hadoop大数据处理之表与表的连接
前言: hadoop中表连接其实类似于我们用sqlserver对数据进行跨表查询时运用的inner join一样,两个连接的数据要有关系连接起来,中间必须有一个相等的字段进行连接,其实hadoop的表连接就是对文本的处理,处理的文本中有一部分的内容是一样的,然后把这鞋大量的数据按照中间的一个相同的部分进行连接,用来解决大数据在关系型数据库查询困难的问题。
之前一直做c#语言的开发是一个本本分分做网站开发的程序员,像对hadoop这类用java语言做开发的内容一直属于菜鸟级别,hadoop中表连接也只最近慢慢学的,也是因为要解决工作中的一些问题慢慢熟悉起来的,在工作中确实解决了不少问题,下面我就讲一下我在工作中那个地方用到了表连接,其实还有很多地方,这里举一个比较经典的。
我们公司是做论坛的,数据了谈不上太大,不过也还够我这种小角色忙活半天了,之前出现了一个需求,就是拿到每一个帖子的发帖用户,和该帖子下所有的回帖用户,然后基于这个数据统计和发帖用户最相关的回帖用户,其实就是找用户与用户之间的关系。
这里的数据有两份(1)发帖人的信息,postid(帖子的id)和userid(发帖人id)(2)回帖人信息,postid(帖子的id)和userid(回帖人id)。这两个数据在数据库中是分别放在两个表中的,看似简单的问题如果一旦跟大数据扯上了关系就不好处理了,这里的发题人信息由3百万的数据,而回帖人的信息有7千多万条数据,中间如果用sqlserver的inner join根本是没办法查询的,这个时候就可以用hadoop的表连接了,首先把数据用工具从数据库到出成文本,因为要对两部分数据进行标示,所以两份数据要在文本中用" "分割的之后的length必须不同,
这一份是主帖的数据第一列是postid,第二列是用户的id,第三列是随便取出来的数据作为主帖的表示

这一份是回帖的数据,第一列是postid,第二列是回帖的用户id
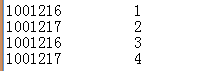
在map阶段用postid作为key进行,中间给主帖一个标示typeL,并且给回帖的数据进行一个标示typeR。

 map
map在reduce就可以把相关联的帖子的发帖人id和回帖人id关联起来了
reduce最终的结果展示
每一行中,第一个就是发帖人id,后边跟着的就是回帖人的信息。