参考《Redis 设计与实现》 (基于redis3.0.0) 作者:黄健宏
学习redis3.2.13
rdb文件结构
databases部分
key_value_pairs部分
type可取值
value 编码
长度编码
字符串对象编码
列表对象编码
集合对象编码
有序集合对象编码
哈希对象编码
rdb文件的创建与载入
创建方式
手动创建
自动创建
保存条件的设置
保存条件的触发判断
载入方式
数据库状态与rdb持久化
数据库状态定义:服务器中的非空数据库以及他们的键值对统称为数据库状态
redis是内存数据库,需要持久化来避免存储在内存中的数据丢失,redb持久化就是redis持久化方式的一种,它将数据库状态压缩后写入磁盘,生成二进制rdb文件。恢复时读取rdb文件即可恢复数据库状态
rdb文件结构
| 名称 | 大小 | 内容 | redis3.2.13新增 |
|---|---|---|---|
| REDIS | 5字节 | 存储字符'R' 'E' 'D' 'I' 'S',rdb文件固定开头,可根据此字符检查是否为rdb文件 | 否 |
| RDB_VERSION | 4字节 | rdb文件的版本号,redis3.2.13版本号为7 | 否 |
| REDIS_VERSION | 不定长 | redis版本号,为3.2.13 | 是 |
| redis_bits | 不定长 | 32位还是63位redis | 是 |
| ctime | 不定长 | rdb文件创建时间 | 是 |
| used-mem | 不定长 | redis服务器已使用内存 | 是 |
| databases | 不定长 | 数据库状态存储在此 | 否 |
| RDB_OPCODE_EOF | 1字节 | 表示databases部分结束,值为255 | 否 |
| check_sum | 8字节 | 前4部分内容的校验和,用于检查文件是否出错 | 否 |
REDIS_VERSION、redis_bits、ctime、used-mem统称为AuxFields,保存了一些辅助信息
databases部分
databases部分可以保存多个非空数据库,每个非空数据库内结构如下:
| 名称 | 大小 | 内容 | redis3.2.13新增 |
|---|---|---|---|
| RDB_OPCODE_SELECTDB | 1字节 | 表示接下来将是数据库号码,值为254 | 否 |
| db_number | 1、2、5字节 | 数据库号码,此部分首字节的最高2位表明db_number长度占用字节数,具体见长度编码一节 | 否 |
| RDB_OPCODE_RESIZEDB | 1字节 | 标识接下来是键空间中键值对数量与待过期键值对数量(过期字典数量),值为251 | 是 |
| db_size | 1、2、5字节 | 键空间中键值对数量 | 是 |
| expires_size | 1、2、5字节 | 待过期键值对数量(过期字典数量) | 是 |
| key_value_pairs | 不定长 | 键值对数据 | 否 |
根据存储rdb的代码来看下rdb结构:
int rdbSaveRio(rio *rdb, int *error) {
dictIterator *di = NULL;
dictEntry *de;
char magic[10];
int j;
long long now = mstime();
uint64_t cksum;
//按需设置校验和回调
if (server.rdb_checksum)
rdb->update_cksum = rioGenericUpdateChecksum;
//REDIS与rdb版本存储
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION); //#define RDB_VERSION 7 不向前兼容 6 5 4 3 2 1
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
if (rdbSaveInfoAuxFields(rdb) == -1) goto werr; //辅助信息存储(redis版本、redis位数、rdb创建时间、redis服务器已使用内存)
//databases部分
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j;
dict *d = db->dict;
if (dictSize(d) == 0) continue; //空数据库将不会被存储
di = dictGetSafeIterator(d);
if (!di) return C_ERR;
//RDB_OPCODE_SELECTDB与数据库号码存储
if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
if (rdbSaveLen(rdb,j) == -1) goto werr;
//RDB_OPCODE_RESIZEDB、键空间中键值对数量与待过期键值对数量(过期字典数量)存储
uint32_t db_size, expires_size;
db_size = (dictSize(db->dict) <= UINT32_MAX) ?
dictSize(db->dict) :
UINT32_MAX;
expires_size = (dictSize(db->expires) <= UINT32_MAX) ?
dictSize(db->expires) :
UINT32_MAX;
if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
if (rdbSaveLen(rdb,db_size) == -1) goto werr;
if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
/* Iterate this DB writing every entry */
//对当前非空数据库的每一项键值对进行存储
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
initStaticStringObject(key,keystr);
expire = getExpire(db,&key);
//存储过期时间与键值对(已过期的键值对不会被存储,如果存在过期时间,按RDB_OPCODE_EXPIRETIME_MS方式存储)
if (rdbSaveKeyValuePair(rdb,&key,o,expire,now) == -1) goto werr;
}
dictReleaseIterator(di);
}
di = NULL; /* So that we don't release it again on error. */
//存储RDB_OPCODE_EOF
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
//CRC64校验和存储(如果校验和功能关闭,则rdb.cksum 将为 0,且载入时会跳过校验和检查)
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
werr:
if (error) *error = errno;
if (di) dictReleaseIterator(di);
return C_ERR;
}key_value_pairs部分
key_value_pairs部分保存一个以上的键值对,键值对可以带过期时间或不带,key_value_pairs部分结构如下:
| 名称 | 大小 | 可取值 | 内容 | 字段是否可选 |
|---|---|---|---|---|
| expiretime | 1字节 | RDB_OPCODE_EXPIRETIME或RDB_OPCODE_EXPIRETIME_MS | 过期时间起始,说明后续时间戳timestamp类型,值为253或252 | 是 |
| timestamp | 4或8字节 | 无 | 键值对过期时间戳,时间单位分别为秒或毫秒,取决于EXPIRETIME,毫秒时为8字节 | 是 |
| type | 1字节 | 见下表 | 表明value的类型 | 否 |
| key | 不定长 | 无 | 键,为字符串对象 | 否 |
| value | 不定长 | 无 | 值,取决于type字段 | 否 |
expiretime与timestamp是可选的,当键值对带有过期时间是它们是成对出现,不带有过期键则expiretime与timestamp均不存在
int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val,
long long expiretime, long long now)
{
//过期时间存在时,存储过期时间
if (expiretime != -1) {
//已过期的键不会被存储
//按RDB_OPCODE_EXPIRETIME_MS方式存储过期时间戳
if (expiretime < now) return 0;
if (rdbSaveType(rdb,RDB_OPCODE_EXPIRETIME_MS) == -1) return -1;
if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1;
}
//存储type key value
if (rdbSaveObjectType(rdb,val) == -1) return -1;
if (rdbSaveStringObject(rdb,key) == -1) return -1;
if (rdbSaveObject(rdb,val) == -1) return -1;
return 1;
}type可取值
type表示对象的类型或
| 宏定义 | 值 | 源对象类型 | 源对象编码 | 内容 |
|---|---|---|---|---|
| RDB_TYPE_STRING | 0 | OBJ_STRING | OBJ_ENCODING_RAW或OBJ_ENCODING_INT | 字符串对象 |
| RDB_TYPE_LIST_QUICKLIST | 14 | OBJ_LIST | OBJ_ENCODING_QUICKLIST | 快速列表实现的列表对象 |
| RDB_TYPE_SET_INTSET | 11 | OBJ_SET | OBJ_ENCODING_INTSET | 整数集合实现的集合对象 |
| RDB_TYPE_SET | 2 | OBJ_SET | OBJ_ENCODING_HT | 字典实现的集合对象 |
| RDB_TYPE_ZSET_ZIPLIST | 12 | OBJ_ZSET | OBJ_ENCODING_ZIPLIST | 压缩列表实现的有序集合对象 |
| RDB_TYPE_ZSET | 3 | OBJ_ZSET | OBJ_ENCODING_SKIPLIST | 跳表实现的有序集合对象 |
| RDB_TYPE_HASH_ZIPLIST | 13 | OBJ_HASH | OBJ_ENCODING_ZIPLIST | 压缩列表实现的哈希对象 |
| RDB_TYPE_HASH | 4 | OBJ_HASH | OBJ_ENCODING_HT | 字典实现的哈希对象 |
int rdbSaveObjectType(rio *rdb, robj *o) {
switch (o->type) {
case OBJ_STRING:
return rdbSaveType(rdb,RDB_TYPE_STRING);
case OBJ_LIST:
if (o->encoding == OBJ_ENCODING_QUICKLIST)
return rdbSaveType(rdb,RDB_TYPE_LIST_QUICKLIST);
else
serverPanic("Unknown list encoding");
case OBJ_SET:
if (o->encoding == OBJ_ENCODING_INTSET)
return rdbSaveType(rdb,RDB_TYPE_SET_INTSET);
else if (o->encoding == OBJ_ENCODING_HT)
return rdbSaveType(rdb,RDB_TYPE_SET);
else
serverPanic("Unknown set encoding");
case OBJ_ZSET:
if (o->encoding == OBJ_ENCODING_ZIPLIST)
return rdbSaveType(rdb,RDB_TYPE_ZSET_ZIPLIST);
else if (o->encoding == OBJ_ENCODING_SKIPLIST)
return rdbSaveType(rdb,RDB_TYPE_ZSET);
else
serverPanic("Unknown sorted set encoding");
case OBJ_HASH:
if (o->encoding == OBJ_ENCODING_ZIPLIST)
return rdbSaveType(rdb,RDB_TYPE_HASH_ZIPLIST);
else if (o->encoding == OBJ_ENCODING_HT)
return rdbSaveType(rdb,RDB_TYPE_HASH);
else
serverPanic("Unknown hash encoding");
default:
serverPanic("Unknown object type");
}
return -1; /* avoid warning */
}value 编码
value里涉及到长度值的保存,以及前面db号的保存都涉及到了对长度的编码(对长度值编码后存储)
长度编码
通过在长度部分首字节的最高2位来标识长度值开始位置以及所占字节数,从而恢复存储其中的长度值(有点绕口,等会举个例子)
| 最高2位 | 值(十进制) | 代码中宏定义 | 含义 |
|---|---|---|---|
| 00 | 0 | RDB_6BITLEN | 本字节取余6位是存储的长度值 |
| 01 | 1 | RDB_14BITLEN | 本字节剩余6位与下一个字节的8位共同存储长度值 |
| 10 | 2 | RDB_32BITLEN | 长度值存储在本字节后的32位中 |
| 11 | 3 | RDB_ENCVAL | 后跟一个特殊编码对象标识符(RDB_ENC_INT8、RDB_ENC_INT16、RDB_ENC_INT32、RDB_ENC_LZF)以及特殊编码对象本身(存储数字或字符串被编码后的内容) |
长度被编码后的例子:
- 长度部分用14字节存储了长度值255 -> 01000000 11111111
- 长度部分跟了特殊编码对象 -> 11(RDB_ENCVAL)11(RDB_ENC_LZF) + 字符串压缩长度+字符串原始长度+压缩字符串
对长度编码源码如下:
uint32_t rdbLoadLen(rio *rdb, int *isencoded) {
unsigned char buf[2];
uint32_t len;
int type;
if (isencoded) *isencoded = 0;
if (rioRead(rdb,buf,1) == 0) return RDB_LENERR;
type = (buf[0]&0xC0)>>6;
if (type == RDB_ENCVAL) {
/* Read a 6 bit encoding type. */
if (isencoded) *isencoded = 1;
return buf[0]&0x3F;
} else if (type == RDB_6BITLEN) {
/* Read a 6 bit len. */
return buf[0]&0x3F;
} else if (type == RDB_14BITLEN) {
/* Read a 14 bit len. */
if (rioRead(rdb,buf+1,1) == 0) return RDB_LENERR;
return ((buf[0]&0x3F)<<8)|buf[1];
} else if (type == RDB_32BITLEN) {
/* Read a 32 bit len. */
if (rioRead(rdb,&len,4) == 0) return RDB_LENERR;
return ntohl(len);
} else {
rdbExitReportCorruptRDB(
"Unknown length encoding %d in rdbLoadLen()",type);
return -1; /* Never reached. */
}
}type为RDB_ENCVAL的长度编码在编码字符串的函数中,后面揭晓
字符串对象编码
| 类型 | 格式 | 解释 |
|---|---|---|
| [len][data]字符串 | 字符串长度+字符串 | 源字符串对象长度小于20字节或关闭了rdb文件压缩功能(redis.conf的rdbcompression),或为源字符串为整数实现但编码整数失败 |
| 整数字符串 | RDB_ENCVAL + RDB_ENC_INT8或RDB_ENC_INT16或RDB_ENC_INT32 + 整数 | 源字符串对象为整数实现 |
| 压缩字符串 | RDB_ENC_LZF + 字符串压缩后长度 + 字符串原始长度 + 压缩后字符串 | 开启了rdb文件压缩功能且源字符串对象长度大于20 |
ssize_t rdbSaveRawString(rio *rdb, unsigned char *s, size_t len) {
int enclen;
ssize_t n, nwritten = 0;
//长度小于11,尝试整数字符串方式编码并存储
if (len <= 11) {
unsigned char buf[5];
if ((enclen = rdbTryIntegerEncoding((char*)s,len,buf)) > 0) {
if (rdbWriteRaw(rdb,buf,enclen) == -1) return -1;
return enclen;
}
}
//条件尝试LZF压缩
if (server.rdb_compression && len > 20) {
n = rdbSaveLzfStringObject(rdb,s,len);
if (n == -1) return -1;
if (n > 0) return n;
/* Return value of 0 means data can't be compressed, save the old way */
}
//按[len][data]编码来存储
if ((n = rdbSaveLen(rdb,len)) == -1) return -1;
nwritten += n;
if (len > 0) {
if (rdbWriteRaw(rdb,s,len) == -1) return -1;
nwritten += len;
}
return nwritten;
}
ssize_t rdbSaveLongLongAsStringObject(rio *rdb, long long value) {
unsigned char buf[32];
ssize_t n, nwritten = 0;
//按整数字符串方式编码value并存储 格式:RDB_ENCVAL + RDB_ENC_INT8或RDB_ENC_INT16或RDB_ENC_INT32 + 整数
int enclen = rdbEncodeInteger(value,buf);
if (enclen > 0) {
return rdbWriteRaw(rdb,buf,enclen);
} else { //失败时,转为字符串,按[len][data]编码来存储
/* Encode as string */
enclen = ll2string((char*)buf,32,value);
serverAssert(enclen < 32);
if ((n = rdbSaveLen(rdb,enclen)) == -1) return -1; //写len
nwritten += n;
if ((n = rdbWriteRaw(rdb,buf,enclen)) == -1) return -1; //写buf
nwritten += n;
}
return nwritten;
}
int rdbSaveStringObject(rio *rdb, robj *obj) {
//字符串对象为整数实现
if (obj->encoding == OBJ_ENCODING_INT) {
return rdbSaveLongLongAsStringObject(rdb,(long)obj->ptr);
} else { //OBJ_ENCODING_RAW
serverAssertWithInfo(NULL,obj,sdsEncodedObject(obj));
return rdbSaveRawString(rdb,obj->ptr,sdslen(obj->ptr));
}
}列表对象编码
| 类型 | 格式 | 解释 |
|---|---|---|
| 快速列表实现的列表 | 快速列表长度 + 每一个被存储为字符串编码的节点 | 先存储了快速列表节点个数,随后按字符串编码的方式存储每一个节点,如果节点的数据已经被压缩,就是压缩字符串,否则如果可以转为整数,就是整数字符串,如果长度大于20,并可压缩,也是压缩字符串,否则为len data字符串 |
集合对象编码
| 类型 | 格式 | 解释 |
|---|---|---|
| 字典实现的集合 | 字典大小 + 每一个被存储为字符串编码的键(集合的元素) | 与列表对象编码解释一致 |
| 整数集合实现的集合 | 以字符串编码方式存储整数集合 | 以字符串方式存储整数集合 |
有序集合对象编码
| 类型 | 格式 | 解释 |
|---|---|---|
| 以压缩列表实现的有序集合 | 以字符串编码方式存储压缩列表 | 以字符串方式存储压缩列表 |
| 以跳表实现的有序结合 | 跳表的长度 + 每一个被存储为字符串编码的成员 + 对应的被存储为字符串形式的分值(非前述字符串编码) | 先存储了跳表的大小,随后对每个成员分值对进行编码存储,成员为字符串编码方式,分值按1字节标识+值的字符串形式存 |
哈希对象编码
| 类型 | 格式 | 解释 |
|---|---|---|
| 压缩列表实现的哈希 | 以字符串编码方式存储压缩列表 | 以字符串方式存储压缩列表 |
| 字典实现的哈希 | 字典大小 + 每一个被存储为字符串编码的键 + 对应的被存储为字符串的值 | 先存储了字典大小,随后对每个键值对进行字符串编码方式存储,键在先,值在后 |
列表对象、集合对象、有序集合对象、哈希对象都以字符串编码方式或类似字符串编码的方式存储每个元素
ssize_t rdbSaveObject(rio *rdb, robj *o) {
ssize_t n = 0, nwritten = 0;
if (o->type == OBJ_STRING) { //字符串对象
/* Save a string value */
if ((n = rdbSaveStringObject(rdb,o)) == -1) return -1;
nwritten += n;
} else if (o->type == OBJ_LIST) { //列表对象
/* Save a list value */
if (o->encoding == OBJ_ENCODING_QUICKLIST) { //快速列表实现
quicklist *ql = o->ptr;
quicklistNode *node = ql->head;
//快速列表节点个数
if ((n = rdbSaveLen(rdb,ql->len)) == -1) return -1;
nwritten += n;
//逐个处理全部节点
while(node) {
if (quicklistNodeIsCompressed(node)) { //节点已被压缩
void *data;
size_t compress_len = quicklistGetLzf(node, &data); //获取被压缩数据与长度
if ((n = rdbSaveLzfBlob(rdb,data,compress_len,node->sz)) == -1) return -1; //存储数据与长度 格式 RDB_ENCVAL + RDB_ENC_LZF + compress_len + original_len + data
nwritten += n;
} else {
if ((n = rdbSaveRawString(rdb,node->zl,node->sz)) == -1) return -1; //字符串编码方式存储
nwritten += n;
}
node = node->next;
}
} else {
serverPanic("Unknown list encoding");
}
} else if (o->type == OBJ_SET) { //集合对象
/* Save a set value */
if (o->encoding == OBJ_ENCODING_HT) { //字典实现
dict *set = o->ptr;
dictIterator *di = dictGetIterator(set);
dictEntry *de;
//字典大小
if ((n = rdbSaveLen(rdb,dictSize(set))) == -1) return -1;
nwritten += n;
//逐个处理全部字典项
while((de = dictNext(di)) != NULL) {
robj *eleobj = dictGetKey(de);
if ((n = rdbSaveStringObject(rdb,eleobj)) == -1) return -1; //字符串编码方式存储
nwritten += n;
}
dictReleaseIterator(di);
} else if (o->encoding == OBJ_ENCODING_INTSET) { //整数集合实现
size_t l = intsetBlobLen((intset*)o->ptr); //intset结构与数据共占用的字节数(整体大小)
if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1; //字符串编码方式存储
nwritten += n;
} else {
serverPanic("Unknown set encoding");
}
} else if (o->type == OBJ_ZSET) { //有序集合对象
/* Save a sorted set value */
if (o->encoding == OBJ_ENCODING_ZIPLIST) { //压缩列表实现
size_t l = ziplistBlobLen((unsigned char*)o->ptr); //压缩列表结构与数据共占用的字节数(整体大小)
if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1; //字符串编码方式存储
nwritten += n;
} else if (o->encoding == OBJ_ENCODING_SKIPLIST) { //跳表实现
zset *zs = o->ptr;
dictIterator *di = dictGetIterator(zs->dict);
dictEntry *de;
//跳表大小
if ((n = rdbSaveLen(rdb,dictSize(zs->dict))) == -1) return -1;
nwritten += n;
//逐个处理全部成员分值对
while((de = dictNext(di)) != NULL) {
robj *eleobj = dictGetKey(de);
double *score = dictGetVal(de);
////字符串编码方式存储成员 按[flag][data]字符串编码方式存储分值(flag为1字节,表示非数值或最大最小值,或是正常数值的长度)
if ((n = rdbSaveStringObject(rdb,eleobj)) == -1) return -1;
nwritten += n;
if ((n = rdbSaveDoubleValue(rdb,*score)) == -1) return -1;
nwritten += n;
}
dictReleaseIterator(di);
} else {
serverPanic("Unknown sorted set encoding");
}
} else if (o->type == OBJ_HASH) { //哈希对象
/* Save a hash value */
if (o->encoding == OBJ_ENCODING_ZIPLIST) { //压缩列表实现
size_t l = ziplistBlobLen((unsigned char*)o->ptr); //压缩列表结构与数据共占用的字节数(整体大小)
if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1; //字符串编码方式存储
nwritten += n;
} else if (o->encoding == OBJ_ENCODING_HT) { //字典实现
dictIterator *di = dictGetIterator(o->ptr);
dictEntry *de;
if ((n = rdbSaveLen(rdb,dictSize((dict*)o->ptr))) == -1) return -1;
nwritten += n;
while((de = dictNext(di)) != NULL) {
robj *key = dictGetKey(de);
robj *val = dictGetVal(de);
if ((n = rdbSaveStringObject(rdb,key)) == -1) return -1;
nwritten += n;
if ((n = rdbSaveStringObject(rdb,val)) == -1) return -1;
nwritten += n;
}
dictReleaseIterator(di);
} else {
serverPanic("Unknown hash encoding");
}
} else {
serverPanic("Unknown object type");
}
return nwritten;
}rdb文件的创建与载入
创建方式
手动创建
- save命令:该命令会阻塞服务器进程直到rdb文件创建完成,由于是主线程执行,save命令执行期间,服务器没法处理任何命令请求,一般不通过此命令创建rdb文件
void saveCommand(client *c) {
if (server.rdb_child_pid != -1) { //正在执行rdb持久化,退出
addReplyError(c,"Background save already in progress");
return;
}
//进行save操作
if (rdbSave(server.rdb_filename) == C_OK) {
addReply(c,shared.ok);
} else {
addReply(c,shared.err);
}
}
int rdbSave(char *filename) {
char tmpfile[256];
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
FILE *fp;
rio rdb;
int error = 0;
//根据pid创建临时文件
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Failed opening the RDB file %s (in server root dir %s) "
"for saving: %s",
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
return C_ERR;
}
//初始化rio
rioInitWithFile(&rdb,fp);
//将数据库状态写入临时文件
if (rdbSaveRio(&rdb,&error) == C_ERR) {
errno = error;
goto werr;
}
//进行刷缓存操作,确保数据写入硬盘
if (fflush(fp) == EOF) goto werr; //c库缓冲刷到内核缓冲
if (fsync(fileno(fp)) == -1) goto werr; //内核缓冲刷到硬盘
if (fclose(fp) == EOF) goto werr;
//将临时文件改名为rdb文件,改名失败则写log并删除临时文件
if (rename(tmpfile,filename) == -1) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
return C_ERR;
}
//写成功log、更新状态信息
serverLog(LL_NOTICE,"DB saved on disk");
server.dirty = 0; //更新脏计数
server.lastsave = time(NULL); //更新最后一次save的时间
server.lastbgsave_status = C_OK; //更新最后一次save的状态
return C_OK;
werr: //错误处理
serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
return C_ERR;
}可以看到save命令执行过程中,没有通过任何子进程/线程执行rdb写入操作
- bgsave命令:fork出子进程专门创建rdb文件,服务器进程继续响应命令请求
/* BGSAVE [SCHEDULE] */
void bgsaveCommand(client *c) {
int schedule = 0;
//bgsave命令带了schedule选项
//当aof持久化正在进行时,schedule选项改变了bgsave的行为,bgsave将会被调度,而不是返回错误
if (c->argc > 1) {
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"schedule")) {
schedule = 1;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
if (server.rdb_child_pid != -1) { //正在执行rdb持久化,没必要重复执行后台save
addReplyError(c,"Background save already in progress");
} else if (server.aof_child_pid != -1) { //aof重写正在运行
if (schedule) { //bgsave等待调度
server.rdb_bgsave_scheduled = 1;
addReplyStatus(c,"Background saving scheduled");
} else {
addReplyError(c,
"An AOF log rewriting in progress: can't BGSAVE right now. "
"Use BGSAVE SCHEDULE in order to schedule a BGSAVE whenver "
"possible.");
}
} else if (rdbSaveBackground(server.rdb_filename) == C_OK) { //执行后退save
addReplyStatus(c,"Background saving started");
} else {
addReply(c,shared.err);
}
}
int rdbSaveBackground(char *filename) {
pid_t childpid;
long long start;
//避免数据竞争
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
//记录执行前数据库修改次数以及最后一次尝试bgsave的时间
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
//用于计算fork耗时
start = ustime();
if ((childpid = fork()) == 0) {
int retval;
/* Child */
closeListeningSockets(0); //关socket
redisSetProcTitle("redis-rdb-bgsave"); //设置进场标题
retval = rdbSave(filename); //保存rdb
if (retval == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty(); //COW使用的内存大小,即持久化时子进程占用的实际物理内存
if (private_dirty) {
serverLog(LL_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
}
exitFromChild((retval == C_OK) ? 0 : 1); //向父进程返回执行结果
} else {
/* Parent */
server.stat_fork_time = ustime()-start; //记录fork耗时
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000); //fork耗时超过监控的阈值,添加延时样本
if (childpid == -1) {//fork失败处理
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %d",childpid); //bgsave启动日志
server.rdb_save_time_start = time(NULL); //bgsave开始时间
server.rdb_child_pid = childpid; //bgsave子进程id
server.rdb_child_type = RDB_CHILD_TYPE_DISK; //rdb类型为写硬盘
updateDictResizePolicy(); //关闭dict的rehash功能,子进程正在写rdb,关闭rehash,避免触发cow,导致大量拷贝内存页
return C_OK;
}
return C_OK; /* unreached */
}可以看到,rdb文件的写入,由单独的进程去执行,子进程结束后通知服务器进程执行结果,这使得服务器进程可以快速返回,来处理其他命令
服务器进程最后关闭dict的rehash,是因为COW技术使得fork出来的子进程与父进程共享物理内存,发生写操作时,会分配物理空间,并将内容复制一份到新分配的空间以供修改,为了避免发生大量分配与拷贝,暂时关闭rehash操作
自动创建
保存条件的设置
通过修改redis配置文件中SNAPSHOTTING部分,让服务器每隔一定的时间条件性执行一次bgsave
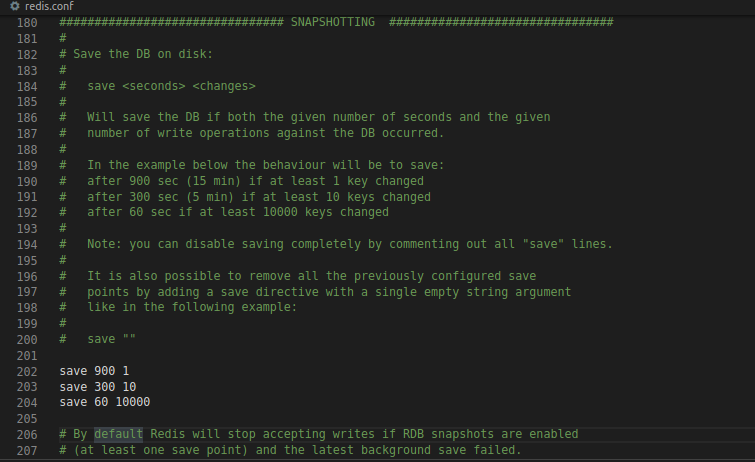
图中设置了3个条件,各条件的意思分别如下:
- 服务器在900秒内,对数据库进行了1次修改
- 服务器在300秒内,对数据库进行了10次修改
- 服务器在60秒内,对数据库进行了10000次修改
当满足以上设置条件的任何一个,服务器就会执行bgsave命令
设置的自动保存条件在redis服务器启动时被存储在了saveparams数组中,数组中的每个元素是包含秒数与修改次数的结构体
保存条件的触发判断
当对任意数据库中的数据进行修改时,redisServer结构体中的dirty就会被增加1,rdb文件保存成功时则会置0,同时会将rdb文件保存时间更新到lastsave,dirty与lastsave被作为了自动保存的检查条件在函数serverCron中使用。
serverCron函数是周期性操作函数,每个100毫秒执行一次,serverCron中对数据库状态的检查代码如下:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
//...
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
ldbPendingChildren())
{
//...
} else {
/* If there is not a background saving/rewrite in progress check if
* we have to save/rewrite now */
//对每个保存条件进行检查
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
//对数据库状态修改次数大于等于设定次数 且 距离上次保存时间超过设定时间
//且 (上次执行失败但已经过了CONFIG_BGSAVE_RETRY_DELAY秒 或 上次执行成功)
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY || //#define CONFIG_BGSAVE_RETRY_DELAY 5
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveBackground(server.rdb_filename);
break;
}
}
}
}载入方式
redis并没有专门载入rdb文件的命令,载入是在启动时自动完成的:
在server.c的main函数中,会对当前进程进行判断,如果不是sentinel_mode,就会调用函数loadDataFromDisk函数,读取持久化生成的aof或rdb文件
void loadDataFromDisk(void) {
long long start = ustime();
if (server.aof_state == AOF_ON) {
if (loadAppendOnlyFile(server.aof_filename) == C_OK)
serverLog(LL_NOTICE,"DB loaded from append only file: %.3f seconds",(float)(ustime()-start)/1000000);
} else {
if (rdbLoad(server.rdb_filename) == C_OK) {
serverLog(LL_NOTICE,"DB loaded from disk: %.3f seconds",
(float)(ustime()-start)/1000000);
} else if (errno != ENOENT) {
serverLog(LL_WARNING,"Fatal error loading the DB: %s. Exiting.",strerror(errno));
exit(1);
}
}
}由上面的if else结构可知,aof文件或rdb文件的载入是二选一的,并且aof的优先级更高,由于aof文件的更新频率通常比rdb文件更新频率高,所以载入aof文件有更高的优先级
后面的载入为rdbSave以及rdb文件结构中代码的逆过程