ASP.NET WebAPi之断点续传下载(上)
前言
之前一直感觉断点续传比较神秘,于是想去一探究竟,不知从何入手,以为就写写逻辑就行,结果搜索一番,还得了解相关http协议知识,又花了许久功夫去看http协议中有关断点续传知识,有时候发觉东西只有当你用到再去看相关内容时才会掌握的更加牢固,理解的更加透彻吧,下面我们首先来补补关于http协议中断点续传的知识。
http协议知识恶补
当请求一个html页面时我们会看到请求页面如下:

第一眼看到上面Accept中的参数时我是懵逼的,之前也就看看缓存cookie等常见的头信息,于是借此机会也学习下这部分内容。
我们知道Accept是指客户端允许请求返回的内容类型,那为何这里面参数有如此之多呢?在学习WebAPi时,我们在服务端未进行过滤时既可以返回xml,也可以返回json,此时如上图一样,text/html未匹配上,接着匹配xml类型,匹配后则进行相应格式内容返回,所以客户端接受如此多类型内容,也是为了服务端那边未设置特定内容响应,此时则根据客户端设置的内容进行最合适的匹配。
那么问题来了,上面的q是啥玩意?
q(quality)
上面给出了客户端能够接受响应的内容类型,自然就有最合适的匹配,此时就用到了q这个参数,在此我将q翻译为quality即权重的意思,应该是比较合适的,它用来表示我们期待接受内容偏爱的程度即所占的权重。它的范围是0-1,其默认值为1,这就类似质检部门对产品合格判断的一种介质。例如当我们需要返回视频资源时,我们客户端设置为如下:
Accept: audio/*; q=0.2, audio/basic
此时我们将上述翻译如下:
audio/basic; q=1 audio/*; q=0.2
我们更加期待返回的是audio/basic类型的资源,因为其权重为1大于audio/*类型的资源,若为匹配到则继续匹配下一个资源,audio/*则表示属于audio类型的所有子类型资源。
接下来,我们再来看一个例子:
Accept: text/plain; q=0.5, text/html,text/x-dvi; q=0.8, text/x-c
此时我们则可以翻译为如下:
Accept: text/html;q=1或者 text/x-c;q=1 text/x-dvi; q=0.8 text/plain; q=0.5
倾向于返回text/html或者text/x-c类型资源,若都不存在,则返回权重为0.8的text/x-dvi,最终还是不存在则返回text/plain。
Accept-Ranges
在响应头中添加此字段允许服务端来显示表明对资源范围的接受。如果服务端接受一个字节范围的资源的请求则此时变成如下:
Accept-Ranges: bytes
如果服务端不接受任何范围的请求资源此时则在响应头添加如下来告诉客户端不要发送范围请求的资源:
Accept-Ranges: none
Content-Range
当在响应头中添加接受字节范围的资源时,此时若客户端请求资源文件比较大时即只是返回部分数据时,此时则返回状态码为206的部分内容,在Content-Range响应头信息中实时显示当前数据的进度。比如如下:

//开始500个字节数据 Content-Range: bytes 0-499/1234 //第二个500个字节数据 Content-Range: bytes 500-999/1234 //除了开始500个字节之外的数据 Content-Range: bytes 500-1233/1234 //最后500个字节数据(表示数据最终传输完毕) Content-Range: bytes 734-1233/1234
如果客户端请求资源到达所给资源的界限此时则返回416的状态码。
注意:当请求资源为字节范围请求时,不要在响应头中使用 multipart/byteranges 类型的content-type。
断点续传场景
当正在下载时出于其他任何原因此时下载中断,那么下载用户只能重新下载,这样的体验想必是比较痛苦的,最烦躁的是如果用户是在移动端下载大文件时,居然下载中断了,接下来又得重新下载,此时想必用户会放弃下载。此时断点续传则应运而生。 断点续传则需要用到上述Accept-Ranges和Content-Range将其添加到响应头中。例如如下:
HEAD http://localhost/api/files/get?filename=blog_backup.zip User-Agent: IIS Host: localhost HTTP/1.1 200 OK Content-Length: 1182367743 Content-Type: application/octet-stream Accept-Ranges: bytes Server: Microsoft-IIS/10.0 Content-Disposition: attachment; filename=blog_backup.zip
HEAD http://localhost/api/files/get?filename=blog_backup.zip User-Agent: IIS Host: localhost Range: bytes=0-999 HTTP/1.1 206 Partial Content Content-Length: 1000 Content-Type: application/octet-stream Content-Range: bytes 0-999/1182367743 Accept-Ranges: bytes Server: Microsoft-IIS/10.0 Content-Disposition: attachment; filename=blog_backup.zip
接下来我们来实现简单的下载以及断点续传下载对比看看效果。
在webapi中提供了一系列方便我们调用的api,比如 ContentDispositionHeaderValue 来设置附件而不像在webform中手动在响应头中进行拼接。以及返回的MimeType类型 MediaTypeHeaderValue 。首先我们看看最普通的下载。
普通下载
普通的下载无非就是获取到文件的标识再打开下载的文件夹,最后得到文件流返回到响应的HttpContent对象中以及设置附件即可。我们看看如下代码还是比较简单的,这种相对比较简单的下载想必我们大家定是信手拈来。
//响应的MimeType类型
private const string MimeType = "application/octet-stream";
//配置文件中配置的文件所在路径
private const string AppSettingDirPath = "DownloadDir";
//将配置文件中取得的路径赋给此变量
private readonly string DirFilePath;
this.DirFilePath = ConfigurationManager.AppSettings[AppSettingDirPath];
接下来就是最重要的下载逻辑了,如下:
public HttpResponseMessage Download(string fileName)
{
var fullFilePath = Path.Combine(this.DirFilePath, fileName);
if (!File.Exists(fullFilePath))
{
throw new HttpResponseException(HttpStatusCode.NotFound);
}
FileStream fileStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.ReadWrite);
var response = new HttpResponseMessage();
response.Content = new StreamContent(fileStream);
response.Content.Headers.ContentDisposition
= new ContentDispositionHeaderValue("attachment") { FileName = fileName };
response.Content.Headers.ContentType
= new MediaTypeHeaderValue(MimeType);
response.Content.Headers.ContentLength
= fileStream.Length;
return response;
}
那么问题来了,我们可不可以在获取文件流返回到HttpContent之前是不是应该首先将文件流放入到缓冲流中然后再返回呢?如下:
var bufferStream = new BufferedStream(fileStream); response.Content = new StreamContent(bufferStream);
我们想着是不是将文件流率先放入到缓冲流中效果是否更佳呢?刚开始我也是这样想来着,但是经过查证资料发现:
为了得到更好的性能,在文件流中已经包含有缓冲流的缓冲逻辑,对于用缓冲流来包裹文件流的情况没有任何好处,还有一点就是在.NET Framework中没有任何一个流需要用到缓冲流,但是,但是有一种情况除外则是若我们自定义实现流且默认没有实现缓冲的逻辑情况下需要用到缓冲流,资料来源于:Filestream and BufferedStream
上述也算是涨知识了。继续回到我们的话题,此时我们下载一个文件则看到如下图所示:

因为未实现断点续传,此时我们通过右键可以看到无法暂停,如下:
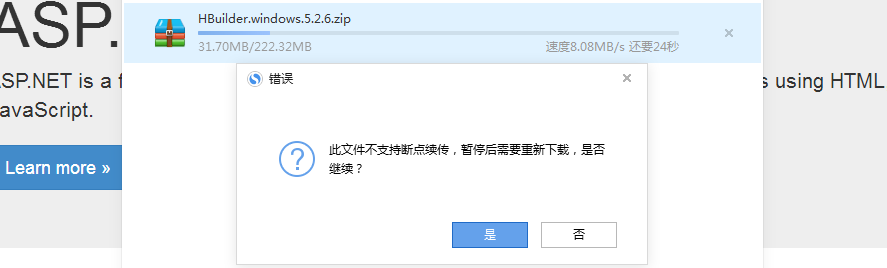
我们继续往下走,接下来来实现断点续传看看:
断点续传下载
在WebAPi提供了Range属性其返回对象为 RangeHeaderValue 里面有存在每个范围的集合如下:
// 摘要:
// Gets the ranges specified from the System.Net.Http.Headers.RangeHeaderValue
// object.
//
// 返回结果:
// Returns System.Collections.Generic.ICollection<T>.The ranges from the System.Net.Http.Headers.RangeHeaderValue
// object.
public ICollection<RangeItemHeaderValue> Ranges { get; }
这是为利用多线程下载而提供,这里我们仅仅实现一个范围的下载。我们通过判断这个对象的值是否为null来实现断点续传。
if (Request.Headers.Range == null ||
Request.Headers.Range.Ranges.Count == 0 ||
Request.Headers.Range.Ranges.FirstOrDefault().From.Value == 0)
{
var sourceStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read);
response = new HttpResponseMessage(HttpStatusCode.OK);
response.Content = new StreamContent(sourceStream);
response.Headers.AcceptRanges.Add("bytes");//告诉客户端接受资源为字节
response.Content.Headers.ContentLength = sourceStream.Length;
response.Content.Headers.ContentType = new MediaTypeHeaderValue(MimeType);
response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment")
{
FileName = fileName
};
}
获取当前已经下载字节数,接着继续进行剩下字节下载。
else
{
var item = Request.Headers.Range.Ranges.FirstOrDefault();
if (item != null && item.From.HasValue)
{
response = this.GetPartialContent(fileName, item.From.Value);
}
}
剩余字节数下载
private HttpResponseMessage GetPartialContent(string fileName, long partial)
{
var response = new HttpResponseMessage();
var fullFilePath = Path.Combine(this.DirFilePath, fileName);
FileInfo fileInfo = new FileInfo(fullFilePath);
long startByte = partial;
var memoryStream = new MemoryStream();
var buffer = new byte[65536];
using (var fileStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read))
{
var bytesRead = 0;
fileStream.Seek(startByte, SeekOrigin.Begin);
int length = Convert.ToInt32((fileInfo.Length - 1) - startByte) + 1;
while (length > 0 && bytesRead > 0)
{
bytesRead = fileStream.Read(buffer, 0, Math.Min(length, buffer.Length));
memoryStream.Write(buffer, 0, bytesRead);
length -= bytesRead;
}
response.Content = new StreamContent(memoryStream);
}
response.Headers.AcceptRanges.Add("bytes");
response.StatusCode = HttpStatusCode.PartialContent;
response.Content.Headers.ContentType = new MediaTypeHeaderValue(MimeType);
response.Content.Headers.ContentLength = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read).Length;
response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment")
{
FileName = fileName
};
return response;
}
接下来我们看看演示结果:
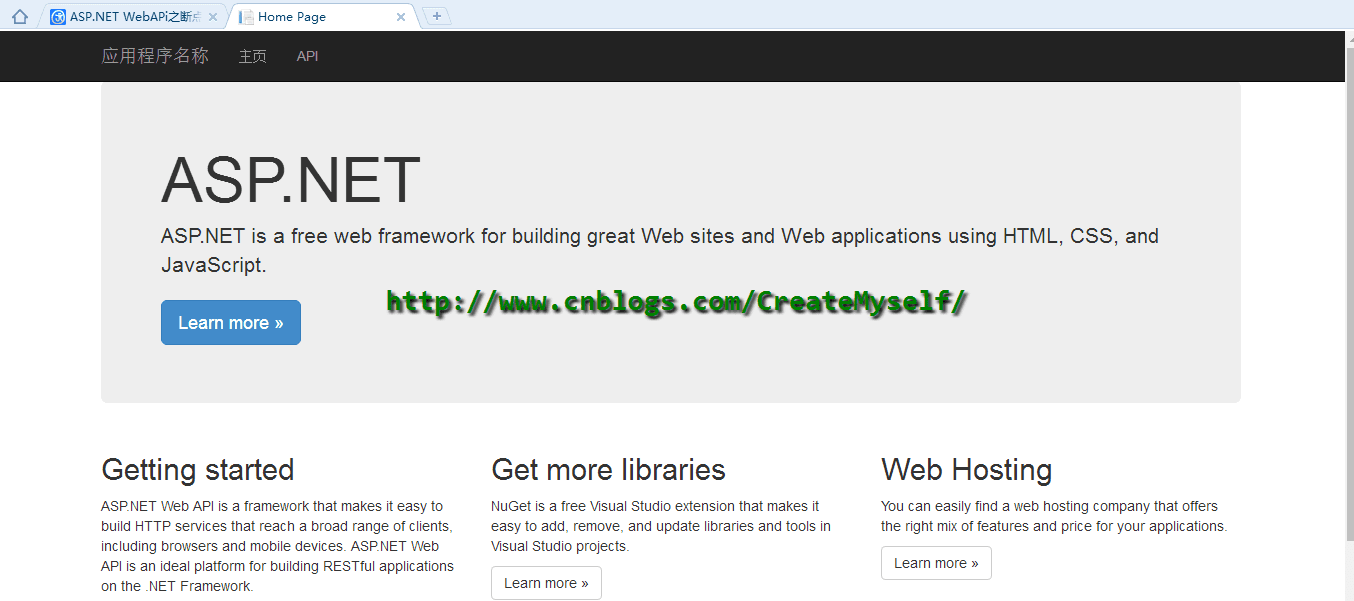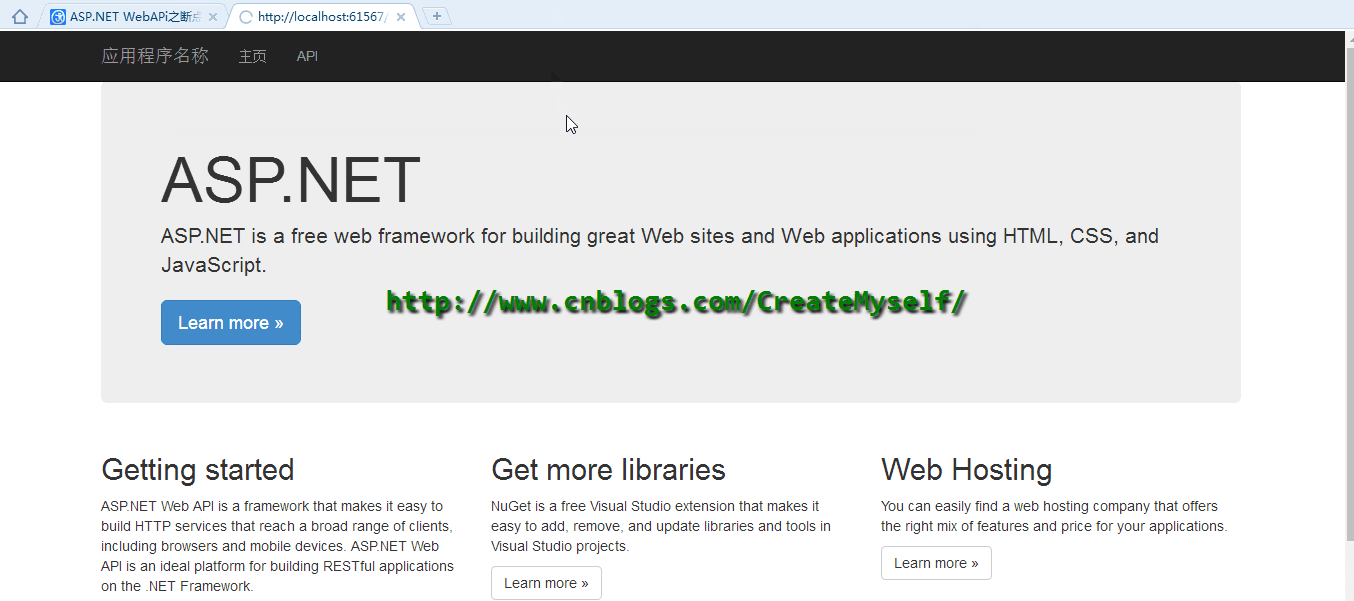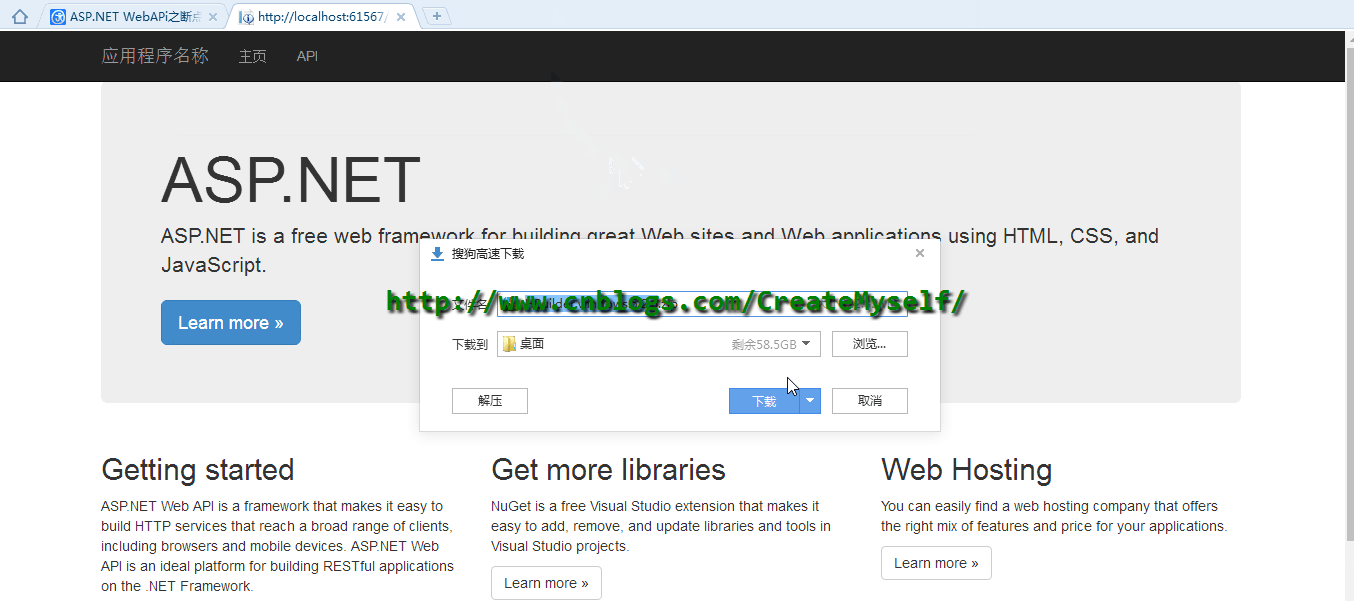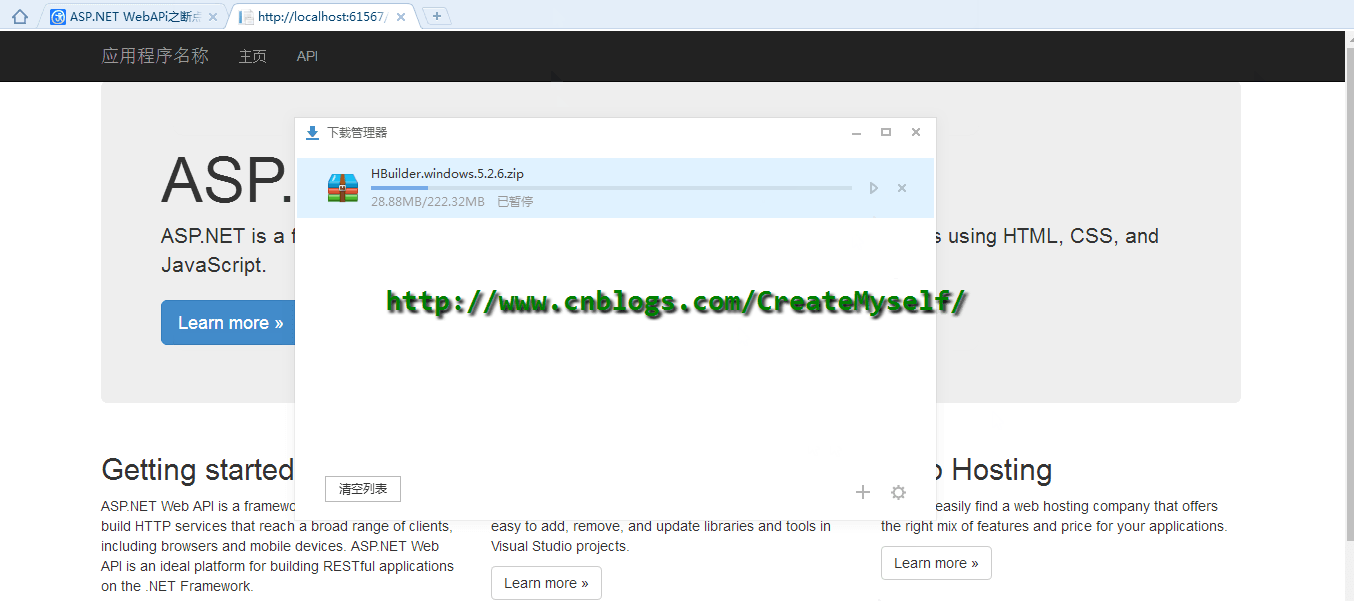
从上面演示我们看出目前已经实现了断点续传,浏览器下载管理器出现了暂停的按钮,但是当暂停后无法继续进行后续下载,在这里存在问题,我们下节再进行后续讲解。同时当返回HttpContent发现居然还有一个可以返回的HttpContent即 PushStreamContent ,此时我们可以将剩余部分字节下载进行如下修改:
Action<Stream, HttpContent, TransportContext> pushContentAction = (outputStream, content, context) =>
{
try
{
var buffer = new byte[65536];
using (var fileStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read))
{
var bytesRead = 0;
fileStream.Seek(startByte, SeekOrigin.Begin);
int length = Convert.ToInt32((fileInfo.Length - 1) - startByte) + 1;
while (length > 0 && bytesRead > 0)
{
bytesRead = fileStream.Read(buffer, 0, Math.Min(length, buffer.Length));
outputStream.Write(buffer, 0, bytesRead);
length -= bytesRead;
}
}
}
catch (HttpException ex)
{
throw ex;
}
finally
{
outputStream.Close();
}
};
response.Content = new PushStreamContent(pushContentAction, new MediaTypeHeaderValue(MimeType));
response.StatusCode = HttpStatusCode.PartialContent;
response.Headers.AcceptRanges.Add("bytes");
response.Content.Headers.ContentType = new MediaTypeHeaderValue(MimeType);
response.Content.Headers.ContentLength = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read).Length;
response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment")
{
FileName = fileName
};
return response;
如上所做也可行,返回StreamContent不就ok了吗,为何还出现一个PushStreamContent呢?这又是一个遗留问题!
总结
本节我们讲述了在webapi中普通下载以及断点续传下载,对于断点续传下载当暂停后无法继续进行下载,暂时还存在一定问题,对于返回的内容既可以为StreamContent,也可以是PushStreamContent,这二者有何区别呢?二者的应用场景是什么呢?这又是一个问题,关于此二者我们下节再讲,webapi一个很轻量的服务框架,你值得拥有,see u。