1、读取:
- sparkDF = spark.read.csv(path)
- sparkDF = spark.read.text(path)
2、打印:
sparkDF.show()【这是pandas中没有的】:打印内容
sparkDF.head():打印前面的内容
sparkDF.describe():统计信息
sparkDF.printSchema():打印schema,列的属性信息打印出来【这是pandas中没有的】
sparkDF.columns:将列名打印出来
3、选择列
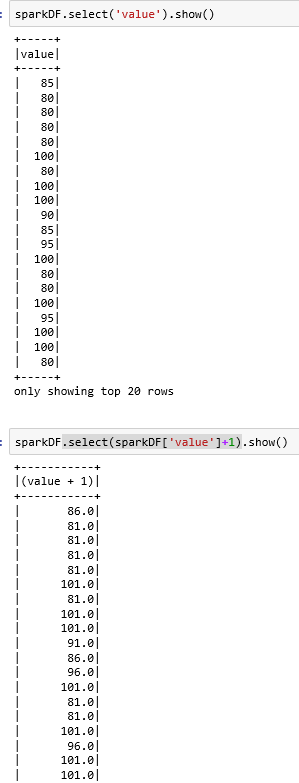
【select函数,原pandas中没有】
sparkDF.select('列名1','列名2‘).show():选择dataframe的两列数据显示出来
sparkDF.select ( sparkDF['列名1']+1 , '列名2' ).show():直接对列1进行操作(值+1)打印出来
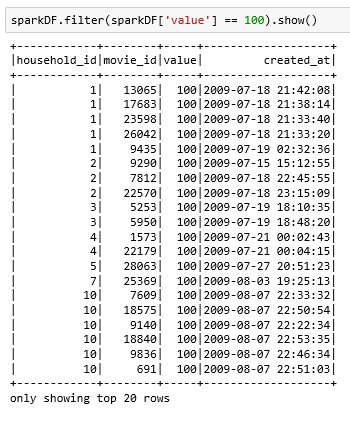
4、筛选列:
filter【类似pandas中dataframe的采用列名来筛选功能】
sparkDF.filter ( sparkDF['value'] == 100 ).show():将value这一列值为100的行筛选出来
5、计算不重复值以及统计dataframe的行数
distinct()函数:将重复值去除
sparkDF.count():统计dataframe中有多少行

将评分为100的电影数量统计出来:
