面向对象第三单元博客作业
前言
第三单元较前两个单元相比,侧重点更偏向于实现而不是设计。与前两单元通过阅读指导书要求,设计一个相对完整的架构不同,在第三单元中,我们只需要针对给出的接口的规格,去实现相应的功能即可,代码量与任务难度都有明显的降低。
此外,第三单元的几次作业中,从PathContainer、Graph到RailwaySystem,每一个要实现的接口都继承了前一个,这极佳的体现了面向对象课程中一直在强调的可扩展性,对日后的学习非常有启示意义。
JML语言简介
JML语言理论基础
JML简介
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言
(Behavior Interface Specification Language,BISL),基于Larch方法构建,BISL提供了对方法和类型的规格定义手段。一般而言,JML有两种主要的用法,一是开展规格化设计,在实现代码是不是依靠自然语言描述,而是借助规格约束,避免了二义性的出现;二是针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性,在遗留代码的维护方面具有特别重要的意义。
JML表达式
JML表达式是对Java表达式的扩展,在此基础上增加了一些操作符与原子表达式,此外,JML表达式中还有量化表达式与集合表达式,此处仅对一些较为常见的JML表达式与操作符做出介绍。
esult: 表示非void类型方法执行后获得的结果;old(expr): 表示表达式在相应方法执行前的取值;forall: 全称量词修饰的表达式;exists: 存在量词修饰的表达式;sum: 返回指定范围内表达式的和;max或min: 返回指定范围内最大/最小值;==>: 推理操作符;<==>: 等价操作符。
JML方法规格
整体上分为正常行为规格 (normal_behavior) 以及 异常行为规格 (exceptional_behavior)两种,包括以下三种条件:
- 前置条件 (pre-condition) : 用
requires子句表示,表明需要满足何种前置条件; - 后置条件 (post-condition) : 用
ensures子句表示,表明方法结束后一定满足何种条件; - 副作用范围限定 (side-effects) : 副作用指方法在执行过程中会修改对象的属性数据或静态成员数据,可用
assignable和modifiable关键词表示。
JML工具链
主要工具链可以通过JML官方的工具链下载地址来获取,此处仅介绍数个较为主流的工具链:
- OpenJML : 最为主流的JML工具链,可以将 JML 规格转换成 SMT-LIB 格式的代码,调用 SMT Solver对代码静态检查;
- JMLdoc : 类似 Javadoc,可以快速生成 JML 文档的相关文件;
- JMLUnitNG : 可以根据规格自动生成测试文件;
SMT Solver验证
尽管idea拥有一个OpenJML的插件可供使用,然而它朴实的界面与不甚友好的显示方式都促使笔者将项目转换为maven,进而转战eclipse。但即便是这样,由于OpenJML对于很多JML语句目前尚不支持,以及一些题目中默认的约定所导致的JML覆盖范围不全面,导致了最终在借助z3 solver进行Check ESC时,会导致诸多方法被检查出Invalid的情况。以Mypath为例,分析结果如下图所示:
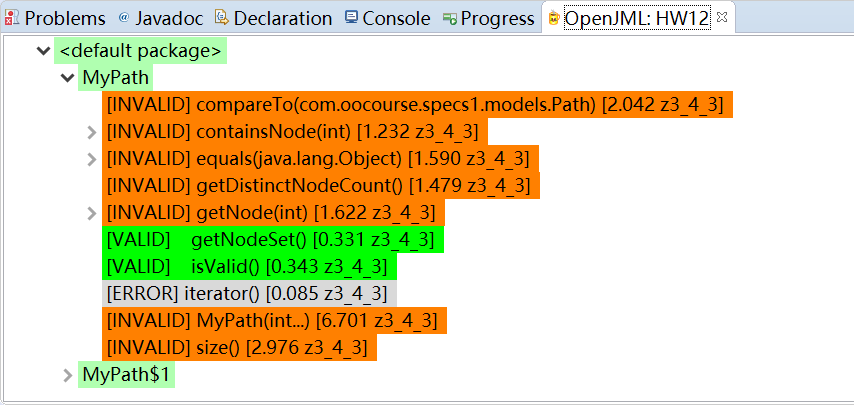
在此简要的分析一些报出的错误:
UndefinedNullDeReference assertion: 在使用path内数组时没有确保每个元素是非null的,但是由于题目约定,似乎不会出现这种情况;PossiblyNullDeReference assertion: 大概是由于这个对象本身可能是null,没有考虑到这种情况;
JMLUnitNG自动测试
由于forall等逻辑OpenJML会报错,因此只针对比较简单的方法进行了自动测试,被测代码如下:
package demo;
public class Demo {
public int[] nodes;
public Demo(int... nodeList) {
if (nodeList != null) {
this.nodes = nodeList;
}
}
//@ ensures
esult == nodes.length;
public int size() {
return nodes.length;
}
/*@ requires index >= 0 && index < size();
@ assignable
othing;
@ ensures
esult == nodes[index];
@*/
public int getNode(int index) {
if (index < 0 || index >= size()) {
return -1;
}
return nodes[index];
}
//@ ensures
esult == (nodes.length >= 2);
public boolean isValid() {
return (this.size() >= 2);
}
}
在输入如下命令后,会生成自动测试样例:
java -jar jmlunitng.jar demo/Demo.java
javac -cp jmlunitng.jar demo/**/*.java demo/*.java
java -jar openjml.jar -rac demo/Demo.java
此时目录树如下
demo
├── Demo.class
├── Demo_InstanceStrategy.class
├── Demo_InstanceStrategy.java
├── Demo.java
├── Demo_JML_Data
│ ├── ClassStrategy_int1DArray.class
│ ├── ClassStrategy_int1DArray.java
│ ├── ClassStrategy_int.class
│ ├── ClassStrategy_int.java
│ ├── Demo__int1DArray_nodeList__0__nodeList.class
│ ├── Demo__int1DArray_nodeList__0__nodeList.java
│ ├── getNode__int_index__0__index.class
│ └── getNode__int_index__0__index.java
├── Demo_JML_Test.class
├── Demo_JML_Test.java
├── PackageStrategy_int1DArray.class
├── PackageStrategy_int1DArray.java
├── PackageStrategy_int.class
└── PackageStrategy_int.java
1 directory, 18 files
输入运行命令
java -cp jmlunitng.jar: demo.Demo_JML_Test
可以得到如下运行结果:
[TestNG] Running:
Command line suite
Passed: racEnabled()
Failed: constructor Demo(null)
Passed: constructor Demo({})
Passed: <<demo.Demo@65e579dc>>.getNode(-2147483648)
Passed: <<demo.Demo@768debd>>.getNode(0)
Passed: <<demo.Demo@7d4793a8>>.getNode(2147483647)
Passed: <<demo.Demo@449b2d27>>.isValid()
Passed: <<demo.Demo@5479e3f>>.size()
===============================================
Command line suite
Total tests run: 8, Failures: 1, Skips: 0
===============================================
可以看出,JMLUnitNG本质上是在对边界条件在做检验,对整型会检查0和边界;而对Object则会检查空和null,由于在Demo()方法中未判断nodeList是否为null,因而有一个测试未通过。
作业架构梳理与BUG分析
第九次作业
架构梳理
本次作业实现了Path和PathContainer两个接口,类图如下:
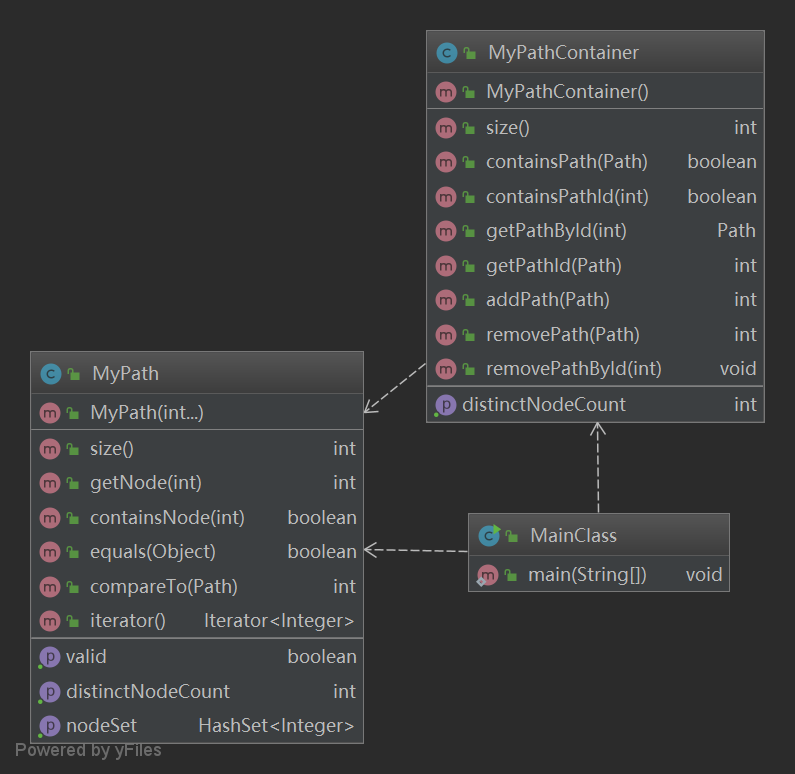
本次作业其实是对于JML规格的初步实践,因此难度并不大,按照规格写就能够保证程序正确性,本次作业笔者本想要严格按照规格写出每一步,后来发现似乎并没有这么做的必要,只需保证逻辑等价即可。因此虽然在MyPath中建的是int数组,且完全按照forall逻辑去遍历,但是在PathContainer里还是用了较为方便的ArrayList。
BUG分析
本次作业的一个小小难点,或者说这个单元的难点,其实是在于如何将时间复杂度控制在要求范围之内,即将大量重复运算做一些精简。可惜的是,做这一次作业的我,还十分天真的以为时间复杂度不会作为重点考察,并没有实现将多次重复的nodeCount工作拆分到不常使用的add与remove方法中,仅仅在path内部做了一个去重处理,就觉得足够了-_-||。于是程序就在一次次的遍历中,毫不留情的TLE了最后五个点。在第十次作业中采用了其他数据结构以及拆分到增删方法的策略,将在下面详细展开。
第十次作业
架构梳理
本次作业要实现的Graph接口,继承了上一次作业中的PathContainer,增加了对于图结构的处理,以及图中连通性与最短路的计算,整体架构如下:
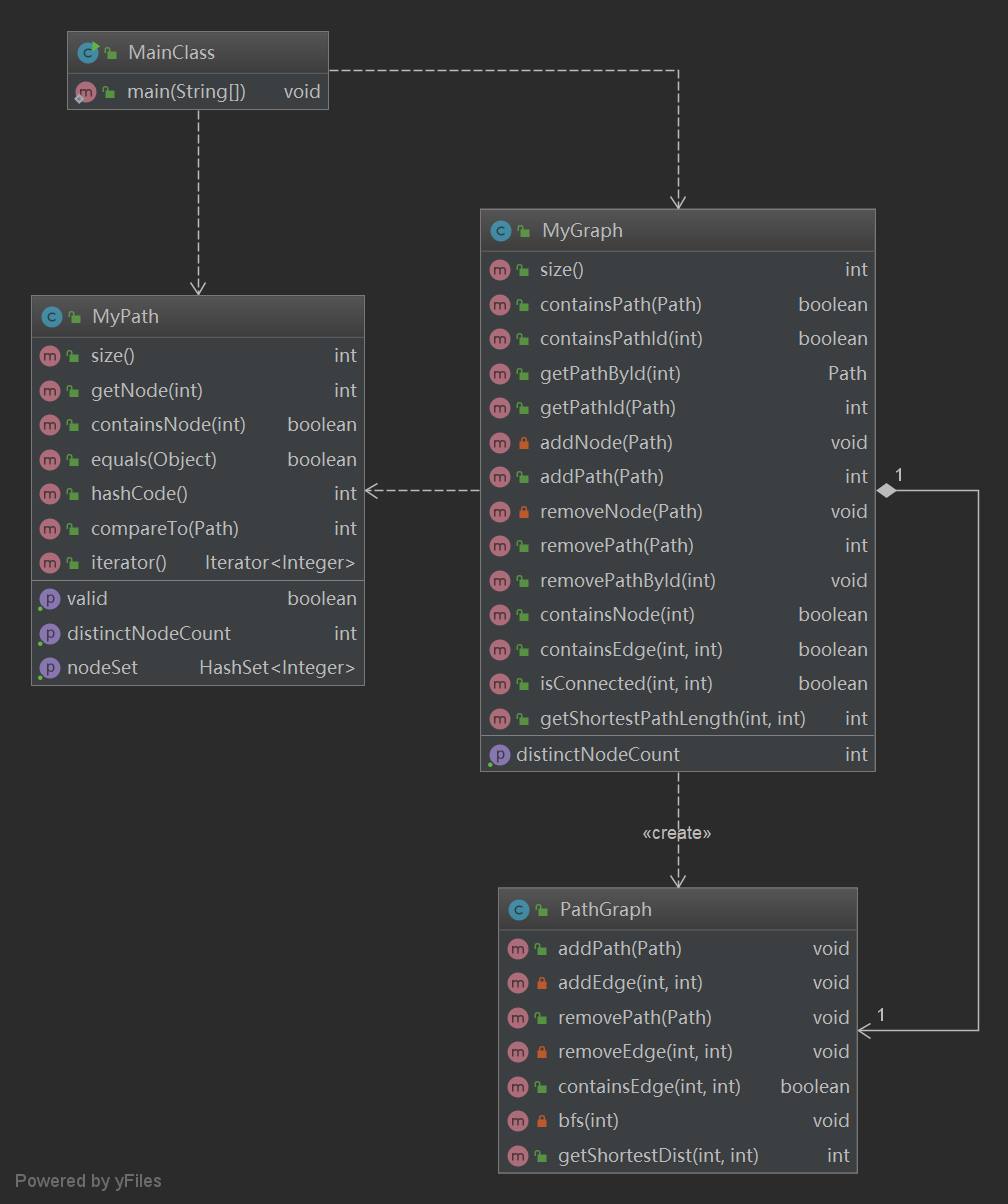
首先要解决的前朝余孽就是上一次的TLE问题,本着用空间换时间的策略,对MyGraph类做出如下调整:
- 原来用来存Path与Id对应关系的
ArrayList变成两个Path与Id之间相互映射的HashMap; - 在每一次增删Path时,完成对
distinctNodeCount的计算,使得每次实际调用该函数时,复杂度均为O(1)。
然后,对于本次扩展的内容,笔者专门新建了一个PathGraph类来实现一个通过Path建的图,并在该类中实现所要求的图操作。同样为保证查找的高效性,笔者使用了两层HashMap嵌套数据结构,实现了一个动态的邻接表,以方便的存储每个点的邻接点以及这些边在图中的条数,以确定在对Path进行增删操作后,图中的某条边是否被删去。对于最短路计算,笔者使用了较为简单的BFS,而连通性则是利用最短路计算结果来判断的,算法方面不再赘述。
此外,为保证此次新增内容不会向上次作业一样TLE,本次作业使用了一种较为简单的缓存机制,在每一次增删路径的间隔中,对于已经计算过BFS的源点,会将其计算结果缓存下来,以供后续查询使用,大大减少了重复计算。
BUG分析
本次强测没有发现BUG,由于没有互测部分就不展开讨论了。
第十一次作业
架构梳理
本次作业要实现的RailwaySystem继承了上一次作业的Graph接口,增加了对于连通块数量、换乘、票价以及不满意度的计算,整体架构如图所示:
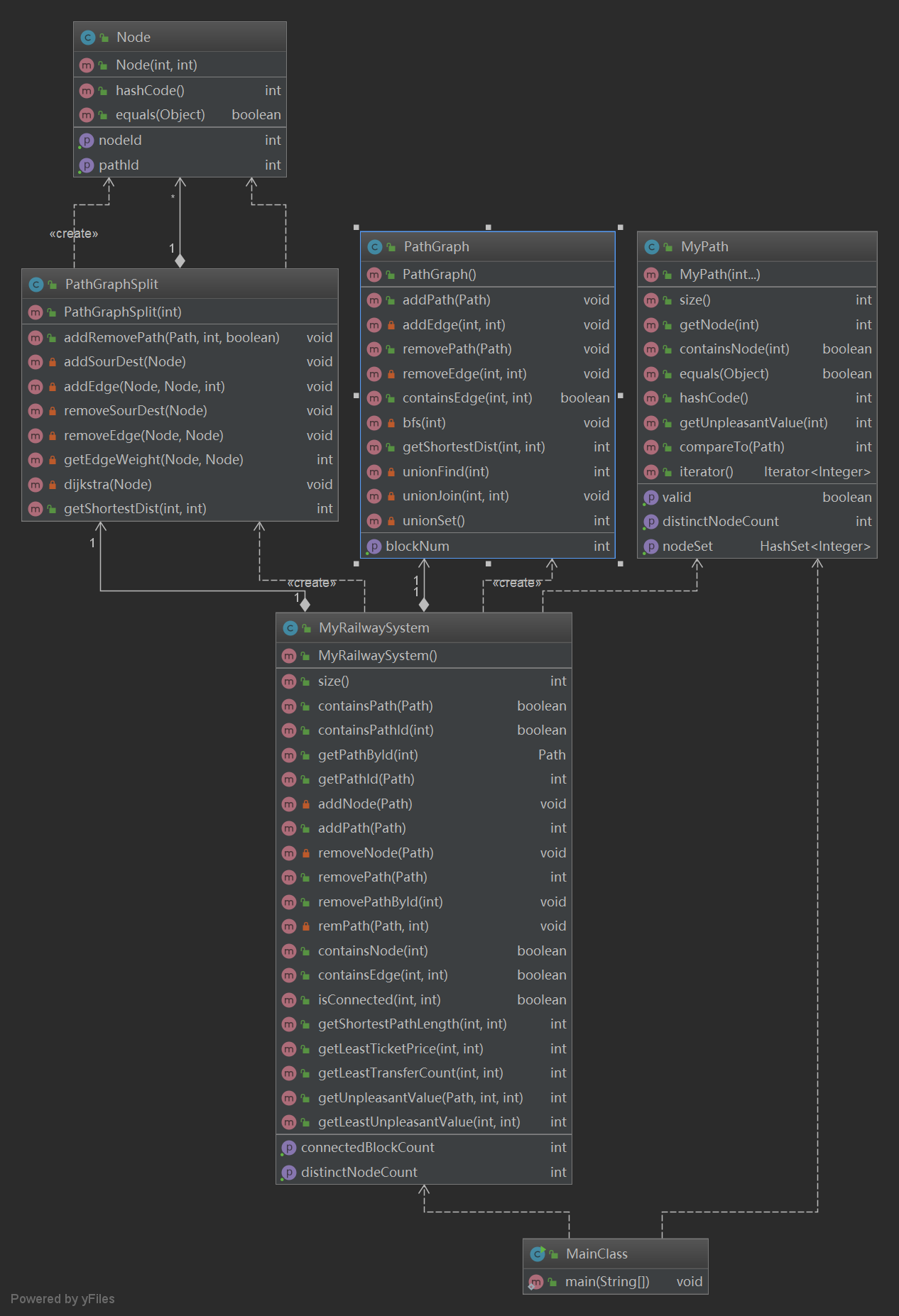
通过分析不难发现,新增的三种带权图计算在实际运算时唯一的区别就是边上的权值不同,因此可以统一使用一个图类PathGraphSplit的三种实例化来对他们进行整合,在该类中,采用了拆点的策略来对换乘进行处理。
拆点,顾名思义,即把不同path上相同编号的Node作为不同的Node处理,并在相同编号的Node间通过源点与汇点相互连接,从而实现换乘时边权的计算。为实现此,笔者实现了单独的Node类,并将源点与汇点的pathId分别设置为0与-1以供与普通path区分。
由于此次图为带权图,之前使用的BFS方法这次不能沿用,因而使用了更为普适的dijkstra算法,通过维护一个Pair<Node, Interger>组成的优先队列来降低每次计算时的复杂度。而至于前次作业中实现的最短路径查询,在拆点后的图中计算反而会增加运算负担,因而相关功能完全保留了上次的运算方式,仅在上次的基础上对新增功能进行了扩展,而没有去重写上次的BFS以求与本次合并。
BUG分析
本次强测没有发现BUG,由于没有互测部分就不展开讨论了。
心得体会
良好的规格不论是在自行设计,还是在团队合作中,都能起到极好的规范作用,让我们写出的代码清晰明确、方便测试且易于管理。不论是由规格出发,在一个规整的框架之内去写代码,还是从代码出发,去总结提炼规格,都是对我们工程化的一种极好锻炼。
但是,按照规格写代码并不完全是带着镣铐跳舞,我们要实现的,不是规格字面意义上规定的内容,而是在规格的约束之下,实现与要求逻辑上等价的代码。规格的存在,为我们指明了不同情况下,程序应该如何表现,也为我们从哪些角度测试提供了思路。
本单元的作业为我们完美的体现了实际工程之中,需求是如何一步步不断的迭代进步的,这种一点点丰满充实自己代码,而不是每次重构很多核心方法的编程模式,也为未来的编程学习提供了更好的思维模式。