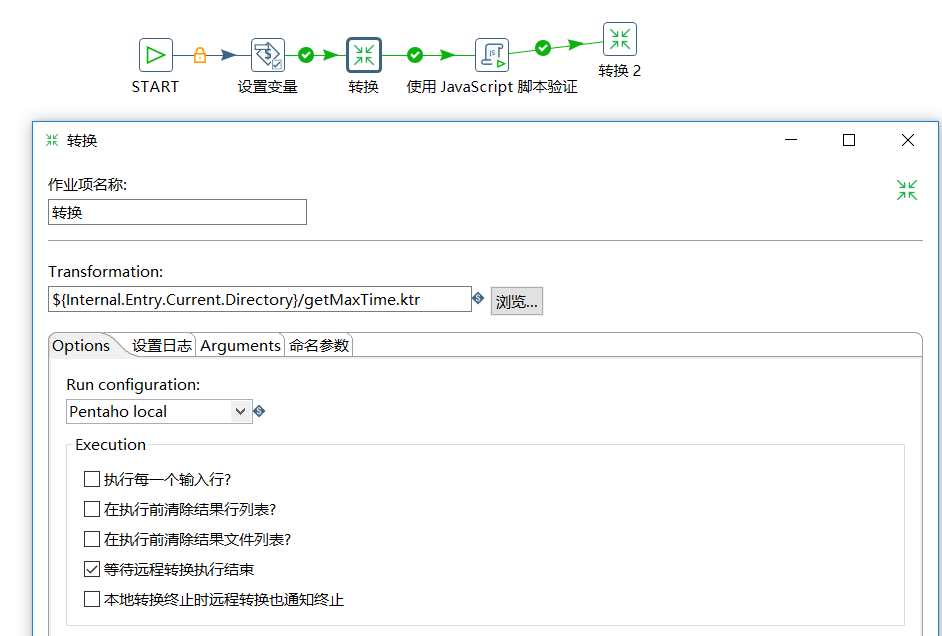
d、取得转换任务中的最大时间,更新到 maxjlsj

e、添加转换(插入数据到ES)
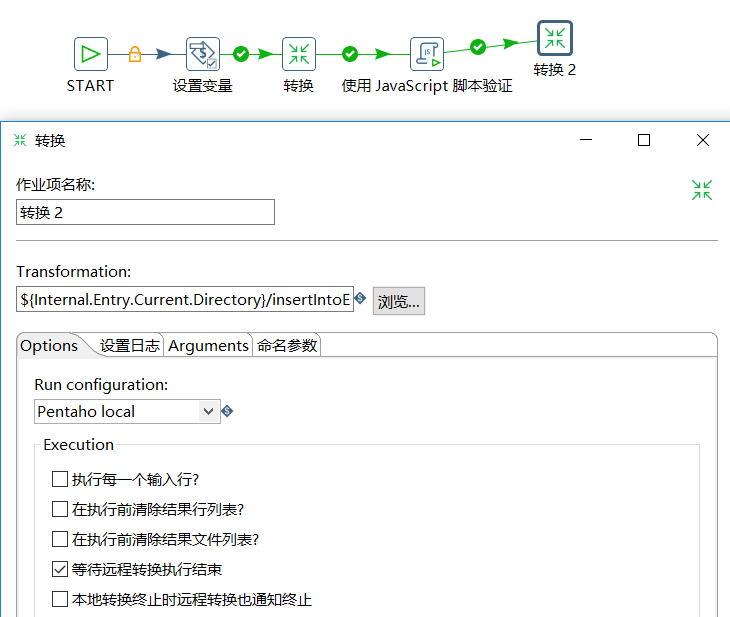
点击运行,大功告成 ...