一、简介:TF-IDF 的改进算法
https://blog.csdn.net/weixin_41090915/article/details/79053584
bm25 是一种用来评价搜索词和文档之间相关性的算法。通俗地说:主要就是计算一个query里面所有词q和文档的相关度,然后再把分数做累加操作。
我们有一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数,我们的做法是,先对query进行切分,得到单词qi,然后单词的分数由3部分组成:
-
- 单词qi和D之间的相关性
- 单词qj和query之间的相关性
- 每个单词的权重
最后对于每个单词的分数我们做一个求和,就得到了query和文档之间的分数。

二、优缺点
适用于:在文档包含查询词的情况下,或者说查询词精确命中文档的前提下,如何计算相似度,如何对内容进行排序。不适用于:基于传统检索模型的方法会存在一个固有缺陷,就是检索模型只能处理 Query 与 Document 有重合词的情况,传统检索模型无法处理词语的语义相关性。
白话举例:提出一个query:当下最火的女网红是谁?
在Document集合中document1的内容为:[当下最火的男明星为鹿晗];
document2的内容为:[女网红能火的只是一小部分]。
显然document1和document2中都包含[火]、[当下]、[网红]等词语。
但是document3的内容可能是:[如今最众所周知的网络女主播是周二柯]。
很显然与当前Query能最好匹配的应该是document3,可是document3中却没有一个词是与query中的词相同的(即上文所说的没有“精确命中”),此时就无法应用BM25检索模型。
三、算法核心:
https://blog.csdn.net/weixin_41090915/article/details/79053584四、传统TF-IDF vs. BM25
传统的TF-IDF是自然语言搜索的一个基础理论,它符合信息论中的熵的计算原理,虽然作者在刚提出它时并不知道与信息熵有什么关系,但你观察IDF公式会发现,它与熵的公式是类似的。实际上IDF就是一个特定条件下关键词概率分布的交叉熵。
BM25在传统TF-IDF的基础上增加了几个可调节的参数,使得它在应用上更佳灵活和强大,具有较高的实用性。
BM25中的TF
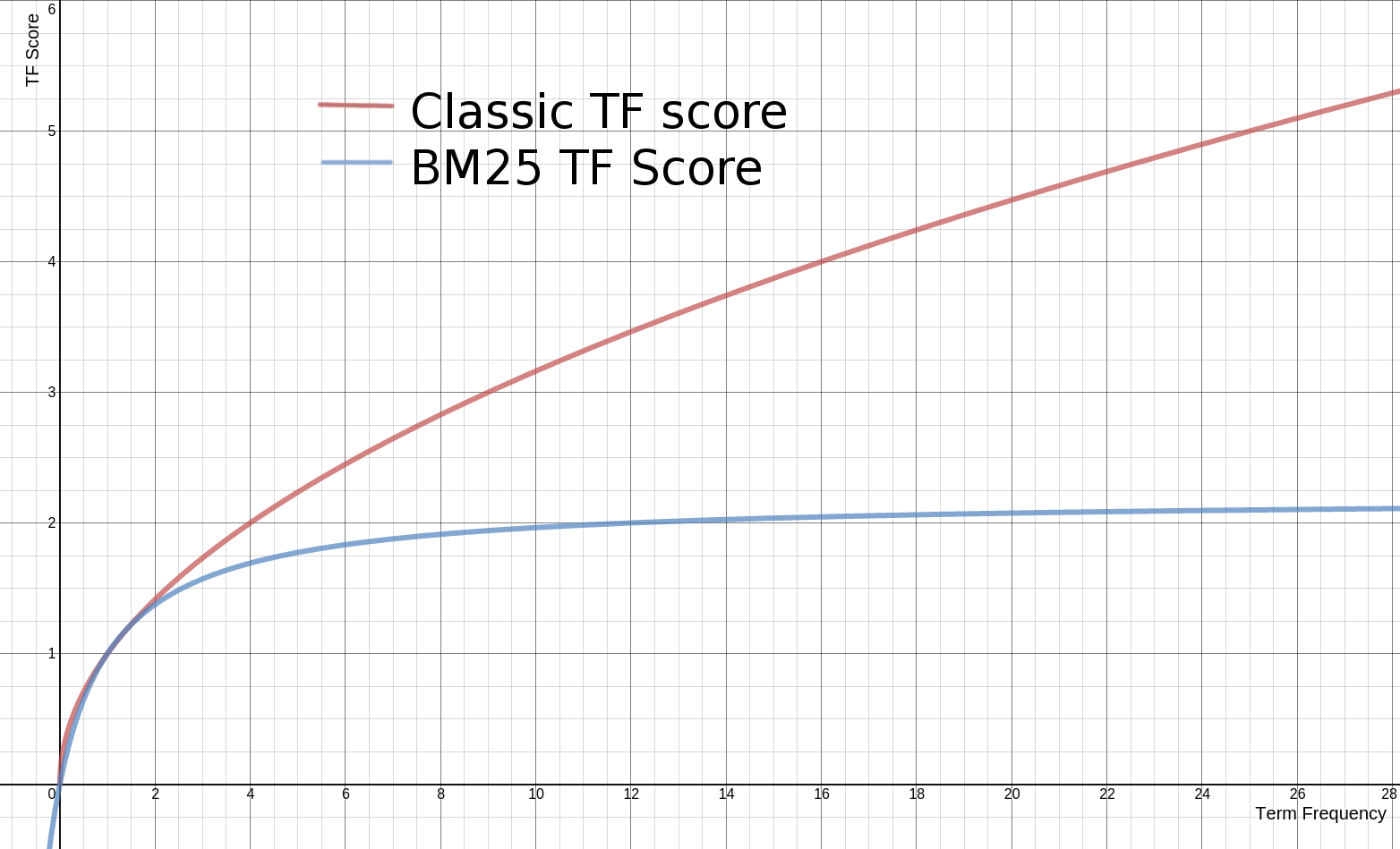
传统的TF值理论上是可以无限大的。而BM25与之不同,它在TF计算方法中增加了一个常量k,用来限制TF值的增长极限。下面是两者的公式:
传统 TF Score = sqrt(tf)
BM25的 TF Score = ((k + 1) * tf) / (k + tf)
下面是两种计算方法中,词频对TF Score影响的走势图。从图中可以看到,当tf增加时,TF Score跟着增加,但是BM25的TF Score会被限制在0~k+1之间。它可以无限逼近k+1,但永远无法触达它。这在业务上可以理解为某一个因素的影响强度不能是无限的,而是有个最大值,这也符合我们对文本相关性逻辑的理解。 在Lucence的默认设置里,k=1.2,使用者可以修改它。