大数据Hadoop学习之搭建Hadoop平台(2.1)
关于大数据,一看就懂,一懂就懵。
大数据的发展也有些年头了,如今正走在风口浪尖上,作为小白,我也来凑一份热闹。
大数据经过多年的发展,有着不同的实现方案和分支,不过,要说大数据实现方案中的翘楚,那就是Hadoop了,因其开源、稳定等因素,受到了业界的承认和欢迎,那我们就来窥视一下Hadoop。
一、什么是Hadoop?
1、 Hadoop是Apache软件基金组织的一个顶级项目,是开发可靠、可扩展、分布式计算的开源软件。
Apache Hadoop软件库是一个框架,允许在使用简单编程模型的计算机集群上对大型数据集进行分布式处理。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。库本身不是依靠硬件来提供高可用性的,而是设计用于检测和处理应用程序层的故障,因此在一组计算机上提供高可用性服务。
2、Hadoop项目包括以下模块
- Hadoop Common:支持其他Hadoop模块的常用工具。
- Hadoop分布式文件系统(HDFS):提供对应用程序数据的高吞吐量访问的分布式文件系统。
- Hadoop YARN:作业调度和集群资源管理的框架。
- Hadoop MapReduce:用于并行处理大型数据集的基于YARN的系统
关于这些模块的具体内容,在后期的文章中会一一详细介绍。
3、与Hadoop相关的其他Apache项目如下:
Ambari:用于配置,管理和监控Apache Hadoop集群的基于Web的工具,其中包括支持Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop。Ambari还提供了一个用于查看集群健康状况的仪表板,如热图和可视化查看MapReduce,Pig和Hive应用程序以及以用户友好的方式诊断其性能特征的功能。
Avro:数据序列化系统。
Cassandra:可扩展的多主数据库,无单点故障。
Chukwa:用于管理大型分布式系统的数据收集系统。
HBase:可扩展的分布式数据库,支持大型表格的结构化数据存储。
Hive:提供数据摘要和即席查询的数据仓库基础设施。
Mahout:可扩展的机器学习和数据挖掘库。
Pig:用于并行计算的高级数据流语言和执行框架。
Spark:一种用于Hadoop数据的计算引擎,具有快速性和通用性。Spark提供了一个简单而富有表现力的编程模型,支持各种应用,包括ETL,机器学习,流处理和图形计算。
Tez:一种基于Hadoop YARN的通用数据流编程框架,它提供了强大且灵活的引擎来执行任意DAG的任务来处理批量和交互式用例的数据。Tez被Hadoop,Pig和Hadoop生态系统中的其他框架以及其他商业软件(例如ETL工具)所采用,以替代Hadoop MapReduce作为底层执行引擎。
ZooKeeper:分布式应用程序的高性能协调服务。
这就是Hadoop,一个动物园,提供了一些基础设施,比如Hadoop分布式文件系统HDFS、yarn、MapReduce、Hadoop common;里面有这许多动物,比如蜜蜂(hive)、猪(pig)、黑斑羚(impala);当然还要有动物园管理员(zookeeper),管理着动物园的生态平衡。
二、如何查看Hadoop各版本
hadoop使用<major>.<minor>.<maintenance>格式来表示版本格式,即"<主要>.<次要>.<维护>",例如Hadoop2.7.3,则表示主要版本为2、次要版本为7、维护版本为3。当然,在版本格式后面还有其他后缀,比如“-alpha2”或“-beta1”,表示API兼容性保证和发布质量。例如hadoop-3.0.0-alpha1和hadoop-3.0.0-beta1。
1、主要版本用于引入实质性,可能不兼容的更改。其示例包括在Hadoop 2中使用YARN和MapReduce 2替换MapReduce 1,以及在Hadoop 3中将所需的Java运行时版本从JDK7更改为JDK8,主要版本标志着有重大更新。
2、次要版本用于在主要发行版中引入新的兼容功能。
3、维护版本包括错误修复或低风险更改。
了解上述这些之后,可以通过Hadoop各版本名称来判断Hadoop的版本重要性,在学习或者项目中选择相应的版本来使用,不过,选择稳定版能够减少许多不可预知的错误,Hadoop各版本文档首页都会介绍该版本是否是稳定版。
关于大数据,一看就懂,一懂就懵。
一、简介
Hadoop的平台搭建,设置为三种搭建方式,第一种是“单节点安装”,这种安装方式最为简单,但是并没有展示出Hadoop的技术优势,适合初学者快速搭建;第二种是“伪分布式安装”,这种安装方式安装了Hadoop的核心组件,但是并没有真正展示出Hadoop的技术优势,不适用于开发,适合学习;第三种是“全分布式安装”,也叫做“分布式安装”,这种安装方式安装了Hadoop的所有功能,适用于开发,提供了Hadoop的所有功能。
二、介绍Apache Hadoop 2.7.3
该系列文章使用Hadoop 2.7.3搭建的大数据平台,所以先简单介绍一下Hadoop 2.7.3。
既然是2.7.3版本,那就代表该版本是一个2.x.y发行版本中的一个次要版本,是基于2.7.2稳定版的一个维护版本,开发中不建议使用该版本,可以使用稳定版2.7.2或者稳定版2.7.4版本。
相较于以前的版本,2.7.3主要功能和改进如下:
1、common:
①、使用HTTP代理服务器时的身份验证改进。当使用代理服务器访问WebHDFS时,能发挥很好的作用。
②、一个新的Hadoop指标接收器,允许直接写入Graphite。
③、与Hadoop兼容文件系统(HCFS)相关的规范工作。
2、HDFS:
①、支持POSIX风格的文件系统扩展属性。
②、使用OfflineImageViewer,客户端现在可以通过WebHDFS API浏览fsimage。
③、NFS网关接收到一些可支持性改进和错误修复。Hadoop端口映射程序不再需要运行网关,网关现在可以拒绝来自非特权端口的连接。
④、SecondaryNameNode,JournalNode和DataNode Web UI已经通过HTML5和Javascript进行了现代化改造。
3、yarn:
①、YARN的REST API现在支持写/修改操作。用户可以通过REST API提交和删除应用程序。
②、用于存储应用程序的通用和特定于应用程序的信息的YARN中的时间轴存储支持通过Kerberos进行身份验证。
④、Fair Scheduler支持动态分层用户队列,在任何指定的父队列下,在运行时动态创建用户队列。
三、先决条件
1、安装Hadoop之前需要做一些准备工作
①、支持的平台:我选用Linux操作系统centos7.2 64位
a. Linux:Hadoop是针对Linux系统研发的,能够很好的与Linux系统融合,借助Linux系统能够让Hadoop更加的稳定、健壮且性能更佳。
b. Windows:Hadoop也能安装在Windows操作系统上,不过,需要借助Cygwin工具,具体安装请参看https://wiki.apache.org/hadoop/Hadoop2OnWindows。
②、必须安装Java:Hadoop是利用java开发的开源软件,所以需要安装java。我使用的是1.8.0_131版本:

③、ssh:必须安装ssh,并且sshd必须正在运行才能使用管理远程Hadoop守护程序的Hadoop脚本。
2、下载Apache Hadoop2.7.3
①、下载地址:http://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/,打开之后如下所示:下载 hadoop-2.7.3.tar.gz
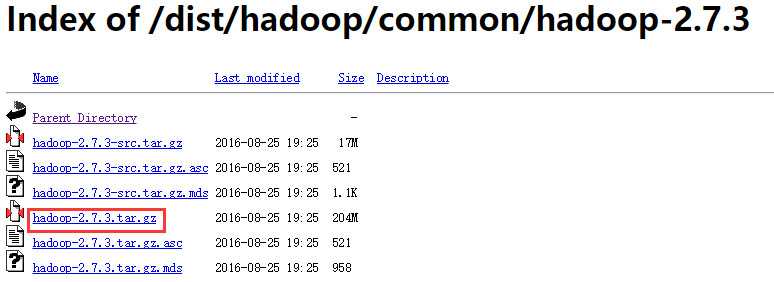
②、将下载好的 Hadoop tar 包放在 /root/software 下,利用tar -zxvf hadoop-2.7.3.tar.gz解压,解压之后将tar包移到其他目录下(不移也可以,反正我移了,后期操作的时候看着清爽点)
3、启动Hadoop
①、编辑hadoop-env.sh文件
进入解压好的hadoop文件夹,在etc/hadoop路径下(即全路径:/root/software/hadoop-2.7.3/etc/hadoop)找到hadoop-env.sh文件:

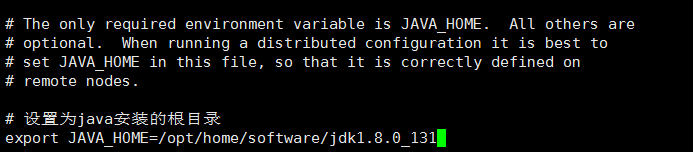
打开hadoop-env.sh文件,找到export JAVA_HOME=${JAVA_HOME},修改为java安装的根目录:
#设置为java安装的根目录 export JAVA_HOME=/opt/home/software/jdk1.8.0_131
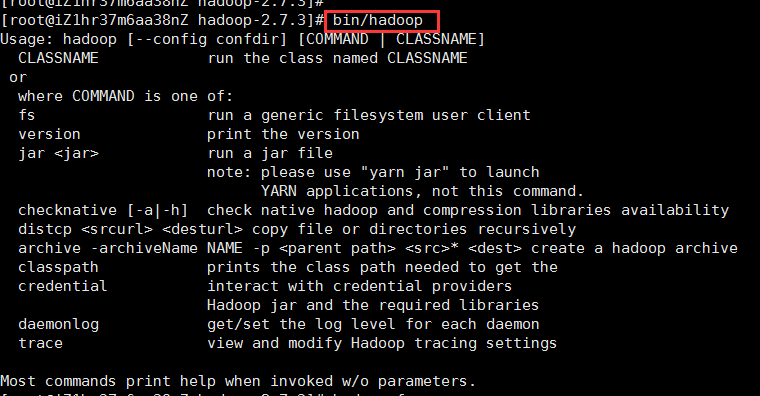
②、退回到hadoop目录下,即/root/software/hadoop-2.7.3路径下,使用命令bin/hadoop,若出现以下提示,则hadoop安装成功:
注:学习hadoop需要有一定的Linux基础和java基础,如没有相应基础的,看该博文会显得比较吃力。建议具有Linux和java基础再学习hadoop。
四、独立安装
hadoop有三种模式的安装,分别为独立安装、伪分布式安装、全分布式安装。独立安装是最简单安装,即将hadoop安装在一台机器上,这种方式适合学习、调试,也是伪分布式安装/全分布式安装的基础。在上述步骤中,如果你使用bin/hadoop出现了提示符,就代表我们已经以独立安装的方式将hadoop安装在我们的Linux系统上了。
五、伪分布式安装
上述已经介绍了独立模式的安装,且hadoop已经以独立模式安装成功,不过,hadoop独立模式并没有任何守护进程,所有程序都在同一个JVM上执行,在独立模式下测试和调试MapReduce程序很方便,但hadoop不仅仅如此。伪分布式安装是在独立安装的基础上进行相应的配置而成,所谓伪分布式安装就是在一台机器上模拟一个小规模的集群,相较于独立模式,伪分布式模式下可以使用yarn、HDFS等。真正全分布模式下运行的hadoop,是需要在多台机器(至少3台)上部署hadoop来达到集群的效果。
目前就只有一台机器,所以可以搭建伪分布模式的hadoop,接下来就介绍怎么以伪分布模式安装hadoop。
1、配置core-site.xml和hdfs-site.xml
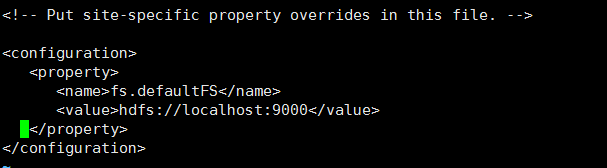
①、配置core-site.xml:该配置文件在etc/hadoop路径下,即/root/software/hadoop-2.7.3/etc/hadoop路径下,在<configuration>节点下添加如下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
如图:这是设置hadoop 默认文件系统的位置
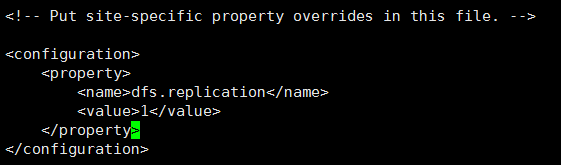
②、配置hdfs-site.xml:该配置文件在etc/hadoop路径下,即/root/software/hadoop-2.7.3/etc/hadoop路径下,在<configuration>节点下添加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
如图:这是设置存储到HDFS文件系统中的文件需要复制的份数,在全分布模式下,每上传一个文件到HDFS文件系统中,HDFS都会根据设置的复制份数把文件复制对应的份数并分散存储到不同的节点上,这种机制保证了HDFS文件的容灾性、容错性,一般在全分布模式下设置为3份,由于我们目前是伪分布模式,只有一个节点(一台机器),所以存储一份即可。
2、安装ssh
①、先检查一下Linux系统上是否安装了ssh,使用以下命令查看本地是否已经安装ssh:
|
1
|
ssh |
如果安装ssh,会出现如下图所示:
②、检查ssh到本地是否需要密码,使用如下命令:如果不需要输入密码,则ssh配置成功,否则进入第③步。
|
1
|
ssh localhost |
③、如果使用ssh localhost需要输入密码,执行以下命令配置ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
如上命令执行成功之后,再执行ssh localhost命令,如果不需要密码且出现以下提示,则ssh配置成功:
3、配置MapReduce
①、使用如下命令格式化文件系统:
bin/hdfs namenode -format
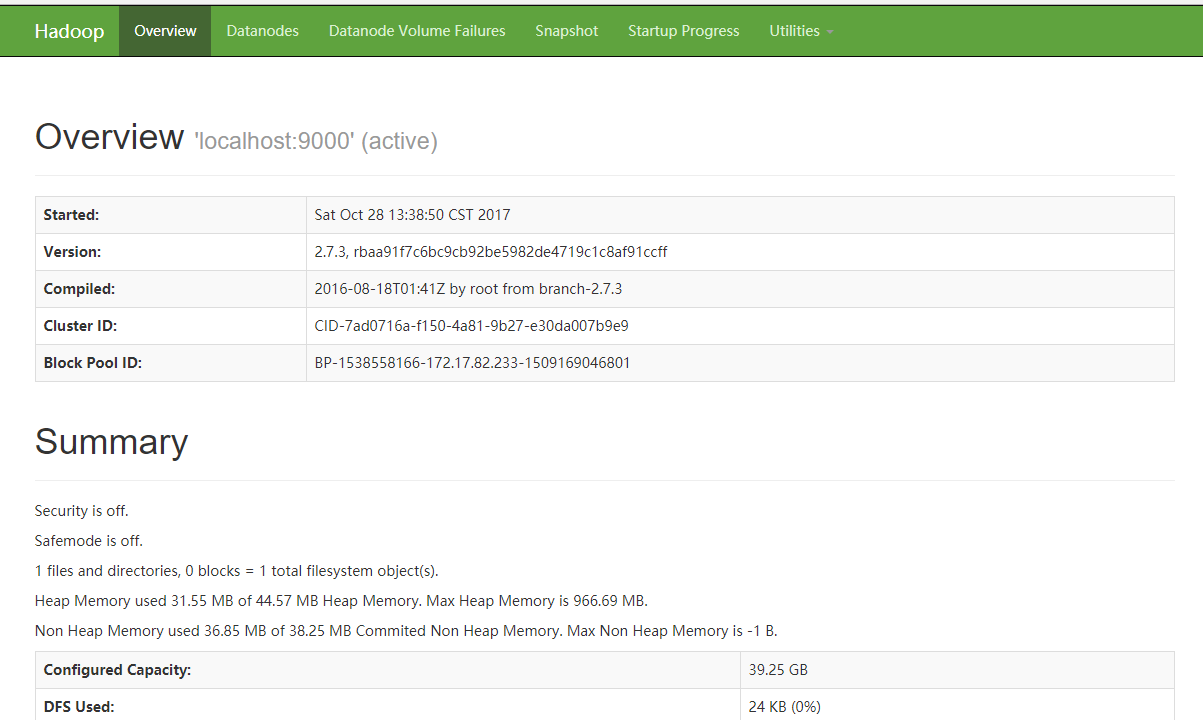
②、使用如下命令启动NameNode守护进程和DataNode守护进程:
sbin/start-dfs.sh
执行上述命令之后,在浏览器中输入http://IP:50070,IP是你安装hadoop机器的IP,出现如下图界面,代表MapReduce配置成功:
4、在单节点上配置yarn:以下的步骤在上述所有操作都执行成功的前提下进行。
①、配置mapred-site.xml:mapred-site.xml文件同样存放在/root/software/hadoop-2.7.3/etc/hadoop路径下,默认该路径下并不存在mapred-site.xml文件,而是存在mapred-site.xml.template文件,复制一份mapred-site.xml.template文件,并改名为mapred-site.xml即可,在<configuration>节点下添加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
②、配置yarn-site.xml:yarn-site.xml文件同样存放在/root/software/hadoop-2.7.3/etc/hadoop路径下,在<configuration>节点下添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
③、使用如下命令启动ResourceManager守护程序和NodeManager守护程序
sbin/start-yarn.sh
④、在浏览器地址栏输入地址:http://101.200.40.240:8088,如果出现如下界面,代表配置单节点yarn成功:
至此,伪分布式hadoop安装成功,在接下来的博文中,会介绍hadoop的使用以及hadoop生态部分项目的使用。