第十一章 回环检测
前端提供特征点的提取和轨迹,地图的初值,而后端负责对所有这些数据进行优化。如果如同VO那样仅考虑相邻时间上的关邻,那么之前的误差将不可避免地累积到下一时刻,这样整个SLAM会出现累积误差,长期的结果将不可靠。
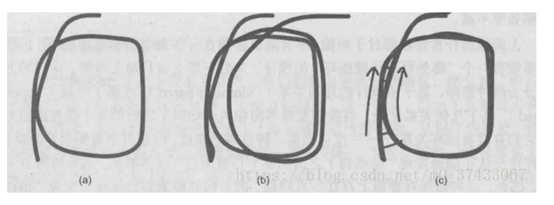
如上图,a表示真实轨迹,b中前端只给出相邻帧间的估计,优化后Pose Graph出现漂移 ,c添加回环检测后的Pose Graph在碰到相同特征点时可以借此消除累积误差。
1. 方法
a. 朴素类:最简单的方式就是对任意2副图像进行一遍特征匹配,根据正确匹配的数量确定哪2副图像存在关联。但盲目地假设“任意2副图像都可能存在回环”,使得检测的数量实在太大,对于N个可能的回环,我们要检测Cn2次。在大多数实时系统当中是不实用的。另一种是,随机抽取历史数据并进行回环检测,比如在n帧当中随机抽取5帧与当前帧比较,这种做法能够维持常数时间的运算量,但这种盲目试探方法在帧数N增长时,抽到回环的几率会大幅下降,使得检测效率不高。
b. 基于外观(Appearance)的回环检测。它和前端,后端的估计无关,仅根据两副图像的相似性确定回环检测关系。目前基于外观的回环检测方式以成为视觉SLAM中主流的做法,并被应用于实际的系统中去。而其核心问题:如何计算图像间的相似性。设计一种方法,计算相似性评分:s(A, B),但其中使用到的像素灰度是个不稳定的值,故该函数不能很好的反映图像间的相似关系。
c. 视觉slam一直是以人类视觉作为标准的,可目前尚未掌握人脑的工作原理。

借用医学上的说法。假阳性(False Positive)又称感知偏差,而假阴性(False Negative)称为感知变异。而我们希望算法与人类的判断一致,所以希望TP, TN尽量高。则对某个特定的算法,我们统计它在某个数据集上的TP,TN,FP,FN的出现次数,并计算两个统计量:准确率和召回率(Precision & Recall)
Precision=TP/(TP+FP),Recall=TP/(TP+FN)
而这2个指标是评价一个算法的好标准。上述相似性评分的准确率和召回率都不高。
2. 词袋模型(与机器学习有交叉)
词袋(Bag-of-Words),目的是用“图像上哪几种特征”来描述一幅图像。例如,一个人,一辆车。另外一张图片是一辆车,2只狗。
其中确定“人”,“车”,“狗”等概念对应BoW中的“单词”。许多单词放在一起,就组成了“字典”。
确定一副图像中出现了哪些在字典中定义的概念-我们用单词出现的情况描述整张图像。这就把一副图像转换成了一个向量的描述。
比较上一步中的描述的相似程度。
a. 字典,字典由许多单词组成,而每一个单词代表一个概念。一个单词是某一类特征的组合,所以字典生成问题类似一个聚类问题。这其实与机器学习有交集,无监督机器学习中,用于让机器自行寻找数据中的规律。K-means(K均值)算法做的很好。
b. K-means:简单来说,当有N个数据,想要归成k个类。
1 随机选取k个中心点:c1,c2,…….ck
2 对每一个样本,计算它与每个中心点之间的距离,取最小的作为它的归类。
3 重新计算每个类的中心点
4 如果每个中心点都变化很小,则算法收敛,退出;否则返回第2步。
c.简单实用的树结构字典
使用一种k叉树来表达字典。思路比较简单,类似与层次聚类,是k-means的直接扩展。假定我们有N个特征点,希望构建一个深度为d, 每次分叉为k的树。做法如下:
1). 在根节点,用K-means把所有样本聚成k类(事实上,为了保证聚类均匀性会使用k-means++)。这样得到了第一层。
2). 对第一层的每个节点,把属于该节点的样本再聚成K类,得到下一层。
3).以此类推,最后得到叶子层。叶子层即为所谓的Words.
这样我们在叶子层构建了单词,而树结构中的中间节点仅供快速查找时使用。2个优点,一是可容纳K指数d个单词。二是查找速度保证了对数级别的查找效率。
3.相似度计算
对单词的区分性或重要性加以评估,给它们不同的权值以起到更好的结果。在文本索引中,常用的一种做法称为TF-IDF(Term Frequency-Inverse Document Frequency),或译频率-逆文档频率。TF部分的思想是,某单词在一幅图像中经常出现,它的区分度就高。另一方面,IDF的思想是,某单词在字典中出现的频率越低,则分类图像时区分度越高。
IDF = log(n/ni) 其中n为所有特征数量,ni是某个叶子节点wi中的特征数量。
TFi = (ni/n) TF部分则是指某个特征在单幅图像中出现的频率。图像A中单词wi出现了ni次,而一共出现的单词次数为n.
于是 wi的权重等于TF乘IDF之积
n∗=TF×IDF
4. 实验分析与评述
在机器学习领域,代码无错而结果不满意,我们首先怀疑“网络结构是否够大,层次是否足够深,数据样本是否足够多”等,但仍处于“好模型敌不过烂数据”。在slam中,仍先从这一原则出发,
a. 增加字典规模,往往可以显著提高图像评分。
b. 关键帧的处理,如果关键帧选得太近,那么必将导致2个关键帧之间相似性过高,不容易检测出历史数据中的回环。故用于回环检测的帧最好是稀疏一些,彼此之间不太相同,又能涵盖整个环境。
c. 词袋的回环检测之后有一个验证。其一是设立回环的缓存机制,时间上的一致性检测。单次检测到的回环并不足以构成良好的约束,而在一段时间中一直检测到的回环,才是正确的回环。另一方法是空间上的一致性检测,即对回环检测到的2个帧进行特征匹配,估计相机的运动。然后。再把运动放到之前的Pose Graph中,检查与之前的估计是否有很大的出入。
d. 与机器学习的关系。
从词袋模型来说,它本身是一个非监督的机器学习过程——构建词典相当于对特征描述子进行聚类,而树只是对所聚的类的一个快速查找的数据结构而已。词袋方法在物体识别问题上明显不如神经网络,故机器学习将来被深度学习打败很有看头。