一,需求分析
1.程序可读入任意英文文本文件,该文件中英文词数大于等于1个。
2.程序需要很壮健,能读取容纳英文原版《哈利波特》10万词以上的文章。
3.指定单词词频统计功能:用户可输入从该文本中想要查找词频的一个或任意多个英文单词,运行程序的统计功能可显示对应单词在文本中出现的次数和柱状图。
4.高频词统计功能:用户从键盘输入高频词输出的个数k,运行程序统计功能,可按文本中词频数降序显示前k个单词的词频及单词。
5.统计该文本所有单词数量及词频数,并能将单词及词频数按字典顺序输出到文件result.txt。
二,功能设计
1.用户输入任意多个英文单词,显示对应单词在文本中出现的次数和柱状图。
2.用户从键盘输入高频词输出的个数k,按文本中词频数降序显示前k个单词的词频及单词。
3.统计该文本所有单词数量及词频数,并能将单词及词频数按字典顺序输出到文件result.txt。
三,设计实现
1.设计两个类,一个TEST类用来读入a.txt文件,同时进行词频统计功能测试。另一个MAIN类用来进行对读入文件的各种操作。
2.在对文件的存储方面采用了TreeMap函数,进行单词的存储,在函数中用到了链表的方式。
3.在MAIN函数类中需要有指定单词统计功能,按单词出现频率,字母顺序排序功能,除此之外还应该有将统计出的单词及频率写入result.txt文件中功能。
四,测试运行
1.读取已经写好的a.txt文件,进行操作。

2.继续功能测试,写入result.txt中,最后退出。

3.最终写入的result.txt文件内容。

五,主要代码
1.功能菜单。

2.用*代表柱状图。

六,实验总结
首先,之前学的Java知识点有好多都很陌生了,在刚开始着手写代码的时候,查阅了之前的课本。在经过基本的熟悉之后,可以写一些基本的东西,但是还有一部分有点难,比如按字母顺序进行排序,写入新的文件中,还有柱状图等,在网上进行参考,查阅,修改最终可以基本实现词频统计的功能。
七,PSP展示
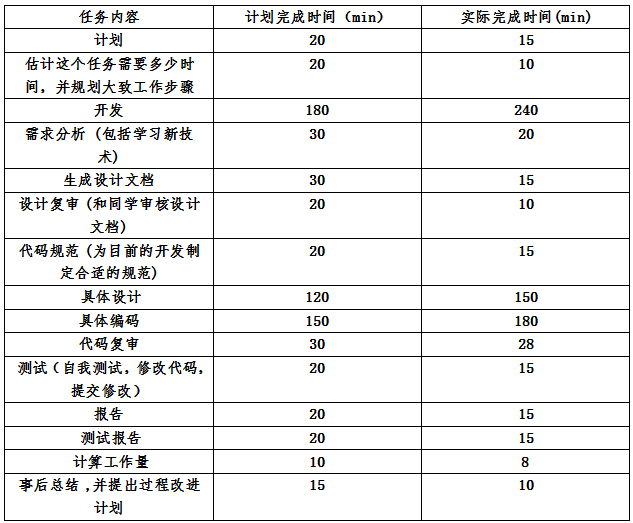
在上面的PSP表格中,在开发,程序编码的过程中所花费的时间较多,超出了预测的时间。希望以后可以在保证质量的情况下,提高效率。
点击查看源代码