2.1引子
a = "I love fishc"
b = list(a)
print (b)
---['I', ' ', 'l', 'o', 'v', 'e', ' ', 'f', 'i', 's', 'h', 'c'] # 字符串到列表的转换
字符串的分割:
split 以什么分割,分割完后列表中将不存在该元素
name = "ded fefe eJjDA"
print(name.split("e")) # 字符串到列表的转换
print (name.split( )) # 这个作用其实挺大,可以移除多余的空格,并将字符串转换成列表
---["d", "d", "f", "f", "jiDA"]
---['ded', 'fefe', 'eJjDA'] #通过对字符串间的空格进行切割,得到一个列表型
a = "I love fishc"
b = tuple(a) #字符串到远元祖的转换
print (b)
---('I', ' ', 'l', 'o', 'v', 'e', ' ', 'f', 'i', 's', 'h', 'c')
a = ["I love fishc"]
b = tuple(a) #列表到元祖间的转换
print (b)
---('I love fishc',)
a = ["I love fishc"]
str = ',' #列表到字符串间的转换,如果列表中有多个字符串则实现了将多个字符串拼接成一个字符串的功能,即‘字符串str字符串’
print (str.join(a))
---I love fishc
a = ("I love fishc")
b = list(a) #元祖到列表的转换
print (b)
---['I', ' ', 'l', 'o', 'v', 'e', ' ', 'f', 'i', 's', 'h', 'c']
len(sub):返回参数sub的长度 #计数是从1开始的
len()不但适用于字符串(单一字符串还是多个字符串),也适用列表
2.2基础数据类型
2.2.1数字int
2.2.2布尔值bool
2.2.3字符串
- 字符串的索引:形象理解即为字符串的排列,第一个都是从零开始排列的
animals = ['bear', 'tiger', 'penguin', 'zebra'] animals = [1] # 记住括号类型,为中括号 print (animals) ---tiger
记住:序数==有序,从1开始
- 字符串的切片:即通过索引来截取一部分字符串,从而得到新的字符
a = 'ABCDEFGHIJK' print(a[0:3]) print(a[2:5]) print(a[0:]) #默认到最后 print(a[0:-1]) #-1就是最后一个 print(a[0:5:2]) #代表前五个字母从0到5,每两个取一个 print(a[5:0:-2]) #反向加步长1,从第5个字母往0,每两个取一个 print(a[-2:-1]) #倒数切片 print(a[ : : 3]) #所有字母,每三个取一个 print(a[:]) #直接建立一份新的副本,相当于拷贝 ---ABC ---CDE ---ABCDEFGHIJK ---ABCDEFGHIJ ---ACE ---FDB ---J ---ADGJ ---ABCDEFGHIJK
字符串常用方法:
name = "ded fefe eJjDA"
print (name.capitalize()) #首字母大写,其余字母变成了小写
print (name.swapcase()) #大小写翻转,本来大写的被置换成小写,小写被置换成大写
print (name.title()) #实现每个单词首字母大写,其余的小写
print (name.lower()) # 实现所有字母都小写
print(name.upper()) # 实现所有字母都大写
print (name.isupper()) #判断所有字母都为大写,返回布尔值
print (name.islower()) #判断所有字母都为小写,返回布尔值
print (name.istitle()) #判断所有单词的首字母都为大写
print (name.center(width)) #将字符串居中,并使用空格填充至长度为width的新字符串
移除(strip )变量中的某个字母
print (name.strip( )) #括号内不写入东西代表移除字符串两边的空格
print (name.lstrip( )) #移除字符串中从最左端开始的字母
print (name.rstrip( )) #移除字符串中从最右端开始的字母
print(name.count("e")) #字符串中"e"字母出现的次数
print(name.count("e"),1,4) #可以切片,分析索引1到索引4,字母e出现次数
print (name.startswith("de")) #判断是否以“de”开头
print (name.endswith("de")) #判断是否以“de”结尾,返回的是布尔值True or False
print (name.find("e")) #寻找字符串中的元素是否存在,如果存在,返回的是他的位置,即索引,如果不存在,返回的是-1
print (name.index("e")) #寻找字符串中的元素是否存在,如果存在,返回的是他的位置,即索引,如果不存在则会报错
print (name[2]) #通过索引查找相对应的字母
print (name.join('##')) #以可迭代对象作为分隔符,将其插入到字符串两边
---#ded fefe eJjDA#
print (name.partition("ef" )) #找到字符串sub,即ef,把字符串分成一个三元组(pre_sub, sub, fol_sub),如果字符串中不含sub则返回(‘原字符串’,‘’,‘’)
---('ded f', 'ef', 'e eJjDA')
name = "ded fefe eJjDA"
字符串的分割: (字符串通过切割变成了列表)
split 以什么分割,分割完后列表中将不存在该元素
print(name.split("e"))
---["d", "d", "f", "f", "jiDA"]
字符串的拼接:
>>>s = name[:4] + "666666" + name[4:]
>>>print s
---ded 666666fefe eJjDA
字符串的居中:
>>> str1.ljust(20,) #设置格式左对齐,其余部分默认情况下,以空格填充
---'hello,Eva! '
>>> str1.center(20,'*') #设置格式左对齐,剩余部分已“*”填充
---'*****hello,Eva!*****'
>>> str1.rjust(20,'&') #设置格式左对齐,剩余部分已“&”填充
---'&&&&&&&&&&hello,Eva!'
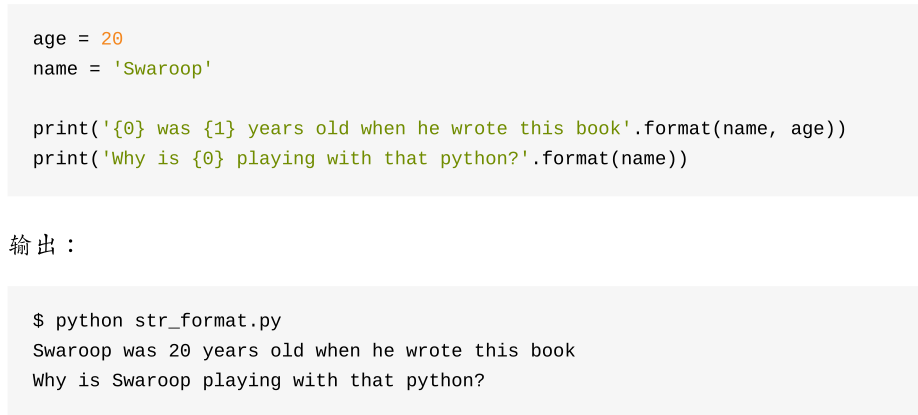
format的三种玩法,格式化输出(左边括号类型为大括号,右边小括号)
res='{} {} {}'.format('egon',18,'male')
print (res)
---egon 18 male
res='{1} {0} {1}'.format('egon',18,'male')
print (res) ---18 egon 18
res='{name} {age} {sex}'.format(sex='male',name='egon',age=18)
print (res) ---egon 18 male
"{{0}}".format("不打印") ----{0}
tpl = "i am {}, age {}, {}".format(*["seven", 18, 'alex']) # 注意这里必须有星号,才可以访问列表元素,如果访问的是字典,则是两个星号
print('tp1')
---i am seven, age 18, alex
#replace 替换
name='alex say :i have one tesla,my name is alex'
print(name.replace('alex','SB',1)) # 1代表从左往右只换取一个,不给数值默认替换全部
#####is系列(返回的是布尔值)
name='jinxin123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isdigit()) #字符串只由数字组成 注意这里str,bytes,unicode类型都包含的
print(name.isspace()#字符串有空格组成
num0='4'
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ'
print(num0.isdigit()) True
print(num1.isdigit()) True
print(num2.isdigit()) True
print(num3.isdigit()) False
print(num4.isdigit()) False

2.2.3.1 格式化字符串
在%操作符的左侧放置一个需要格式化的字符串,这个字符串带有一个或者多个嵌入的转换目标,都以%开头(如:%d)。
在%操作符右侧放置一个(或多个)对象,这些对象将会插入到左侧想让python进行格式化字符串的一个(或多个)转换目标的位置上去。
>>>'this is %d %s bird!' % (1,'dead')
that is 1 dead bird!
2.2.3.2 更高级的格式化字符串表达式

2.2.3.3基于字典的字符串格式化:
基本原理:
a = '%(n)d %(x)s' % {'n': 1, 'x': 'what'}
print(a)
---1 what
例:
reply = 'hello, %(name)s, your age is %(age)s' # 注意这里%后面的取值
values = {'name': 'bob', 'age': 40}
print(reply % values)
---hello, bob, your age is 40
2.2.4元祖(tuple) 注意:元祖也能切片操作
元祖近似于列表,二者最大的区别 在于列表可以修改和删除,而元祖不能。
temp = (“老刘”,“老张”,“老王”,“老郑”)
temp = temp[:2] + ("王八蛋",) + temp[2:] #这里这个新元素必须有括号和逗号,否则会报错
print temp
---(“老刘”,“老张”,“王八蛋” ,“老王”,“老郑”)
2.2.5列表list (列表无论增加还是删除元素,最好先执行内置函数的运算,再打印)
letters = ['a','b','c','d','e'] print(letters[1]) ---b #使用索引从列表获取一个元素,但是是字符串类型。 print(letters[1:2]) ---['b'] #使用切片的方式从列表中获取一个元素,但是是列表类型。 print(letters[:]) ---['a','b','c','d','e'] #直接建立元列表的副本
列表中元素的拼接:
li = ['alex','eric','rain']
str = '-'
print (str.join(li)) 或print ('-'.join(li)) # 将'-'插入到列表每个元素之间,最终得到一个字符串
---alex-eric-rain
list和range结合起来使用:
s = list(range(0,10))
print (s) #很厉害的知识点
---[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
使用range打印100,99,98,....1,0
for i in range(100,-1,-1)
print (i)
或 [x for x in reversed(range(101))]
列表的增:
append() 向列表末尾增加一个元素。
extend() 向列表末尾增加多个元素。
li = [1,'a','b',2,3,'a']
li.insert(2,55) #按照索引去增加,把数字55添加在索引2的位置
print(li) # 这里不能一步打印出来,即print (li.insert(2,55)),看好对象
---[1, 'a', 55, 'b', 2, 3, 'a']
li = [1,'a','b',2,3,'a']
li.append('aaa')
li.append([1,2,3]) #追加在列表最后面(记住向列表追加元素之前,必须先创建列表,可以是空列表,也可以是非空列表)
print(li)
---[1, 'a', 'b', 2, 3, 'a', 'aaa', [1, 2, 3]]
li = [1,'a','b',2,3,'a']
li.extend([1,2,3]) #相对于append,extend圆括号里面必须是一个列表,相同点都是追加在末尾
print(li)
---[1, 'a', 'b', 2, 3, 'a', 1, 2, 3]
列表的删:
li = [1,'a','b',2,3,'a']
li = li.pop(1) # 选中当中的一个元素并打印,如果不输入数值索引,则会默认最后一个元素,并打印该元素。
del li[1:3] #选中并删除索引1到索引3的元素,打印剩下元素,这个只能利用索引删除
li.remove('a') #移除指定元素,打印其他元素,这个在不知道索引的情况下进行删除
li.clear() #清除所有元素
print(li)
列表的改:
li = [1,'a','b',2,3,'a']
li[1] = 'dfasdfas' #对指定索引下的元素进行修改
li[1:3] = ['a','b'] #对索引范围内的元素进行修改
print(li)
a = ["q","w","q","r","t","y"]
print(a.count("q")) #记住这里不管是找数字还是字符串的索引都必须加入引号的
---2
index(索引)(方法用于从列表中找出某个值第一个匹配项的索引位置)
a = ["q","w","r","t","y"]
print(a.index("r"))
---2 #像列表中如果没有这个元素则会报错。
if 'r' in a:
print (a.index('r')) #最好结合‘in’使用,如果不存在返回的是布尔值
a = [2,1,3,4,5] a.sort() #对列表a中的元素进行排序,从小到大分类 print(a) ---[1, 2, 3, 4, 5] a.sort(reverse = True) print(a) ----[5, 4, 3, 2, 1] #对列表a中的元素进行排序,从大到小分类,可以一步实现大小分类 list2 = a[:] #对列表进行拷贝 print list2 ---[2,1,3,4,5] a = [2,1,3,4,5] a.reverse() #对列表a中的元素从反向排序 print(a) ---[5, 4, 3, 1, 2] 利用sorted()函数进行排序 a = [2,1,3,4,5] b = sorted(a) # 利用函数这个来排序原列表没有被修改 print(b) ---[1, 2, 3, 4, 5]
列表常用操作符:(比较操作符,逻辑操作符,连接操作符,重复操作符,成员关系操作符)
比较操作符 list1 = [123,456] list2 = [234,123] #有多个元素时,列表默认先比较第0个元素的大小,后面的不用考虑 list1 > list2 ---False 逻辑操作符 list3 = [123,456] (list1 < list2) and (list1 == list3) ---True 连接操作符 list4 = list1 + list2 #(这个只能在列表间相加,无法直接添加某个元素进来,只能使用append函数或者insert函数) ---[123,456,234,123] #一般不建议这么用,容易存在bug,最好使用append函数 list * 3 ---[123,456,123,456, 123,456 ] 123 in list3 ---True list5 = [123,["小甲鱼","牡丹"],456] #二维数组的访问 "小甲鱼" in list5 ---False "小甲鱼" in list5[1] ---True list5 [1][1] #列表中的列表的访问 ---“牡丹”
2.3字典(dictionary)(最灵活的内置数据结构类型。可以将一个物件和另一个物件相关联,并从y获取x。其实字典相当于一个“查询表”)
{'name': 'das', 'ds': 75} # 可以事先拼出整个字典
D = {}
D['name'] = 'das' # 动态建立字典的一个字段
D['ds'] = dict(name='das', da=75) # 这一步k值‘ds’对应的value是一个字典
dict([('name', 'das'), ('ds', 75)]) # 如果需要在程序运行时把键和值逐步建成序列,那么这种形式比较有用
dict(zip(['name','ds'],['das',75])) # 通过zip函数构建字典,‘name’对应的是‘das’
phoneNumbers = {'Bob':'444-4321', 'Mary':'555-6789','Jenny':'867-5309'}
"Bob" in phoneNumbers
True
"Barb" in phoneNumbers
False
字典的增:
stuff = {'name': 'Zed', 'age': 36, 'height': 6*12+2}
print(stuff['name'])
stuff[‘A’] = "balabala"
stuff[2] = "abadccve"
print (stuff)
---Zed
---{'age': 36, 2: 'abadccve', 'A': 'balabala', 'name': 'Zed', 'height': 74} →没有规则的打印出来了
stuff = {'name': 'Zed', 'age': 36, 'height': 6*12+2}
stuff.setdefault('namedada', 'dasd') # 有则不发生改变,没有就添加,所以不会覆盖
print(stuff)
---{'name': 'Zed', 'age': 36, 'height': 74, 'namedada': 'dasd'}
字典的删:
stuff = {'name': 'Zed', 'age': 36, 'height': 6*12+2}
del stuff['name']
del stuff['height']
print (stuff)
---{'age': 36}
stuff.pop('name')
print(stuff)
---{'age': 36, 'height': 74}
stuff.popitem() # 随机删除字典当中一个键值对
print(stuff)
---{'name': 'Zed', 'age': 36}
stuff.clear() # 清空字典
print(stuff)
---{}
字典的改:
dic = {"name":"jin","age":18,"sex":"male"}
dic2 = {"name":"alex","weight":75}
dic2.update(dic) #将dic所有的键值对覆盖添加(相同的覆盖,没有的添加)到dic2中
print(dic2)
---{'age': 18, 'name': 'jin', 'weight': 75, 'sex': 'male'}
字典的查:
stuff = {'name': 'Zed', 'age': 36, 'height': 6*12+2}
a = stuff.get('name') # 存在则打印相对的值,不存在则返回None
print(a)
--- Zed
dic['name'] # 返回key值,不存在则会报错
stuff.keys()
stuff.values()
stuff.items() #这三个都可以通过list()转换,这样看着效果好一点
字典的循环:
dic = {"name":"jin","age":18,"sex":"male"}
for key in dic:
print(key)
---age
---name
---sex
for item in dic.items():
print(item)
---('age', 18)
---('name', 'jin')
---('sex', 'male')
数据补充知识:
对于元组:
如果只有一个元素,并且没有逗号,此元素是什么数据类型,改表达式就是什么数据类型。
tu = (1)
tu1 = (1,)
print(tu,type(tu)) ---1 <class 'int'>
print(tu1,type(tu1)) ---(1,) <class 'tuple'>
tu = ('海贼王')
tu1 = ('海贼王',)
print(tu,type(tu)) ---海贼王 <class 'str'>
print(tu1,type(tu1)) ---('海贼王',) <class 'tuple'>
对于list
在循环一个列表时,最好不要进行删除的动作(一旦删除,索引会随之改变),容易出错。
li = [11,22,33,44,55] # 将索引为奇数的元素删除。
del li[1::2]
print(li)
l1 = []
for i in range(len(li)):
if i % 2 == 0:
l1.append(li[i])
li = l1
print(li)
l1 = []
for i in li:
if li.index(i) % 2 == 0:
l1.append(i)
li = l1
print(li)
for i in a[1::2]:
li.remove(i)
print(li)
对于字典
dic = dict.fromkeys([1,2,3],[])
print(dic) ---{1: [], 2: [], 3: []}
dic[1].append('老男孩')
print(dic) ---{1: ['老男孩'], 2: ['老男孩'], 3: ['老男孩']}
在循环字典中,不能增加或者删除此字典的键值对。
dic = {'k1':'value1','k2':'value2','name':'wusir'} ,将字典中含有k元素的键,对应的键值对删除。
for i in dic:
if 'k' in i:
del dic[i]
print(dic) # dictionary changed size during iteration
l1 = []
for i in dic:
if 'k' in i:
l1.append(i)
for i in l1:
del dic[i]
print(dic) ---{'name': 'wusir'}
2.4 for 循环
dic = {'name':'太白','age':18,'sex':'man'}
for k,v in dic.items():
print(k,v)
---name 太白
---age 18
---sex man
for looper in [1, 2, 3, 4, 5]:
print (looper)
1
2
3
4
5
for looper in [1,2,3,4,5]:
print(looper,end = ' ') #注意end参数的使用技巧,通过一个空格来结束输出工作,而非换行
1 2 3 4 5
for looper in [1, 2, 3, 4, 5]: # 移花接木式的玩法,下面有例题可以见证它的妙用
print ("hello")
hello
hello
hello
hello
hello
2.5enumerate(例举,枚举):
li = ['alex','银角','女神','egon','太白']
for i in enumerate(li):
print(i)
for index,name in enumerate(li,1):
print(index,name)
---(0, 'alex')
---(1, '银角')
---(2, '女神')
---(3, 'egon')
---(4, '太白')
---1 alex
---2 银角
---3 女神
---4 egon
---5 太白
2.6range(范围):
for i in range(1,10,2): #从1到10,间隔两个数 print(i) 1 3 5 7 9 for i in range(10,1,-2): # 反向取值,间隔两个数 print(i) 10 8 6 4 2
本节例题:
已知字符串 name = "aahhh113244ADD.,/'[@#$hhhhTTTTTT666",
1.将name中的数字取出,组成一个新的字符串
2.去除name中重复的字母,最后输出一个只留一个字母的字符串
3.将name字符串反向并输出(切片)
计算用户输入内容中索引为奇数并且对应的元素为数字的个数


content = input('>>>') count = 0 for i in range(len(content)): if i % 2 == 1 and content[i].isdigit(): count += 1 print(count)
words = input('内容:') i = 0 for num in words[1:len(words)+1: 2]: if num.isdigit(): i += 1 print('个数:%r' % i)
求列表['a','2',2,4,5,'2','b',4,7,'a',5,'d','a','z']中元素出现的次数:
some_data = ['a','2',2,4,5,'2','b',4,7,'a',5,'d','a','z'] count = dict() for item in some_data: if item in count: count[item] += 1 else: count[item] = 1 print(count)
list3 = [{"name": "alex", "hobby": "抽烟"},
{"name": "alex", "hobby": "喝酒"},
{"name": "alex", "hobby": "烫头"},
{"name": "alex", "hobby": "Massage"},
{"name": "wusir", "hobby": "喊麦"},
{"name": "wusir", "hobby": "街舞"},]
如何把上面的列表转换成下方的列表?
list4 = [{"name": "alex", "hobby_list": ["抽烟", "喝酒", "烫头", "Massage"]},
{"name": "wusir", "hobby_list": ["喊麦", "街舞"]},]
lis = []
list4 = {}
for i in list3:
lis.append(i["name"])
b = list(set(lis))
for j in b:
list4.setdefault(j, [])
if j in i["name"]:
list4[j].append(i["hobby"])
print(list4)
# 这个和结果有一些出入,最后结果是在一个字典内。但是构想不错,也可以借鉴一下
dic = {}
for i in list3:
if i['name'] not in dic: # 将第一个alex和wusir对应的值添加进来
dic[i['name']] = {'name':i['name'],'hobby_list':[i['hobby']]}
else: # 通过这步将alex,wusir后面的值追加进来
dic[i['name']]['hobby_list'].append(i['hobby'])
list3 = list(dic.values()) # 取alex,wusir对应的value值
print(list3)
购物车:
要求用户输入总资产,例如:2000
显示商品列表,让用户根据序号选择商品,加入购物车
购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功。
goods = [{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
goods = [{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
salary = int(input("total money:").strip())
for index, item in enumerate(goods,1):
print(index, item['name'], item['price'])
buys = []
while True:
things = input("the nunmber of goodsq or Q exit:")
if things.strip().upper() == "Q":
break
else:
if things.strip().isdigit():
things = int(things)
if (things > 0 and things <= len(goods)):
salary -= goods[things - 1]["price"]
if salary > 0:
print("you left salary", salary)
buys.append(goods[things - 1]["name"])
else:
print("your salary is lower")
print("this what you buys:", buys)
exit()
else:
print("what your input is out of the number")
else:
print("what you input includes other alphas")
good_lis = []
count = input('你的总资产').strip()
if count.isdigit:
count = int(count)
print("商品列表:")
for index, name in enumerate(goods, 1):
print(index, name["name"], name["price"])
while True:
choice = input("商品序号:").strip()
choice = int(choice)
if (choice >= 1 and choice <= 4):
count -= goods[choice - 1]["price"]
good_lis.append(goods[choice - 1]["name"])
if count < goods[choice - 1]["price"]:
print("余额不足")
print("一下是商品列表:""
", good_lis)
break
else:
print("已成功加入购物车")
else:
print("你所输入的序号超出范围,请重新输入")
else:
print("你所输入大有非法字符,重新输入")
有如下值li= [11,22,33,44,55,77,88,99,90],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
li = [11,22,33,44,55,77,88,99,90] result = {} for row in li: result.setdefault('k1',[]) # 选用该方法可以不用考虑覆盖的问题 result.setdefault('k2',[]) if row > 66: result['k1'].append(row) elif row < 66: result['k2'].append(row) print(result) li = [11,22,33,44,55,77,88,99,90] result = {} for row in li: if row < 66: if 'key1' not in result: # 如多没有这步则前面的值都会被后一个覆盖 result['key1'] = [] result['key1'].append(row) #注意这里的缩进 else: if 'key2' not in result: result['key2'] = [] result['key2'].append(row) print(result)