统计函数
select * from 教师资料 where 教师薪资>(select AVG(教师薪资) from 教师资料) \从教师资料表中查出所有高于平均薪资的人员。
use LtsDatabase
alter table 网站职员表 \修改此表
add 奖金 money \增加奖金字段
更新奖金字段
use LtsDatabase
update 网站职员表 set 奖金=500 \更新网站职员表所有奖金更新至500元
计算每个员工的总收入是多少
use LtsDatabase
select 职员编号,姓名,工资+奖金 as 总收入 from 网站职员表 \计算出所有职员的基本工资+总工资
like运算符(模糊查询)
use LtsDatabase
select * from 网站职员表 where 毕业院校 like '%河%' \从网站职员表中查询,条件为毕业院校中带河的关键字
(汇总分组查询)
select * from 网站职员表 order by 年龄 compute max(工资),min(工资),sum(工资),avg(工资) by 年龄 \通过年龄进行分组,然后再算出分完组每组工资的的最高值、最低值、总和、平均值。
(排序,自增或自减) (计算,进行汇总) (通过by进行分组)
(默认为自增)
select 毕业院校,MAX(工资) as 最高工资,MIN(工资) as 最低工资,AVG(工资) as 平均工资,SUM(工资) as 工资总额,SUM(工资+奖金) as 收入总额 FROM 网站职员表 group by 毕业院校
\通过毕业院校进行分组
\按毕业院校进行分组,然后根据分完组的院校里进行最高工资,最低工资,平均工资,工资总额的计算和比较。这个语句主要部分还是毕业院校,
所有执行的语句是围绕毕业院校的。
select 毕业院校,MAX(工资) as 最高工资,MIN(工资) as 最低工资,AVG(工资) as 平均工资,SUM(工资) as 工资总额,SUM(工资+奖金) as 收入总额 FROM 网站职员表 group by 毕业院校 having SUM(工资)>5000
\按毕业院校进行分组,然后根据分完组的院校里进行最高工资,最低工资,平均工资,工资总额的计算和比较。并只显示工资大于5000元的分组。
group by 我们可以从字面上理解,group表示分组,by后面写字段名,就表示根据哪个字段进行分组,如果有用Excel比较多的话,group by比较类似Excel里面的透视表。
group by必须配合聚合函数来用,分组之后可以计数(COUNT),求和(SUM),求平均数(AVG)等。
常用的聚合函数 count()计数,sum()求和,avg()平均数,()max最大值,()min最小值。
带分组的嵌套查询
select * from 网站职员表 where 毕业院校 in(select 毕业院校 from 网站职员表 group by 毕业院校 having SUM(工资)>5000)
!!!where后面的主语是毕业院校,所以查询的事毕业院校必须在一个范围之内,这个范围就是in括号里面的条件
\首先进行子句的查询,从网站职员表中查询所有的毕业院校,对毕业院校进行分组,并且计算查询出相同毕业院校中的工资总和大于五千元。
!!!select * from(此处带*星号,是查询此表中的所有字段,不带*星号是查询指定的字段)
!!!嵌套查询中,一般先查询子句,再查询主句,但相关子句查询例外。
谓词和量词的查询
\exists 与 in的区别,in的特性是前面的指定字段必须在后面的集合中出现,
exists\存在 not exists\不存在
\EXISTS表示存在量词:带有EXISTS的子查询不返回任何记录的数据,只返回逻辑值“True”或“False”
\谓词
select * from 网站职员表 where exists (select * from 网站职员表 where 毕业院校='哈工大')
\存在
\查询网站职员表,条件是在网站职员表中查找出存在毕业院校等于哈工大等于哈工大的,若存在,则查询出来整个网站职员表,
exists在此句中的作用就是通过(select * from 网站职员表 where 毕业院校='哈工大')此子句的返回值是否为"True"来决定是否执行前面的语句。
any量词
select * from 网站职员表 where 工资>any(select 工资 from 网站职员表 where 姓名='小伟')
\在网站职员表中查询出所有工资大于小伟的员工
\从网站职员表中查询出大于括号里面任意一个值,也就是说假如网站职员表中哪怕只有一个小伟,
就查询出所有大于小伟工资的值,假如有两个小伟,那就查询出大于任意一个“小伟”工资的值。
select * from 网站职员表 where 工资>all(select 工资 from 网站职员表 where 毕业院校='哈工大')
\从网站职员表中查询出>大于 所有毕业院校为哈工大员工工资的员工。
利用top查询出前n条记录
select top 3 * from 网站职员表 \查询出网站职员表中前3条记录
select top 10 percent * from 网站职员表 \查询出网站职员表中前百分之十10%条记录
将查询的结果保存,如何把查询的数据保存成一个新的(虚拟)表,如果这个表不存在,我们可以创建它。
select * into 第二网站职员表 from 网站职员表 where 工资>2800
从网站职员表中查询出工资大于2800的员工,并把查询到的结果存储到第二网站职员表,。
(存储到) 如果不存在第二网站职员表,创建该表,并将查询到的数据存储到该表中。
select top 10 percent * into 第二网站职员表 from 网站职员表 where 工资>2800
\从网站职员表中查询出前10%的记录,并把这些记录存储到第二网站职员表中,
若不存在第二网站职员表,创建该表,并将查询到的数据存储到该表中。
集合并和集合交进行运算
update 第二网站职员表 set 姓名='第二网站职员表'+姓名
\ 把第二网站职员表里的原有名字更新设置为“第二网站职员表+姓名”的格式
\字符串命名表达式,这里的+加号是字符串连接符
集合并运算
select * from 网站职员表 union select * from 第二网站职员表
\分别查询出两个表中的记录并把他们合并在一起。
(联合,合并) !!!此表为虚拟表,并不会重新创建个新表。
集合交运算
(叠加求交,交运算)
select * from 网站职员表 interset select * from 第二网站职员表
\分别查询出两个表中的记录并让他们分别显示出两个表。
!!!虚拟表
连接查询
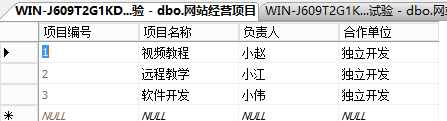
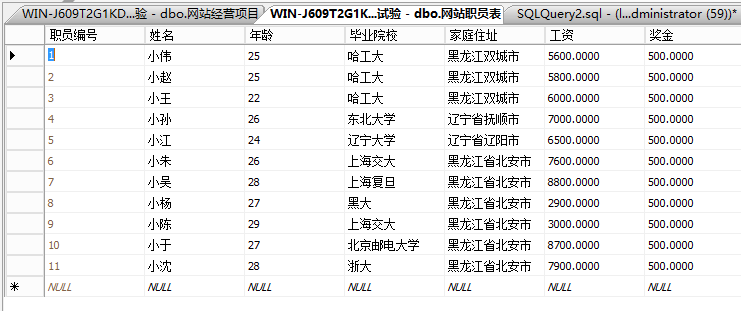
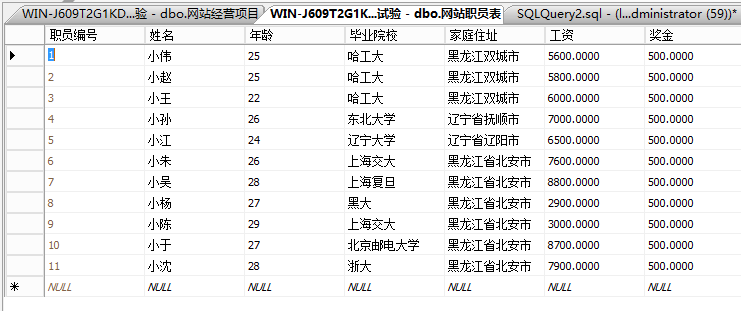
select * from 网站职员表,网站经营项目表
\此命令的运算过程为将网站经营项目表中每3条记录与网站职员表中的11条记录中的每一条记录进行组合,
组合成一条新记录,
并把这新组合出来的33记录组成新的‘虚拟表’。
 !!!虚拟表就是把查询并运算出来的新记录,显示出的表,并不会保存起来,所有查询出来的记录都是虚拟表。
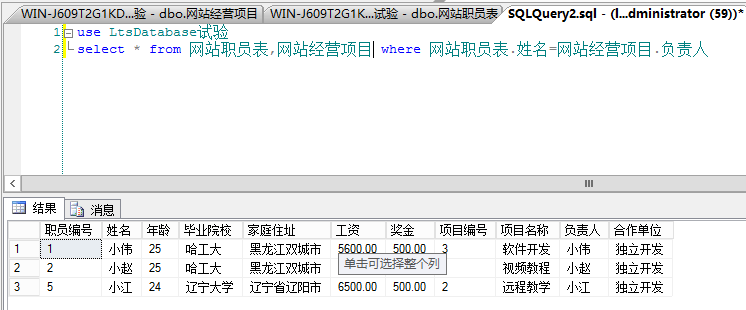
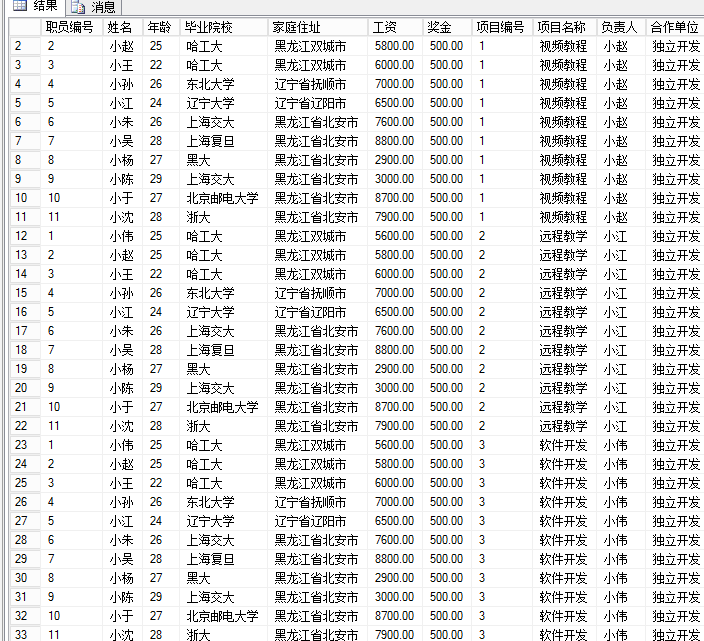
select * from 网站职员表,网站经营项目表 where 网站职员表.姓名=网站经营项目.负责人
!!!虚拟表就是把查询并运算出来的新记录,显示出的表,并不会保存起来,所有查询出来的记录都是虚拟表。
select * from 网站职员表,网站经营项目表 where 网站职员表.姓名=网站经营项目.负责人
\从网站职员表和网站经营项目表中查找出条件是 网站职员表.姓名=网站经营项目.负责人的数据,
并组合成一个新表。
\网站职员表和网站经营项目后面的点.是英文状态下的,键入此点可自动提示该表的相关字段。