摘自:https://blog.csdn.net/me_yundou/article/details/80459341
具体看上面链接
一、摘要:
这篇文章主要介绍的是作者识别(author identification)问题。作者识别问题是指基于某个T时间之前的所有论文(paper)和它们的作者(author),以及所属机构(organization),或者发表会议(venue)这些已知的历史数据之间的关系,构建一个模型(learning model),然后对T时间之后发表的匿名的论文(anonymous paper)能识别出它们可能的作者(potential authors)是谁(对所有候选作者进行排序,排序靠前的认为是识别出来的论文可能的作者)。
模型:联合模型 = 度量学习模型 + 增强的skipgram模型 ,其中,度量学习已经可以实现作者识别的问题,加上skipgram是增强学习的效果。
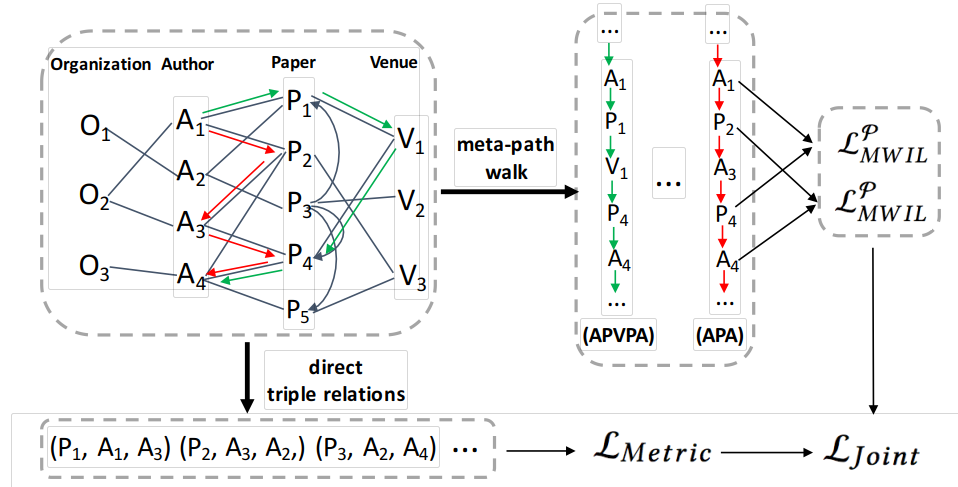
本文中作者首先提出了一个可行的模型,模型名为度量学习模型(metric learning model),然后使用了一些方法(比如,元路径 meta-path,增强的skipgram模型)对该模型进行增强,最后得到一个联合模型(joint model),也就是本文最终实验使用的模型。如下图,左上角虚线框内是各种节点之间关系的已知历史数据,然后下方的元祖直接关系(direct triple relations)就是提取了历史数据中paper和true author以及false author之间的关系(例如图中元祖(P1,A1,A3)就是说明论文P1的真实作者是A1,虚假作者是A3,这样的关系称为直接关系),构成了一个基本可行的度量学习模型(metric learning model),这个模型的目标函数就是L metric。然后,历史数据右边的使用元路径游走(meta-path walk)以及改进的skipgram模型提取历史数据中的间接关系(间接关系包括同一篇论文的作者,同一个机构的作者,或者同一个会议的论文等)得到的L MWIL 就是对基本可行模型的增强部分。这两个部分结合起来就得到了本文的目标------联合模型(joint model)。