整个内容是我在春招面试时候整理的一些题目,里面涵盖有网上搬运的(由于当时没有记录来源,如果有转载没标注来源,请与我联系),还有我面试到的。整个排版很乱,后期我会一步一步整理。整个内容大概快有两万字。整理的过程也是自我知识体系梳理的过程,希望能得到知识体系知识的提升。
修改记录:
2020/4/19 修改1~4
一、基础知识
1 简单名词解释
OOP:面向对象编程。面向过程可以理解成工厂里的流水线,封装的方式是按数据处理的流程。而面向对象更像是对工人的描述。将工人的工作方式封装成一个个的函数,然后让程序进行调用。
OOD:面向对象设计。
OOA:面向对象分析。
高内聚:指一个软件模块是由相关性很强的代码组成,只负责一项任务,也就是常说的单一职责原则。
低耦合:简单理解,一个完整的系统,模块与模块之间,尽可能的使其独立存在。让每一个模块尽可能独立完成某个特定的子功能。
面向对象的好处:
(1)降低耦合。每个功能分装成相应的类,降低功能之间代码上联系。
(2)提高可维护性。
2 封装
封装的优点:
(1)即隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别;将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成“类”,其中数据和函数都是类的成员
(2)设计类时,不希望直接存取类中的数据,而是希望通过方法来存取数据。这样就可以达到封装数据的目的,方便以后的维护升级,也可以在操作数据时多一层判断。
(3)封装还可以解决数据存取的权限问题,可以使用封装将数据隐藏起来,形成一个封闭的空间,然后可以设置哪些数据只能在这个空间中使用,哪些数据可以在空间外部使用。一个类中包含敏感数据,有些人可以访问,有些人不能访问,如果不对这些数据的访问加以限制,后果将会非常严重。所以要对类的成员使用不同的访问修饰符,从而定义他们的访问级别。
(4)通过修改访问修饰符实现
Public 数据类型 变量名
{
get{return 变量名}//获取数据
set{变量名=value;}//设置数据
}
使用封装还可以实现对属性的只读、只写:
public string Name { get; private set; }//只读
public string Name { private get; set; }//只写
这样写属性时,编译器会自动创建private string name。这种是会自动实现后备成员变量的自动实现属性。
如果是:
public string Name { get; set; }
这样的没有啥限定的属性,其实和公有字段没多大区别了。
3 继承
继承是面向对象最重要的特性之一。任何类都可以从另外一个类继承,这就是说,这个类拥有它继承类的所有成员。在面向对象编程中,被继承的类称为父类或基类。C#中提供了类的继承机制,但只支持单继承,而不支持多继承,即在C#一次只允许继承一个类,不能同时继承多个类。
Public class 类名:父类名
如何使用父类里面的成员变量,方法,构造函数?
关键字:base
成员变量:base.成员变量名
方法:base.方法名
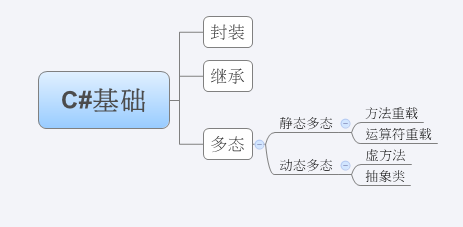
4 多态
多态性意味着有多重形式。在面向对象编程范式中,多态性往往表现为"一个接口,多个功能"。多态性可以是静态的或动态的。在静态多态性中,函数的响应是在编译时发生的。在动态多态性中,函数的响应是在运行时发生的。
4.1 静态多态性:在编译时,函数和对象的连接机制被称为早期绑定,也被称为静态绑定。C# 提供了两种技术来实现静态多态性。
(1)方法重载:可以在同一个范围内对相同的方法名有多个定义。方法的定义必须彼此不同,可以是参数列表中的参数类型不同,也可以是参数个数不同。不能重载只有返回类型不同的方法声明。
(2) 运算符重载:可以重定义或重载 C# 中内置的运算符
4.2 动态多态性:当有一个定义在类中的函数需要在继承类中实现时,可以使用虚方法。
4.2.1 虚方法(virtual)
(1)虚方法是使用关键字 virtual 声明的。
(2)虚方法可以在不同的继承类中有不同的实现。
(3)对虚方法的调用是在运行时发生的。
(4)动态多态性是通过抽象类和虚方法实现的。
4.2.2 接口(Interface)
接口和抽象类差不多,区别在于,接口内包含的全部是未实现的方法。而且接口类和方法的关键词不需要再声明abstract,接口类的关键词,interface,一般定义接口名称,按照约定,我们会在名称前面加上一个I。例如下图的打印机接口。
虚方法:virtual
虚方法存在于相对于需要实现多态的子类的父类当中,同时也是实现多态的最基本的方法。
具体语法:父类的方法,用virtual修饰,表示虚方法。继承它的子类,在内部用override进行重写。下面进行案例分析:
4.2.3 抽象方法和抽象类
然而如果父类中的方法完全不知道去干什么(即方法体中没有必要的代码),必须要子类进行重写才有意义的话,这种情况就需要使用抽象方法。说话,但是不同的人会说不同的话,这个时候就要用抽象类,先声明可以说话,但是不实现。
抽象方法和抽象类的关键字都是:abstract
如果父类的方法很抽象,而且没有具体的do(做什么)即方法体,必须要子类进行重写才有实际意义的话,这种情况就需要用抽象方法了。
父类、子类及输出:
C# 允许您使用关键字 abstract 创建抽象类,用于提供接口的部分类的实现。当一个派生类继承自该抽象类时,实现即完成。抽象类包含抽象方法,抽象方法可被派生类实现。派生类具有更专业的功能。
请注意,下面是有关抽象类的一些规则:
您不能创建一个抽象类的实例。
您不能在一个抽象类外部声明一个抽象方法。
通过在类定义前面放置关键字 sealed,可以将类声明为密封类。当一个类被声明为 sealed 时,它不能被继承。抽象类不能被声明为 sealed。
下面的程序演示了一个抽象类:
3.抽象方法的特点
(1)只有方法头没有方法体的方法称之为抽象方法。(即只有方法的声明,没有方法的实现)
(2)抽象方法用abstract关键字来修饰。
(3)抽象方法代表一种不确定的操作或行为。(由子类去具体实现)
(4)抽象方法不能被调用。
4.抽象类的特点
(1)定义中含有抽象方法的类叫做抽象类。
(2)抽象类用abstract关键字来修饰。
(3)抽象类代表一种抽象的对象类型。
(4)抽象类不能实例化。
(5)抽象类中可以有具体方法,可以没有抽象方法。(也就是说一个类中只要有一个方法是抽象方法那么这个类一定是抽象类,反过来,一个抽象类中可以没有抽象方法,可以带有具体
实现的方法)
(6)一旦一个类中有抽象方法,那么这个类必须也要用abstract来修饰,代表这个类是抽象类,它是不能被实例化的。
抽象类是实现多态的方法之一,一个类被abstract标记的类叫抽象类。当父类的方法不知道如何去实现或者要把某个类抽象出来的时候,可以考虑将父类写成抽象类,将方法写成抽象方法,抽象类的成员也必须标记abstract,即抽象类不一定包含抽象方法,但抽象方法所在的类一定是抽象类,并且不能有任何实现,也就是没有方法体,抽象成员的访问修饰符可以不写,如果写,不能是private,实现父类抽象方法的方法的参数和返回值都要一样;
定义虚方法:
访问修饰符 virtual 返回的数据类型/void 方法名()
{
//执行代码,也可以完全不写
}
重写父类的方法(子类中):
访问修饰符 override 返回的数据类型
void 方法名()
{
//执行代码
}
1、重载(overload): 在同一个作用域(一般指一个类)的两个或多个方法函数名相同,参数列表不同的方法叫做重载,它们有三个特点(俗称两必须一可以):
方法名必须相同
参数列表必须不相同
返回值类型可以不相同
2、重写(override):子类中为满足自己的需要来重复定义某个方法的不同实现,需要用 override 关键字,被重写的方法必须是虚方法,用的是 virtual 关键字。它的特点是(三个相同):相同的方法名、相同的参数列表、相同的返回值
2、虚方法:即为基类中定义的允许在派生类中重写的方法,使用virtual关键字定义。如:
3.抽象方法:在基类中定义的并且必须在派生类中重写的方法,使用 abstract 关键字定义。如:
注意:抽象方法只能在抽象类中定义,如果不在抽象类中定义,则会报出如下错误:
··················
1、值类型与引用类型
值类型:struct、enum、int、float、char、bool、decimal
什么是值类型:
进一步研究文档,你会发现所有的结构都是抽象类型System.ValueType的直接派生类,而System.ValueType本身又是直接从System.Object派生的。根据定义所知,所有的值类型都必须从System.ValueType派生,所有的枚举都从System.Enum抽象类派生,而后者又从System.ValueType派生。
所有的值类型都是隐式密封的(sealed),目的是防止其他任何类型从值类型进行派生。
基于值类型的变量直接包含值。 [2] 将一个值类型变量赋给另一个值类型变量时,将复制包含的值。这与引用类型变量的赋值不同,引用类型变量的赋值只复制对对象的引用,而不复制对象本身。
所有的值类型均隐式派生自SystemValueType。
引用类型:class、delegate、interface、array、object、string
在c#中所有的类都是引用类型,包括接口。
委托(Delegate)特别用于实现事件和回调方法。所有的委托(Delegate)都派生自 System.Delegate 类。
3、装箱与拆箱https://www.cnblogs.com/zjtao/p/11345442.html
4、一种最普通的场景是,调用一个含类型为Object的参数的方法,该Object可支持任意为型,以便通用。当你需要将一个值类型(如Int32)传入时,需要装箱。
另一种用法是,一个非泛型的容器,同样是为了保证通用,而将元素类型定义为Object。于是,要将值类型数据加入容器时,需要装箱。
装箱:把值类型转换成引用类型
拆箱:把引用类型转换成值类型
装箱:对值类型在堆中分配一个对象实例,并将该值复制到新的对象中。
(1)第一步:新分配托管堆内存(大小为值类型实例大小加上一个方法表指针。
(2)第二步:将值类型的实例字段拷贝到新分配的内存中。
(3)第三步:返回托管堆中新分配对象的地址。这个地址就是一个指向对象的引用了。
拆箱:检查对象实例,确保它是给定值类型的一个装箱值。将该值从实例复制到值类型变量中。
在装箱时是不需要显式的类型转换的,不过拆箱需要显式的类型转换。
1.1 隐式数值转换
隐式数值转换包括以下几种:
●从sbyte类型到short,int,long,float,double,或decimal类型。
●从byte类型到short,ushort,int,uint,long,ulong,float,double,或decimal类型。
●从short类型到int,long,float,double,或decimal类型。
●从ushort类型到int,uint,long,ulong,float,double,或decimal类型。
●从int类型到long,float,double,或decimal类型。
●从uint类型到long,ulong,float,double,或decimal类型。
●从long类型到float,double,或decimal类型。
●从ulong类型到float,double,或decimal类型。
●从char类型到ushort,int,uint,long,ulong,float,double,或decimal类型。
●从float类型到double类型。
其中,从int,uint,或long到float以及从long到double的转换可能会导致精度下降,但决不会引起数量上的丢失。其它的隐式数值转换则不会
为什么要使用集合?
数组的局限性:
(1)数组元素个数是固定的,数组一但定义,就无法改变元素总数。如果需求变化,则必须修改源码
(2)如果初始化元素总数非常大,则会造成空间浪费。
集合的特点:
(1)根据需要动态增加元素个数,没有限制。
(2)可以用以存储多个对象,这是个十分重要的属性。
泛型List
List泛型集合的特点:
(1)表示泛型,T是Type的简写,表示当前不确定具体类型。
(2)可以根据用户的实际需要,确定当前集合需要存放的数据类型,一旦确定不可改变。
List泛型使用前的准备工作:
(1)引入命名空间:System.Collections.Generic
(2)确定存储类型:List students = new List();
4堆和栈
5、栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义,通常用于值类型;堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存的大小
引用类型总是存放在堆中。
存放在栈中时要管存储顺序,保持着先进后出的原则,他是一片连续的内存域,有系统自动分配和维护;
堆是无序的,他是一片不连续的内存域,有用户自己来控制和释放,如果用户自己不释放的话,当内存达到一定的特定值时,通过垃圾回收器(GC)来回收。
栈内存无需我们管理,也不受GC管理。当栈顶元素使用完毕,立马释放。而堆则需要GC清理。
使用引用类型的时候,一般是对指针进行的操作而非引用类型对象本身。但是值类型则操作其本身。
4、GC(Garbage Collection)
当程序需要更多的堆空间时,GC需要进行垃圾清理工作,暂停所有线程,找出所有无被引用的对象,进行清理,并通知栈中的指针重新指向地址排序后的对象。
GC只能处理托管内存资源的释放,对于非托管资源则不能使用GC进行回收,必须由程序员手动回收,例如FileStream或SqlConnection需要调用Dispose进行资源的回收。
5、CLR(Common Language Runtime)
公共语言运行库,负责资源管理(包括内存分配、程序及加载、异常处理、线程同步、垃圾回收等),并保证应用和底层操作系统的分离。
6、静态构造函数
最先被执行的构造函数,且在一个类里只允许有一个无参的静态构造函数
执行顺序:静态变量>静态构造函数>实例变量>实例构造函数
7、文件I/O
通过流的方式对文件进行读写操作
(1)FileStream
(2)StreamReader/StreamWriter
8、序列化与反序列化
序列化:将对象状态转换为可保持或传输的格式的过程。将对象实例的字段及类的名称转换成字节流,然后把字节流写入数据流。
通过序列化,可以执行如下操作:通过 Web 服务将对象发送到远程应用程序、在域之间传递对象、以 XML 字符串的形式传递对象通过防火墙、跨应用程序维护安全性或用户专属信息。
反序列化:将流转换为对象。
这两个过程结合起来,可以轻松地存储和传输数据。
9、线程同步
(1)方法一:阻塞(调用Sleep()或Join())
(2)方法二:加互斥锁lock
1 代码重用,继承类都能用抽象类定义的方法
2 灵活,某个继承类既可以继承改方法也可以派生一个新的
3 抽象类是所有继承类通用方法的最小集合,可以封装某一个继承类的实例用来进行传递
10、抽象类abstract class与接口interface的异同
相同点:
(1)都可以被继承
(2)都不能被实例化
(3)都可以包含方法的声明
不同点:
(1)抽象类被子类继承;接口被类实现
(2)抽象类只能被单个类继承;接口可继承接口,并可多继承接口
(3)抽象基类可以定义字段、属性、方法实现;接口只能定义属性、索引器、事件、和方法声明,不能包含字段
(4)抽象类可以做方法声明,也可做方法实现;接口只能做方法声明
(5)具体派生类必须覆盖(override)抽象基类的抽象方法;派生类必须实现接口的所有方法
(6)抽象类是一个不完整的类,需要进一步细化;接口是一个行为规范
(7)抽象类中的虚方法或抽象方法必须用public修饰;接口中的所有成员默认为public,不能有private修饰符(也不能用public进行显示修饰)
一、
(1) 抽象方法只作声明,抽象类可以做方法声明,也可做方法实现;接口只能做方法声明
(2) 抽象类不能被实例化
(3) 抽象类可以但不是必须有抽象属性和抽象方法,但是一旦有了抽象方法,就一定要把这个类声明为抽象类
(4) 具体派生类必须覆盖基类的抽象方法
(5) 抽象派生类可以覆盖基类的抽象方法,也可以不覆盖。如果不覆盖,则其具体派生类必须覆盖它们。如:
二、接 口
(1) 接口不能被实例化
(2) 接口只能包含方法声明
(3) 接口的成员包括方法、属性、索引器、事件
(4) 接口中不能包含常量、字段(域)、构造函数、析构函数、静态成员。如:
11、类class与结构体struct的异同
Class属于引用类型,是分配在内存的堆上的;
Struct属于值类型,是分配在内存的栈上的;不能从另外一个结构或者类继承,本身也不能被继承;没有默认的构造函数,但是可以添加构造函数;可以不使用new 初始化
12、using关键字的使用场景
(1)作为指令:用于导入其他命名空间中定义的类型或为命名空间创建别名
(2)作为语句:用于定义一个范围,在此范围的末尾将释放对象
13、new关键字的使用场景
(1)实例化对象
(2)隐藏父类方法
(3)new约束指定泛型类声明中的任何类型参数都必须具有公共的无参数构造函数
14、委托与事件
委托可以把一个方法作为参数传入另一个方法,可以理解为指向一个函数的引用;
事件是一种特殊的委托。
15、重载(overload)与重写(override)的区别
重载:是方法的名称相同,参数或参数类型不同;重载是面向过程的概念。
重写:是对基类中的虚方法进行重写。重写是面向对象的概念。
16、return执行顺序
try{} 里有一个return语句,那么finally{} 里的code在return前执行。
17、switch(expression)
其中expression支持任何数据类型,包括null。
18、反射Reflection
动态获取程序集信息。
19、property与attribute的区别
property是属性,用于存取类的字段;
attribute是特性,用来标识类,方法等的附加性质。
20、访问修饰符
(1)public 公有访问,不受任何限制。
(2)private 私有访问,只限于本类成员访问。
(3)protected 保护访问,只限于本类和子类访问。
(4)internal 内部访问,只限于当前程序集内访问。
21、static关键字的应用
对类有意义的字段和方法使用static关键字修饰,称为静态成员,通过类名加访问操作符“.”进行访问; 对类的实例有意义的字段和方法不加static关键字,称为非静态成员或实例成员。
注: 静态字段在内存中只有一个拷贝,非静态字段则是在每个实例对象中拥有一个拷贝。而方法无论是否为静态,在内存中只会有一份拷贝,区别只是通过类名来访问还是通过实例名来访问。
23、值传递与引用传递
值传递时,系统首先为被调用方法的形参分配内存空间,并将实参的值按位置一一对应地复制给形参,此后,被调用方法中形参值得任何改变都不会影响到相应的实参;
引用传递时,系统不是将实参本身的值复制后传递给形参,而是将其引用值(即地址值)传递给形参,因此,形参所引用的该地址上的变量与传递的实参相同,方法体内相应形参值得任何改变都将影响到作为引用传递的实参。
简而言之,按值传递不是值参数是值类型,而是指形参变量会复制实参变量,也就是会在栈上多创建一个相同的变量。而按引用传递则不会。可以通过 ref 和 out 来决定参数是否按照引用传递。
24、参数传递 ref 与 out 的区别
(1)ref指定的参数在函数调用时必须先初始化,而out不用
(2)out指定的参数在进入函数时会清空自己,因此必须在函数内部进行初始化赋值操作,而ref不用
总结:ref可以把值传到方法里,也可以把值传到方法外;out只可以把值传到方法外
注意:string作为特殊的引用类型,其操作是与值类型看齐的,若要将方法内对形参赋值后的结果传递出来,需要加上ref或out关键字。
三、数据库
https://www.cnblogs.com/qi123/p/9217010.html
通用数据库连接流程
第一,使用SqlConnection对象连接数据库;
第二,建立SqlCommand对象,负责SQL语句的执行和存储过程的调用;
第三,对SQL或存储过程执行后返回的“结果”进行操作。
对返回“结果”的操作可以分为两类:
一是用SqlDataReader直接一行一行的读取数据集;
二是DataSet联合SqlDataAdapter来操作数据库。
常用方法:
command.ExecuteNonQuery(): 返回受影响函数,如增、删、改操作;
command.ExecuteScalar():执行查询,返回首行首列的结果;
command.ExecuteReader():返回一个数据流(SqlDataReader对象)。
6、DataSet对象
6.1 SqlDataAdapter;
命名空间:System.Data.SqlClient.SqlDataAdapter;
SqlDataAdapter是SqlCommand和DataSet之间的桥梁,实例化SqlDataAdapter对象:
SqlConnection sqlCnt = new SqlConnection(connectString);
sqlCnt.Open();
// 创建SqlCommand
SqlCommand mySqlCommand = new SqlCommand();
mySqlCommand.CommandType = CommandType.Text;
mySqlCommand.CommandText = "select * from product";
mySqlCommand.Connection = sqlCnt;
// 创建SqlDataAdapter
SqlDataAdapter myDataAdapter = new SqlDataAdapter();
myDataAdapter.SelectCommand = mySqlCommand; // 为SqlDataAdapter对象绑定所要执行的SqlCommand对象
上述SQL可以简化为
SqlConnection sqlCnt = new SqlConnection(connectString);
sqlCnt.Open();
// 隐藏了SqlCommand对象的定义,同时隐藏了SqlCommand对象与SqlDataAdapter对象的绑定
SqlDataAdapter myDataAdapter = new SqlDataAdapter("select * from product", sqlCnt);
属性和方法
myDataAdapter.SelectCommand属性:SqlCommand变量,封装Select语句;
myDataAdapter.InsertCommand属性:SqlCommand变量,封装Insert语句;
myDataAdapter.UpdateCommand属性:SqlCommand变量,封装Update语句;
myDataAdapter.DeleteCommand属性:SqlCommand变量,封装Delete语句。
myDataAdapter.fill():将执行结果填充到Dataset中,会隐藏打开SqlConnection并执行SQL等操作。
6.2 SqlCommandBuilder;
命名空间:System.Data.SqlClient.SqlCommandBuilder。
对DataSet的操作(更改、增加、删除)仅是在本地修改,若要提交到“数据库”中则需要SqlCommandBuilder对象。用于在客户端编辑完数据后,整体一次更新数据。具体用法如下:
SqlCommandBuilder mySqlCommandBuilder = new SqlCommandBuilder(myDataAdapter); // 为myDataAdapter赋予SqlCommandBuilder功能
myDataAdapter.Update(myDataSet, "表名"); // 向数据库提交更改后的DataSet,第二个参数为DataSet中的存储表名,并非数据库中真实的表名(二者在多数情况下一致)。
6.3 DataSet
命名空间:System.Data.DataSet。
数据集,本地微型数据库,可以存储多张表。
使用DataSet第一步就是将SqlDataAdapter返回的数据集(表)填充到Dataset对象中:
SqlDataAdapter myDataAdapter = new SqlDataAdapter("select * from product", sqlCnt);
DataSet myDataSet = new DataSet(); // 创建DataSet
myDataAdapter.Fill(myDataSet, "product"); // 将返回的数据集作为“表”填入DataSet中,表名可以与数据库真实的表名不同,并不影响后续的增、删、改等操作
① 访问DataSet中的数据
SqlDataAdapter myDataAdapter = new SqlDataAdapter("select * from product", sqlCnt);
DataSet myDataSet = new DataSet();
myDataAdapter.Fill(myDataSet, "product");
DataTable myTable = myDataSet.Tables["product"];
foreach (DataRow myRow in myTable.Rows) {
foreach (DataColumn myColumn in myTable.Columns) {
Console.WriteLine(myRow[myColumn]); //遍历表中的每个单元格
}
}
四、
1、数据库操作的相关类
特定类:Connection,Command,CommandBuilder,DataAdapter,DataReader,Parameter,Transaction
共享类:DataSet,DataTable,DataRow,DataColumn,DataRealtion,Constraint,DataColumnMapping,DataTableMapping
(1)Connection:开启程序与数据库之间的连接。
(2)Command:对数据库发送一些指令。例如增删改查等指令,以及调用存在数据库中的存储过程等。
(3)DataAdapter:主要在数据源及DataSet 之间执行传输工作,通过Command 下达命令后,将取得的数据放进DataSet对象中。
(4)DataSet:这个对象可视为一个暂存区(Cache),可以把数据库中所查询到的数据保存起来,甚至可以将整个数据库显示出来,DataSet是放在内存中的。
备注:将DataAdapter对象当做DataSet 对象与数据源间传输数据的桥梁。DataSet包含若干DataTable、DataTableTable包含若干DataRow。
(5)DataReader:一笔向下循序的读取数据源中的数据。
总结:http://ADO.NET 使用Connection对象来连接数据库,使用Command或DataAdapter对象来执行SQL语句,并将执行的结果返回给DataReader或DataAdapter,然后再使用取得的DataReader或DataAdapter对象操作数据结果。
2、事务:将多个任务放在一块进行运行,将多个sql语句放在一块运行
3、索引
4、视图
5、存储过程
插入
string sqlconn = "Data Source=.;Initial Catalog=claa;Integrated Security=True";
using (SqlConnection sqlcon = new SqlConnection(sqlconn))
{
sqlcon.Open();
string text = "Insert into Class values('李四','我很快乐')";
using (SqlCommand conn = new SqlCommand(text,sqlcon))
{
int number= conn.ExecuteNonQuery();
删除
string sql = "delete from Class where Class.cName='李四'";
using (SqlCommand conn = new SqlCommand(sql, con))
{
int i= conn.ExecuteNonQuery();
string connectionString = "Data Source=.;Initial Catalog=db_buiness;Integrated Security=True";
using (SqlConnection conn = new SqlConnection(connectionString))
{
conn.Open();
string commandText = "Update Class set cName=‘张三’ where id=2 ";
using (SqlCommand cmd = new SqlCommand(commandText,conn))
{
int num= cmd.ExecuteNonQuery();
三、数据结构(常用的排序算法)
1、冒泡排序
(1)原理
(2)实现代码
2、快速排序
(1)原理
(2)实现代码
五、软件开发流程
需求分析 --> 概要设计 --> 详细设计 --> 编码 --> 测试 --> 交付 --> 验收 --> 维护
熟悉API接口应用,封装.OCX、.Dll组件开发。
一、DLL 与应用程序
动态链接库(也称为 DLL ,即为“ Dynamic Link Library ”的缩写)是 Microsoft Windows 最重要的组成要素之一,打开 Windows 系统文件夹,你会发现文件夹中有很多 DLL 文件, Windows 就是将一些主要的系统功能以 DLL 模块的形式实现。
动态链接库是不能直接执行的,也不能接收消息,它只是一个独立的文件,其中包含能被程序或其它 DLL 调用来完成一定操作的函数 ( 方法。注: C# 中一般称为“方法” ) ,但这些函数不是执行程序本身的一部分,而是根据进程的需要按需载入,此时才能发挥作用。
DLL 只有在应用程序需要时才被系统加载到进程的虚拟空间中,成为调用进程的一部分,此时该 DLL 也只能被该进程的线程访问,它的句柄可以被调用进程所使用,而调用进程的句柄也可以被该 DLL 所使用。在内存中,一个 DLL 只有一个实例,且它的编制与具体的编程语言和编译器都没有关系,所以可以通过 DLL 来实现混合语言编程。 DLL 函数中的代码所创建的任何对象(包括变量)都归调用它的线程或进程所有。
下面列出了当程序使用 DLL 时提供的一些优点: [1]
1) 使用较少的资源
当多个程序使用同一个函数库时, DLL 可以减少在磁盘和物理内存中加载的代码的重复量。这不仅可以大大影响在前台运行的程序,而且可以大大影响其他在 Windows 操作系统上运行的程序。
2) 推广模块式体系结构
DLL 有助于促进模块式程序的开发。这可以帮助您开发要求提供多个语言版本的大型程序或要求具有模块式体系结构的程序。模块式程序的一个示例是具有多个可以在运行时动态加载的模块的计帐程序。
3) 简化部署和安装
当 DLL 中的函数需要更新或修复时,部署和安装 DLL 不要求重新建立程序与该 DLL 的链接。此外,如果多个程序使用同一个 DLL ,那么多个程序都将从该更新或修复中获益。当您使用定期更新或修复的第三方 DLL 时,此问题可能会更频繁地出现。
1.封装自己的dll;
a.打开visual studio - 文件 - 新建 - 项目- 类库 - 名称MyTestDll;
b.右键Class1.cs - 修改为 TestDll.cs;
c.在里面写一个方法,如:
namespace MyTestDll
{
public static class TestDll
{
///
/// 比较两个对象的大小
///
///
///
public static T Maximun(T t1, T t2)
{
try
{
if (t1.CompareTo(t2) > 0)
{
return t1;
}
else
{
return t2;
}
}
catch (System.Exception ex)
{
return default(T);
}
}
}
}
d.保存 - 生成解决方案;
e.在Debug文件夹下就会有一个MyTestDll.dll文件,把它放在需要引用的工程;
2.调用装的dll文件;
a.打开visual studio - 文件 - 新建 - 项目- 控制台应用程序;
b.将MyTestDll.dll文件放在DeBug文件夹下面;
c.引用 - 添加引用 - 浏览 - 将MyTestDll.dll添加进来;
d.引用命令空间using MyTestDll;
主程序代码:
static void Main(string[] args)
{
int var = TestDll
Console.WriteLine("{0}", var);
Console.ReadKey();
}
运行结果:
按F2查看封装的TestDll
六、其他(了解)
1、.NET Core 与 .NET Framework 的区别
.NET Core 就是 .NET Framework 的开源且跨平台版本。但微软毕竟不能维护两个不同的分支,一个跑在Windows上,一个跑在Linux(Unix Like)系统上,所以微软抽象出来一个标准库.NET Standard Library,.NET Core 与 .NET Framework 都必须实现标准库的API ,就这样.NET Core、.NET Framework、Xamarin成了三兄弟,分别为不同的平台服务。
ASP.NET
ASP.NET 是新一代 ASP 。它与经典 ASP 是不兼容的,但 ASP.NET 可能包括经典 ASP。
ASP.NET 页面是经过编译的,这使得它们的运行速度比经典 ASP 快。
ASP.NET 具有更好的语言支持,有一大套的用户控件和基于 XML 的组件,并集成了用户身份验证。
ASP.NET 页面的扩展名是 .aspx ,通常是用 VB (Visual Basic) 或者 C# (C sharp) 编写。
在 ASP.NET 中的控件可以用不同的语言(包括 C++ 和 Java)编写。
当浏览器请求 ASP.NET 文件时,ASP.NET 引擎读取文件,编译和执行脚本文件,并将结果以普通的 HTML 页面返回给浏览器。
WinService、WebService开发
二、字段的使用
1.关于字段
a.字段又称为:“成员变量”,一般在类的内部做数据交互使用。
b.字段命名规范:camel命名法(首单词字母小写)。
2.通俗的理解:
私有化:字段就好比我们的个人财产,仅供个人使用,所以一般是private修饰。
添加标准:根据程序的功能需求,具体来添加需要的不同类型的字段。
四、属性
1.属性的使用
作用:在面向对象设计中主要使用属性描述对象的静态特征。
要求:一般采用Pascal命名法(首字母大写),数据类型要和对应的字段要一致。
2.属性的理解
a.属性其实就是外界访问私有字段的入口,属性本身不保存任何数据,在对属性赋值和读取的时候其实就是操作的对应私有字段。
图例:
b.属性本质其实就是一个方法,通过get和set方法来操作对应的字段,通过反编译工具我们可以看出,如图:
1.你们对于应届毕业生的能力要求一般是多少,是要有完整的项目经历和扎实的基础知识之间,你们会选什么?
2.公司的在.net方向的技术栈主要在哪方面,实在winform桌面开发?
3.如果工作的话,我会在哪里工作,是在上海?
三层架构是哪三层
界面层(User Interface layer):也就是UI层
业务逻辑层(Business Logic Layer)
数据访问层(Data access layer):实现对于数据库数据的访问和数据存储
Model类库:实现各个实体类
1、 各层的任务
数据访问层:使用ADO.NET中的数据操作类,为数据库中的每个表,设计1个数据访问类。类中实现:记录的插入、删除、单条记录的查询、记录集的查询、单条记录的有无判断等基本的数据操作方法。对于一般的管理信息软件,此层的设计是类似的,包含的方法也基本相同。此层的任务是:封装每个数据表的基本记录操作,为实现业务逻辑提供数据库访问基础。
业务逻辑层:为用户的每个功能模块,设计1个业务逻辑类,此时,需要利用相关的数据访问层类中,记录操作方法的特定集合,来实现每个逻辑功能。
界面层:根据用户的具体需求,为每个功能模块,部署输入控件、操作控件和输出控件,并调用业务逻辑层中类的方法实现功能。
2、 层之间的调用关系
数据访问层的类,直接访问数据库,实现基本记录操作。
业务逻辑层的类,调用相关的数据访问类,实现用户所需功能。
界面层:部署控件后,调用业务逻辑层的类,实现功能。
将应用程序的功能分层后,对于固定的DBMS,数据访问层基本可以不变,一旦用户的需求改变,首先修改业务逻辑层,界面层稍做改动即可。这种做法使程序的可复用性、可修改性,都得到了很好的改善,大大提高了软件工程的效率。
Html
HTML 是用来描述网页的一种语言。‘
HTML 标记标签通常被称为 HTML 标签 (HTML tag)。
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。CSS不仅可以静态地修饰网页,还可以配合各种脚本语言动态地对网页各元素进行格式化。 [1]
CSS 能够对网页中元素位置的排版进行像素级精确控制,支持几乎所有的字体字号样式,拥有对网页对象和模型样式编辑的能力。 [2]
JavaScript是一种属于网络的脚本语言,已经被广泛用于Web应用开发,常用来为网页添加各式各样的动态功能,为用户提供更流畅美观的浏览效果。通常JavaScript脚本是通过嵌入在HTML中来实现自身的功能的。
数据库用户和登录名即相关又不相关
数据库访问效率优化方法:
C#网页端做后台
MVC模式与三层架构的区别
转载Fast_Snail 最后发布于2017-03-10 09:31:09 阅读数 1076 收藏
展开
之前总是混淆MVC表现模式和三层架构模式,为此记录下。
三层架构和MVC是有明显区别的,MVC应该是展现模式(三个加起来以后才是三层架构中的UI层) 三层架构(3-tier application) 通常意义上的三层架构就是将整个业务应用划分为:表现层(UI)、业务逻辑层(BLL)、数据访问层(DAL)。区分层次的目的即为了“高内聚,低耦合”的思想。 1、表现层(UI):通俗讲就是展现给用户的界面,即用户在使用一个系统的时候他的所见所得。 2、业务逻辑层(BLL):针对具体问题的操作,也可以说是对数据层的操作,对数据业务逻辑处理。 3、数据访问层(DAL):该层所做事务直接操作数据库,针对数据的增添、删除、修改、更新、查找等。
MVC是 Model-View-Controller,严格说这三个加起来以后才是三层架构中的UI层,也就是说,MVC把三层架构中的UI层再度进行了分化,分成了控制器、视图、实体三个部分,控制器完成页面逻辑,通过实体来与界面层完成通话;而C层直接与三层中的BLL进行对话。
mvc可以是三层中的一个表现层框架,属于表现层。三层和mvc可以共存。 三层是基于业务逻辑来分的,而mvc是基于页面来分的。 MVC主要用于表现层,3层主要用于体系架构,3层一般是表现层、中间层、数据层,其中表现层又可以分成M、V、C,(Model View Controller)模型-视图-控制器
曾把MVC模式和Web开发中的三层结构的概念混为一谈,直到今天才发现一直是我的理解错误。MVC模式是GUI界面开发的指导模式,基于表现层分离的思想把程序分为三大部分:Model-View-Controller,呈三角形结构。Model是指数据以及应用程序逻辑,View是指 Model的视图,也就是用户界面。这两者都很好理解,关键点在于Controller的角色以及三者之间的关系。在MVC模式中,Controller和View同属于表现层,通常成对出现。Controller被设计为处理用户交互的逻辑。一个通常的误解是认为Controller负责处理View和Model的交互,而实际上View和Model之间是可以直接通信的。由于用户的交互通常会涉及到Model的改变和View的更新,所以这些可以认为是Controller的副作用。
MVC是表现层的架构,MVC的Model实际上是ViewModel,即供View进行展示的数据。 ViewModel不包含业务逻辑,也不包含数据读取。 而在N层架构中,一般还会有一个Model层,用来与数据库的表相对应,也就是所谓ORM中的O。这个Model可能是POCO,也可能是包含一些验证逻辑的实体类,一般也不包含数据读取。进行数据读取的是数据访问层。而作为UI层的MVC一般不直接操作数据访问层,中间会有一个业务逻辑层封装业务逻辑、调用数据访问层。UI层(Controller)通过业务逻辑层来得到数据(Model),并进行封装(ViewModel),然后选择相应的View。
MVC本来是存在于Desktop程序中的,M是指数据模型,V是指用户界面,C则是控制器。使用MVC的目的是将M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式。比如一批统计数据你可以分别用柱状图、饼图来表示。C存在的目的则是确保M和V的同步,一旦M改变,V应该同步更新。 MVC如何工作 MVC是一个设计模式,它强制性的使应用程序的输入、处理和输出分开。使用MVC应用程序被分成三个核心部件:模型、视图、控制器。它们各自处理自己的任务。 视图V 视图是用户看到并与之交互的界面。对老式的Web应用程序来说,视图就是由HTML元素组成的界面,在新式的Web应用程序中,HTML依旧在视图中扮演着重要的角色,但一些新的技术已层出不穷,它们包括Macromedia Flash和象XHTML,XML/XSL,WML等一些标识语言和Web services. 如何处理应用程序的界面变得越来越有挑战性。MVC一个大的好处是它能为你的应用程序处理很多不同的视图。在视图中其实没有真正的处理发生,不管这些数据是联机存储的还是一个雇员列表,作为视图来讲,它只是作为一种输出数据并允许用户操纵的方式。 模型M 模型表示企业数据和业务规则。在MVC的三个部件中,模型拥有最多的处理任务。被模型返回的数据是中立的,就是说模型与数据格式无关,这样一个模型能为多个视图提供数据。由于应用于模型的代码只需写一次就可以被多个视图重用,所以减少了代码的重复性。 控制器C 控制器接受用户的输入并调用模型和视图去完成用户的需求。所以当单击Web页面中的超链接和发送HTML表单时,控制器本身不输出任何东西和做任何处理。它只是接收请求并决定调用哪个模型构件去处理请求,然后再确定用哪个视图来显示返回的数据。
模型Model 模型是应用程序的主体部分。模型表示业务数据,或者业务逻辑. 实现具体的业务逻辑、状态管理的功能。 视图View 视图是应用程序中用户界面相关的部分,是用户看到并与之交互的界面。 就是与用户实现交互的页面,通常实现数据的输入和输出功能。 控制器controller 控制器工作就是根据用户的输入,控制用户界面数据显示和更新model对象状态。起到控制整个业务流程的作用,实现View层跟Model层的协同工作。
3层架构指:表现层(显示层) 业务逻辑层 数据访问层(持久化)如果大家非要“生搬硬套”把它和MVC扯上关系话那我就只能在这里"强扭这个瓜"了即: V 3层架构中"表现层"aspx页面对应MVC中View(继承的类不一样) C 三层架构中"表现层"的aspx.cs页面(类)对应MVC中的Controller,理解这一点并不难,大家想一想我们以前写过的 Redirect,当然它本身就是跳转了一些链接页面,而MVC中的Controller要做的更爽,它控制并显示输出了一个视图。即然所起到的作用都是对业务流程和显示信息的控制,只不过是实现手段不同而已。 M 3层架构中业务逻辑层和数据访问层对应MVC中Model(必定View和Controller已找到“婆家”剩下Model只能是业务逻辑层和数据访问层了)
为什么要使用 MVC 大部分Web应用程序都是用像ASP,PHP,或者CFML这样的过程化(自PHP5.0版本后已全面支持面向对象模型)语言来创建的。它们将像数据库查询语句这样的数据层代码和像HTML这样的表示层代码混在一起。经验比较丰富的开发者会将数据从表示层分离开来,但这通常不是很容易做到的,它需要精心的计划和不断的尝试。MVC从根本上强制性的将它们分开。尽管构造MVC应用程序需要一些额外的工作,但是它给我们带来的好处是无庸质疑的。 首先,最重要的一点是多个视图能共享一个模型,现在需要用越来越多的方式来访问你的应用程序。对此,其中一个解决之道是使用MVC,无论你的用户想要Flash界面或是 WAP 界面;用一个模型就能处理它们。由于你已经将数据和业务规则从表示层分开,所以你可以最大化的重用你的代码了。 由于模型返回的数据没有进行格式化,所以同样的构件能被不同界面使用。例如,很多数据可能用HTML来表示,但是它们也有可能要用Adobe Flash和WAP来表示。模型也有状态管理和数据持久性处理的功能,例如,基于会话的购物车和电子商务过程也能被Flash网站或者无线联网的应用程序所重用。 因为模型是自包含的,并且与控制器和视图相分离,所以很容易改变你的应用程序的数据层和业务规则。如果你想把你的数据库从MySQL移植到Oracle,或者改变你的基于RDBMS数据源到LDAP,只需改变你的模型即可。一旦你正确的实现了模型,不管你的数据来自数据库或是LDAP服务器,视图将会正确的显示它们。由于运用MVC的应用程序的三个部件是相互独立,改变其中一个不会影响其它两个,所以依据这种设计思想你能构造良好的松耦合的构件。 对我来说,控制器也提供了一个好处,就是可以使用控制器来联接不同的模型和视图去完成用户的需求,这样控制器可以为构造应用程序提供强有力的手段。给定一些可重用的模型和视图,控制器可以根据用户的需求选择模型进行处理,然后选择视图将处理结果显示给用户。
拿一个简单的登陆模块说,需求是你输入一个用户名、密码,如果输入的跟预先定义好的一样,那么就进入到正确页面,如果不一样,就提示个错误信息“你Y别在这儿蒙我,输入的不对!”。 V 这个小小的模块中,起始的输入用户名密码的页面跟经过校验后显示的页面就相当于View C 而这里还需要一个controller页面,就是用于接收输入进来的用户名密码,还有经过校验后返回的一个flg(此flg就是用于判断你输入的是否正确,而跳转到相应的页面的) M 最后还缺一个Model,那么就是你那个用于校验的类了,他就是处理你输入的是否跟预先订好的一样不一样的,之后返回一个flg。 这样就完全实现了逻辑跟页面的分离,我页面不管你咋整,反正我就一个显示,而controller呢也不管你Model咋判断对不对,反正我给你了用户名跟密码,你就得给我整回来一个flg来,而Medol呢,则是反正你敢给我个用户名跟密码,我就给你整过去个flg
m 提供数据,数据之间的关系,转化等。并可以通知视图和控制器自己哪些地方发生了变化。 v 提供显示,能根据m的改变来更新自己 c 比如视图做了点击一个按钮,会先发给这个视图的控制器,然后这个控制器来决定做什么操作(让模型更新数据,控制视图改变) mvc是一个复合模式 mv,mc都是观察者模式 m内部的组件组合模式 vc之间是策略模式(可以随时更换不同的控制器)
MVC模式是上世纪70年代提出,最初用于Smalltalk平台上的。 MVC是表现模式,是用来向用户展现的许多组建的一个模式(UI/Presentation Patten) MVC有三种角色: Model:用来储存数据的组件(与领域模型概念不同,两者会相互交叉) View:从Model中获取数据进行内容展示的组件。同样的Model在不同的View下可展示不同的效果。获取Model的状态,而不对其进行操作。 Controller:接受并处理用户指令(操作Model(业务)),选择一个View进行操作。
MVC概述:协作 存在单向引用,例如Model不知道View和Controller的存在。View不知道Controller的存在。这就隔离了表现和数据。View和controller是单向引用。而实际中View和Controller也是有数据交互的。
MVC的重要特点是分离。两种分离: View和数据(Model)的分离 使用不同的View对相同的数据进行展示;分离可视和不可视的组件,能够对Model进行独立测试。因为分离了可视组件减少了外部依赖利于测试。(数据库也是一种外部组件) View和表现逻辑(Controller)的分离 Controller是一个表现逻辑的组件,并非一个业务逻辑组件。MVC可以作为表现模式也可以作为建构模式,意味这Controller也可以是业务逻辑。分离逻辑和具体展示,能够对逻辑进行独立测试。
MVC和三层架构 MVC与三层架构类似么? View-UI Layer | Controller-Bussiness Layer | Model-Data Access Layer 其实这样是错误的 MVC是表现模式(Presentation Pattern) 三层架构是典型的架构模式(Architecture Pattern) 三层架构的分层模式是典型的上下关系,上层依赖于下层。但MVC作为表现模式是不存在上下关系的,而是相互协作关系。即使将MVC当作架构模式,也不是分层模式。MVC和三层架构基本没有可比性,是应用于不同领域的技术。
MVC模式与三层架构:
ui (view)←(contorller)
bll (model)
3、列举ASP.NET 页面之间传递值的几种方式。
1.使用QueryString, 如....?id=1; response. Redirect()....
2.使用Session变量
3.使用Server.Transfer
4.Cookie传值
4、C#中的委托是什么?事件是不是一种委托?事件和委托的关系。
委托可以把一个方法作为参数代入另一个方法。
委托可以理解为指向一个函数的指针。
委托和事件没有可比性,因为委托是类型,事件是对象,下面说的是委托的对象(用委托方式实现的事件)和(标准的event方式实现)事件的区别。事件的内部是用委托实现的。因为对于事件来讲,外部只能“注册自己+=、注销自己-=”,外界不可以注销其他的注册者,外界不可以主动触发事件,因此如果用Delegate就没法进行上面的控制,因此诞生了事件这种语法。事件是用来阉割委托实例的,类比用一个自定义类阉割List。事件只能add、remove自己,不能赋值。事件只能+=、-=,不能= 。加分的补充回答:事件内部就是一个private的委托和add、remove两个方法
面试聊:用Reflector查看.Net的类的内部实现,解决问题。
5、override与重载(overload)的区别
重载是方法的名称相同。参数或参数类型不同,进行多次重载以适应不同的需要。重载(overload)是面向过程的概念。
Override 是进行基类中函数的重写。Override是面向对象的概念
6、C#中索引器是否只能根据数字进行索引?是否允许多个索引器参数?
参数的个数和类型都是任意的。加分的补充回答:用reflector反编译可以看出,索引器的内部本质上就是set_item、get_item方法。
基础知识:
索引的语法:
public string this[string s],通过get、set块来定义取值、赋值的逻辑
索引可以有多个参数、参数类型任意
索引可以重载。
如果只有get没有set就是只读的索引。
索引其实就是set_Item、get_Item两个方法。
7、属性和public字段的区别是什么?调用set方法为一个属性设值,然后用get方法读取出来的值一定是set进去的值吗?
属性可以对设值、取值的过程进行非法值控制,比如年龄禁止设值负数,而字段则不能进行这样的设置。虽然一般情况下get读取的值就是set设置的值,但是可以让get读取的值不是set设置的值的,极端的例子。Public Age{get{return 100;}set{}}。加分的补充回答:用reflector反编译可以看出,属性内部本质上就是set_、get_方法
class Person
{
public int Age
{
get
{
return 3;
}
set
{
}
}
}
Person p1 = new Person();
p1.Age = 30;
p1.Age++;
Console.Write(p1.Age);//输出3
必须手写掌握的代码(既包含拿电脑写,拿笔写):
手写三层架构
手写冒泡排序
手写AJAX:XMLHttpRequest
手写增删改查、SQLHelper
8、三层架构
通常意义上的三层架构就是将整个业务应用划分为:表现层(UI)、业务逻辑层(BLL)、数据访问层(DAL)。区分层次的目的即为了“高内聚,低耦合”的思想。表现层(UI):通俗讲就是展现给用户的界面,即用户在使用一个系统的时候的所见所得。业务逻辑层(BLL):针对具体问题的操作,也可以说是对数据层的操作,对数据业务逻辑处理。数据访问层(DAL):该层所做事务直接操作数据库,针对数据的增添、删除、修改、更新、查找等每层之间是一种垂直的关系。三层结构是N层结构的一种,一般来说,层次之间是向下依赖的,下层代码未确定其接口(契约)前,上层代码是无法开发的,下层代码接口(契约)的变化将使上层的代码一起变化。
优点: 分工明确,条理清晰,易于调试,而且具有可扩展性。
缺点: 增加成本。
9、什么是装箱(boxing)和拆箱(unboxing)? (*)
Object是引用类型,但是它的子类Int32竟然不能去Object能去的“要求必须是引用类型”
的地方,违反了继承的原则,所以需要把Int32装在Object中才能传递。
装箱:从值类型接口转换到引用类型。
拆箱:从引用类型转换到值类型。
object obj = null;//引用类型
obj = 1;//装箱,boxing。把值类型包装为引用类型。
int i1 = (int)obj;//拆箱。unboxing
2)下面三句代码有没有错,以inboxing或者unboxing为例,解释一下内存是怎么变化的
int i=10;
object obj = i;
int j = obj;
分析:在inboxing(装箱)时是不需要显式的类型转换的,不过unboxing(拆箱)需要显式的类型转换,所以第三行代码应该改为:
3 int j = (int)obj;
要掌握装箱与拆箱,就必须了解CTS及它的特点:
NET重要技术和基础之一的CTS(Common Type System)。CTS是为了实现在应用程序声明和使用这些类型时必须遵循的规则而存在的通用类型系统。.Net将整个系统的类型分成两大类 :值类型和引用类型。
CTS中的所有东西都是对象;所有的对象都源自一个基类——System.Object类型。值类型的一个最大的特点是它们不能为null,值类型的变量总有一个值。为了解决值类型不可以为null,引用类型可以为null的问题,微软在.Net中引入了装箱和拆箱:装箱就是将值类型用引用类型包装起来转换为引用类型;而从引用类型中拿到被包装的值类型数据进行拆箱。
10、CTS、CLS、CLR分别作何解释(*)把英文全称背过来。
C#和.Net的关系。
C#只是抽象的语言,可以把C#编译生成Java平台的二进制代码,也可以把Java代码编译生成.Net平台的二进制代码。所以C#只是提供了if、while、+-*/、定义类、int、string等基础的语法,而Convert.ToInt32、FileStream、SqlConnection、String.Split等都属于.Net的东西。深蓝色是C#的,浅蓝色是.Net的。
C# new→IL:newobj
C# string →.Net中的String
类型的差别:.net中的Int32在C#中是int,在VB.Net中是Integer。String、Int32等公共类型。
语法的差别:IL中创建一个对象的方法是L_0001: newobj instance void 索引.C1::.ctor()
C#中是new C1();VB.net中是 Dim c1 As New C1
CTS:Common Type System 通用类型系统。Int32、Int16→int、String→string、Boolean→bool。每种语言都定义了自己的类型,.Net通过CTS提供了公共的类型,然后翻译生成对应的.Net类型。
CLS:Common Language Specification 通用语言规范。不同语言语法的不同。每种语言都有自己的语法,.Net通过CLS提供了公共的语法,然后不同语言翻译生成对应的.Net语法。
CLR:Common Language Runtime 公共语言运行时,就是GC、JIT等这些。有不同的CLR,比如服务器CLR、Linux CLR(Mono)、Silverlight CLR(CoreCLR)。相当于一个发动机,负责执行IL。
11、在dotnet中类(class)与结构(struct)的异同?
Class可以被实例化,属于引用类型,是分配在内存的堆上的。类是引用传递的。
Struct属于值类型,是分配在内存的栈上的。结构体是复制传递的。加分的回答:Int32、Boolean等都属于结构体
12、堆和栈的区别?
栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义;局部值类型变量、值类型参数等都在栈内存中。
堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存的大小。
13、能用foreach遍历访问的对象的要求
需要实现IEnumerable接口或声明GetEnumerator方法的类型。
14、GC是什么? 为什么要有GC?
C/C++中由程序员进行对象的回收像学校食堂中由学生收盘子,.Net中由GC进行垃圾回收像餐馆中店员去回收。
GC是垃圾收集器(Garbage Collection)。程序员不用担心内存管理,因为垃圾收集器会自动进行管理。GC只能处理托管内存资源的释放,对于非托管资源则不能使用GC进行回收,必须由程序员手工回收,一个例子就是FileStream或者SqlConnection需要程序员调用Dispose进行资源的回收。
要请求垃圾收集,可以调用下面的方法:GC.Collect()一般不需要手动调用GC.Collect()。当一个对象没有任何变量指向(不再能使用)的时候就可以被回收了。
基础知识:当没有任何变量指向一个对象的时候对象就可以被回收掉了,但不一定会立即被回收。
object obj = new object();//只有new才会有新对象
Console.WriteLine(obj);
object obj2 = obj;
obj = null;
obj2 = null;
Console.WriteLine();
15、值类型和引用类型的区别?
1.将一个值类型变量赋给另一个值类型变量时,将复制包含的值。引用类型变量的赋值只复制对对象的引用,而不复制对象本身。
2.值类型不可能派生出新的类型:所有的值类型均隐式派生自 System.ValueType。但与引用类型相同的是,结构也可以实现接口。
3.值类型不可能包含 null 值:然而,可空类型功能允许将 null 赋给值类型。
4.每种值类型均有一个隐式的默认构造函数来初始化该类型的默认值。
16、C#中的接口和类有什么异同。
不同点:
不能直接实例化接口。
接口不包含方法的实现。
接口可以多继承,类只能单继承。
类定义可在不同的源文件之间进行拆分。
相同点:
接口、类和结构都可以从多个接口继承。
接口类似于抽象基类:继承接口的任何非抽象类型都必须实现接口的所有成员。
接口和类都可以包含事件、索引器、方法和属性。
基础知识:接口只能定义方法(只能定义行为,不能定义实现也就是字段),因为事件、索引器、属性本质上都是方法,所以接口中也可以定义事件、索引器、属性。
17、abstract class和interface有什么区别?
相同点:
都不能被直接实例化,都可以通过继承实现其抽象方法。
不同点:
接口支持多继承;抽象类不能实现多继承。
接口只能定义行为;抽象类既可以定义行为,还可能提供实现。
接口只包含方法(Method)、属性(Property)、索引器(Index)、事件(Event)的签名,但不能定义字段和包含实现的方法;
抽象类可以定义字段、属性、包含有实现的方法。
接口可以作用于值类型(Struct)和引用类型(Class);抽象类只能作用于引用类型。例如,Struct就可以继承接口,而不能继承类。
加分的补充回答:讲设计模式的时候SettingsProvider的例子。
18、是否可以继承String类?
String类是sealed类故不可以继承。
19、int、DateTime、string是否可以为null?
null表示“不知道”,而不是“没有”。没有年龄和不知道年龄是不一样。
数据库中null不能用0表示。0岁和不知道多少岁不一样。
Sex is zero。《色即是空》
//int i1 = null;
//int? i2 = null;//值类型后加?就成了可空数据类型
////int i3 = i2;//所以把可空的赋值给一定不能为空的会报错。
//int i4 = (int)i2;//可以显式转换,由程序员来保证“一定不为空”
//int? i5 = i4;//一定会成功!
//using()→try{]catch{}finally{}
//int?是微软的一个语法糖。是一种和int没有直接关系的Nullable类型
Nullable
Nullable
Console.WriteLine(d1==null);
int、DateTime不能,因为其为Struct类型,而结构属于值类型,值类型不能为null,只有引用类型才能被赋值null。string可以为null。
C#中int等值类型不可以为null、而数据库中的int可以为null,这就是纠结的地方。int?就变成了可空的int类型。bool?、DateTime?
int i1 = 3;
int? i2 = i1;
//int i3 = i2;//不能把可能为空的赋值给一定不能为空的变量
int i3 = (int)i2;//显式转换
可空数据类型经典应用场景:三层中的Model属性的设计。
int?翻译生成.Net的Nullable
20、using关键字有什么用?什么是IDisposable?
using可以声明namespace的引入,还可以实现非托管资源的释放,实现了IDisposiable的类在using中创建,using结束后会自动调用该对象的Dispose方法,释放资源。加分的补充回答:using其实等价于try……finally,用起来更方便。
21、XML 与 HTML 的主要区别
-
XML是区分大小写字母的,HTML不区分。
-
在HTML中,如果上下文清楚地显示出段落或者列表键在何处结尾,那么你可以省略
或者 之类的结束 标记。在XML中,绝对不能省略掉结束标记。
HTML:
XML:
-
在XML中,拥有单个标记而没有匹配的结束标记的元素必须用一个 / 字符作为结尾。这样分析器就知道不用 查找结束标记了。
-
在XML中,属性值必须分装在引号中。在HTML中,引号是可用可不用的。
-
在HTML中,可以拥有不带值的属性名。在XML中,所有的属性都必须带有相应的值。
XML是用来存储和传输数据的
HTML是用来显示数据的
如果使用了完全符合XML语法要求的HTML,那么就叫做符合XHTML标准。符合XHTML标准的页面有利于SEO。
22、string str = null 与 string str =””说明其中的区别。
答:string str = null 是不给他分配内存空间,而string str = "" 给它分配长度为空字符串的内存空间。 string str = null没有string对象,string str = “”有一个字符串对象。
string s3 = string.Empty;//反编译发现,string.Empty就是在类构造函数中 Empty = "";
23、写出一条Sql语句:取出表A中第31到第40记录(SQLServer,以自动增长的ID作为主键,注意:ID可能不是连续的。
答:解1: select top 10 * from A where id not in (select top 30 id from A)
演变步骤:
1)select top 30 id from T_FilterWords--取前条
2)select * from T_FilterWords
where id not in (select top 30 id from T_FilterWords)--取id不等于前三十条的
--也就是把前条排除在外
3)select top 10 * from T_FilterWords
where id not in (select top 30 id from T_FilterWords)
--取把前条排除在外的前条,也就是-40条
解2: select top 10 * from A where id > (select max(id) from (select top 30 id from A )as A)
解答3:用ROW_NUMBER实现
24、在.Net中所有可序列化的类都被标记为
[serializable]
25、什么是code-Behind技术。
就是代码隐藏,在ASP.NET中通过ASPX页面指向CS文件的方法实现显示逻辑和处理逻辑的分离,这样有助于web应用程序的创建。比如分工,美工和编程的可以个干各的,不用再像以前asp那样都代码和html代码混在一起,难以维护。code-Behind是基于部分类技术实现的,在我的项目的三层代码生成器中用到了部分类。
26、接口是一种引用类型,在接口中可以声明( a),但不可以声明公有的域或私有的成员变量。
a) 方法、属性、索引器和事件;
b) 索引器和字段;
c) 事件和字段;
解读:接口中不能声明字段只能声明方法,属性、索引器和事件 最终都编译生成方法。因为字段属于实现层面的东西,只有存取值的时候才会用到字段,所以中接口中不能定义字段。
27、在ADO.NET中,对于Command对象的ExecuteNonQuery()方法和ExecuteReader()方法,下面叙述错误的是(c)。
a) insert、update、delete等操作的Sql语句主要用ExecuteNonQuery()方法来执行;
b) ExecuteNonQuery()方法返回执行Sql语句所影响的行数。
c) Select操作的Sql语句只能由ExecuteReader()方法来执行;
d) ExecuteReader()方法返回一个DataReader对象;
拿SQLHelper实现一下。
28、StringBuilder 和 String 的区别?
答:String 在进行运算时(如赋值、拼接等)会产生一个新的实例,而 StringBuilder 则不会。所以在大量字符串拼接或频繁对某一字符串进行操作时最好使用 StringBuilder,不要使用 String
如果要操作一个不断增长的字符串,尽量不用String类,改用StringBuilder类。两个类的工作原理不同:String类是一种传统的修改字符串的方式,它确实可以完成把一个字符串添加到另一个字符串上的工作没错,但是在.NET框架下,这个操作实在是划不来。因为系统先是把两个字符串写入内存,接着删除原来的String对象,然后创建一个String对象,并读取内存中的数据赋给该对象。这一来二去的,耗了不少时间。而使用System.Text命名空间下面的StringBuilder类就不是这样了,它提供的Append方法,能够在已有对象的原地进行字符串的修改,简单而且直接。当然,一般情况下觉察不到这二者效率的差异,但如果你要对某个字符串进行大量的添加操作,那么StringBuilder类所耗费的时间和String类简直不是一个数量级的。
29、请叙述属性与索引器的区别。 (*)
属性 索引器
通过名称标识。 通过签名标识。
通过简单名称或成员访问来访问。 通过元素访问来访问。
可以为静态成员或实例成员。 必须为实例成员。
属性的 get 访问器没有参数。 索引器的 get 访问器具有与索引器相同的形参表。
属性的 set 访问器包含隐式 value 参数。 除了 value 参数外,索引器的 set 访问器还具有与索引器相同的形参表。
30、请解释ASP。NET中的web页面与其隐藏类之间的关系?
一个ASP.NET页面一般都对应一个隐藏类,一般都在ASP.NET页面的声明中指定了隐藏类例如一个页面Tst1.aspx的页面声明如下
<%@ Page language="c#" Codebehind="Tst1.aspx.cs" AutoEventWireup="false" Inherits="T1.Tst1" %>
Codebehind="Tst1.aspx.cs" 表明经编译此页面时使用哪一个代码文件
Inherits="T1.Tst1" 表用运行时使用哪一个隐藏类
aspx页面会编译生成一个类,这个类从隐藏类继承。
31、您在什么情况下会用到虚方法?它与接口有什么不同?
答案:子类重新定义父类的某一个方法时,必须把父类的方法定义为virtual
在定义接口中不能有方法体,虚方法可以。
实现时,子类可以不重新定义虚方法,但如果一个类继承接口,那必须实现这个接口。
32、DataReader和DataSet的异同?
DataReader使用时始终占用SqlConnection,在线操作数据库
每次只在内存中加载一条数据,所以占用的内存是很小的
是只进的、 只读的
DataSet则是将数据一次性加载在内存中.抛弃数据库连接..读取完毕即放弃数据库连接(非连接模式)
DataSet将数据全部加载在内存中.所以比较消耗内存...但是确比DataReader要灵活..可以动态的添加行,列,数据.对数据库进行 回传更新操作(动态操作读入到内存的数据)
33、public static const int A = 1;这段代码有错误么?
错误:const不能被修饰为static ;因为定义为常量 (const )后就是静态的(static )。
34、传入某个属性的set方法的隐含参数的名称是什么?
value,它的类型和属性所声名的类型相同。
35、C#支持多重继承么?
类之间不支持,接口之间支持。类对接口叫做实现,不叫继承。 类是爹、接口是能力,能有多个能力,但不能有多个爹。
36、C#中所有对象共同的基类是什么?
System.Object
37、通过超链接怎样传递中文参数?
答:用URL编码,通过QueryString传递,用urlencode编码 用urldecode解码
38、string、String;int、Int32;Boolean、bool的区别
String、Int32、Boolean等都属于.Net中定义的类,而string、int、bool相当于C#中对这些类定义的别名。CTS。
39、Server.Transfer和Response.Redirect的区别是什么?(常考)
答: Server.Transfer仅是服务器中控制权的转向,在客户端浏览器地址栏中不会显示出转向后的地址;Response.Redirect则是完全的跳转,浏览器将会得到跳转的地址,并重新发送请求链接。这样,从浏览器的地址栏中可以看到跳转后的链接地址。
Server.Transfer是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器,浏览器根本不知道服务器发送的内容是从哪儿来的,所以它的地址栏中还是原来的地址。 这个过程中浏览器和Web服务器之间经过了一次交互。
Response.Redirect就是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,一般来说浏览器会用刚才请求的所有参数重新请求。这个过程中浏览器和Web服务器之间经过了两次交互。
Server.Transfer不可以转向外部网站,而Response.Redirect可以。
Server.Execute效果和Server.Transfer类似,但是是把执行的结果嵌入当前页面。
40、不是说字符串是不可变的吗?string s="abc";s="123"不就是变了吗?
String是不可变的在这段代码中,s原先指向一个String对象,内容是 "abc",然后我们将s指向"123",那么s所指向的那个对象是否发生了改变呢?答案是没有。这时,s不指向原来那个对象了,而指向了另一个 String对象,内容为"123",原来那个对象还存在于内存之中,只是s这个引用变量不再指向它了。
41、是否可以从一个static方法内部发出对非static方法的调用?
不可以。因为非static方法是要与对象关联在一起的,必须创建一个对象后,才可以在该对象上进行方法调用,而static方法调用时不需要创建对象,可以直接调用。也就是说,当一个static方法被调用时,可能还没有创建任何实例对象,如果从一个static方法中发出对非static方法的调用,那个非static方法是关联到哪个对象上的呢?这个逻辑无法成立,所以,一个static方法内部不能发出对非static方法的调用。
42、说出一些常用的类、接口,请各举5个
要让人家感觉你对.Net开发很熟,所以,不能仅仅只列谁都能想到的那些东西,要多列你在做项目中涉及的那些东西。就写你最近写的那些程序中涉及的那些类。
常用的类:StreamReader、WebClient、Dictionary<K,V>、StringBuilder、SqlConnection、FileStream、File、Regex、List
常用的接口:IDisposable、IEnumerable、IDbConnection、IComparable、ICollection、IList、IDictionary
要出乎意料!不要仅仅完成任务!笔试不是高考!处处要显出牛!
说出几个开源软件?MySQL、Linux、 Discuz、Apache、Paint.Net、Android、Chrome、Notepad++……
开源项目有一些是开发包。开源软件指的是可以直接用的。Jquery、NPOI、ASP.Net MVC、Silverlight Toolkit、AJAX toolkit、json.net
43、编写一个单例(Singleton)类。
把构造函数设置为private,设置一个public、static的对象实例
public FileManager
{
private FileManager(){}
public readonly static FileManager Instance = new FileManager();
}
扩展:搜“C# Singleton”,有线程安全的更牛B的实现
44、什么是sql注入?如何避免sql注入?
用户根据系统的程序构造非法的参数从而导致程序执行不是程序员期望的恶意SQL语句。使用参数化的SQL就可以避免SQL注入。
详细参考复习ppt。举例子,摆事实!
1' or 1=1
45、数据库三范式是什么?
用自己的话解释,而不是背概念。
第一范式:字段不能有冗余信息,所有字段都是必不可少的。
第二范式:满足第一范式并且表必须有主键。
第三范式:满足第二范式并且表引用其他的表必须通过主键引用。
员工内部→自己的老大→外部的老大
记忆顺序:自己内部不重复→别人引用自己→自己引用别人。
46、post、get的区别
get的参数会显示在浏览器地址栏中,而post的参数不会显示在浏览器地址栏中;
使用post提交的页面在点击【刷新】按钮的时候浏览器一般会提示“是否重新提交”,而get则不会;
用get的页面可以被搜索引擎抓取,而用post的则不可以;
用post可以提交的数据量非常大,而用get可以提交的数据量则非常小(2k),受限于网页地址的长度。
用post可以进行文件的提交,而用get则不可以。
参考阅读:http://www.cnblogs.com/skynet/archive/2010/05/18/1738301.html
47、.Net、ASP.Net、C#、VisualStudio之间的关系是什么?
答:.Net一般指的是.Net Framework,提供了基础的.Net类,这些类可以被任何一种.Net编程语言调用,.Net Framework还提供了CLR、JIT、GC等基础功能。
ASP.Net是.Net中用来进行Web开发的一种技术,ASP.Net的页面部分写在aspx 文件中,逻辑代码通常通过Code-behind的方式用C#、VB.Net等支持.Net的语言编写。
C#是使用最广泛的支持.Net的编程语言。除了C#还有VB.Net、IronPython等。
VisualStudio是微软提供的用来进行.Net开发的集成开发环境(IDE),使用VisualStudio可以简化很多工作,不用程序员直接调用csc.exe等命令行进行程序的编译,而且VisualStudio提供了代码自动完成、代码高亮等功能方便开发。除了VisualStudio,还有SharpDevelop、MonoDevelop等免费、开源的IDE,VisualStudio Express版这个免费版本。
48、AJAX解决什么问题?如何使用AJAX?AJAX有什么问题需要注意?项目中哪里用到了AJAX?
答:AJAX解决的问题就是“无刷新更新页面”,用传统的HTML表单方式进行页面的更新时,每次都要将请求提交到服务器,服务器返回后再重绘界面,这样界面就会经历:提交→变白→重新显示这样一个过程,用户体验非常差,使用AJAX则不会导致页面重新提交、刷新。
AJAX最本质的实现是在Javascript中使用XMLHttpRequest进行Http的请求,开发中通常使用UpdatePanel、JQuery等方式简化AJAX的开发,UpdatePanel的方式实现AJAX最简单,但是数据通讯量比较大,因为要来回传整个ViewState,而且不灵活,对于复杂的需求则可以使用JQuery提供的ajax功能。
UpdatePanel的内部原理。
AJAX最重要的问题是无法跨域请求(www.rupeng.com →so.rupeng.com),也就是无法在页面中向和当前域名不同的页面发送请求,可以使用在当前页面所在的域的服务端做代理页面的方式解决。
在如鹏网项目中发帖的时候显示相关帖的功能、站内搜索项目中显示搜索Suggestion、数据采集项目中都用到了AJAX。
常考:不用任何框架编写一个AJAX程序。XHR:XmlHttpRequest。背也要背下来!
如果面试的时候谈AJAX谈到UpdatePanel的时候,就是NB的时候!!!先侃UpdatePanel的原理!引出为什么Dom操作的动态效果在用UpdatePanel提交刷新以后没有了,以及CKEditor被套在UpdatePanel中提交以后也变成了textarea,为什么把Fileupload放到Updatepanel中无法实现无刷新上传。说成是公司内部的一个菜鸟用UpdatePanel遇到这样问题,由于我懂XHR、UpdatePanel的原理,所以轻松解决!UpdatePanel生成的上万行JS脚本,不适合于互联网项目。“WebForm怎么可能把开发人员编程傻子呢!不明白原理苦命呀!还是MVC好呀,MVC。。。。。。。”
49、Application 、Cookie和 Session 两种会话有什么不同?
答:Application是用来存取整个网站全局的信息,而Session是用来存取与具体某个访问者关联的信息。Cookie是保存在客户端的,机密信息不能保存在Cookie中,只能放小数据;Session是保存在服务器端的,比较安全,可以放大数据。
谈到Session的时候就侃Session和Cookie的关系:Cookie中的SessionId。和别人对比说自己懂这个原理而给工作带来的方便之处。
50、开放式问题:你经常访问的技术类的网站是什么?
博客园(www.cnblogs.com)、csdn、codeplex、codeproject、msdn文档、msdn论坛(遇到问题先到网上搜解决方案,还不行就问同事,同事也解决不了就去MSDN论坛提问,一定能得到解决)。Cnbeta.com。
八、数据库优化经验(后端工程师非常常见)
出现指数:四颗星
主要考点:此题考察后端工程师操作数据库的经验。说实话,数据库是博主的弱项,博主觉得对于这种考题,需要抓住几个常用并且关键的优化经验,如果说得不对,欢迎大家斧正。
参考答案:
1、数据库运维方面的优化:启用数据库缓存。对于一些比较常用的查询可以采用数据库缓存的机制,部署的时候需要注意设置好缓存依赖项,防止“过期”数据的产生。
2、数据库索引方面的优化:比如常用的字段建索引,联合查询考虑联合索引。(PS:如果你有基础,可以敞开谈谈聚集索引和非聚集索引的使用场景和区别)
3、数据库查询方面的优化:避免select * 的写法、尽量不用in和not in 这种耗性能的用法等等。
4、数据库算法方面的优化:尽量避免大事务操作、减少循环算法,对于大数据量的操作,避免使用游标的用法等等。
1、什么是面向对象?
面向对象说到底就是一种思想,任何事物都可以看作是一个对象。在有些面试题目中也称之为OOP(Object Oriented Programming)。分开来解读就是:
Object:对象
Oriented: 面向的
Programming:程序设计
面向对象就是把一个人或事务的属性,比如名字,年龄这些定义在一个实体类里面。存和取的时候直接使用存取实体类就把这个人的名字,年龄这些全部存了,这个实体类就叫对象,这种思想就叫面向对象。
面向对象开发具有以下优点:
代码开发模块化,便于维护。
代码复用性强
代码的可靠性和灵活性。
代码的可读性和可扩展性。
一、对于 Web 性能优化,您有哪些了解和经验吗?
出现指数:五颗星
主要考点:这道题是博主在博客园的新闻里面看到的,回想之前几年的面试经历,发现此题出现概率还是比较高的。因为它的考面灰常广,可以让面试官很快了解你的技术涉及面以及这些技术面的深度。
参考答案:这个问题可以分前端和后端来说。
1、前端优化
(1)减少 HTTP 请求的次数。我们知道每次发送http请求,建立连接和等待相应会花去相当一部分时间,所以在发送http请求的时候,尽量减少请求的次数,一次请求能取出的数据就不要分多次发送。
(2)启用浏览器缓存,当确定请求的数据不会发生变化时,能够直接读浏览器缓存的就不要向服务端发送请求。比如我们ajax里面有一个参数能够设置请求的时候是否启用缓存,这种情况下就需要我们在发送请求的时候做好相应的缓存处理。
(3)css文件放 在
(4)使用压缩的css和js文件。这个不用多说,网络流量小。
(5)如果条件允许,尽量使用CDN的方式引用文件,这样就能减少网络流量。比如我们常用的网站http://www.bootcdn.cn/。
(6)在写js和css的语法时,尽量避免重复的css,尽量减少js里面循环的次数,诸如此类。
2、后端优化:
(1)程序的优化:这是一个很大的话题,我这里就选几个常见的。比如减少代码的层级结构、避免循环嵌套、避免循环CURD数据库、优化算法等等。
(2)数据库的优化:(由于数据库优化不是本题重点,所以可选几个主要的来说)比如启用数据库缓存、常用的字段建索引、尽量避免大事务操作、避免select * 的写法、尽量不用in和not in 这种耗性能的用法等等。
(3)服务器优化:(这个可作为可选项)负载均衡、Web服务器和数据库分离、UI和Service分离等等。
二、MVC路由理解?(屡见不鲜)
出现指数:五颗星
主要考点:此题主要考点是MVC路由的理解。
参考答案:
1、首先我们要理解MVC中路由的作用:url Routing的作用是将浏览器的URL请求映射到特定的MVC控制器动作。
2、当我们访问http://localhost:8080/Home/Index 这个地址的时候,请求首先被UrlRoutingModule截获,截获请求后,从Routes中得到与当前请求URL相符合的RouteData对象, 将RouteData对象和当前URL封装成一个RequestContext对象,然后从Requestcontext封装的RouteData中得到 Controller名字,根据Controller的名字,通过反射创建控制器对象,这个时候控制器才真正被激活,最后去执行控制器里面对应的 action。
三、谈谈你觉得做的不错系统,大概介绍下用到了哪些技术?
出现指数:五颗星
主要考点:这是一道非常开放的面试题。博主遇到过好几家公司的面试官都问道了这个,博主觉得他们是想通过这个问题快速了解面试者的技术水平。此题只要结合你最近项目用到的技术谈谈就好了。
参考答案:
就拿我之前做过的一个项目为例来简单说明一下吧。项目分为客户端和服务端,客户端分 为BS客户端和CS客户端,BS客户端采用MVC 5.0的框架,CS客户端是Winform项目,服务端使用WebApi统一提供服务接口,考虑以后可能还要扩展手机端,所以服务接口的参数和返回值使用 通用的Json格式来传递数据。
1、服务端采用的面向接口编程,我们在软件架构的过程中,层和层之间通过接口依赖, 下层不是直接给上层提供实现,而是提供接口,具体的实现以依赖注入的方式在运行的时候动态注入进去。MEF就是实现依赖注入的一种组件。它的使用使得UI 层不直接依赖于BLL层,而是依赖于中间的一个IBLL层,在程序运行的时候,通过MEF动态将BLL里面的实现注入到UI层里面去,这样做的好处是减少 了层与层之间的耦合。服务端的异常里面、权限验证、日志记录等通用功能使用了AOP拦截的机制统一管理,项目中使用的是Postsharp这个组件,很好 地将通用需求功能从不相关的类当中分离出来,提高了代码的可维护性。
2、BS的客户端采用的jquery+bootstrap 的方式,所有页面采用流式布局,能更好适应各种不同的终端设备(PC、手机)。项目中使用了各种功能强大的bootstrap组件,能适应各种复杂的业务需求。
四、Js继承实现。
出现指数:五颗星
主要考点:这道题考验面试者对js理解的深度。根据博主的经历,这种题一般在笔试出现的几率较大,为什么把它放在这里,因为它确实太常见了。其实js实现继承的方式很多,我们只要写好其中一种就好了。
参考答案:原型链继承
1 //1.定义Persiong函数 2 function Person(name, age) { 3 this.name = name; 4 this.age = age; 5 } 6 //2.通过原型链给Person添加一个方法 7 Person.prototype.getInfo = function () { 8 console.log(this.name + " is " + this.age + " years old!"); 9 }10 function Teacher(staffId) {11 this.staffId = staffId;12 }13 //3.通过prototype生命 Teacher继承Person14 Teacher.prototype = new Person();15 //4.实例Teacher函数16 var will = new Teacher(1000);17 will.name= "Will";18 will.age = 28;19 //5.调用父类函数20 will.getInfo();
五、谈谈你对设计模式的认识?结合你用得最多的一种设计模式说说它的使用。
出现指数:五颗星
主要考点:不用多说,这题考的就是对设计模式的理解。一般为了简单可能会要求你写一个单例模式,注意最好是写一个完整点的,考虑线程安全的那种。然后会让你说说你在项目中什么情况下会用到这种模式
参考答案:
通用写法
1 public class Singleton 2 { 3 // 定义一个静态变量来保存类的实例 4 private static Singleton uniqueInstance; 5 // 定义一个标识确保线程同步 6 private static readonly object locker = new object(); 7 // 定义私有构造函数,使外界不能创建该类实例 8 private Singleton() 9 {10 }11 ///
单例模式确保一个类只有一个实例,并提供一个全局访问点,它的使用场景比如任务管理 器整个系统中应该只有一个把,再比如操作文件的对象,同一时间我们只能有一个对象作文件吧。最重要的,比如我们项目中用得非常多的功能→日志记录,在 一个线程中,记录日志的对象应该也只能有一个吧。单例模式的目的是为了保证程序的安全性和数据的唯一性。或者你也可以结合你使用的其他设计模式来说明。
六、IIS的工作原理?
出现指数:四颗星
主要考点:此题主要考的是.net framework和IIS是如何结合呈现页面的。这是一个有点复杂的过程,面试的时候不可能说得完整,那么我们就抓住几个关键点说说就可以。其实博主也不能完全理解这个过程,今天正好借这个机会温下。
参考答案:
1、当客户端发送HTTP Request时,服务端的HTTP.sys(可以理解为IIS的一个监听组件) 拦截到这个请求;
2、HTTP.sys 联系 WAS 向配置存储中心请求配置信息。
3、然后将请求传入IIS的应用程序池。
4、检查请求的后缀,启动aspnet_isapi.dll这个dll,这个dll是.net framework里面的,也就是说到这一步,请求进入了.net framework的管辖范围。
5、这个时候如果是WebForm,开始执行复杂的页面生命周期(HttpRuntime→ProcessRequest→HttpContext→HttpHandler);如果是MVC,则启动mvc的路由机制,根据路由规则为URL来指定HttpHandler。
6、httpHandler处理请求后,请求结束,给出Response,客户端处理响应,整个过程结束。
七、Http协议
出现指数:四颗星
主要考点:此题主要考对于web里面http协议的理解。
参考答案:
1、http协议是浏览器和服务器双方共同遵循的规范,是一种基于TCP/IP应用层协议。
2、http是一种典型的请求/响应协议。客户端发送请求,请求的内容以及参数存放到请求报文里面,服务端收到请求后,做出响应,返回响应的结果放到响应报文里面。通过F12可以查看请求报文和响应报文。
3、http协议是”无状态”的,当客户端向服务端发送一次http请求后,服务端收到请求然后返回给客户端相应的结果,服务器会立即断开连接并释放资源。在实际开发过程中,我们有时需要“保持”这种状态,所以衍生出了Session/Cookie这些技术。
4、http请求的方式主要有get/post。
5、http状态码最好记几个,博主有一次面试就被问到了。200(请求成功)、404(请求的资源不存在)、403(禁止访问)、5xx(服务端错误)
九、关于代码优化你怎么理解?你会考虑去代码重构吗?
出现指数:四颗星
主要考点:此题考的是面试者对代码优化的理解,以及代码如何重构的相关知识。
参考答案:
1、对于代码优化,之前的公司每周会做代码审核,审核的主要作用就是保证代码的正确性和执行效率,比如减少代码的层级结构、避免循环嵌套、避免循环CURD数据库、尽量避免一次取出大量数据放在内存中(容易内存溢出)、优化算法等。
2、对于陈旧代码,可能很多地方有调用,并且开发和维护人员很有可能不是同一个人,所以重构时要格外小心,如果没有十足的把握,不要轻易重构。如果必须要重构,必须做好充分的单元测试和全局测试。
十、谈谈你的优点和缺点?
出现指数:四颗星
主要考点:这道题让人有一种骂人的冲动,但是没办法,偏偏很多所谓的大公司会问这个。比如华为。这个问题见仁见智,答案可以自己组织。
参考答案:
优点:对于新的技术学**能力强,能很快适应新环境等等
缺点:对技术太过于执着等等
十一、关于服务器端 MVC 架构的技术实现,您是怎样理解的?这种架构方式有什么好处?您在项目中是如何应用这一架构的?
出现指数:三颗星
主要考点:此题主要考的对于MVC这种框架的理解。
参考答案:MVC,顾名思义,Model、View、Controller。所有的 界面代码放在View里面,所有涉及和界面交互以及URL路由相关的逻辑都在Controller里面,Model提供数据模型。MVC的架构方式会让系 统的可维护性更高,使得每一部分更加专注自己的职责,并且MVC提供了强大的路由机制,方便了页面切换和界面交互。然后可以结合和WebForm的比较, 谈谈MVC如何解决复杂的控件树生成、如何避免了复杂的页面生命周期。
十二、网站优化:网站运行慢,如何定位问题?发现问题如何解决?
出现指数:三颗星
主要考点:此题和问题一类似,考察Web的问题定位能力和优化方案。
参考答案:
浏览器F12→网络→查看http请求数以及每个请求的耗时,找到问题的根源,然后依次解决,解决方案可以参考问题一里面的Web优化方案。
十三、说说你最擅长的技术?并说说你是如何使用的?
出现指数:三颗星
主要考点:这是一道非常开放的面试题。最初遇到这种问题,博主很想来一句:你妹,这叫什么问题!但确实有面试官问到。回头想想,其实此题考查你擅长的技术的涉及深度。其实博主觉得对于这个问题,可以结合你项目中用到的某一个技术来说就好了。
参考答案:
简单谈谈MEF在我们项目里面的使用吧。
在谈MEF之前,我们必须要先谈谈DIP、IOC、DI
依赖倒置原则(DIP):一种软件架构设计的原则(抽象概念)
控制反转(IoC):一种反转流、依赖和接口的方式(DIP的具体实现方式)。
依赖注入(DI):IoC的一种实现方式,用来反转依赖(IoC的具体实现方式)。
什么意思呢?也就是说,我们在软件架构的过程中,层和层之间通过接口依赖,下层不是 直接给上层提供实现,而是提供接口,具体的实现以依赖注入的方式在运行的时候动态注入进去。MEF就是实现依赖注入的一种组件。它的使用使得UI层不直接 依赖于BLL层,而是依赖于中间的一个IBLL层,在程序运行的时候,通过MEF动态将BLL里面的实现注入到UI层里面去,这样做的好处是减少了层与层 之间的耦合。这也正是面向接口编程方式的体现。
十四、自己写过JS组件吗?举例说明。
出现指数:三颗星
主要考点:此题考的js组件封装和js闭包的一些用法。一般来说,还是笔试出现的几率较大。
参考答案:自定义html的select组件
1 //combobox 2 (function ($) { 3 $.fn.combobox = function (options, param) { 4 if (typeof options == 'string') { 5 return $.fn.combobox.methods[options](this, param); 6 } 7 options = .fn.combobox.defaults, options || {}); 8 var target = $(this); 9 target.attr('valuefield', options.valueField);10 target.attr('textfield', options.textField);11 target.empty();12 var option = $('');13 option.attr('value', '');14 option.text(options.placeholder);15 target.append(option);16 if (options.data) {17 init(target, options.data);18 }19 else {20 //var param = {};21 options.onBeforeLoad.call(target, option.param);22 if (!options.url) return;23 $.getJSON(options.url, option.param, function (data) {24 init(target, data);25 });26 }27 28 function init(target, data) {29 $.each(data, function (i, item) {30 var option = $('');31 option.attr('value', item[options.valueField]);32 option.text(item[options.textField]);33 target.append(option);34 });35 options.onLoadSuccess.call(target);36 }37 target.unbind("change"); target.on("change", function (e) { if (options.onChange) return options.onChange(target.val()); }); } $.fn.combobox.methods = { getValue: function (jq) { return jq.val(); }, setValue: function (jq, param) { jq.val(param); }, load: function (jq, url) { (''); option.attr('value', ''); option.text('请选择'); jq.append(option); (''); option.attr('value', item[jq.attr('valuefield')]); option.text(item[jq.attr('textfield')]); jq.append(option); }); }); } }; $.fn.combobox.defaults = { url: null, param: null, data: null, valueField: 'value', textField: 'text', placeholder: '请选择', onBeforeLoad: function (param) { }, onLoadSuccess: function () { }, onChange: function (value) { }38 };39 })(jQuery);
调用的时候
1 $("#sel_search_orderstatus").combobox({2 url: '/apiaction/Order/OrderApi/GetOrderStatu',3 valueField: 'VALUE',4 textField: 'NAME'5 });
就能自动从后台取数据,注意valueField和textField对应要显示和实际值。
十五、自己写过多线程组件吗?简要说明!
出现指数:三颗星
主要考点:此题是两年前博主在携程的一次电话面试中遇到的,其他地方基本上没遇到过,其实到现在也不能理解当时面试官问这个问题的目的。但我想,此问题必有出处,估计面试官是想了解你对多线程以及线程池等的理解深度。
知识点:
1、什么是面向对象?
面向对象说到底就是一种思想,任何事物都可以看作是一个对象。在有些面试题目中也称之为OOP(Object Oriented Programming)。分开来解读就是:
Object:对象
Oriented: 面向的
Programming:程序设计
面向对象就是把一个人或事务的属性,比如名字,年龄这些定义在一个实体类里面。存和取的时候直接使用存取实体类就把这个人的名字,年龄这些全部存了,这个实体类就叫对象,这种思想就叫面向对象。
面向对象开发具有以下优点:
代码开发模块化,便于维护。
代码复用性强
代码的可靠性和灵活性。
代码的可读性和可扩展性。
3 .列举ASP.NET 页面之间传递值的几种方式。
答. 1.Request.QueryString
2.Request.Form
3.Session
4.Application
5.Cache
6.Cookie
7.Server.Transfer
8.Database
9.HttpContext的Item属性等
4.a=10,b=15,请在不使用第三方变量的情况下,把a、b的值互换
答: int a=a+b; int b=a-b;int a=a-b;
5.用.net做B/S结构的系统,您是用几层结构来开发,每一层之间的关系以及为什么要这样分层?
答:一般为3层:数据访问层,业务层,表示层。
数据访问层对数据库进行增删查改。
业务层一般分为二层,业务表观层实现与表示层的沟通,业务规则层实现用户密码的安全等。
表示层为了与用户交互例如用户添加表单。
优点: 分工明确,条理清晰,易于调试,而且具有可扩展性。
缺点: 增加成本。
6.能用foreach遍历访问的对象需要实现 ________________接口或声明________________方法的类型。
答:IEnumerable 、 GetEnumerator。
7.GC是什么? 为什么要有GC?
答:GC是垃圾收集器。程序员不用担心内存管理,因为垃圾收集器会自动进行管理。要请求垃圾收集,可以调用下面的方法之一:
System.gc()
Runtime.getRuntime().gc()
8.启动一个线程是用run()还是start()?
答:启动一个线程是调用start()方法,使线程所代表的虚拟处理机处于可运行状态,这意味着它可以由JVM调度并执行。这并不意味着线程就会立即运行。run() 方法可以产生必须退出的标志来停止一个线程。
9.是否可以继承String类?
答:String类是final类故不可以继承。
10.session喜欢丢值且占内存,Cookis不安全,请问用什么办法代替这两种原始的方法
答:redis 或者 memcache。当然,微软也提供了解决方案。iis中由于有进程回收机制,系统繁忙的话Session会丢失,可以用Sate server或SQL Server数据库的方式。
11.IOC容器?
- IOC即控制反转,是一种设计思想,在之前的项目中,当我们需要一个对象时,需要new一个对象,而IOC的设计思想是我们将需要的对象注入到一个容器中,就会获得我们所需要的资源 。
- IOC和DI IOC是控制反转,DI是依赖注入,控制反转的解释有些模棱两可,而依赖注入就很明确,我们将需要的对象注入到容器中,获取所需要的资源。
- IOC控制反转:正常情况下程序开发是上端调用下端,依赖下端,依赖倒置原则告诉我们,上端不要依赖下端,要依赖抽象,上端只依赖抽象,细节交给第三方工厂(容器)来决定,这就是IOC,就是控制反转——使系统架构可以更稳定,支持扩展。
12、什么是委托,事件是不是一种委托?
- 委托可以把一个方法作为参数代入另一个方法。
- 委托可以理解为指向一个函数的引用。
- 事件是一种特殊的委托。
delegate <函数返回类型> <委托名> (<函数参数>)
13.c#多线程是什么?
多线程的优点:可以同时完成多个任务;可以使程序的响应速度更快;可以节省大量时间进行处理任务;可以随时停止任务;可以设置每个任务的优先级,以优化程序性能。
14.WebApi概述
Web API是在.NET Framework之上构建的Web的API的框架,Web API是一个编程接口,用于操作可通过标准HTTP方法和标头访问的系统,Web API需要基于.NET 3.5或更高版本才可以进行开发
15.什么是WebService
webservice是一种跨平台,跨语言的规范,用于不同平台,不同语言开发的应用之间的交互,是基于网络的、分布式的模块化组件,它执行特定的任务,遵守具体的技术规范。
16.存储过程是什么?有什么用?有什么优点?用什么来调用?
存储过程是预编译,安全性高,也是大大提高了效率,存储过程可以重复使用以减少数据库开发人员的工作量,复杂的逻辑我们可以使用存储过程完成,在存储过程中我们可以使用临时表,还可以定义变量,拼接sql语句,调用时,只需执行这个存储过程名,传入我们所需要的参数即可。
17.何为触发器?
触发器是一种特殊的存储过程,主要是通过事件触发而被执行。它可以强化约束来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以级联运算。
常见的触发器有三种:分别应用于Insert , Update , Delete 事件。
18.什么叫做泛型?
只是为了去掉重复代码,应对不同类型的共同需求。
- C#中值类型和引用类型分别有哪些?
值类型:结构体(数值类型,bool型,用户定义的结构体),枚举,可空类型。
引用类型:数组,用户定义的类、接口、委托,object,字符串。
21 .NET的错误处理机制是什么?
.net错误处理机制采用try->catch->finally结构,发生错误时,层层上抛,直到找到匹配的Catch为止。
22.C#可否对内存进行直接的操作?
在.net下,.net引用了垃圾回收(GC)功能,它替代了程序员不过在C#中,不能直接实现Finalize方法,而是在析构函数中调用基类的Finalize()方法。
- ADO.NET相对于ADO等主要有什么改进?
1:ado.net不依赖于ole db提供程序,而是使用.net托管提供的程序,
2:不使用com
3:不在支持动态游标和服务器端游
4:,可以断开connection而保留当前数据集可用
5:强类型转换
6:xml支持
24.如果在一个B/S结构的系统中需要传递变量值,但是又不能使用Session、Cookie、Application,您有几种方法进行处理?
this.Server.Transfer、Response.Redirect()、QueryString
- .NET中读写数据库需要用到那些类?他们的作用?
Connection连接对象,Command执行命令和存储过程,DataReader向前只读的数据流,DataAdapter适配器,支持增删查询,DataSet数据级对象,相当与内存里的一张或多张表。
26.简要谈一下您对微软.NET架构下remoting和webservice两项技术的理解以及实际中的应用。
WS主要是可利用HTTP,穿透防火墙。而Remoting可以利用TCP/IP,二进制传送提高效率。
remoting是.net中用来跨越machine,process, appdomain进行方法调用的技术,对于三成结构的程序,就可以使用remoting技术来构建.它是分布应用的基础技术.相当于以前的DCOM。
Web Service是一种构建应用程序的普通模型,并能在所有支持internet网通讯的操作系统上实施。Web Service令基于组件的开发和web的结合达到最佳,基于组件的对象模型。
27.什么是反射?
动态获取程序集信息。
28.override与重载的区别?
重载是方法的名称相同。参数或参数类型不同,进行多次重载以适应不同的需要。
Override是子类对基类中函数的重写。为了适应需要。
29.装箱和拆箱的概念和原理
装箱是将值类型转化为引用类型的过程;
拆箱是将引用类型转化为值类型的过程
30.Session有什么重大BUG,微软提出了什么方法加以解决?
是iis中由于有进程回收机制,系统繁忙的话Session会丢失,可以用Sate server或SQL Server数据库的方式存储Session不过这种方式比较慢,而且无法捕获Session的END事件。
参考文献:https://blog.csdn.net/user2041/article/details/80591365
特性一:正则表达式
相信大家都会非常喜欢这个特性,无须服务器端的检测,使用浏览器的本地功能就可以帮助你判断电子邮件的格式,URL,或者是电话格式,防止用户输入错误的信息,通过使用HTML5的pattern属性,我们可以很方便的整合这个功能,代码如下:
运行如下:
如果在Firefox浏览器中运行,并且输入错误的email地址,会看到如下:
特性二:数据列表元素
在没有HTML5的日子里,我们会选择使用一些JS或者知名的jQuery UI来实现自动补齐的功能,而在HTML5中,我们可以直接使用datalist元素,如下:
摘要:计算机网络基础
引言
网络协议是每个前端工程师都必须要掌握的知识,TCP/IP 中有两个具有代表性的传输层协议,分别是 TCP 和 UDP,本文将介绍下这两者以及它们之间的区别。
一、TCP/IP网络模型
计算机与网络设备要相互通信,双方就必须基于相同的方法。比如,如何探测到通信目标、由哪一边先发起通信、使用哪种语言进行通信、怎样结束通信等规则都需要事先确定。不同的硬件、操作系统之间的通信,所有的这一切都需要一种规则。而我们就把这种规则称为协议(protocol)。
TCP/IP 是互联网相关的各类协议族的总称,比如:TCP,UDP,IP,FTP,HTTP,ICMP,SMTP 等都属于 TCP/IP 族内的协议。
TCP/IP模型是互联网的基础,它是一系列网络协议的总称。这些协议可以划分为四层,分别为链路层、网络层、传输层和应用层。
链路层:负责封装和解封装IP报文,发送和接受ARP/RARP报文等。
网络层:负责路由以及把分组报文发送给目标网络或主机。
传输层:负责对报文进行分组和重组,并以TCP或UDP协议格式封装报文。
应用层:负责向用户提供应用程序,比如HTTP、FTP、Telnet、DNS、SMTP等。
在网络体系结构中网络通信的建立必须是在通信双方的对等层进行,不能交错。 在整个数据传输过程中,数据在发送端时经过各层时都要附加上相应层的协议头和协议尾(仅数据链路层需要封装协议尾)部分,也就是要对数据进行协议封装,以标识对应层所用的通信协议。接下去介绍TCP/IP 中有两个具有代表性的传输层协议----TCP和UDP。
二、UDP
UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层。UDP有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就是说,当报文发送之后,是无法得知其是否安全完整到达的。
它有以下几个特点:
- 面向无连接
首先 UDP 是不需要和 TCP一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了。并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。
具体来说就是:
在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作 - 有单播,多播,广播的功能
UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。 - UDP是面向报文的
发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文 - 不可靠性
首先不可靠性体现在无连接上,通信都不需要建立连接,想发就发,这样的情况肯定不可靠。
并且收到什么数据就传递什么数据,并且也不会备份数据,发送数据也不会关心对方是否已经正确接收到数据了。
再者网络环境时好时坏,但是 UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。
从上面的动态图可以得知,UDP只会把想发的数据报文一股脑的丢给对方,并不在意数据有无安全完整到达。
5. 头部开销小,传输数据报文时是很高效的。
UDP 头部包含了以下几个数据:
两个十六位的端口号,分别为源端口(可选字段)和目标端口
整个数据报文的长度
整个数据报文的检验和(IPv4 可选 字段),该字段用于发现头部信息和数据中的错误
因此 UDP 的头部开销小,只有八字节,相比 TCP 的至少二十字节要少得多,在传输数据报文时是很高效的
三、TCP
当一台计算机想要与另一台计算机通讯时,两台计算机之间的通信需要畅通且可靠,这样才能保证正确收发数据。例如,当你想查看网页或查看电子邮件时,希望完整且按顺序查看网页,而不丢失任何内容。当你下载文件时,希望获得的是完整的文件,而不仅仅是文件的一部分,因为如果数据丢失或乱序,都不是你希望得到的结果,于是就用到了TCP。
TCP协议全称是传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议,由 IETF 的RFC 793定义。TCP 是面向连接的、可靠的流协议。流就是指不间断的数据结构,你可以把它想象成排水管中的水流。
- TCP连接过程
如下图所示,可以看到建立一个TCP连接的过程为(三次握手的过程):
第一次握手
客户端向服务端发送连接请求报文段。该报文段中包含自身的数据通讯初始序号。请求发送后,客户端便进入 SYN-SENT 状态。
第二次握手
服务端收到连接请求报文段后,如果同意连接,则会发送一个应答,该应答中也会包含自身的数据通讯初始序号,发送完成后便进入 SYN-RECEIVED 状态。
第三次握手
当客户端收到连接同意的应答后,还要向服务端发送一个确认报文。客户端发完这个报文段后便进入 ESTABLISHED 状态,服务端收到这个应答后也进入 ESTABLISHED 状态,此时连接建立成功。
这里可能大家会有个疑惑:为什么 TCP 建立连接需要三次握手,而不是两次?这是因为这是为了防止出现失效的连接请求报文段被服务端接收的情况,从而产生错误。
- TCP断开链接
TCP 是全双工的,在断开连接时两端都需要发送 FIN 和 ACK。
第一次握手
若客户端 A 认为数据发送完成,则它需要向服务端 B 发送连接释放请求。
第二次握手
B 收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,此时表明 A 到 B 的连接已经释放,不再接收 A 发的数据了。但是因为 TCP 连接是双向的,所以 B 仍旧可以发送数据给 A。
第三次握手
B 如果此时还有没发完的数据会继续发送,完毕后会向 A 发送连接释放请求,然后 B 便进入 LAST-ACK 状态。
第四次握手
A 收到释放请求后,向 B 发送确认应答,此时 A 进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有 B 的重发请求的话,就进入 CLOSED 状态。当 B 收到确认应答后,也便进入 CLOSED 状态。
3. TCP协议的特点
面向连接
面向连接,是指发送数据之前必须在两端建立连接。建立连接的方法是“三次握手”,这样能建立可靠的连接。建立连接,是为数据的可靠传输打下了基础。
仅支持单播传输
每条TCP传输连接只能有两个端点,只能进行点对点的数据传输,不支持多播和广播传输方式。
面向字节流
TCP不像UDP一样那样一个个报文独立地传输,而是在不保留报文边界的情况下以字节流方式进行传输。
可靠传输
对于可靠传输,判断丢包,误码靠的是TCP的段编号以及确认号。TCP为了保证报文传输的可靠,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失了)将会被重传。
提供拥塞控制
当网络出现拥塞的时候,TCP能够减小向网络注入数据的速率和数量,缓解拥塞
TCP提供全双工通信
TCP允许通信双方的应用程序在任何时候都能发送数据,因为TCP连接的两端都设有缓存,用来临时存放双向通信的数据。当然,TCP可以立即发送一个数据段,也可以缓存一段时间以便一次发送更多的数据段(最大的数据段大小取决于MSS)
四、TCP和UDP的比较
- 对比
UDP TCP
是否连接 无连接 面向连接
是否可靠 不可靠传输,不使用流量控制和拥塞控制 可靠传输,使用流量控制和拥塞控制
连接对象个数 支持一对一,一对多,多对一和多对多交互通信 只能是一对一通信
传输方式 面向报文 面向字节流
首部开销 首部开销小,仅8字节 首部最小20字节,最大60字节
适用场景 适用于实时应用(IP电话、视频会议、直播等) 适用于要求可靠传输的应用,例如文件传输 - 总结
TCP向上层提供面向连接的可靠服务 ,UDP向上层提供无连接不可靠服务。
虽然 UDP 并没有 TCP 传输来的准确,但是也能在很多实时性要求高的地方有所作为
对数据准确性要求高,速度可以相对较慢的,可以选用TCP
参考文章与书籍
基础篇
怎样创建一个线程
受托管的线程与 Windows线程
前台线程与后台线程
名为BeginXXX和EndXXX的方法是做什么用的
异步和多线程有什么关联
WinForm多线程编程篇
我的多线程WinForm程序老是抛出InvalidOperationException ,怎么解决?
Invoke,BeginInvoke干什么用的,内部是怎么实现的
每个线程都有消息队列吗?
为什么Winform不允许跨线程修改UI线程控件的值
有没有什么办法可以简化WinForm多线程的开发
线程池
线程池的作用是什么?
所有进程使用一个共享的线程池,还是每个进程使用独立的线程池?
为什么不要手动线程池设置最大值?
.Net线程池有什么不足?
同步
CLR怎样实现lock(obj)锁定?
WaitHandle是什么,他和他的派生类怎么使用
什么是用双锁实现Singleton,为什么要这样做,为什么有人说双锁检验是不安全的
互斥对象(Mutex)、事件(Event)对象与lock语句的比较
什么时候需要锁定
只有共享资源才需要锁定
把锁定交给数据库
了解你的程序是怎么运行的
业务逻辑对事务和线程安全的要求
计算一下冲突的可能性
请多使用lock,少用Mutex
Web和IIS
应用程序池,WebApplication,和线程池之间有什么关系
Web页面怎么调用异步WebService
基础篇
怎样创建一个线程
我只简单列举几种常用的方法,详细可参考.Net多线程总结(一)
一)使用Thread类
ThreadStart threadStart=new ThreadStart(Calculate);//通过ThreadStart委托告诉子线程讲执行什么方法,这里执行一个计算圆周长的方法
Thread thread=new Thread(threadStart);
thread.Start(); //启动新线程
public void Calculate(){
double Diameter=0.5;
Console.Write("The perimeter Of Circle with a Diameter of {0} is {1}"Diameter,Diameter*Math.PI);
}
二)使用Delegate.BeginInvoke
delegate double CalculateMethod(double Diameter); //申明一个委托,表明需要在子线程上执行的方法的函数签名
static CalculateMethod calcMethod = new CalculateMethod(Calculate);//把委托和具体的方法关联起来
static void Main(string[] args)
{
//此处开始异步执行,并且可以给出一个回调函数(如果不需要执行什么后续操作也可以不使用回调)
calcMethod.BeginInvoke(5, new AsyncCallback(TaskFinished), null);
Console.ReadLine();
}
//线程调用的函数,给出直径作为参数,计算周长
public static double Calculate(double Diameter)
{
return Diameter * Math.PI;
}
//线程完成之后回调的函数
public static void TaskFinished(IAsyncResult result)
{
double re = 0;
re = calcMethod.EndInvoke(result);
Console.WriteLine(re);
}
三)使用ThreadPool.QueueworkItem
WaitCallback w = new WaitCallback(Calculate);
//下面启动四个线程,计算四个直径下的圆周长
ThreadPool.QueueUserWorkItem(w, 1.0);
ThreadPool.QueueUserWorkItem(w, 2.0);
ThreadPool.QueueUserWorkItem(w, 3.0);
ThreadPool.QueueUserWorkItem(w, 4.0);
public static void Calculate(double Diameter)
{
return Diameter * Math.PI;
}
下面两条来自于http://www.cnblogs.com/tonyman/archive/2007/09/13/891912.html
受托管的线程与 Windows线程
必须要了解,执行.NET应用的线程实际上仍然是Windows线程。但是,当某个线程被CLR所知时,我们将它称为受托管的线程。具体来说,由受托管的代码创建出来的线程就是受托管的线程。如果一个线程由非托管的代码所创建,那么它就是非托管的线程。不过,一旦该线程执行了受托管的代码它就变成了受托管的线程。
一个受托管的线程和非托管的线程的区别在于,CLR将创建一个System.Threading.Thread类的实例来代表并操作前者。在内部实现中,CLR将一个包含了所有受托管线程的列表保存在一个叫做ThreadStore地方。
CLR确保每一个受托管的线程在任意时刻都在一个AppDomain中执行,但是这并不代表一个线程将永远处在一个AppDomain中,它可以随着时间的推移转到其他的AppDomain中。
从安全的角度来看,一个受托管的线程的主用户与底层的非托管线程中的Windows主用户是无关的。
前台线程与后台线程
启动了多个线程的程序在关闭的时候却出现了问题,如果程序退出的时候不关闭线程,那么线程就会一直的存在,但是大多启动的线程都是局部变量,不能一一的关闭,如果调用Thread.CurrentThread.Abort()方法关闭主线程的话,就会出现ThreadAbortException 异常,因此这样不行。
后来找到了这个办法: Thread.IsBackground 设置线程为后台线程。
msdn对前台线程和后台线程的解释:托管线程或者是后台线程,或者是前台线程。后台线程不会使托管执行环境处于活动状态,除此之外,后台线程与前台线程是一样的。一旦所有前台线程在托管进程(其中 .exe 文件是托管程序集)中被停止,系统将停止所有后台线程并关闭。通过设置 Thread.IsBackground 属性,可以将一个线程指定为后台线程或前台线程。例如,通过将 Thread.IsBackground 设置为 true,就可以将线程指定为后台线程。同样,通过将 IsBackground 设置为 false,就可以将线程指定为前台线程。从非托管代码进入托管执行环境的所有线程都被标记为后台线程。通过创建并启动新的 Thread 对象而生成的所有线程都是前台线程。如果要创建希望用来侦听某些活动(如套接字连接)的前台线程,则应将 Thread.IsBackground 设置为 true,以便进程可以终止。
所以解决办法就是在主线程初始化的时候,设置:Thread.CurrentThread.IsBackground = true;
这样,主线程就是后台线程,在关闭主程序的时候就会关闭主线程,从而关闭所有线程。但是这样的话,就会强制关闭所有正在执行的线程,所以在关闭的时候要对线程工作的结果保存。
经常看到名为BeginXXX和EndXXX的方法,他们是做什么用的
这是.net的一个异步方法名称规范
.Net在设计的时候为异步编程设计了一个异步编程模型(APM),这个模型不仅是使用.NET的开发人员使用,.Net内部也频繁用到,比如所有的Stream就有BeginRead,EndRead,Socket,WebRequet,SqlCommand都运用到了这个模式,一般来讲,调用BegionXXX的时候,一般会启动一个异步过程去执行一个操作,EndEnvoke可以接收这个异步操作的返回,当然如果异步操作在EndEnvoke调用的时候还没有执行完成,EndInvoke会一直等待异步操作完成或者超时
.Net的异步编程模型(APM)一般包含BeginXXX,EndXXX,IAsyncResult这三个元素,BeginXXX方法都要返回一个IAsyncResult,而EndXXX都需要接收一个IAsyncResult作为参数,他们的函数签名模式如下
IAsyncResult BeginXXX(...);
<返回类型> EndXXX(IAsyncResult ar);
BeginXXX和EndXXX中的XXX,一般都对应一个同步的方法,比如FileStream的Read方法是一个同步方法,相应的BeginRead(),EndRead()就是他的异步版本,HttpRequest有GetResponse来同步接收一个响应,也提供了BeginGetResponse和EndGetResponse这个异步版本,而IAsynResult是二者联系的纽带,只有把BeginXXX所返回的IAsyncResult传给对应的EndXXX,EndXXX才知道需要去接收哪个BeginXXX发起的异步操作的返回值。
这个模式在实际使用时稍显繁琐,虽然原则上我们可以随时调用EndInvoke来获得返回值,并且可以同步多个线程,但是大多数情况下当我们不需要同步很多线程的时候使用回调是更好的选择,在这种情况下三个元素中的IAsynResult就显得多余,我们一不需要用其中的线程完结标志来判断线程是否成功完成(回调的时候线程应该已经完成了),二不需要他来传递数据,因为数据可以写在任何变量里,并且回调时应该已经填充,所以可以看到微软在新的.Net Framework中已经加强了对回调事件的支持,这总模型下,典型的回调程序应该这样写
a.DoWork+=new SomeEventHandler(Caculate);
a.CallBack+=new SomeEventHandler(callback);
a.Run();
(注:我上面讲的是普遍的用法,然而BeginXXX,EndXXX仅仅是一种模式,而对这个模式的实现完全取决于使用他的开发人员,具体实现的时候你可以使用另外一个线程来实现异步,也可能使用硬件的支持来实现异步,甚至可能根本和异步没有关系(尽管几乎没有人会这样做)-----比如直接在Beginxxx里直接输出一个"Helloworld",如果是这种极端的情况,那么上面说的一切都是废话,所以上面的探讨并不涉及内部实现,只是告诉大家微软的模式,和框架中对这个模式的经典实现)
异步和多线程有什么关联
有一句话总结的很好:多线程是实现异步的一种手段和工具
我们通常把多线程和异步等同起来,实际是一种误解,在实际实现的时候,异步有许多种实现方法,我们可以用进程来做异步,或者使用纤程,或者硬件的一些特性,比如在实现异步IO的时候,可以有下面两个方案:
1)可以通过初始化一个子线程,然后在子线程里进行IO,而让主线程顺利往下执行,当子线程执行完毕就回调
2)也可以根本不使用新线程,而使用硬件的支持(现在许多硬件都有自己的处理器),来实现完全的异步,这是我们只需要将IO请求告知硬件驱动程序,然后迅速返回,然后等着硬件IO就绪通知我们就可以了
实际上DotNet Framework里面就有这样的例子,当我们使用文件流的时候,如果制定文件流属性为同步,则使用BeginRead进行读取时,就是用一个子线程来调用同步的Read方法,而如果指定其为异步,则同样操作时就使用了需要硬件和操作系统支持的所谓IOCP的机制
WinForm多线程编程篇
我的多线程WinForm程序老是抛出InvalidOperationException ,怎么解决?
在WinForm中使用多线程时,常常遇到一个问题,当在子线程(非UI线程)中修改一个控件的值:比如修改进度条进度,时会抛出如下错误
Cross-thread operation not valid: Control 'XXX' accessed from a thread other than the thread it was created on.
在VS2005或者更高版本中,只要不是在控件的创建线程(一般就是指UI主线程)上访问控件的属性就会抛出这个错误,解决方法就是利用控件提供的Invoke和BeginInvoke把调用封送回UI线程,也就是让控件属性修改在UI线程上执行,下面列出会报错的代码和他的修改版本
ThreadStart threadStart=new ThreadStart(Calculate);//通过ThreadStart委托告诉子线程讲执行什么方法
Thread thread=new Thread(threadStart);
thread.Start();
public void Calculate(){
double Diameter=0.5;
double result=Diameter*Math.PI;
CalcFinished(result);//计算完成需要在一个文本框里显示
}
public void CalcFinished(double result){
this.TextBox1.Text=result.ToString();//会抛出错误
}
上面加粗的地方在debug的时候会报错,最直接的修改方法是修改Calculate这个方法如下
delegate void changeText(double result);
public void Calculate(){
double Diameter=0.5;
double result=Diameter*Math.PI;
this.BeginInvoke(new changeText(CalcFinished),t.Result);//计算完成需要在一个文本框里显示
}
这样就ok了,但是最漂亮的方法是不去修改Calculate,而去修改CalcFinished这个方法,因为程序里调用这个方法的地方可能很多,由于加了是否需要封送的判断,这样修改还能提高非跨线程调用时的性能
delegate void changeText(double result);
public void CalcFinished(double result){
if(this.InvokeRequired){
this.BeginInvoke(new changeText(CalcFinished),t.Result);
}
else{
this.TextBox1.Text=result.ToString();
}
}
上面的做法用到了Control的一个属性InvokeRequired(这个属性是可以在其他线程里访问的),这个属性表明调用是否来自另非UI线程,如果是,则使用BeginInvoke来调用这个函数,否则就直接调用,省去线程封送的过程
Invoke,BeginInvoke干什么用的,内部是怎么实现的?
这两个方法主要是让给出的方法在控件创建的线程上执行
Invoke使用了Win32API的SendMessage,
UnsafeNativeMethods.PostMessage(new HandleRef(this, this.Handle), threadCallbackMessage, IntPtr.Zero, IntPtr.Zero);
BeginInvoke使用了Win32API的PostMessage
UnsafeNativeMethods.PostMessage(new HandleRef(this, this.Handle), threadCallbackMessage, IntPtr.Zero, IntPtr.Zero);
这两个方法向UI线程的消息队列中放入一个消息,当UI线程处理这个消息时,就会在自己的上下文中执行传入的方法,换句话说凡是使用BeginInvoke和Invoke调用的线程都是在UI主线程中执行的,所以如果这些方法里涉及一些静态变量,不用考虑加锁的问题
每个线程都有消息队列吗?
不是,只有创建了窗体对象的线程才会有消息队列(下面给出<Windows 核心编程>关于这一段的描述)
当一个线程第一次被建立时,系统假定线程不会被用于任何与用户相关的任务。这样可以减少线程对系统资源的要求。但是,一旦这个线程调用一个与图形用户界面有关的函数(例如检查它的消息队列或建立一个窗口),系统就会为该线程分配一些另外的资源,以便它能够执行与用户界面有关的任务。特别是,系统分配一个T H R E A D I N F O结构,并将这个数据结构与线程联系起来。
这个T H R E A D I N F O结构包含一组成员变量,利用这组成员,线程可以认为它是在自己独占的环境中运行。T H R E A D I N F O是一个内部的、未公开的数据结构,用来指定线程的登记消息队列(posted-message queue)、发送消息队列( send-message queue)、应答消息队列( r e p l y -message queue)、虚拟输入队列(virtualized-input queue)、唤醒标志(wake flag)、以及用来描述线程局部输入状态的若干变量。图2 6 - 1描述了T H R E A D I N F O结构和与之相联系的三个线程。
为什么Winform不允许跨线程修改UI线程控件的值
在vs2003下,使用子线程调用ui线程创建的控件的属性是不会有问题的,但是编译的时候会出现警告,但是vs2005及以上版本就会有这样的问题,下面是msdn上的描述
"当您在 Visual Studio 调试器中运行代码时,如果您从一个线程访问某个 UI 元素,而该线程不是创建该 UI 元素时所在的线程,则会引发 InvalidOperationException。调试器引发该异常以警告您存在危险的编程操作。UI 元素不是线程安全的,所以只应在创建它们的线程上进行访问"
从上面可以看出,这个异常实际是debugger耍的花招,也就是说,如果你直接运行程序的exe文件,或者利用运行而不调试(Ctrl+F5)来运行你的程序,是不会抛出这样的异常的.大概ms发现v2003的警告对广大开发者不起作用,所以用了一个比较狠一点的方法.
不过问题依然存在:既然这样设计的原因主要是因为控件的值非线程安全,那么DotNet framework中非线程安全的类千千万万,为什么偏偏跨线程修改Control的属性会有这样严格的限制策略呢?
这个问题我还回答不好,希望博友们能够予以补充
有没有什么办法可以简化WinForm多线程的开发
使用backgroundworker,使用这个组建可以避免回调时的Invoke和BeginInvoke,并且提供了许多丰富的方法和事件
参见.Net多线程总结(二)-BackgroundWorker,我在这里不再赘诉
线程池
线程池的作用是什么
作用是减小线程创建和销毁的开销
创建线程涉及用户模式和内核模式的切换,内存分配,dll通知等一系列过程,线程销毁的步骤也是开销很大的,所以如果应用程序使用了完一个线程,我们能把线程暂时存放起来,以备下次使用,就可以减小这些开销
所有进程使用一个共享的线程池,还是每个进程使用独立的线程池?
每个进程都有一个线程池,一个Process中只能有一个实例,它在各个应用程序域(AppDomain)是共享的,.Net2.0 中默认线程池的大小为工作线程25个,IO线程1000个,有一个比较普遍的误解是线程池中会有1000个线程等着你去取,其实不然, ThreadPool仅仅保留相当少的线程,保留的线程可以用SetMinThread这个方法来设置,当程序的某个地方需要创建一个线程来完成工作时,而线程池中又没有空闲线程时,线程池就会负责创建这个线程,并且在调用完毕后,不会立刻销毁,而是把他放在池子里,预备下次使用,同时如果线程超过一定时间没有被使用,线程池将会回收线程,所以线程池里存在的线程数实际是个动态的过程
为什么不要手动线程池设置最大值?
当我首次看到线程池的时候,脑袋里的第一个念头就是给他设定一个最大值,然而当我们查看ThreadPool的SetMaxThreads文档时往往会看到一条警告:不要手动更改线程池的大小,这是为什么呢?
其实无论FileStream的异步读写,异步发送接受Web请求,甚至使用delegate的beginInvoke都会默认调用 ThreadPool,也就是说不仅你的代码可能使用到线程池,框架内部也可能使用到,更改的后果影响就非常大,特别在iis中,一个应用程序池中的所有 WebApplication会共享一个线程池,对最大值的设定会带来很多意想不到的麻烦
线程池的线程为何要分类?
线程池有一个方法可以让我们看到线程池中可用的线程数量:GetAvaliableThread(out workerThreadCount,out iocompletedThreadCount),对于我来说,第一次看到这个函数的参数时十分困惑,因为我期望这个函数直接返回一个整形,表明还剩多少线程,这个函数居然一次返回了两个变量.
原来线程池里的线程按照公用被分成了两大类:工作线程和IO线程,或者IO完成线程,前者用于执行普通的操作,后者专用于异步IO,比如文件和网络请求,注意,分类并不说明两种线程本身有差别,线程就是线程,是一种执行单元,从本质上来讲都是一样的,线程池这样分类,举例来说,就好像某施工工地现在有1000把铁锹,规定其中25把给后勤部门用,其他都给施工部门,施工部门需要大量使用铁锹来挖地基(例子土了点,不过说明问题还是有效的),后勤部门用铁锹也就是铲铲雪,铲铲垃圾,给工人师傅修修临时住房,所以用量不大,显然两个部门的铁锹本身没有区别,但是这样的划分就为管理两个部门的铁锹提供了方便
线程池中两种线程分别在什么情况下被使用,二者工作原理有什么不同?
下面这个例子直接说明了二者的区别,我们用一个流读出一个很大的文件(大一点操作的时间长,便于观察),然后用另一个输出流把所读出的文件的一部分写到磁盘上
我们用两种方法创建输出流,分别是
创建了一个异步的流(注意构造函数最后那个true)
FileStream outputfs=new FileStream(writepath, FileMode.Create, FileAccess.Write, FileShare.None,256,true);
创建了一个同步的流
FileStream outputfs = File.OpenWrite(writepath);
然后在写文件期间查看线程池的状况
string readpath = "e:RHEL4-U4-i386-AS-disc1.iso";
string writepath = "e:kakakak.iso";
byte[] buffer = new byte[90000000];
//FileStream outputfs=new FileStream(writepath, FileMode.Create, FileAccess.Write, FileShare.None,256,true);
//Console.WriteLine("异步流");
//创建了一个同步的流
FileStream outputfs = File.OpenWrite(writepath);
Console.WriteLine("同步流");
//然后在写文件期间查看线程池的状况
ShowThreadDetail("初始状态");
FileStream fs = File.OpenRead(readpath);
fs.BeginRead(buffer, 0, 90000000, delegate(IAsyncResult o)
{
outputfs.BeginWrite(buffer, 0, buffer.Length,
delegate(IAsyncResult o1)
{
Thread.Sleep(1000);
ShowThreadDetail("BeginWrite的回调线程");
}, null);
Thread.Sleep(500);//this is important cause without this, this Thread and the one used for BeginRead May seem to be same one
},
null);
Console.ReadLine();
public static void ShowThreadDetail(string caller)
{
int IO;
int Worker;
ThreadPool.GetAvailableThreads(out Worker, out IO);
Console.WriteLine("Worker: {0}; IO: {1}", Worker, IO);
}
输出结果
异步流
Worker: 500; IO: 1000
Worker: 500; IO: 999
同步流
Worker: 500; IO: 1000
Worker: 499; IO: 1000
这两个构造函数创建的流都可以使用BeginWrite来异步写数据,但是二者行为不同,当使用同步的流进行异步写时,通过回调的输出我们可以看到,他使用的是工作线程,而非IO线程,而异步流使用了IO线程而非工作线程
其实当没有制定异步属性的时候,.Net实现异步IO是用一个子线程调用fs的同步Write方法来实现的,这时这个子线程会一直阻塞直到调用完成.这个子线程其实就是线程池的一个工作线程,所以我们可以看到,同步流的异步写回调中输出的工作线程数少了一,而使用异步流,在进行异步写时,采用了 IOCP方法,简单说来,就是当BeginWrite执行时,把信息传给硬件驱动程序,然后立即往下执行(注意这里没有额外的线程),而当硬件准备就绪, 就会通知线程池,使用一个IO线程来读取
.Net线程池有什么不足
没有提供方法控制加入线程池的线程:一旦加入线程池,我们没有办法挂起,终止这些线程,唯一可以做的就是等他自己执行
1)不能为线程设置优先级
2)一个Process中只能有一个实例,它在各个AppDomain是共享的。ThreadPool只提供了静态方法,不仅我们自己添加进去的WorkItem使用这个Pool,而且.net framework中那些BeginXXX、EndXXX之类的方法都会使用此Pool。
3)所支持的Callback不能有返回值。WaitCallback只能带一个object类型的参数,没有任何返回值。
4)不适合用在长期执行某任务的场合。我们常常需要做一个Service来提供不间断的服务(除非服务器down掉),但是使用ThreadPool并不合适。
下面是另外一个网友总结的什么不需要使用线程池,我觉得挺好,引用下来
如果您需要使一个任务具有特定的优先级。
如果您具有可能会长时间运行(并因此阻塞其他任务)的任务。
如果您需要将线程放置到单线程单元中(所有 ThreadPool 线程均处于多线程单元中)。
如果您需要与该线程关联的稳定标识。例如,您应使用一个专用线程来中止该线程、将其挂起或按名称发现它。
锁定与同步
CLR怎样实现lock(obj)锁定?
从原理上讲,lock和Syncronized Attribute都是用Moniter.Enter实现的,比如如下代码
object lockobj=new object();
lock(obj){
//do things
}
在编译时,会被编译为类似
try{
Moniter.Enter(obj){
//do things
}
}
catch{}
finally{
Moniter.Exit(obj);
}
而[MethodImpl(MethodImplOptions.Synchronized)]标记为同步的方法会在编译时被lock(this)语句所环绕
所以我们只简单探讨Moniter.Enter的实现
(注:DotNet并非使用Win32API的CriticalSection来实现Moniter.Enter,不过他为托管对象提供了一个类似的结构叫做Syncblk)
每个对象实例头部都有一个指针,这个指针指向的结构,包含了对象的锁定信息,当第一次使用Moniter.Enter(obj)时,这个obj对象的锁定结构就会被初时化,第二次调用Moniter.Enter时,会检验这个object的锁定结构,如果锁没有被释放,则调用会阻塞
WaitHandle是什么,他和他的派生类怎么使用
WaitHandle是Mutex,Semaphore,EventWaitHandler,AutoResetEvent,ManualResetEvent共同的祖先,他们包装了用于同步的内核对象,也就是说是这些内核对象的托管版本。
Mutex:类似于一个接力棒,拿到接力棒的线程才可以开始跑,当然接力棒一次只属于一个线程(Thread Affinity),如果这个线程不释放接力棒(Mutex.ReleaseMutex),那么没办法,其他所有需要接力棒运行的线程都知道能等着看热闹
Semaphore:类似于一个小桶,里面装了几个小球,凡是拿到小球就可以跑,比如指定小桶里最初有四个小球,那么开始的四个线程就可以直接拿着自己的小球开跑,但是第五个线程一看,小球被拿光了,就只好乖乖的等着有谁放一个小球到小桶里(Semophore.Release),他才能跑,但是这里的游戏规则比较特殊,我们可以随意向小桶里放入小球,也就是说我可以拿走一个小球,放回去俩,甚至一个都不拿,放回去5个,这样就有五个线程可以拿着这些小球运行了.我们可以规定小桶里有开始有几个小球(构造函数的第一个参数),也可以规定最多不能超过多少小球(构造函数的第二个参数)
ManualResetEvent,AutoResetEvent可以参考http://www.cnblogs.com/uubox/archive/2007/12/18/1003953.html
什么是用双锁实现Singleton,为什么要这样做,双锁检验是不安全的吗?
使用双锁检验技巧来实现单件,来自于Java社区
public static MySingleton Instance{
get{
if(_instance!=null)}{
lock(_instance){
if(s_valuenull){
_instance= new MySingleton();
}
}
}
}
}
这样做其实是为了提高效率,比起
public static MySingleton Instance{
get{
lock(_instance){
if(s_valuenull){
_instance= new MySingleton();
}
}
前一种方法在instance创建的时候不需要用lock同步,从而增进了效率
在java中这种技巧被证明是不安全的详细见http://www.cs.umd.edu/~pugh/java/memoryModel/
但是在.Net下,这样的技巧是成立的,因为.Net使用了改进的内存模型
并且在.Net下,我们可以使用LazyInit来实现单件
private static readonly _instance=new MySingleton()
public static MySingleton Instance{
get{return _instance}
}
当第一此使用_instance时,CLR会生成这个对象,以后再访问这个字段,将会直接返回
互斥对象(Mutex),信号量(Semaphore),事件(Event)对象与lock语句的比较
首先这里所谓的事件对象不是System.Event,而是一种用于同步的内核机制
互斥对象和事件对象属于内核对象,利用内核对象进行线程同步,线程必须要在用户模式和内核模式间切换,所以一般效率很低,但利用互斥对象和事件对象这样的内核对象,可以在多个进程中的各个线程间进行同步。
lock或者Moniter是.net用一个特殊结构实现的,不涉及模式切换,也就是说工作在用户方式下,同步速度较快,但是不能跨进程同步
什么时候需要锁定?
刚刚接触锁定的程序员往往觉得这个世界非常的危险,每个静态变量似乎都有可能产生竞争
首先锁定是解决竞争条件的,也就是多个线程同时访问某个资源,造成意想不到的结果,比如,最简单的情况,一个计数器,如果两个线程同时加一,后果就是损失了一个计数,但是频繁的锁定又可能带来性能上的消耗,还有最可怕的情况,死锁
到底什么情况下我们需要使用锁,什么情况下不用呢?
只有共享资源才需要锁定
首先,只有可以被多线程访问的共享资源才需要考虑锁定,比如静态变量,再比如某些缓存中的值,属于线程内部的变量不需要锁定
把锁定交给数据库
数据库除了存储数据之外,还有一个重要的用途就是同步,数据库本身用了一套复杂的机制来保证数据的可靠和一致性,这就为我们节省了很多的精力.保证了数据源头上的同步,我们多数的精力就可以集中在缓存等其他一些资源的同步访问上了
了解你的程序是怎么运行的
实际上在web开发中大多数逻辑都是在单个线程中展开的,无论asp.net还是php,一个请求都会在一个单独的线程中处理,其中的大部分变量都是属于这个线程的,根本没有必要考虑锁定,当然对于asp.net中的application对象中的数据,我们就要小心一些了
WinForm中凡是使用BeginInvoke和Invoke调用的方法也都不需要考虑同步,因为这用这两个方法调用的方法会在UI线程中执行,因此实际是同步的,所以如果调用的方法中存在某些静态变量,不需要考虑锁定
业务逻辑对事务和线程安全的要求
这条是最根本的东西,开发完全线程安全的程序是件很费时费力的事情,在电子商务等涉及金融系统的案例中,许多逻辑都必须严格的线程安全,所以我们不得不牺牲一些性能,和很多的开发时间来做这方面的工作,而一般的应用中,许多情况下虽然程序有竞争的危险,我们还是可以不使用锁定,比如有的时候计数器少一多一,对结果无伤大雅的情况下,我们就可以不用去管他
计算一下冲突的可能性
我以前曾经谈到过,架构不要过设计,其实在这里也一样,假如你的全局缓存里的某个值每天只有几百或者几千个访问,并且访问时间很短,并且分布均匀(实际上这是大多数的情况),那么冲突的可能性就非常的少,也许每500天才会出现一次或者更长,从7*24小时安全服务的角度来看,也完全符合要求,那么你还会为这样万分之一的可能性花80%的精力去设计吗?
请多使用lock,少用Mutex
如果你一定要使用锁定,请尽量不要使用内核模块的锁定机制,比如.net的Mutex,Semaphore,AutoResetEvent,ManuResetEvent,使用这样的机制涉及到了系统在用户模式和内核模式间的切换,所以性能差很多,但是他们的优点是可以跨进程同步线程,所以应该清楚的了解到他们的不同和适用范围
Web和IIS
应用程序池,WebApplication,和线程池之间有什么关系
一个应用程序池是一个独立的进程,拥有一个线程池,应用程序池中可以有多个WebApplication,每个运行在一个单独的AppDomain中,这些WebApplication公用一个线程池
不同的AppDomain保证了每个WebApplication的静态变量不会互相干扰,不同的应用程序池保证了一个网站瘫痪,其他不同进程中的站点还能正常运行
下图说明了他们的关系
Web页面怎么调用异步WebService
把Page的Async属性设置为true,就可以调用异步的方法,但是这样调用的效果可能并不如我们的相像,请参考Web中使用多线程来增强用户体验
序列化和反序列化的实现
https://www.cnblogs.com/caofangsheng/p/5687994.html
C#模态对话框和非模态对话框
模态对话框
弹出窗口阻止调用窗口的所有消息响应。
只有在弹出窗口结束后调用窗口才能继续。
在模态窗口“关闭”后,可以读取模态窗口中信息,包括窗口的返回状态,窗口子控件的值。
非模态对话框
可以在弹出窗口和调用窗口之间随意切换。
调用窗口调用show方法后,下面的代码可以立即执行。在非模态窗口关闭后,窗口的所有资源被释放,窗口不存在,无法获取窗口的任何信息。
所谓模态对话框,就是指除非采取有效的关闭手段,用户的鼠标焦点或者输入光标将一直停留在其上的对话框。非模态对话框则不会强制此种特性,用户可以在当前对话框以及其他窗口间进行切换
概念说明
1 模态窗口
打开模态窗口后,只要不关闭该窗口,鼠标焦点或者光标就会一直停留在该窗口上。只有关闭该窗口后,调用窗口才能继续。模态窗口关闭后,仍可以读取模态窗口中的信息,如窗口的返回状态等。
2 非模态窗口
打开非模态窗口后,仍可以操作调用窗口。关闭非模态窗口,该窗口将不复存在,会释放窗口的所有资源,所以无法得到该窗口的任何信息。
实例说明
1 建立Windows窗体程序ShowAndShowDialogExp,程序主画面包含两个按钮,用于打开模态窗口和非模态窗口(如下图所示)。
2 编写按钮的Click事件代码
private void button1_Click(object sender, EventArgs e)
{
Form frm1 = new Form();
frm1.Text = "我是模态窗口!";
frm1.ShowDialog();//打开模态窗口(对话框)}
private void button2_Click(object sender, EventArgs e)
{
Form frm2 = new Form();
frm2.Text = "我是非模态窗口!";
frm2.Show();//打开非模态窗口(对话框)
}
3 运行代码,进行操作体验
点击按钮“打开模态窗口”,打开模态窗口frm1,窗口标题栏显示“我是模态窗口!”,此时无法切换到调用窗口,当关闭该窗口后,又可以继续操作调用窗口了。
点击按钮“打开非模态窗口”,打开非模态窗口frm2,此时,可以仍切换到调用窗口操作调用窗口。
4 实例结论
C#中使用Show()方法打开非模态窗口,使用ShowDialog()方法打开模态窗口。
5 进阶
修改前面按钮的Click事件代码,修改后的代码如下所示。
private void button1_Click(object sender, EventArgs e)
{
Form frm1 = new Form();
frm1.Text = "我是模态窗口!";
frm1.ShowDialog();//打开模态窗口(辍对话框)MessageBox.Show(frm1.DialogResult.ToString());
}
private void button2_Click(object sender, EventArgs e)
{
Form frm2 = new Form();
frm2.Text = "我是非模态窗口!";
frm2.Show();//打开非模态窗口(对话框)MessageBox.Show(frm2.DialogResult.ToString());
}
朋友,发现跟前面代码的区别了吗?
呵呵,仅仅加了一句输出弹出窗口的DialogResult属性值的代码而已。
再次执行代码,程序的运行情况是:
点击“打开模态窗口”打开模态窗口,接着关闭模态窗口,会弹出消息框,输出“Cancel”(frm1.DialogResult.ToString()的结果)。
点击“打开非模态窗口”打开非模态窗口后,便会弹出消息框,输出“None”(frm2.DialogResult.ToString()的结果)。
从程序执行情况我们了解到:
执行Show()方法后,后面的代码会立即执行;而执行ShowDialog()方法后,后面的代码需要等弹出窗口关闭后才能及时执行。
前面说到:模态窗口关闭后,仍可以读取模态窗口中的信息。
这主要是因为:当“关闭”模态窗口后,窗体并没有被真的被“关闭”,因为用户点击“关闭”按钮或者设置DialogResult属性值时,并没有调用窗体的Close方法,只是将窗体的Visible属性赋值为false,隐藏了窗体而已。这样隐藏的窗体是可以被重新显示的,且窗体资源并没有被释放。所以,在你真的不需要这个窗体时,一定要记得Dispose一下哦。
为了说明这一切,修改前面打开模态窗口的按钮Click事件代码。
private void button1_Click(object sender, EventArgs e)
{
Form frm1 = new Form();
frm1.Text = "我是模态窗口!";
frm1.ShowDialog();//打开模态窗口(对话框)MessageBox.Show(frm1.DialogResult.ToString());
frm1.Visible = true;
}
模块之间的接口应该尽量少而简单。
Web api:https://www.cnblogs.com/yuchenghao/p/10598825.html